Chord算法
转自:http://blog.csdn.net/wangxiaoqin00007/article/details/7374833
虽然网上搜索CHord,一搜一大堆,但大多讲得不太清楚明白。今天发现一篇blog,图文并茂,逻辑清楚且易懂,特意转载收藏。
P2P的一个常见问题是如何高效的定位节点,也就是说,一个节点怎样高效的知道在网络中的哪个节点包含它所寻找的数据,如下图:
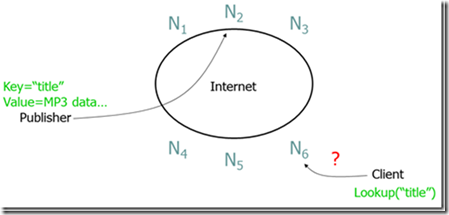
对此,有三种比较典型的来解决这个问题。
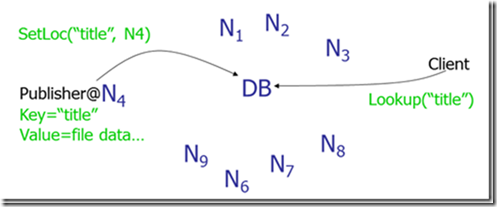
Napster:使用一个中心服务器接收所有的查询,服务器告知去哪下载其所需要的数据。存在的问题是中心服务器单点失效导致整个网络瘫痪。
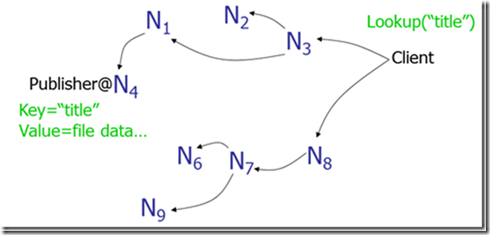
Gnutella:使用消息洪泛(message flooding)来定位数据。一个消息被发到系统内每一个节点,直到找到其需要的数据为止。当然,使用生存时间(TTL)来限制网络内转发消息的数量。存在的问题是消息数与节点数成线性关系,导致网络负载较重。
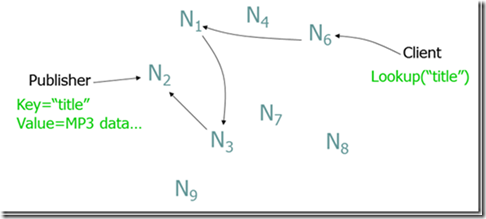
SN型:现在大多数采用所谓超级节点(Super Node),SN保存网络中节点的索引信息,这一点和中心服务器类型一样,但是网内有多个SN,其索引信息会在这些SN中进行传播,所以整个系统的崩溃几率就会小很多。尽管如此,网络还是有崩溃的可能。
现在的研究结果中,Chord、Pastry、CAN和Tapestry等常用于构建结构化P2P的分布式哈希表系统(Distributed Hash Table,DHT)。
DHT的主要思想是:首先,每条文件索引被表示成一个(K, V)对,K称为关键字,可以是文件名(或文件的其他描述信息)的哈希值,V是实际存储文件的节点的IP地址(或节点的其他描述信息)。所有的文件索引条目(即所有的(K, V)对)组成一张大的文件索引哈希表,只要输入目标文件的K值,就可以从这张表中查出所有存储该文件的节点地址。然后,再将上面的大文件哈希表分割成很多局部小块,按照特定的规则把这些小块的局部哈希表分布到系统中的所有参与节点上,使得每个节点负责维护其中的一块。这样,节点查询文件时,只要把查询报文路由到相应的节点即可(该节点维护的哈希表分块中含有要查找的(K,V)对)。
这里介绍的Chord算法就是解决网络内节点定位问题的一种P2P协议。它通过多个节点跳转找到我们所查找的资源:
我们先看看它是如何进行的,随后再总结其特点和操作特征,以及一些实现。
1.Chord里面的基本要素
节点ID:NID(node identifier),表示一个物理机器,m位的一个数字(m要足够大以保证不同节点的NID相同的几率小的可以忽略不计),由节点机器的IP地址通过哈希操作得到。
资源ID;KID(key identifiers),原为键ID,其实际表示一个资源(因为Key与一个资源value哈希绑定),故在本文中统称资源ID(这样比较直观),m位的一个数字(m要足够大以保证不同资源的KID相同的几率小的可以忽略不计),由Key通过哈希操作得到。
常哈希函数:较之一般哈希函数,节点的加入和离开对整个系统影响最小,另外还有一些优势在此不赘述。在Chord中使用SHA-1来进行常哈希计算。
Chord环:Chord Ring,NID和KID被分配到一个大小为2^m的环上,用于资源分配(给某一个节点)和节点分布,以及资源定位(注:在这个环上的ID为0--2^m-1)。首先我们说资源分配,资源被分配到NID>=KID的节点上,这个节点成为k的后继节点,是环上从k起顺时针方向的第一个节点,记为successor(k)。而节点分布则顺时针将节点N由大到小放在这个环上。例如下边这幅图:
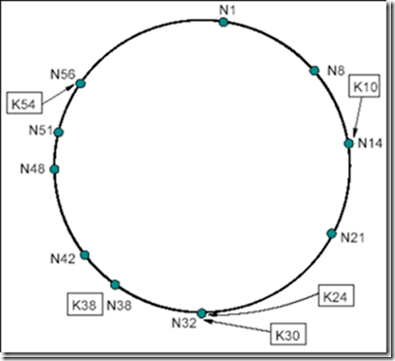
这是一个m=6的环,其中有10个节点,5个资源,K10的后继节点为N14,也就是说K10被分配给了N14。
2.Chord资源定位(Key Location)
资源定位是Chord协议的核心功能,为了便于理解,我们先介绍一个简单的资源定位方法,然后再介绍这个可伸缩的资源定位方法。
简单方法:
考虑如下场景:节点n寻找KID为id的资源,此时节点n首先问询是否在下一个节点上(find_successor),这要看资源k的KID是否在该节点NID和下一个节点的NID之间,若在则说明资源k被分配给了下一个节点,若不在则在下一个节点上发起同样的查询,问询下下一个点是否有该资源。如此迭代下去,用伪代码定义这个操作:
n.find_successor(id)
if (id є (n; successor])
return successor;
else
// 将查询沿着环进行下去
return successor.find_successor(id);
例如下图:
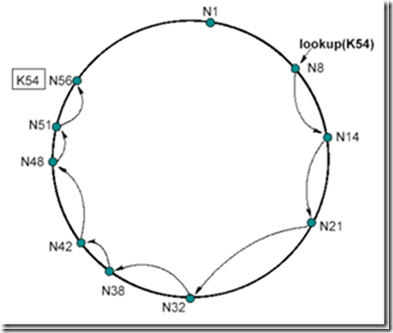
节点N8寻找K54这个资源,N8.find_successor(K54)发现下一个节点N14不合符54є (8; 14],于是N14发起同样的搜索,然后一跳一跳后直到节点N56满足54є (51; 56],于是得知资源K54在N56这个节点上。
在一个有N个节点的环上,这样的查找方法显然在最坏的时候要查找N次才能得到所需资源的位置,查找次数与节点个数成线性关系。显然,这样的效率不给力,所以Chord使用了可伸缩资源定位的方式来提高效率。
可伸缩方法:
在每个节点N上都维护了最多有m项(m为ID的位数)的路由表(称为finger table),用来定位资源。这个表的第i项是该节点的后继节位置,至少包含到2^(i-1)后的位置。还是延续上边的例子:
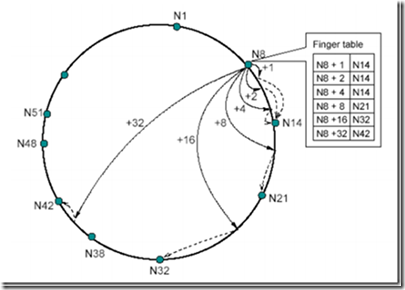
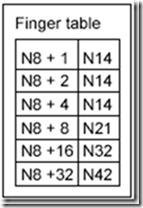
节点N8的路由表中,左边那一栏包含了N8+1到N8+32(2^5-1)的位置,右边那一栏每个位置对应的实际存在的节点。比如N8+1-N14,表示在N8后的第一个位置上的资源由N14来负责。这样记录有以下优势:
每个节点只包含全网中一小部分节点的信息。
每个节点对于临近节点负责的位置知道的更多,比如N8节点对于N14负责的位置知道3处,而对N21负责的位置只知道1处。
路由表通常不包含直接找到后继节点的信息,往往需要询问其他节点来完成。
当在某个节点上查找资源时,首先判断其后继节点是不是就持有该资源,若没有则直接从该节点的路由表从最远处开始查找,看哪一项离持有资源的节点最近(发现后跳转),若没有则说明本节点自身就有要寻找的资源。如此迭代下去。
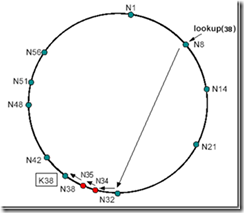
例如:节点N8寻找K54这个资源
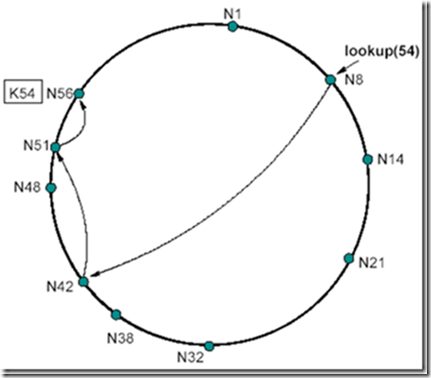
首先,在N8上查找后继节点为N14,发现K54并不符合54є (8; 14]的要求,那么直接在N8的路由表上查找符合这个要求的表项(由远及近查找),此时N8的路由表为:
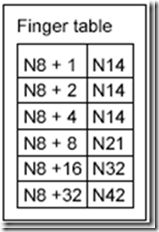
我们发现路由表中最远的一项N8+32--N42满足42є (8; 54],则说明N42这个点离持有K54这个资源的节点最近(因为N42在该路由表中离N8这个节点最远),那么此时跳到N42这个节点上继续查找。N42的后继节点为N48,不符合54є (42; 48]的要求,说明N48不持有资源54,此时,开始在N42的路由表上查找:
N42节点的路由表为:

我们由远及近开始查找,发现N42+8--N51满足51є (42; 54],则说明N51这个点离持有K54这个资源的节点最近,那么此时跳到N51这个节点上继续查找。N51节点的后继节点为N56,符合54є (51; 56],此时定位完成,N56持有资源节点K54。
用伪代码表示:
// 查询节点n后继节点。
n.find_successor(id)
if (id є (n; successor])
return successor;
else n0 = closest_preceding_node(id);
return n0.find successor(id);
// search the local table for the highest
// predecessor of id
n.closest_preceding_node(id)
for i = m downto 1
if (finger[i] є (n; id))
return finger[i];
return n;
经证明,最多经过O(log N)次查找就能找到一个资源。
3.Chord的节点加入
Chord通过在每个节点的后台周期性的进行stabilization询问后继节点的前序节点是不是自己来更新后继节点以及路由表中的项。
有三个操作:
join(n0) :n加入一个Chord环,已知其中有一个节点n0.
Stabilize(): n查询其后继节点的前序节点P来决定P是否应该是n的后续节点,也就是说当p不是n本身时,说明p是新加入的,此时将n的后继节点设置为p。
Notify(n0): n0通知n它的存在,若此时n没有前序节点或,n0比n现有的前序节点更加靠近n,则n将其设置为前序节点。
Fix_fingers(): 修改路由表。
具体的,例如:
这是原先的结构:
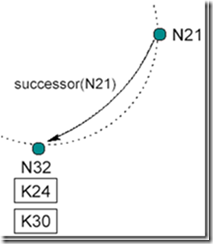
现在N26节点要加入系统,首先它指向其后继N32,然后通知N32,N32接到通知后将N26标记为它的前序节点(predecessor)。如下图:
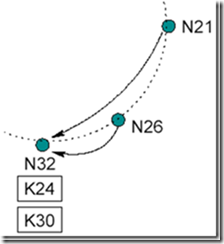
然后N26修改路由表,如下图:
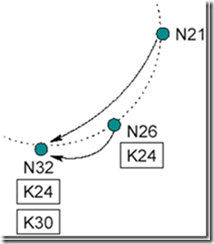
下一次N21运行stabilize()询问其后继节点N32的前序节点是不是还是自己,此时发现N32的前序节点已经是N26:
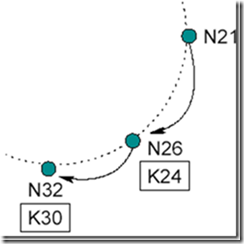
于是N21就将后继节点修改为N26,并通知N26自己已经将其设置为后继节点,N26接到通知后将N21设置为自己的前序节点。
这个加入操作会带来两方面的影响:
1)正确性方面:当一个节点加入系统,而一个查找发生在stabilization结束前,那么此时系统会有三个状态:
A.所有后继指针和路由表项都正确时:对正确性没有影响。
B.后继指针正确但表项不正确:查找结果正确,但速度稍慢(在目标节点和目标节点的后继处加入非常多个节点时)。如下图:
C.后继指针和路由表项都不正确:此时查找失败,Chord上层的软件会发现数据查找失败,在一段时间后会进行重试。
总结一下:节点加入对数据查找没有影响。
2)效率方面:当stabilization完成时,对查找效率的影响不会超过O(log N) 的时间。当stabilization未完成时,在目标节点和目标节点的后继处加入非常多个节点时才会有性能影响。可以证明,只要路由表调整速度快于网络节点数量加倍的速度,性能就不受影响。
4.Chord节点失败的处理
我们可以看出,Chord依赖后继指针的正确性以保证整个网络的正确性。但如图,若N14, N21, N32同时失效,那么N8是不会知道N38是它新的后继节点。为了防止这样的情况,每个节点都包含一个大小为r的后继节点列表,一个后续节点失效了就依次尝试列表中的其他后继节点。可以证明,在失效几率为1/2的网络中,寻找后继的时间为O(log N) 。
5.Chord的特征和应用
特征:去中心化,高可用度,高伸缩性,负载平衡,命名灵活。
应用:全球文件系统、命名服务、数据库请求处理、互联网级别的数据结构、通信服务、事件通知、文件共享。
参考文献:
Chord项目网址:http://pdos.csail.mit.edu/chord/
http://net.chinaunix.net/8/2008/07/28/1231438.shtml
Chord算法的更多相关文章
- Chord算法(原理)
Chrod算法是P2P中的四大算法之中的一个,是有MIT(麻省理工学院)于2001年提出,其它三大算法各自是: CAN Pastry Tapestry Chord的目的是提供一种能在P2P网络高速定位 ...
- Chord算法实现具体
背景 Chord算法是DHT(Distributed Hash Table)的一种经典实现.下面从网上无节操盗了一段介绍性文字: Chord是最简单.最精确的环形P2P模型."Chord&q ...
- 一致性hash算法简介
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简单哈希 ...
- chord原理的解读
chord: A Scalable Peer-to-peer Lookup Service for Internet Application 在 P2P 系统中,有效地定位分布在网络中不同节点的数据资 ...
- hash一致性算法
一致性hash算法是,1097麻省理工提出的分布式hashDHT实现算法,极倔internet的热点问题 平衡性 hash结果尽可能的分布到所有的缓存中去,缓冲空间利用率最高 单调性 保持已有的缓存能 ...
- [转载] nosql 数据库的分布式算法
原文: http://juliashine.com/distributed-algorithms-in-nosql-databases/ NoSQL数据库的分布式算法 On 2012年11月9日 in ...
- 一个轻client,多语言支持,去中心化,自己主动负载,可扩展的实时数据写服务的实现方案讨论
背景 背景是设计一个实时数据接入的模块,负责接收client的实时数据写入(如日志流,点击流),数据支持直接下沉到HBase上(兴许提供HBase上的查询),或先持久化到Kafka里.方便兴许进行一些 ...
- 强一致性hash实现java版本及强一致性hash原理
一致性 hash 分布式过程中我们将服务分散到若干的节点上,以此通过集体的力量提升服务的目的.然而,对于一个客户端来说,该由哪个节点服务呢?或者说对某个节点来说他分配到哪些任务呢? 强哈希 考虑到单服 ...
- NoSQL数据库的分布式算法
本文译自 Distributed Algorithms in NoSQL Databases 系统的可扩展性是推动NoSQL运动发展的的主要理由,包含了分布式系统协调,故障转移,资源管理和许多其他特性 ...
随机推荐
- C语言 文件操作9--fgetc()和fputc()
//fgetc()和fputc() #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<stdlib.h> # ...
- js计算两个日期相隔几小时几分钟?
var dt1 = "2009-11-5 10:30" var dt2 = "2009-11-8 9:20" function ge ...
- C#模拟POST提交表单(一)--WebClient
C#的提交表单方式主要有两种WebClient与HttpWebRequest,这里先介绍一种 WebClient,转送门:http://msdn.microsoft.com/zh-cn/library ...
- $self $index $first $last parent() outerParent()
index5.html <html><head> <title>$self $index $first $last parent() outerParent()&l ...
- Bootstrap系列 -- 26. 下拉菜单标题
Bootstrap下拉菜单中使用 dropdown-header 来显示菜单标题,和上一篇说道的分割线一样 <div class="dropdown"> <but ...
- 记<<ssh穿透防火墙连接内网的机器(不用路由端口映射)>>
场景: 在家连接公司的内网服务器. 需求: 不用设置端口映射在家用putty登录公司内网服务器. 条件: 有一台公网服务器做转发,有开放端口的控制权.(公网服务器可以是阿里云ECS, 腾讯云主机这样的 ...
- [C#]Attribute特性(3)——AttributeUsage特性和特性标识符
相关文章 [C#]Attribute特性 [C#]Attribute特性(2)——方法的特性及特性参数 AttributeUsage特性 除了可以定制自己的特性来注释常用的C#类型外,您可以用At ...
- Moqui之时间转换
<script><![CDATA[ if (fromDate == null && thruDate == null && year &&am ...
- 今天学习到的关于mysql数据库的linux命令
1. 登录mysql数据库: mysql -uroot -p 2.安装会提示的mysql的数据库软件:mycli sudo apt-get install mycli 3.安装依赖包: sudo ap ...
- java多线程-Condition
Condition 将 Object 监视器方法(wait.notify 和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待 set ...