学习笔记64_k邻近算法
1 .假定已知数据的各个属性值,以及其类型,例如:
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类别 |
| m1 | 3 | 104 | 爱情片 |
| m2 | 2 | 100 | 爱情片 |
| m3 | 1 | 81 | 爱情片 |
| m4 | 2 | 90 | 爱情片 |
| w1 | 101 | 10 | 动作片 |
| w2 | 99 | 5 | 动作片 |
| w3 | 98 | 2 | 动作片 |
上述数据称为训练数据。
如果有新的电影, k1 , 18 , 90 ,未知
| 电影名称 | 与未知电影的距离 |
| m1 | 20.5 |
| m2 | 18.7 |
| m3 | 19.2 |
| m4 | 21 |
| w1 | 115.3 |
| w2 | 117.4 |
| w5 | 118.9 |
距离 : 通过一定的计算方法获得 , 总体来说,距离 = f (k1打斗镜头,k1接吻镜头,m1打斗镜头,m1接吻镜头)
如果 k1与 某些电影 最接近,这里,就是3个电影最接近, 所以K1为爱情片,这里K可以为3,或2 ,或1都行。
***如果出现了距离为 50的片1部,它既不是爱情片,也不是动作片,那么,由于
K邻近算法:
1.存在一个样本数据集合, 且样本中,每个数据都存在标签(已经分好类)
2.输入没有标签的新数据后(没有分类的),将新数据的每个特征值,使用一定的办法,与样本中的特征进行比较,然后提取出那些最近似(距离最小)的数据的类型,其中出现最多的类型,作为自己的类型。
***** 一般来说,如果有大量的数据的时候,只需要遍历出K个距离足够小的样本,然后从样本中,选择出现类型最多的分类,作为新数据的分类。
关键点:
1.K的取值(根据数据量,以及各个分类占有的百分比取)。
2.距离如何计算。
3.如何界定距离足够小。
*************************************************************************************************
使用K近邻算法,进行简单的图形识别:
简单: 要识别的东西的特征比较明显;图片颜色有比较强的对比度;图片刚好括着要识别的东西;要识别的东西放得比较正 等等。
***若果不满足简单,那么就需要预处理,将图片简单化*****
假设有图片:

图片的数据是像素,假设图片的数据格式:
| (r11,g11,b11) | (r12,g12,b12) | (r13,g13,b13) | ... |
| (r21,g21,b21) | ... | ... | ... |
| (r31,g31,b31) | ... | ... | ... |
| ... | ... | ... | ... |
这样的数据结构,假设有大量图片,对每个图片:
第一步:读取图片数据,然后上述的数据结构。
第二步:归一化,如上图,颜色可以分为2类,选择 这个颜色的 RGB运算值为1,其他为0
这个颜色的 RGB运算值为1,其他为0
*实际上,每个训练数据的图片,颜色可能都是不一样的,可以使用聚类:
情况可能有如下: 1. 只有两种颜色,如果某种颜色的比例占少数,那么这个颜色运算值应该为1;
2. 三种以上颜色,如果某种颜色的比例占多数,那么这个颜色运算值应该为1;
(归一化的算法很多。)

第三步:形成 特征-分类:
*第n行值,是指第n行中,1的总数。
| 第1行值 | 第2行值 | 第3行值 | ... | 数字类型 |
| 5 | 9 | 10 | ... | 2 |
| 5 | 5 | 5 | ... | 1 |
| 6 | 8 | 11 | ... | 2 |
| ... | ... | ... | ... | 3 |
| ... | ... | ... | ... | 4 |
| ... | ... | ... | ... | ... |
算法使用:
1.如果要识别新的图片,首先要执行上面 一,二,三部;
2.求距离:
d = Math.sqrt( d1² + d2² + ............ )
遍历出K个距离足够小的 样本
3. 在K个样本中,找出“数字类型”出现最多的 类型,作为 新的图片 所识别的数字。
除了使用MSQ(均方差,也就是d平方)的方法外,对于样本属于哪一类,还有使用夹角来衡量:
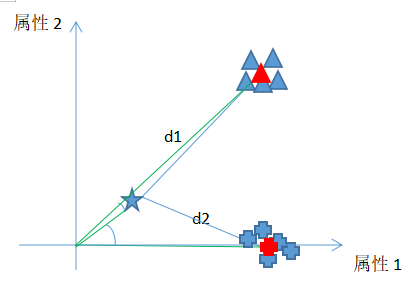
假如属性1为数学成绩,属性2位语文成绩,三角形为“均衡生”,而加号为“偏科生”,那么,要认定星号样本属于“均衡生”还是“偏科生”,
显然应该是“均衡生”,但是d1>d2,所以用空间夹角最好(联想向量点积计算)。
补充一点,这个“距离”,其实可以联想到神经网络中的“损失函数”
学习笔记64_k邻近算法的更多相关文章
- GMM高斯混合模型学习笔记(EM算法求解)
提出混合模型主要是为了能更好地近似一些较复杂的样本分布,通过不断添加component个数,能够随意地逼近不论什么连续的概率分布.所以我们觉得不论什么样本分布都能够用混合模型来建模.由于高斯函数具有一 ...
- 强化学习-学习笔记7 | Sarsa算法原理与推导
Sarsa算法 是 TD算法的一种,之前没有严谨推导过 TD 算法,这一篇就来从数学的角度推导一下 Sarsa 算法.注意,这部分属于 TD算法的延申. 7. Sarsa算法 7.1 推导 TD ta ...
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
- 【学习笔记】 Adaboost算法
前言 之前的学习中也有好几次尝试过学习该算法,但是都无功而返,不仅仅是因为该算法各大博主.大牛的描述都比较晦涩难懂,同时我自己学习过程中也心浮气躁,不能专心. 现如今决定一口气肝到底,这样我明天就可以 ...
- 挑子学习笔记:DBSCAN算法的python实现
转载请标明出处:https://www.cnblogs.com/tiaozistudy/p/dbscan_algorithm.html DBSCAN(Density-Based Spatial Clu ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- R语言学习笔记—K近邻算法
K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.即每个样本都可以用它最接近的k个邻居来代表.KNN算法适 ...
- 普通平衡树学习笔记之Splay算法
前言 今天不容易有一天的自由学习时间,当然要用来"学习".在此记录一下今天学到的最基础的平衡树. 定义 平衡树是二叉搜索树和堆合并构成的数据结构,它是一 棵空树或它的左右两个子树的 ...
- 【算法学习笔记】Meissel-Lehmer 算法 (亚线性时间找出素数个数)
「Meissel-Lehmer 算法」是一种能在亚线性时间复杂度内求出 \(1\sim n\) 内质数个数的一种算法. 在看素数相关论文时发现了这个算法,论文链接:Here. 算法的细节来自 OI w ...
随机推荐
- MySQL数据库从复制及企业配置实践
在实际生产中,数据的重要性不言而喻: 如果我们的数据库只有一台服务器,那么很容易产生单点故障的问题,比如这台服务器访问压力过大而没有响应或者奔溃,那么服务就不可用了,再比如这台服务器的硬盘坏了,那么整 ...
- 在 Vue-cli 创建的项目中引入 Element-UI
Element-UI 是饿了么前端团队退出了一套基于 vue.js 开发的 UI 组件库,在与 Vue-cli 创建的项目结合时,需要做以下配置: 1. 安装 loader 模块 cnpm insta ...
- [Note] 解决使用Workerman和apache创建wss服务时出现的 Error during WebSocket handshake: net::ERR_RESPONSE_HEADERS_TRUNCATED
使用apache代理生成的wss服务常出现 Error during WebSocket handshake: net::ERR_RESPONSE_HEADERS_TRUNCATED 的问题,但多刷新 ...
- MongoDB 学习笔记之 GridFS
GridFS: GridFS 是 MongoDB 的一个用来存储/获取大型数据(图像.音频.视频等类型的文件)的规范.它相当于一个存储文件的文件系统,但它的数据存储在 MongoDB 的集合中.Gri ...
- JavaSE----02.Java语言基础
02.Java语言基础 1.关键字 Java关键字是电脑语言里事先定义的,有特别意义的标识符,有时又叫保留字,还有特别意义的变量.Java的关键字对Java的编译器有特殊的意义,他们用来表示一 ...
- 【SQL】 收入支出求盈亏
求项目ID为1000的盈亏 表名为:T 字段:ID P_ID AMOUNT TYPE(1:收入 2:支出) '
- 【NOIP2009】道路游戏
Description 小新正在玩一个简单的电脑游戏. 游戏中有一条环形马路,马路上有 nn 个机器人工厂,两个相邻机器人工厂之间由一小段马路连接.小新以某个机器人工厂为起点,按顺时针顺序依次将这 n ...
- Python3实战spark大数据分析及调度 ☝☝☝
Python3实战spark大数据分析及调度 ☝☝☝ 一.实例分析 1.1 数据 student.txt 1.2 代码 二.代码解析 2.1函数解析 2.1.1 collect() RDD的特性 在 ...
- netty源码解解析(4.0)-25 ByteBuf内存池:PoolArena-PoolChunk
PoolArena实现了用于高效分配和释放内存,并尽可能减少内存碎片的内存池,这个内存管理实现使用PageRun/PoolSubpage算法.分析代码之前,先熟悉一些重要的概念: page: 页,一个 ...
- [JZOJ5778]【NOIP提高A组模拟2018.8.8】没有硝烟的战争
Description 被污染的灰灰草原上有羊和狼.有N只动物围成一圈,每只动物是羊或狼.该游戏从其中的一只动物开始,报出[1,K]区间的整数,若上一只动物报出的数是x,下一只动物可以报[x+1,x+ ...