ASRWGAN: Wasserstein Generative Adversarial Network for Audio Super Resolution
ASEGAN:WGAN音频超分辨率
这篇文章并不具有权威性,因为没有发表,说不定是外国的某个大学的毕业设计,或者课程结束后的作业、或者实验报告。
CS230: Deep Learning, Spring 2018, Stanford University, CA. (LateX template borrowed from NIPS 2017.)
作者:Jonathan Gomes-Selman, Arjun Sawhney, WoodyWang
摘要
本文提出使用Wasserstein(沃瑟斯坦)生成对抗网络来提高现有神经网络的性能,训练神经网络来执行音频超分辨率任务。受SRGAN[3]的启发,我们利用一个预先训练过的ASRNet版本,如Kuleshov等人描述的模型[2],作一个全卷积鉴别器模型的生成器。我们对生成器使用一个自适应的损失函数,将content loss内容损失(生成器输出和对应的真实音频信号之间的MSE)与传统的对抗性损失相加。结果表明,该模型在信噪比(SNR)和对数谱距离(LSD)两方面均优于bicubic interpolation(双三次插值)基线。与ASRNet相比,我们的模型在LSD度量上表现出了更强的性能,并且我们的模型重构低分辨率信号的更高频率而降低了信噪比。ASRNet和我们的模型在MUSHRA测试中都达到了近乎相同的性能,该测试结合了人类对产生的音频信号清晰度的感知,并且都显著优于基线。
1 引言
随着个人助理系统和音频数据的兴起,对技术设备的听觉输入变得越来越普遍;然而,考虑到声音的粗糙性和可变性以及录音设备的细微差别,以音频作为输入的系统常常不得不处理质量较差的音频,有时必须重新确认或重复询问相同的问题来解释输入语音。因此,如果一个网络能够以质量较差的音频作为输入,在不需要用户确认或重复的情况下增强或解析它,就可以改善个人助理和其他使用音频数据通知操作的技术的体验。
考虑到这个动机,我们提出了改进现有的模型,执行语音带宽扩展,一种特定形式的音频超分辨率。从一个下采样的版本低质量音频,通过重建,生成高质量的音频,如[2]所述。考虑到SRGAN[3]利用生成对抗网络(GAN)对现有的图像超分辨率模型进行改进的成功,我们提出了一种改进的Wasserstein GAN体系结构来增强由[2]引入的音频超分辨率模型ASRNet。通过将改进后的ASRNet作为生成器与深度卷积鉴频器耦合,我们的ASRWGAN结果显示了使用GANs增强当前音频超分辨率方法的前景。
2 相关工作
我们的灵感来自于各种音频和非音频相关的深度学习方法。从根本上说,正如前面提到的,我们项目的主要目标是改进现有的用于音频超分辨率的深度残差啊网络(ASRNet)的性能。ASRNet是由[2]提出的,它借鉴了前人对图像超分辨率的研究成果,将其建模为具有残差跳跃连接的深度卷积神经网络。ASRNet已被证明大大优于传统插值技术,并为音频超分辨率提供了一个有前途的实时网络架构。
我们提出了一个模型来进一步提高ASRNet的性能,结合了生成对抗网络的优点。正如[2]所指出的,音频超分辨率的任务在很大程度上反映了图像超分辨率的任务。因此,我们提出的模型和方法与SRGAN[3]中提出的模型和方法密切相关。SRGAN是一种用于图像超分辨率的GAN,在大缩放因子下超分辨率图像的表现优于现有的先进体系结构。
在开发我们的GAN架构时,我们也从Wave- GAN[1]的实现中得到了灵感。WaveGAN探索了使用全卷积架构进行音频合成的问题,而不是使用与时间序列建模密切相关的RNNs。WaveGAN的性能展示了将卷积模型应用于一维时间序列数据的潜力,这是我们在这里进一步研究的一种方法。
3 数据集和特征
我们使用的数据来自语音与技术研究中心[5]提供的CSTR VCTK语料库。这个数据集包括109个母语为英语的人的语音数据,每个人背诵大约400个英语句子,尽管我们只是为了效率和计算时间的限制而对单个演讲者的数据进行培训。顺便说一句,我们注意到,在未来的应用中,我们可以预见到为Skype或Alexa等服务中的单说话人专门训练的音频超分辨率模型。数据采用WAV文件格式,我们使用Python的librosa库将其转换为一个numpy数组,固定采样率为16000Hz。我们将音频信号表示为函数$f(t):[0,T]-->R$,其中$f(t)$是$t$处的振幅,$t$是信号的时间长度。为了将连续信号作为输入进行处理,必须将$f(t)$离散为向量$x(t):[\frac{1}{R},\frac{2}{R},...,\frac{RT}{R}]$,其中R为输入音频的采样率,单位为Hz。
为了标准化输入长度,我们从数据集中的语音中抽取半秒的patch作为样本,经过预处理得到shape为(8192,1)的向量。然后我们随机打乱这些向量,并执行以下的训练/测试数据集分割
训练集: 3328 样本, 测试集: 500 样本
我们使用Chebyshev低通滤波器对每个高分辨率的语音进行预处理,将初始信号抽取为低分辨率的等长信号,并将其作为生成器网络的输入。基线我们采用双三次插值方法进行音频超分辨率任务。
4 方法及最终模型
如图1所示,我们提出的模型灵感主要来源于三个主要模型:SRGAN[3]、wave-GAN[1]和ASRNet[2]。密切关注我们的一般方法SRGAN中提出的方法,其中包括使用pre-trained生成器网络(ASRNet)来避免局部最小值和在生成器丢失中加入内容损失成份,通过提供有关手头实际任务的领域知识(超分辨率)来提高性能。对于GAN体系结构的生成器和鉴别器,我们分别使用了修改后的ASRNet和WaveGAN鉴别器。我们选择WaveGAN 鉴别器是因为它在音频时间序列数据上的表现,这在很大程度上关系到长一维卷积滤波器能否成功捕捉到声音的周期性。
在我们的架构研究中,我们主要关注两种类型的GAN,即寻常 GAN和Wasserstein GAN (WGAN)[4]。我们最初的实现是一个普通的GAN,使用传统的GAN训练技术,比如使用非饱和成本函数,以及Leaky Relu非线性激活函数(如CS230课程中所述)等。然而,这个模型在训练时表现出模式崩溃、爆炸梯度和不同的损失,因此我们转向WGAN以获得更大的训练稳定性。

图1:调整后超参数的ASR-WGAN架构
WGAN通过重新定义损失函数、合并权重剪裁、降低学习速度和使用非基于动量的优化器(RMS Prop)来适应普通的GAN。正如在[4]中提到的,这些更改允许更可靠的梯度反向传播到生成器,同时保持参数值较小,以防止出现模型崩溃等问题
修改后的损失函数
$$公式1:Discriminator\_Loss=max_DE_{x\sim p_x}[D(x)]-E_{z\sim p_z}[D(G(z))]$$
根据[4]中描述的WGAN训练算法,鉴别器不再训练来识别真实和预测的例子,而是训练来计算Wasserstein沃瑟斯坦距离
$$公式2:Generator\_Loss=\frac{1}{n}||x-G(z)||_2^2+\lambda max_GE_{z\sim p_z}[D(G(z))]$$
我们修改了[4]中提出的生成器损失,由于在[3]中类似方法的成功,所以在传统对抗性损失的基础上加入内容损失。我们使用预测和真实示例之间的MSE(均方误差)来提供关于实际任务目标(超分辨率)的领域知识,以及一个额外的超参数$\lambda$来平衡内容损失和对抗性损失。具体地说,我们用$\lambda$来控制我们的模型对内容丢失的优化
5 结构与讨论
度量:根据Kuleshov等人的研究[2],我们使用信噪比和对数谱距离作为度量。给定一个目标信号$y$和重建$x$,信噪比和LSD定义如方程(3)和(4)所示,其中$X$和$\hat{X}$是$x$和$y$的对数谱功率大小,它被定义为$X=\log |S|^2$, $S$是短时傅里叶变换的信号,和$l,k$分别为index指标帧和频率。
$$公式3:SNR(x,y)=10\log \frac{||y||_2^2}{||x-y||_2^2}$$
$$公式4:LSD(x,y)=\frac{1}{L}\sum_{l=1}^L\sqrt{\frac{1}{K}\sum_{k=1}^K(X(l,k)-\hat{X}(l,k))^2}$$
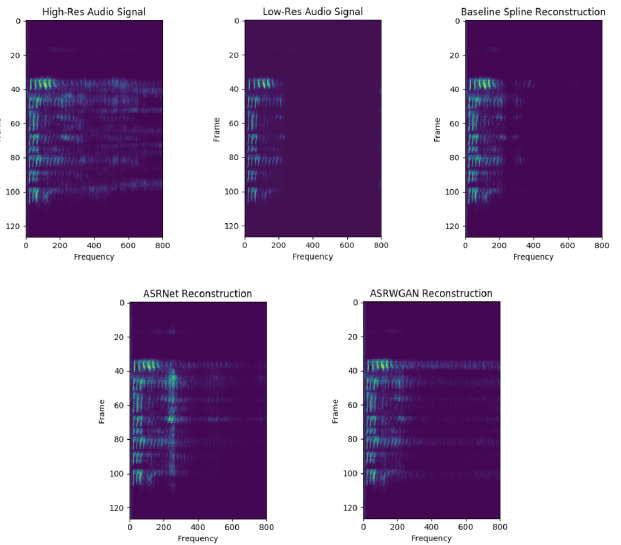
图2:来自各种重建方法的语音语谱图
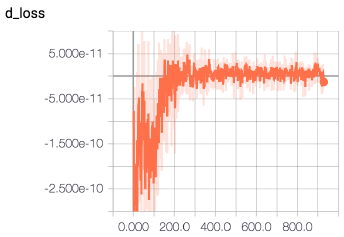
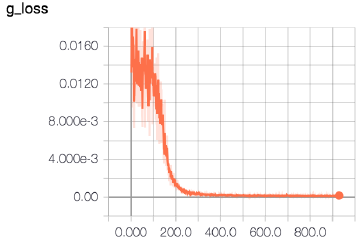
图3:鉴别器和生成器的损失曲线,y轴上分别为损失值,x轴上为小批量迭代次数
估计:如图2所示。与基线双三次插值或样条重建相比,我们的ASRWGAN重建显示出在解决更高频率的显着改善。相对于ASRNet,我们的ASR-WGAN仍然可以恢复更多的高频率,但是会出现一些原始高分辨率语音中不存在的无关噪声,这可以通过保存更多的预训练生成器模型来解决。
从表1和表2的客观指标来看,我们看到信噪比略有下降,大约为1-2 dB,但LSD有所改善(减少)。LSD指标比信噪比指标[2]更能分辨更高的频率。在仔细检查了epochs 1-5所保存的权重之后,信噪比显著下降到~ 5,这表明利用预先训练好的网络的好处正在减少,这可能是由于我们的鉴别器和生成器之间的性能差距造成的。然而,我们看到基线性能在短短40个周期内快速恢复和改进。因此,尽管与ASRNet生成器相比,我们似乎引入了更多的噪声,但作为权衡,我们恢复了更多的高频。
| Objective Metrics | Spline | ASRNet | ASR-WGAN |
| SNR | 14.8 | 17.1 | 15.7 |
| log Spectral Distance | 8.2 | 3.6 | 3.3 |
表1:在上缩放比率为4时候的音频超分辨率方法的客观评价
| MUSHRA | Sample 1 | Sample 2 | Sample 3 | Sample 4 |
| ASR-WGAN | 70 | 61 | 73 | 68 |
| ASRNet | 67 | 63 | 75 | 68.3 |
| SPline | 42 | 34 | 36 | 37.3 |
表2:对每个音频样本的平均MUSHRA用户打分
在添加了权重和梯度裁剪并过渡到WGAN之后,我们避免了模型崩溃,并在训练中看到了改进的稳定性,如图3中我们的损失曲线所示。我们可以看到,当鉴别器在连续的迭代中不断更新时,生成器的损失稳步下降。
根据Kuleshov等人[2]的工作建议,然后我们通过询问10名受过训练的音乐家,让他们使用MUSHRA(带有隐藏参考和锚点的多个因素)测试来评估重建的总体质量。我们从VCTK单说话人数据集中随机选取三个音频样本,对样本进行降采样,然后使用双三次样条插值、ASRNet和我们的ASRWGAN重构样本。然后,我们要求每位受试者给每个样本打分,分值从0(糟糕)到100(完美)。实验结果见表2所示。我们看到我们的ASR-WGAN重建评分明显高于样条,但ASRNets和ASRWGAN重建之间的差异不那么明显。
6 结论与未来的工作
我们介绍了一种新的音频超分辨率的深层架构。我们的方法是新颖的,因为它结合了SRGAN, Wave-GAN和ASRNet。与传统评价方法相比,实证评价方法的性能有所提高。
特别适用于生成音频信号的高频分量。与传统方法相比,MUSHRA评估的最终结果也优于传统方法。我们的架构中同时使用了普通的GAN和WGAN。我们最终选择了WGAN,由于它的学习速度更小,损失函数更小,并且增加了权重和梯度剪切,提高了训练的稳定性,所以更适合我们的问题。
我们最强的模型,命名为ASR-WGAN,在信噪比(SNR)和对数光谱距离(LSD)方面都比传统的双三次插值方法表现出更强的性能,同时在LSD度量上表现出更强的性能,与ASRNet相比信噪比降低。我们认为这些结果与我们的模型试图重建输入音频信号的最高频率的观察结果是一致的,这可能是音频超分辨率最具挑战性的部分。该模型以不连续的形式对预测的输出信号引入了一些噪声。在定性上,MUSHRA实验表明,输出信号的清晰度与ASRNet相当,且远优于我们的基线模型。
未来工作:我们假设ASRWGAN的结构,特别是鉴别器和生成器之间的初始性能差距,导致ASRWGAN不能充分利用生成器的初始预训练状态。鉴于此,我们未来工作的第一个行动是通过引入跳过连接和残差单元使我们的识别器更具表现力,并调整鉴别器与生成器的训练比例。此外,我们打算对生成器上的损失函数进行实验,特别是内容损失,以便更好地反映优化人类耳朵性能的最终目标。给定更多的计算时间,一个自然的扩展将是在VCTK数据集中的多个扬声器上训练我们的模型,并执行更彻底的超参数搜索,以找到权值剪切边界。
7 贡献
每个团队成员对项目的贡献是平等的。Jonathan编写了大部分代码来创建ASRWGAN的体系结构。Woody编写代码在AWS实例上训练和测试模型。Arjun在分析音频和图像超分辨率领域现有GAN实现的基础上,对数据集进行预处理,并对GAN体系结构进行调整和实现。所有团队成员都认真阅读了相关论文,提高了团队的工作效率,花时间调试和重构代码,并在最终报告的撰写中做出了同等的贡献。
8 致谢
我们要感谢Volodymyr Kuleshov对我们整个项目的支持,帮助我们理解他最初的models架构。我们也要感谢Ahmad Momeni, Brandon Yang和CS230的全体教师帮助我们实施和理解我们的ASRWGAN。
9 代码
项目代码可在https://github.com/jonathangomesselman/CS230-Project中找到
参考文献
[1] Donahue, Chris et al. Synthesizing Audio with Generative Adversarial Networks in arXiv, 2018.
[2] Kuleshov, Volodymyr et al. Audio Super Resolution with Neural Networks in arXiv (Workshop Track) 2017.
[3] Ledig, Christian et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network in arXiv 2017.
[4] Arjovsky, Martin et al. Wasserstein GAN in ICML, 2017.
[5] English Multi-speaker Corpus for CSTR Voice Cloning Toolkit, 2010.
[6] Abadi, Martín et al. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org, 2015. 6
ASRWGAN: Wasserstein Generative Adversarial Network for Audio Super Resolution的更多相关文章
- Speech Super Resolution Generative Adversarial Network
博客作者:凌逆战 博客地址:https://www.cnblogs.com/LXP-Never/p/10874993.html 论文作者:Sefik Emre Eskimez , Kazuhito K ...
- 论文阅读之:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network 2016.10.23 摘要: ...
- Face Aging with Conditional Generative Adversarial Network 论文笔记
Face Aging with Conditional Generative Adversarial Network 论文笔记 2017.02.28 Motivation: 本文是要根据最新的条件产 ...
- 生成对抗网络(Generative Adversarial Network)阅读笔记
笔记持续更新中,请大家耐心等待 首先需要大概了解什么是生成对抗网络,参考维基百科给出的定义(https://zh.wikipedia.org/wiki/生成对抗网络): 生成对抗网络(英语:Gener ...
- GAN Generative Adversarial Network 生成式对抗网络-相关内容
参考: https://baijiahao.baidu.com/s?id=1568663805038898&wfr=spider&for=pc Generative Adversari ...
- 论文阅读:Single Image Dehazing via Conditional Generative Adversarial Network
Single Image Dehazing via Conditional Generative Adversarial Network Runde Li∗ Jinshan Pan∗ Zechao L ...
- DeepPrivacy: A Generative Adversarial Network for Face Anonymization阅读笔记
DeepPrivacy: A Generative Adversarial Network for Face Anonymization ISVC 2019 https://arxiv.org/pdf ...
- 《MIDINET: A CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORK FOR SYMBOLIC-DOMAIN MUSIC GENERATION》论文阅读笔记
出处 arXiv.org (引用量暂时只有3,too new)2017.7 SourceCode:https://github.com/RichardYang40148/MidiNet Abstrac ...
- GAN (Generative Adversarial Network)
https://www.bilibili.com/video/av9770302/?p=15 前面说了auto-encoder,VAE可以用于生成 VAE的问题, AE的训练是让输入输出尽可能的接近, ...
随机推荐
- Convolution model by吴恩达
# GRADED FUNCTION: model def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.009, num_epoc ...
- idea取消大小写自动提示
file-settings 取消勾选Match case
- 大数据平台搭建 - cdh5.11.1 - hbase集群搭建
一.简介 HBase是一种构建在HDFS之上的分布式.面向列的存储系统.在需要实时读写.随机访问超大规模数据集时,可以使用HBase. 尽管已经有许多数据存储和访问的策略和实现方法,但事实上大多数解决 ...
- selenium WebDriver 截取网站的验证码
在做爬虫项目的时候,有时候会遇到验证码的问题,由于某些网站的验证码是动态生成的,即使是同一个链接,在不同的时间访问可能产生不同的验证码, 一 刚开始的思路就是打开这个验证码的链接,然后通过java代码 ...
- PopupWindow弹出框
使用PopupWindow实现一个悬浮框,悬浮在Activity之上,显示位置可以指定 首先创建pop_window.xml: <?xml version="1.0" enc ...
- 语音信号的梅尔频率倒谱系数(MFCC)的原理讲解及python实现
梅尔倒谱系数(MFCC) 梅尔倒谱系数(Mel-scale FrequencyCepstral Coefficients,简称MFCC).依据人的听觉实验结果来分析语音的频谱, MFCC分析依据的听觉 ...
- Spring入门教程
Spring新手入门教程,配套下面这两个大神的课程就可以了. 一个是Spring视频教程. 一个是Spring博客教程. https://www.imooc.com/learn/196 http:// ...
- RabbitMQ的六种工作模式总结
最近学习RabbitMQ的使用方式,记录下来,方便以后使用,也方便和大家共享,相互交流. RabbitMQ的六种工作模式: 1.Work queues2.Publish/subscribe3.Rout ...
- svn新建文件不能提交的解决方法
svn新建文件不能提交的解决方法 在当前新建文件的目录下,右键空白处: 选择Properties 找到所有有ignore字眼的属性,查看这个属性的继承目录(inherited from),入我的是cl ...
- 【linux】【mysql】mysql主从数据库
系统环境:Centos7 主:192.168.8.162 从:192.168.8.127 前提条件 a.关闭防火墙 systemctl stop firewalld 关闭防火墙开机自启 system ...