Hadoop 系列(二)—— 集群资源管理器 YARN
一、hadoop yarn 简介
Apache YARN (Yet Another Resource Negotiator) 是 hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在 YARN 上,由 YARN 进行统一地管理和资源分配。
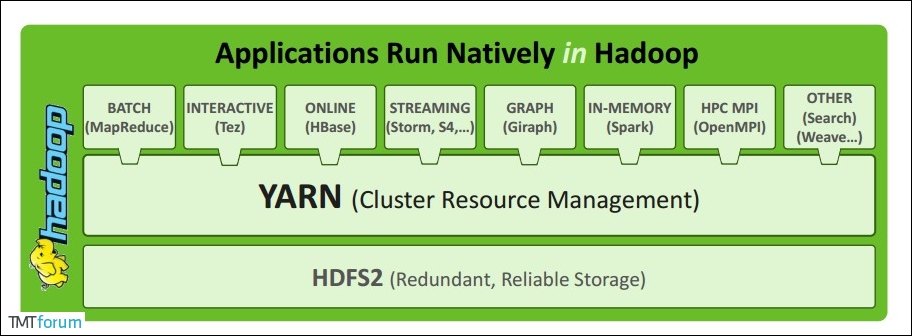
二、YARN架构
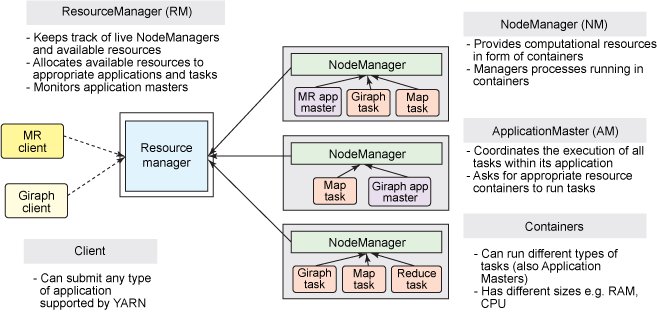
1. ResourceManager
ResourceManager 通常在独立的机器上以后台进程的形式运行,它是整个集群资源的主要协调者和管理者。ResourceManager 负责给用户提交的所有应用程序分配资源,它根据应用程序优先级、队列容量、ACLs、数据位置等信息,做出决策,然后以共享的、安全的、多租户的方式制定分配策略,调度集群资源。
2. NodeManager
NodeManager 是 YARN 集群中的每个具体节点的管理者。主要负责该节点内所有容器的生命周期的管理,监视资源和跟踪节点健康。具体如下:
- 启动时向
ResourceManager注册并定时发送心跳消息,等待ResourceManager的指令; - 维护
Container的生命周期,监控Container的资源使用情况; - 管理任务运行时的相关依赖,根据
ApplicationMaster的需要,在启动Container之前将需要的程序及其依赖拷贝到本地。
3. ApplicationMaster
在用户提交一个应用程序时,YARN 会启动一个轻量级的进程 ApplicationMaster。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器内资源的使用情况,同时还负责任务的监控与容错。具体如下:
- 根据应用的运行状态来决定动态计算资源需求;
- 向
ResourceManager申请资源,监控申请的资源的使用情况; - 跟踪任务状态和进度,报告资源的使用情况和应用的进度信息;
- 负责任务的容错。
4. Contain
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。当 AM 向 RM 申请资源时,RM 为 AM 返回的资源是用 Container 表示的。YARN 会为每个任务分配一个 Container,该任务只能使用该 Container 中描述的资源。ApplicationMaster 可在 Container 内运行任何类型的任务。例如,MapReduce ApplicationMaster 请求一个容器来启动 map 或 reduce 任务,而 Giraph ApplicationMaster 请求一个容器来运行 Giraph 任务。
三、YARN工作原理简述
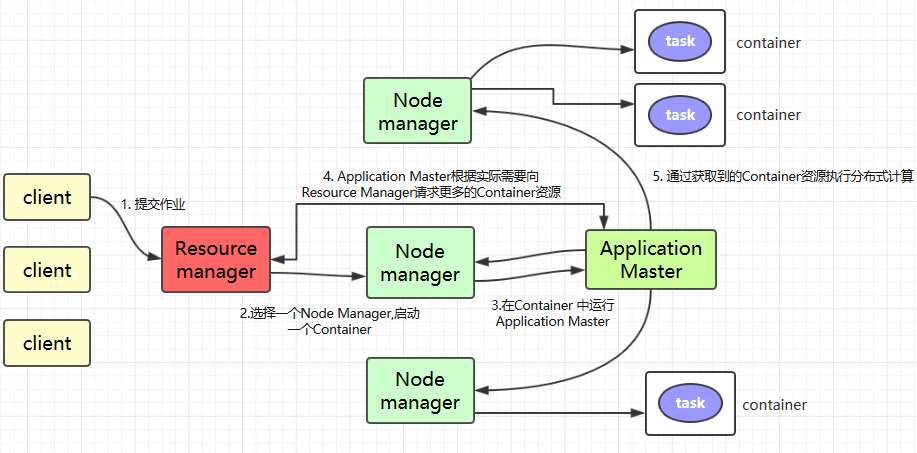
Client提交作业到 YARN 上;Resource Manager选择一个Node Manager,启动一个Container并运行Application Master实例;Application Master根据实际需要向Resource Manager请求更多的Container资源(如果作业很小, 应用管理器会选择在其自己的 JVM 中运行任务);Application Master通过获取到的Container资源执行分布式计算。
四、YARN工作原理详述
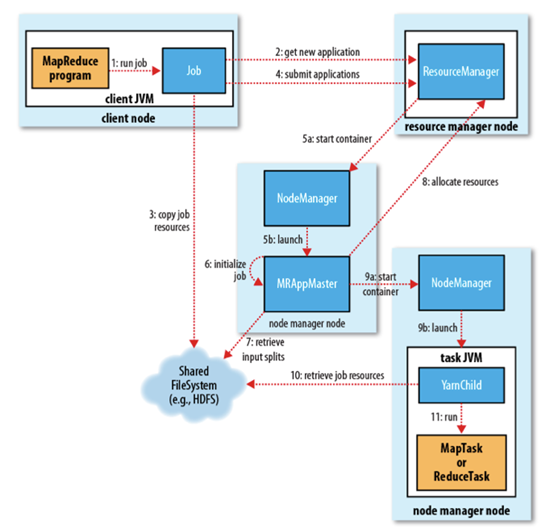
1. 作业提交
client 调用 job.waitForCompletion 方法,向整个集群提交 MapReduce 作业 (第 1 步) 。新的作业 ID(应用 ID) 由资源管理器分配 (第 2 步)。作业的 client 核实作业的输出, 计算输入的 split, 将作业的资源 (包括 Jar 包,配置文件, split 信息) 拷贝给 HDFS(第 3 步)。 最后, 通过调用资源管理器的 submitApplication() 来提交作业 (第 4 步)。
2. 作业初始化
当资源管理器收到 submitApplciation() 的请求时, 就将该请求发给调度器 (scheduler), 调度器分配 container, 然后资源管理器在该 container 内启动应用管理器进程, 由节点管理器监控 (第 5 步)。
MapReduce 作业的应用管理器是一个主类为 MRAppMaster 的 Java 应用,其通过创造一些 bookkeeping 对象来监控作业的进度, 得到任务的进度和完成报告 (第 6 步)。然后其通过分布式文件系统得到由客户端计算好的输入 split(第 7 步),然后为每个输入 split 创建一个 map 任务, 根据 mapreduce.job.reduces 创建 reduce 任务对象。
3. 任务分配
如果作业很小, 应用管理器会选择在其自己的 JVM 中运行任务。
如果不是小作业, 那么应用管理器向资源管理器请求 container 来运行所有的 map 和 reduce 任务 (第 8 步)。这些请求是通过心跳来传输的, 包括每个 map 任务的数据位置,比如存放输入 split 的主机名和机架 (rack),调度器利用这些信息来调度任务,尽量将任务分配给存储数据的节点, 或者分配给和存放输入 split 的节点相同机架的节点。
4. 任务运行
当一个任务由资源管理器的调度器分配给一个 container 后,应用管理器通过联系节点管理器来启动 container(第 9 步)。任务由一个主类为 YarnChild 的 Java 应用执行, 在运行任务之前首先本地化任务需要的资源,比如作业配置,JAR 文件, 以及分布式缓存的所有文件 (第 10 步。 最后, 运行 map 或 reduce 任务 (第 11 步)。
YarnChild 运行在一个专用的 JVM 中, 但是 YARN 不支持 JVM 重用。
5. 进度和状态更新
YARN 中的任务将其进度和状态 (包括 counter) 返回给应用管理器, 客户端每秒 (通 mapreduce.client.progressmonitor.pollinterval 设置) 向应用管理器请求进度更新, 展示给用户。
6. 作业完成
除了向应用管理器请求作业进度外, 客户端每 5 分钟都会通过调用 waitForCompletion() 来检查作业是否完成,时间间隔可以通过 mapreduce.client.completion.pollinterval 来设置。作业完成之后, 应用管理器和 container 会清理工作状态, OutputCommiter 的作业清理方法也会被调用。作业的信息会被作业历史服务器存储以备之后用户核查。
五、提交作业到YARN上运行
这里以提交 Hadoop Examples 中计算 Pi 的 MApReduce 程序为例,相关 Jar 包在 Hadoop 安装目录的 share/hadoop/mapreduce 目录下:
# 提交格式: hadoop jar jar包路径 主类名称 主类参数
# hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Hadoop 系列(二)—— 集群资源管理器 YARN的更多相关文章
- Hadoop 三剑客之 —— 集群资源管理器 YARN
一.hadoop yarn 简介 二.YARN架构 1. ResourceManager 2. NodeManager 3. ApplicationMa ...
- Hadoop 学习之路(二)—— 集群资源管理器 YARN
一.hadoop yarn 简介 Apache YARN (Yet Another Resource Negotiator) 是hadoop 2.0 引入的集群资源管理系统.用户可以将各种服务框架部署 ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop分布式资源管理器Yarn、MR运行机制剖析
介绍YARN组件的功能及应用场景 1.ResourceManager(RM) RM是一个全局的资源管理器,集群中只有一个.它负责整个Hadoop系统的资源管理和分配,包括处理客户端请求.启动监控 Ap ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- Hadoop+Hbase分布式集群架构“完全篇”
本文收录在Linux运维企业架构实战系列 前言:本篇博客是博主踩过无数坑,反复查阅资料,一步步搭建,操作完成后整理的个人心得,分享给大家~~~ 1.认识Hadoop和Hbase 1.1 hadoop简 ...
- Spark集群管理器介绍
Spark可以运行在各种集群管理器上,并通过集群管理器访问集群中的其他机器.Spark主要有三种集群管理器,如果只是想让spark运行起来,可以采用spark自带的独立集群管理器,采用独立部署的模式: ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
随机推荐
- Xmanager 5远程连接CentOS7图形化界面
1.安装Xmanager 5下载链接:https://pan.baidu.com/s/1JwBk3UB4ErIDheivKv4-NA提取码:cw04 双击xmgr5_wm.exe进行安装 点击‘下一步 ...
- python 基本数据类型之整数和布尔值
#1. 当前整数的二进制表示,以最少位数 # age = # print(age.bit_length()) #2. 获取当前数据的字节表示 # age = # v = age.to_bytes(,b ...
- Vs连接Mysql数据库
Vs连接Mysql数据库步骤 1. 首先下载mysql数据库,安装,建库建表 https://www.yiibai.com/mysql/getting-started-with-mysql-store ...
- APP系统架构设计初探
一,图片体验的优化. 在手机上显示图片,速度是一个非常重要的体验点,试想,如果您打开一个网站,发现里面的图片一直显示失败或者是x,稍微做得好一点的,可能是一个不消失的loading或者是菊花等等,但不 ...
- CMinpack使用介绍
github: https://github.com/devernay/cminpack 主页: http://devernay.github.io/cminpack/ 使用手册: http://de ...
- MyBatis从入门到精通:第二章数据的创建与插入文件
数据库表的创建: create table sys_user ( id bigint not null auto_increment, ), user_password ), user_email ) ...
- Docker实现GPA+Exporter监控告警系统
Docker实现GPA+Exporter监控告警系统 1.搭建grafana,prometheus,blackbox_exporter环境 # docker run -d -p 9090:9090 - ...
- Loadrunner基本概念解析<一>
学习性能测试前需要掌握的基本概念,以下做一个记录,本文会持续更新,我期望的是,用通俗简洁的语言来进行更好的理解. [基本概念如下:] ---并发用户数: 1️⃣错误的理解: 使用系统的全部用户数 ...
- Spring Cloud 之 Zuul基础.
一.概述 API 网关是一个更为智能的应用服务器,它的定义类似于面向对象设计模式中的 Facade 模式,它的存在就像是整个微服务架构系统的门面一样,所有的外部客户端访问都需要经过它来进行调度和过滤 ...
- Git设置忽略文件
在向代码仓库提交的时候,一般需要忽略掉一些文件或目录,比如Eclipse工程的配置文件,Maven工程的target目录,以及.log日志文件等等. 这个问题在Git中解决起来也很简单:在Git工作区 ...