决策树(基于增益率)之python实现
如图,为使用到的公式,信息熵表明样本的混乱程度,增益表示熵减少了,即样本开始分类,增益率是为了平衡增益准则对可取值较多的属性的偏好,同时增益率带来了对可取值偏小的属性的偏好,实际中,先用增益进行筛选,选取大于增益平均值的,然后再选取其中增益率最高的。
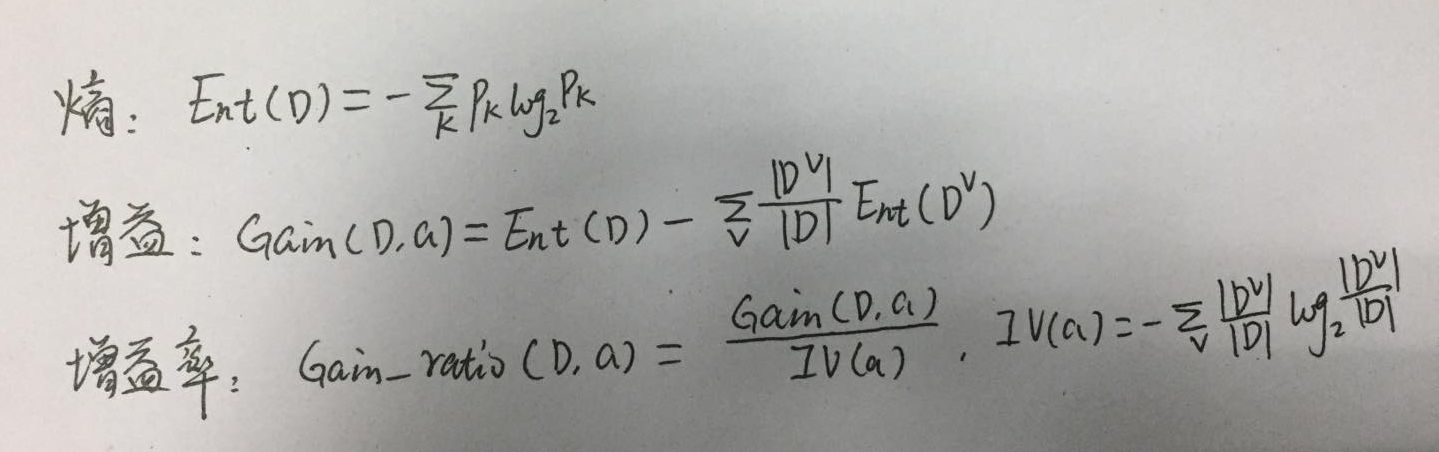
以下代码纯粹手写,未参考其他人代码,如果问题,请不吝赐教。
1,计算信息熵的函数
import numpy as np
# 计算信息熵
# data:like np.array
# data.shape=(num_data,data_features+1) 即属性与label放一起了
def entropy(data,num_class):
class_set=list(set(data[:,-1]))
result=0
length=len(data)
# 这里修改一下,不使用num_class
for i in range(len(class_set)):
l=len(data[data[:,-1]==class_set[i]])
p=l/length
result-=p*np.log2(p)
return result
2,计算增益及属性a的固有值(IV)
# 计算不同属性的信息增益
# detail_features:特征构成的list,每个特征的可取值构成list元素,即也是list
def calculate_gain(data,detail_features,num_class):
'''返回各属性对应的信息增益及平均值'''
result=[]
ent_data=entropy(data,num_class)
for i in range(len(detail_features)):
res=ent_data
for j in range(len(detail_features[i])):
part_data=data[data[:,i]==detail_features[i][j]]
length=len(part_data)
res-=length*entropy(part_data,num_class)/len(data)
result.append(res)
return result,np.array(result).mean()
# 计算某个属性的固有值
def IVa(data,attr_index):
attr_values=list(set(data[:,attr_index]))
v=len(attr_values)
res=0
for i in range(v):
part_data=data[data[:,attr_index]==attr_values[i]]
p=len(part_data)/len(data)
res-=p*np.log2(p)
return res
3,构建节点类,以便构建树
class Node:
def __init__(self,key,childs):
self.childs=[]
self.key=key
def add_node(self,node):
self.childs.append(node)
4,构建树
# 判断数据是否在所有属性的取值都一样,以致无法划分
def same_data(data,attrs):
for i in range(len(attrs)):
if len(set(data[:,i]))>1:
return False
return True # attrs:属性的具体形式
def create_tree(data,attrs,num_class,root):
# 注意这里3个退出条件
# 1,如果数据为空,不能划分,此时这个叶节点不知标记为哪个分类了
if len(data)==0:
return
# 2,如果属性集为空,或所有样本在所有属性的取值相同,无法划分,返回样本最多的类别
if len(attrs)==0 or same_data(data,attrs):
class_set=list(set(data[:,-1]))
max_len=0
index=0
for i in range(len(class_set)):
if len(data[data[:,-1]==class_set[i]])>max_len:
max_len=len(data[data[:,-1]==class_set[i]])
index=i
root.key=root.key+class_set[index]
return
# 3,如果当前节点包含同一类的样本,无需划分
if len(set(data[:,-1]))==1:
root.key=root.key+data[0,-1]
return
ent=entropy(data,num_class)
gain_result,mean=calculate_gain(data,attrs,num_class)
max=0
max_index=-1
# 求增益率最大
for i in range(len(gain_result)):
if gain_result[i]>=mean:
iva=IVa(data,i)
if gain_result[i]/iva>max:
max=gain_result[i]/iva
max_index=i
for j in range(len(attrs[max_index])):
part_data=data[data[:,max_index]==attrs[max_index][j]]
# 删除该列特征
part_data=np.delete(part_data,max_index,axis=1)
# 添加节点
root.add_node(Node(key=attrs[max_index][j],childs=[]))
# 删除某一类已判断属性
new_attrs=attrs[0:max_index]
new_attrs.extend(attrs[max_index+1:])
create_tree(part_data,new_attrs,num_class,root.childs[j])
5,使用西瓜数据集2.0测试,数据这里就手写了,比较少
def createDataSet():
"""
创建测试的数据集
:return:
"""
dataSet = [
#
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
#
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
#
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
#
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
#
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
#
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
#
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
#
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'], # ----------------------------------------------------
#
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
#
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
#
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
#
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
#
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'],
#
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
#
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
#
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
#
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜']
] # 特征值列表
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感'] # 特征对应的所有可能的情况
labels_full = [] for i in range(len(labels)):
items=[item[i] for item in dataSet]
uniqueLabel = set(items)
labels_full.append(list(uniqueLabel))
return np.array(dataSet), labels, labels_full
6,开始构建树
dataset,labels,labels_full=createDataSet()
root=Node('',[])
create_tree(dataset, labels_full, 2, root)
7,打印树结构
def print_root(n,root):print(n,root.key)
for node in root.childs:
print_root(n+1,node)
print_root(0,root)
打印结果为:数字表示层次
0
1 模糊坏瓜
1 稍糊
2 硬滑坏瓜
2 软粘好瓜
1 清晰
2 硬滑好瓜
2 软粘
3 青绿
4 稍蜷好瓜
4 蜷缩
4 硬挺坏瓜
3 乌黑坏瓜
3 浅白
8,绘制树形结构,这里我就手动绘制了。图中有2个叶节点为空白,即模型不知道该推测其为好瓜还是坏瓜。这里我暂时没有好的思路解决,只能随机处理?

9,总结
首先,暂时没有添加predict函数。其次,这是个简陋版的实现,有很多待优化的地方,如连续值处理、缺失值处理、剪枝防止过拟合,树的创建使用的是递归(样本大导致栈溢出,改成队列实现较好),也有基于基尼指数的实现,还有多变量决策树(可实现复杂的分类边界)。
决策树(基于增益率)之python实现的更多相关文章
- (数据科学学习手札23)决策树分类原理详解&Python与R实现
作为机器学习中可解释性非常好的一种算法,决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方 ...
- Python黑帽编程1.2 基于VS Code构建Python开发环境
Python黑帽编程1.2 基于VS Code构建Python开发环境 0.1 本系列教程说明 本系列教程,采用的大纲母本为<Understanding Network Hacks Atta ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- windows下使用pycharm开发基于ansible api的python程序
Window下python安装ansible,基于ansible api开发python程序 在windows下使用pycharm开发基于ansible api的python程序时,发现ansible ...
- 基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法. 由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节.算法的原理什么的, ...
- 数据结构:二叉树 基于list实现(python版)
基于python的list实现二叉树 #!/usr/bin/env python # -*- coding:utf-8 -*- class BinTreeValueError(ValueError): ...
- 决策树之ID3算法实现(python)
决策树的概念其实不难理解,下面一张图是某女生相亲时用到的决策树: 基本上可以理解为:一堆数据,附带若干属性,每一条记录最后都有一个分类(见或者不见),然后根据每种属性可以进行划分(比如年龄是>3 ...
- 基于微博数据用 Python 打造一颗“心”
一年一度的虐狗节刚过去不久,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的.程序员在晒什么,程序员在加班.但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗“ ...
- 基于协程的Python网络库gevent
import gevent def test1(): print 12 gevent.sleep(0) print 34 def test2(): print 56 gevent.sleep(0) p ...
随机推荐
- PHP面相对象编程-重载、覆盖(重写) 多态、接口
http://www.ctolib.com/topics-21262.html http://cnn237111.blog.51cto.com/2359144/1284085 http://blog. ...
- Setup Factory 9 简单打包
由于项目资源太大,使用VS自带打包工具无法实现需求,所以Setup Factory 9进行打包生成多个文件的方案,下面记录使用方法: 一:这里点击下载:下载,提取码:tt7a 二:下载完安装需要注册码 ...
- .NET CORE下最快比较两个文件内容是否相同的方法 - 续
.NET CORE下最快比较两个文件内容是否相同的方法 - 续 在上一篇博文中, 我使用了几种方法试图找到哪个是.NET CORE下最快比较两个文件的方法.文章发布后,引起了很多博友的讨论, 在此我对 ...
- 学习笔记(一)-PyTorch在Windows环境搭建
一.安装Anaconda 3.5 Anaconda是一个用于科学计算的Python发行版,支持Linux.Mac和Window系统,提供了包管理与环境管理的功能,可以很方便地解决Python并存.切换 ...
- hdu-6638 Snowy Smile
题目链接 Snowy Smile Problem Description There are n pirate chests buried in Byteland, labeled by 1,2,-, ...
- UVA1486 Transportation 费用流 拆边。
#include <iostream> #include <cstdio> #include <cmath> #include <queue> #inc ...
- SpringBoot项目创建及入门基础
一:快速构建springboot项目 进入https://start.spring.io/,选择相应的springboot版本,包名,项目名,依赖 图中选择web,利用tomcat服务器进行开发 sp ...
- codeforces 876 F. High Cry(思维)
题目链接:http://codeforces.com/contest/876/problem/F 题解:一道简单的思维题,知道最多一共有n*(n+1)/2种组合,不用直接找答案直接用总的组合数减去不符 ...
- Git的合并
merge: A---B---C topic / D---E---F---G master A---B---C topic / \ D---E---F---G---H master (在当前的bran ...
- java路障CyclicBarrier
当所有线程都执行到某行代码,才可已往下执行: package threadLock; import java.util.Random; import java.util.concurrent.Brok ...