LeetCode刷题总结-递归篇
递归是算法学习中很基本也很常用的一种方法,但是对于初学者来说比较难以理解(PS:难点在于不断调用自身,产生多个返回值,理不清其返回值的具体顺序,以及最终的返回值到底是哪一个?)。因此,本文将选择LeetCode中一些比较经典的习题,通过简单测试实例,具体讲解递归的实现原理。本文要讲的内容包括以下几点:
- 理解递归的运行原理
- 求解递归算法的时间复杂度和空间复杂度
- 如何把递归用到解题中(寻找递推关系,或者递推公式)
- 记忆化操作
- 尾递归
- 剪枝操作
理解递归的运行原理
例1求解斐波那契数列
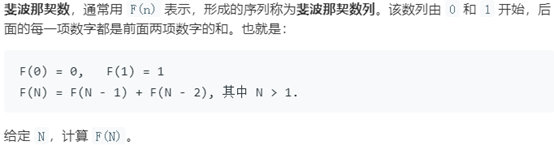
题目描述(题目序号:509,困难等级:简单):
求解代码(基础版):
- class Solution {
- public int fib(int N) {
- if(N <= 1)
- return N;
- return fib(N - 1) + fib(N - 2);
- }
- }
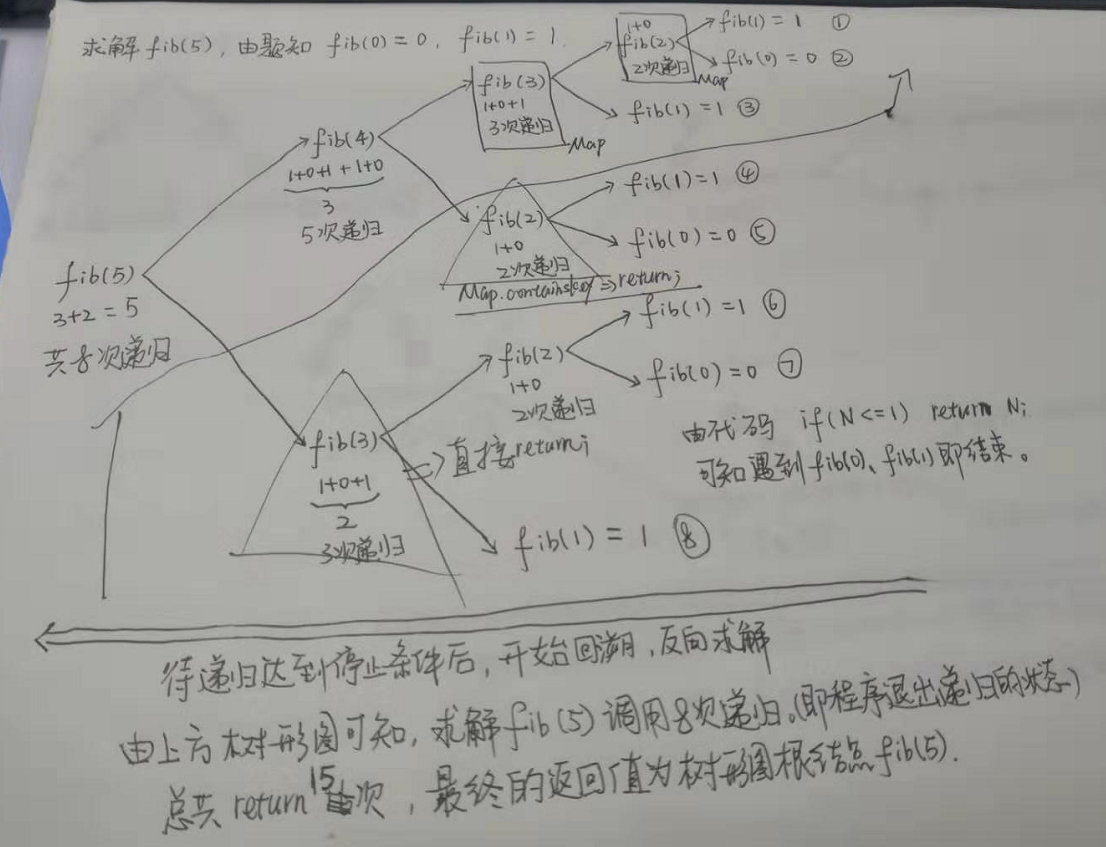
现在以N = 5为例,分析上述代码的运行原理,具体如下图:
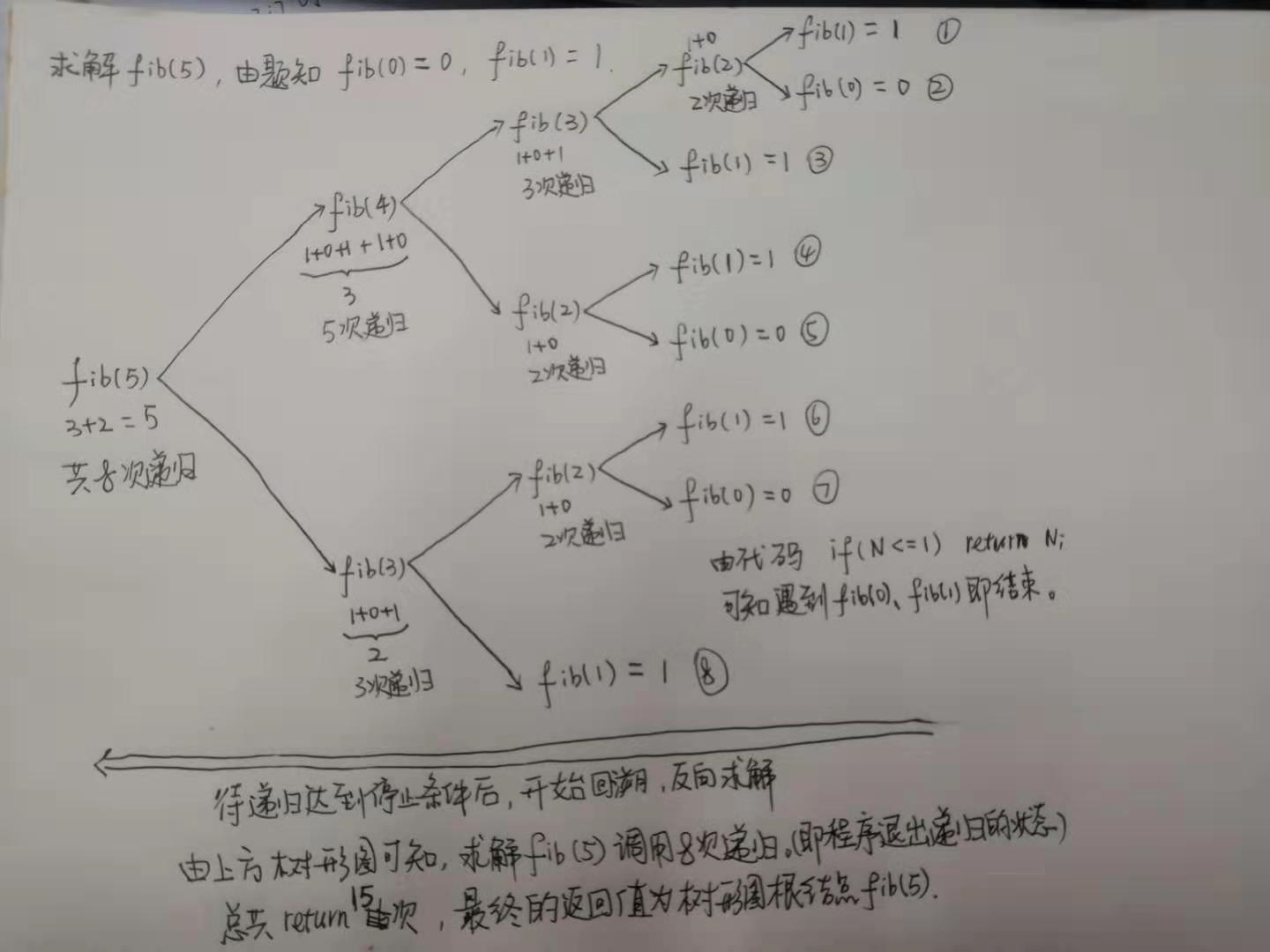
递归的返回值很多,初学者很难理解最终的返回值是哪个,此时可以采用上图的方式画一个树形图,手动执行递归代码,树形图的叶节点即为递归的终止条件,树形图的根节点即为最终的返回值。树形图的所有节点个数即为递归程序得到最终返回值的总体运行次数,可以借此计算时间复杂度,这个问题会在后文讲解。
例2 二叉树的三种遍历方式
二叉树的遍历方式一般有四种:前序遍历、中序遍历、后序遍历和层次遍历,前三种遍历方式应用递归可以大大减少代码量,而层次遍历一般应用队列方法(即非递归方式)求解。以下将要讲解应用递归求解二叉树的前、中、后序遍历的实现原理。
前序遍历
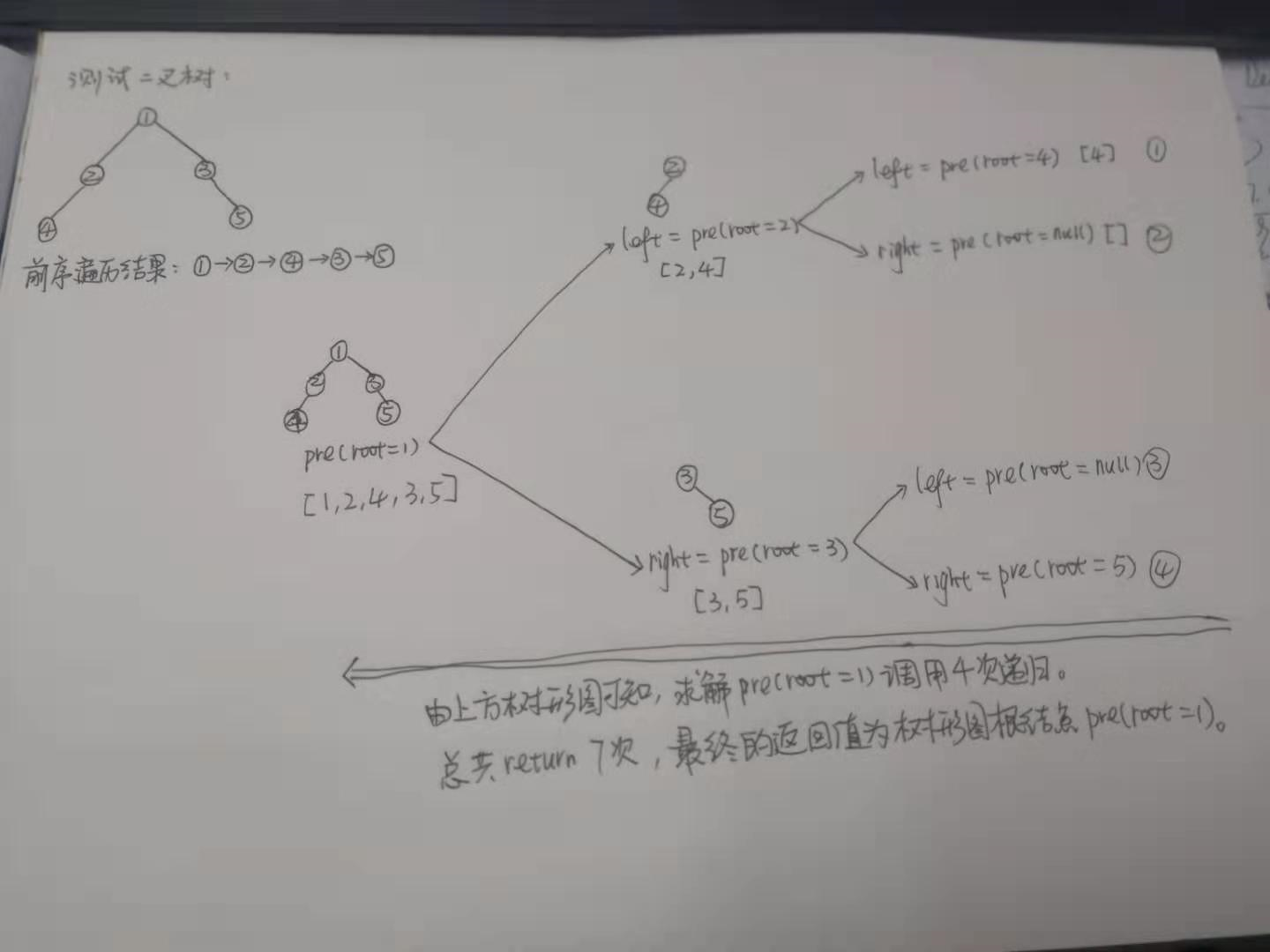
前序遍历方式:根节点->左子树->右子树。
题目描述(题目序号:144,困难等级:中等):

求解代码:
- /**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
- class Solution {
- public List<Integer> preorderTraversal(TreeNode root) {
- List<Integer> list = new ArrayList<>();
- if(root == null)
- return list;
- List<Integer> left = preorderTraversal(root.left);
- List<Integer> right = preorderTraversal(root.right);
- list.add(root.val);
- for(Integer l: left)
- list.add(l);
- for(Integer r: right)
- list.add(r);
- return list;
- }
- }
具体测试实例如下图:
中序遍历
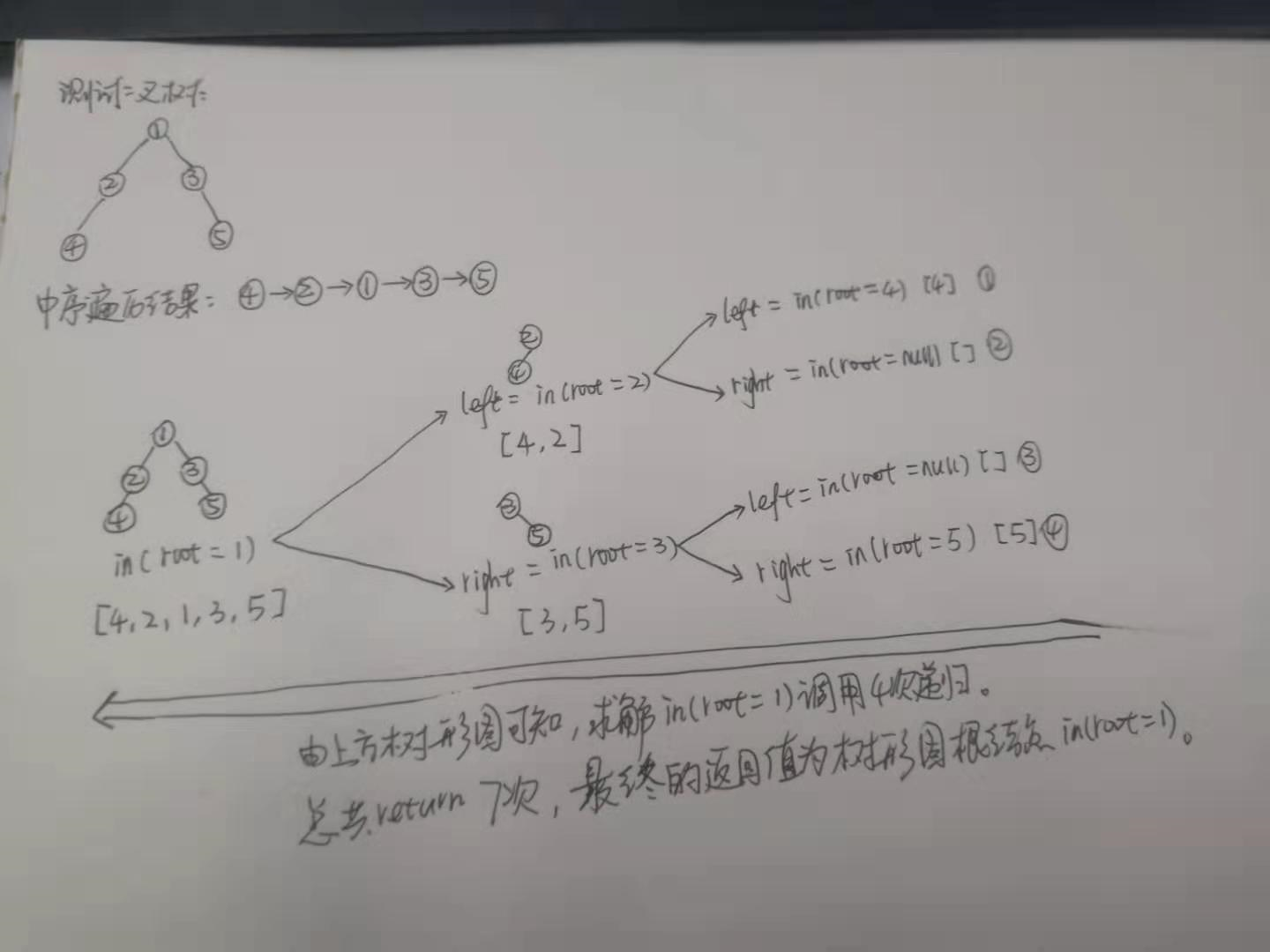
中序遍历方式:左子树->根节点->右子树。
题目描述(题目序号:94,困难等级:中等):

求解代码:
- /**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
- class Solution {
- public List<Integer> inorderTraversal(TreeNode root) {
- List<Integer> list = new ArrayList<>();
- if(root == null)
- return list;
- List<Integer> left = inorderTraversal(root.left);
- List<Integer> right = inorderTraversal(root.right);
- for(Integer l: left)
- list.add(l);
- list.add(root.val);
- for(Integer r: right)
- list.add(r);
- return list;
- }
- }
具体测试实例如下图:
后序遍历
后序遍历方式:左子树->右子树->根节点。
题目描述(题目序号:145,困难等级:困难):

求解代码:
- /**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
- class Solution {
- public List<Integer> postorderTraversal(TreeNode root) {
- List<Integer> list = new ArrayList<>();
- if (root == null)
- return list;
- List<Integer> left = postorderTraversal(root.left);
- List<Integer> right = postorderTraversal(root.right);
- for(Integer l: left)
- list.add(l);
- for(Integer r: right)
- list.add(r);
- list.add(root.val);
- return list;
- }
- }
具体测试实例如下图:
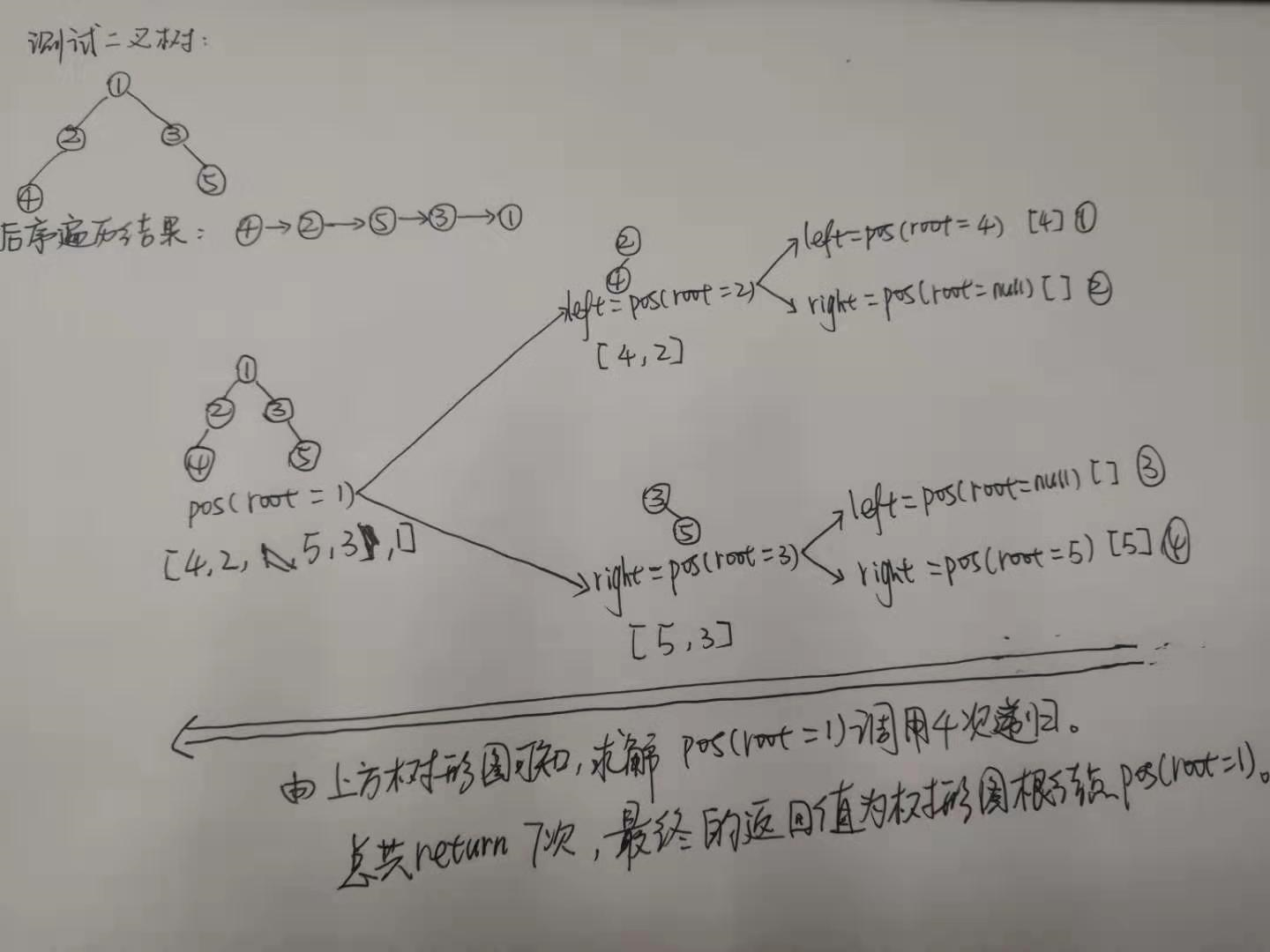
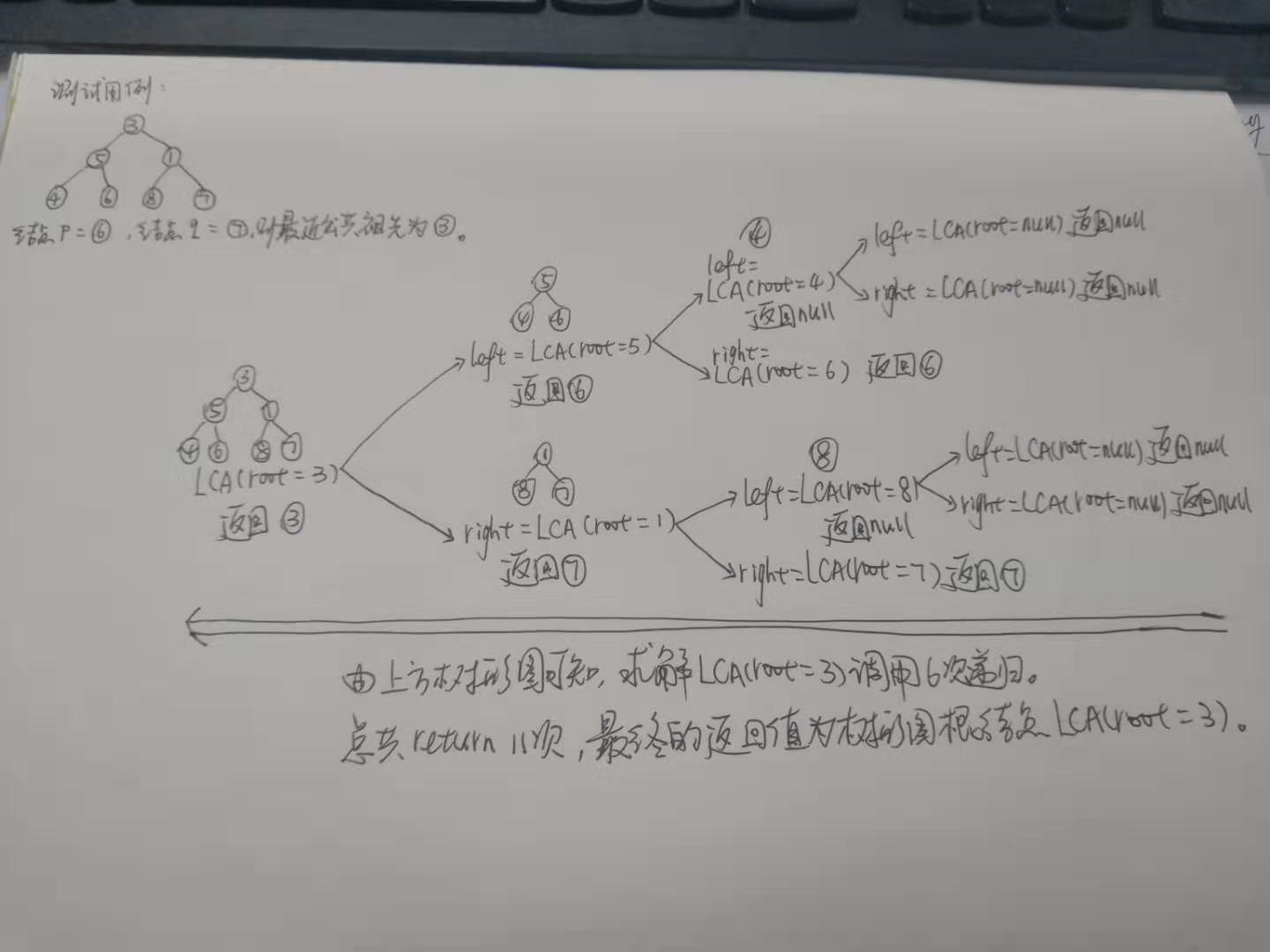
例3求解二叉树的最近公共祖先
题目描述(题目序号:236,困难等级:中等):

求解思路:
递归终止条件:
(1) 根节点为空
(2) 根节点为指定的两个节点之一
递归方式:
在根节点的左子树中寻找最近公共祖先。
在根节点的右子树中寻找最近公共祖先。
如果左子树和右子树返回值均不为空,说明两个节点分别在左右子树,最终返回root。
如果左子树为空,说明两个节点均在右子树,最终返回右子树的返回值。
如果右子树为空,说明两个节点均在左子树,最终返回左子树的返回值。
如果左子树和右子树均为空,说明该次没有匹配的结果。
具体代码如下:
- /**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
- class Solution {
- public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
- if (root == null) {
- return root;
- }
- if (root == p || root == q) {
- return root;
- }
- TreeNode left = lowestCommonAncestor(root.left, p, q);
- TreeNode right = lowestCommonAncestor(root.right, p, q);
- if (left != null && right != null) {
- return root;
- } else if (left != null) {
- return left;
- } else if (right != null) {
- return right;
- }
- return null;
- }
- }
具体测试实例如下图:
求解递归算法的时间复杂度和空间复杂度
以上一节例1斐波那契数列为例。
时间复杂度
时间复杂度一般可以理解为程序运行调用的次数。在应用递归解题过程中,如果当前递归运行过程中,相关求解过程的运行时间不受变量影响,且运行时间是常数量级,则该算法的时间复杂度为递归的总体返回次数。
以上一节例1中解题思路,求解fib(5)总共return15次,画的树形图包含5层。那么求解例1中示例解答程序代码的时间复杂度,就是求解树形图的整体节点个数。对于n层满二叉树,共有2^n – 1个节点,所以求解fib(n),大约需要返回(2^n - 1)次,才能得到最终的根节点值。那么,fib(n)的时间复杂度为O(2^n)。
空间复杂度
递归算法的空间复杂度一般与递归的深度有关。一般来说,如果当前递归运行过程中,消耗的空间复杂度是一个常数,那么该算法的最终空间复杂度即为递归的深度。计算方式:递归的深度*一次递归的空间复杂度。
递归的运行状态,随着运行深度的增加,系统会把上一次的状态存入系统栈中,一旦遇到递归终止条件,便开始不断出栈,直到栈为空时,程序结束。所以,递归程序的空间复杂度一般和递归的深度有关。
以上一节例1中解题思路,求解fib(5)时,需要最深的层次需要经历以下过程:
第一层:fib(5) = fib(4) + fib(3)
第二层:fib(4) = fib(3) + fib(2)
第三层:fib(3) = fib(2) + fib(1)
第四层:fib(2) = fib(1) + fib(0)
第五层:fib(1),遇到递归终止条件,开始进行出栈操作。
可知求解fib(5)时,递归的深度为5,具体可对照例1中画的二叉树,正好等于二叉树的高度。那么求解fib(n)的空间复杂度为O(n)。
如何把递归用到解题中(寻找递推关系,或者递推公式)
例4字符串的反转
题目描述(题目序号:344,困难等级:简单):

递推关系:reverse(s[0,n]) = reverse(s[1,n-1])
具体代码如下:
- class Solution {
- public void reverseString(char[] s) {
- dfs(s, 0, s.length-1);
- }
- public void dfs(char[] s, int start, int end) {
- if(start > end)
- return;
- dfs(s, start+1, end-1);
- char temp = s[start];
- s[start] = s[end];
- s[end] = temp;
- }
- }
例5两两交换链表中的节点
题目描述(题目序号:24,困难等级:中等):
递推关系:swapPairs(head) = swapPairs(head.next.next)
具体代码如下:
- /**
- * Definition for singly-linked list.
- * public class ListNode {
- * int val;
- * ListNode next;
- * ListNode(int x) { val = x; }
- * }
- */
- class Solution {
- public ListNode swapPairs(ListNode head) {
- if(head == null || head.next == null){
- return head;
- }
- ListNode next = head.next;
- head.next = swapPairs(next.next);
- next.next = head;
- return next;
- }
- }
例6 所有可能的满二叉树
题目描述(题目序号:894,困难等级:中等):
递推关系: allPossibleFBT(N) = allPossibleFBT(i) + allPossibleFBT(N – 1 - i),其中i为奇数,1<= i<N。
具体代码如下:
- /**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
- class Solution {
- public List<TreeNode> allPossibleFBT(int N) {
- List<TreeNode> ans = new ArrayList<>();
- if (N % 2 == 0) {
- return ans;
- }
- if (N == 1) {
- TreeNode head = new TreeNode(0);
- ans.add(head);
- return ans;
- }
- for (int i = 1; i < N; i += 2) {
- List<TreeNode> left = allPossibleFBT(i);
- List<TreeNode> right = allPossibleFBT(N - 1 - i);
- for (TreeNode l : left) {
- for (TreeNode r : right) {
- TreeNode head = new TreeNode(0);
- head.left = l;
- head.right = r;
- ans.add(head);
- }
- }
- }
- return ans;
- }
- }
记忆化操作
由第一节例1的解答代码可知,求解fib(n)的时间复杂度为O(2^n),其中进行了大量重复求值过程,比如求解fib(5)时,需要求解两次fib(3),求解三次fib(2)等。那么如何避免重复求解的过程呢?我们可以采用记忆化操作。
记忆化操作就是把之前递归求解得到的返回值保存到一个全局变量中,后面遇到对应的参数值,先判断当前全局变量中是否包含其解,如果包含则直接返回具体解,否则进行递归求解。
例1:
原解答代码:
- class Solution {
- public int fib(int N) {
- if(N <= 1)
- return N;
- return fib(N - 1) + fib(N - 2);
- }
- }
时间复杂度为O(2^n),空间复杂度为O(n)。提交测试结果:
采用记忆化改进:
- class Solution {
- private Map<Integer, Integer> map = new HashMap<>();
- public int fib(int N) {
- if(N <= 1)
- return N;
- if(map.containsKey(N))
- return map.get(N);
- int result = fib(N - 1) + fib(N - 2);
- map.put(N, result);
- return result;
- }
- }
具体递归应用测试示例如下图:
时间复杂度为O(n),空间复杂度为O(n)。提交测试结果:

求解斐波那契数列,还有多种方法,比如矩阵乘法、数学公式直接计算等。所以,采用记忆化改进的代码并不是最优,这点在本文不作详细讨论。
尾递归
尾递归是指在返回时,直接返回递归函数调用的值,不做额外的运算。比如,第一节中斐波那契数列的递归是返回: return fib(N-1) + fib(N-2);。返回时,需要做加法运算,这样的递归调用就不属于尾递归。
下面解释引用自LeetCode解答
尾递归的好处是,它可以避免递归调用期间栈空间开销的累积,因为系统可以为每个递归调用重用栈中的固定空间。
在尾递归的情况下,一旦从递归调用返回,我们也会立即返回,因此我们可以跳过整个递归调用返回链,直接返回到原始调用方。这意味着我们根本不需要所有递归调用的调用栈,这为我们节省了空间。
尾递归的优势可以通俗的理解为:降低算法的空间复杂度,由原来应用栈存储中间状态,变换为不断直接返回最终值。
通常,编译器会识别尾递归模式,并优化其执行。然而,并不是所有的编程语言都支持这种优化,比如 C,C++ 支持尾递归函数的优化。另一方面,Java 和 Python 不支持尾递归优化。
剪枝操作
剪枝操作是指在递归调用过程中,通过添加相关判断条件,减少不必要的递归操作,从而提高算法的运行速度。一般来说,良好的剪枝操作能够降低算法的时间复杂度,提高程序的健壮性。下面将以一道算法题来说明。
题目描述(题目序号:698,困难等级:中等):

解题思路:
首先,对原始数组进行从小到大排序操作。
然后,初始化长度为K的数组,每一个元素赋值为sum(nums) / K。
最后,从排序后的数组的最后一个元素开始进行递归操作。依次,选择长度为K的数组中每个元素减去数组中的元素,如果相减的差为0或者小于0则跳过,否则执行正常的相减操作。
剪枝策略:
(1) 如果数组nums中最大元素大于sum(nums) / K,则直接返回,结束程序。
(2) 如果执行当前减法操作得到的结果小于nums数组中最小值,则放弃本次递归操作,进行下一次递归操作。
具体实现代码如下(包含剪枝):
- class Solution {
- public boolean canPartitionKSubsets(int[] nums, int k) {
- int sum = 0;
- for(int i = 0; i < nums.length; i++){
- sum += nums[i];
- }
- if(sum % k != 0){
- return false;
- }
- sum = sum / k;
- Arrays.sort(nums);
- if(nums[nums.length - 1] > sum){
- return false;
- }
- int[] arr = new int[k];
- Arrays.fill(arr, sum);
- return help(nums, nums.length - 1, arr, k);
- }
- boolean help(int[] nums, int cur, int[] arr, int k){
- if(cur < 0){
- return true;
- }
- for(int i = 0; i < k; i++){
- //如果正好能放下当前的数或者放下当前的数后,还有机会继续放前面的数(剪枝)
- if(arr[i] == nums[cur] || (arr[i] - nums[cur] >= nums[0])){
- arr[i] -= nums[cur];
- //递归,开始放下一个数
- if(help(nums, cur - 1, arr, k)){
- return true;
- }
- arr[i] += nums[cur];
- }
- }
- return false;
- }
- }
测试结果:

将剪枝操作删除,变成正常的递归调用,即把下述代码:
- //如果正好能放下当前的数或者放下当前的数后,还有机会继续放前面的数(剪枝)
- if(arr[i] == nums[cur] || (arr[i] - nums[cur] >= nums[0])){
变换成:
- if(arr[i] >= nums[cur]){
测试结果:

由上述对比分析可知,灵活运用剪枝操作可以有效提高程序的运行效率。
LeetCode刷题总结-递归篇的更多相关文章
- LeetCode刷题总结-树篇(上)
引子:刷题的过程可能是枯燥的,但程序员们的日常确不乏趣味.分享一则LeetCode上名为<打家劫舍 |||>题目的评论: 如有兴趣可以从此题为起点,去LeetCode开启刷题之 ...
- LeetCode刷题总结-数组篇(上)
数组是算法中最常用的一种数据结构,也是面试中最常考的考点.在LeetCode题库中,标记为数组类型的习题到目前为止,已累计到了202题.然而,这202道习题并不是每道题只标记为数组一个考点,大部分习题 ...
- LeetCode刷题总结-数组篇(中)
本文接着上一篇文章<LeetCode刷题总结-数组篇(上)>,继续讲第二个常考问题:矩阵问题. 矩阵也可以称为二维数组.在LeetCode相关习题中,作者总结发现主要考点有:矩阵元素的遍历 ...
- LeetCode刷题总结-树篇(中)
本篇接着<LeetCode刷题总结-树篇(上)>,讲解有关树的类型相关考点的习题,本期共收录17道题,1道简单题,10道中等题,6道困难题. 在LeetCode题库中,考察到的不同种类的树 ...
- LeetCode刷题总结-数组篇(下)
本期讲O(n)类型问题,共14题.3道简单题,9道中等题,2道困难题.数组篇共归纳总结了50题,本篇是数组篇的最后一篇.其他三个篇章可参考: LeetCode刷题总结-数组篇(上),子数组问题(共17 ...
- LeetCode刷题总结-树篇(下)
本文讲解有关树的习题中子树问题和新概念定义问题,也是有关树习题的最后一篇总结.前两篇请参考: LeetCode刷题总结-树篇(上) LeetCode刷题总结-树篇(中) 本文共收录9道题,7道中等题, ...
- LeetCode刷题专栏第一篇--思维导图&时间安排
昨天是元宵节,过完元宵节相当于这个年正式过完了.不知道大家有没有投入继续投入紧张的学习工作中.年前我想开一个Leetcode刷题专栏,于是发了一个投票想了解大家的需求征集意见.投票于2019年2月1日 ...
- LeetCode刷题总结-字符串篇
本文梳理对LeetCode上有关字符串习题的知识点,并给出对应的刷题建议.本文建议刷题的总数为32题.具体知识点如下图: 1.回文问题 题号:5. 最长回文子串,难度中等 题号:214. 最短回文串, ...
- LeetCode刷题总结-动态规划篇
本文总结LeetCode上有动态规划的算法题,推荐刷题总数为54道.具体考点分析如下图: 1.中心扩展法 题号:132. 分割回文串 II,难度困难 2.背包问题 题号:140. 单词拆分 II,难度 ...
随机推荐
- java8 新特性精心整理(全)
前言 越来越多的项目已经使用 Java 8 了,毫无疑问,Java 8 是Java自Java 5(发布于2004年)之后的最重要的版本.这个版本包含语言.编译器.库.工具和 JVM 等方面的十多个新特 ...
- 如何用java实现数据脱敏
数据脱敏是什么意思呢? 数据脱敏是指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护.在涉及客户安全数据或者一些商业性敏感数据的情况下,在不违反系统规则条件下,对真实数据进行改造并 ...
- JavaScript之深入对象(一)
在之前的<JavaScript对象基础>中,我们大概了解了对象的创建和使用,知道对象可以使用构造函数和字面量方式创建.那么今天,我们就一起来深入了解一下JavaScript中的构造函数以及 ...
- String StringBuffer StringBuilder的异同
1.String与StrIngBuffer StringBuilder的主要区别在于StrIng是不可变对象,每次对String对象进行修改之后,相对于重新创建一个对象. String源码解读: pr ...
- 《深度解析Tomcat》 第一章 一个简单的Web服务器
本章介绍Java Web服务器是如何运行的.从中可以知道Tomcat是如何工作的. 基于Java的Web服务器会使用java.net.Socket类和java.net.ServerSocket类这两个 ...
- django查询表记录的十三种方法
django查询表记录的十三种方法 all() 结果为queryset类型 >>> models.Book.objects.all() <QuerySet [<Book: ...
- idea创建javaweb原生项目
使用idea创建javaweb项目 idea还是写框架项目比较爽,原生的javaweb项目不是特别方便,这篇文章就是记录一下创建的过程 图较多注意流量 选择创建web项目 配置tomcat服务器 配置 ...
- 利用Python进行数据分析:【Pandas】(Series+DataFrame)
一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的.3.pandas的主要功能 --具备对其功能的数据结构DataFrame.S ...
- S2-052 漏洞复现
Structs2框架已知的漏洞编号如下: S2-005 S2-009 S2-016 (含S2-013) S2-019 S2-020 S2-021 S2-032 S2-037(含S2-033) DevM ...
- Shell之命令执行的判断依据
目录 Shell之命令执行的判断依据 参考 Shell之命令执行的判断依据