(转)两种高效过滤敏感词算法--DFA算法和AC自动机算法
原文:https://blog.csdn.net/u013421629/article/details/83178970
一道bat面试题:快速替换10亿条标题中的5万个敏感词,有哪些解决思路?
有十亿个标题,存在一个文件中,一行一个标题。有5万个敏感词,存在另一个文件。写一个程序过滤掉所有标题中的所有敏感词,保存到另一个文件中。
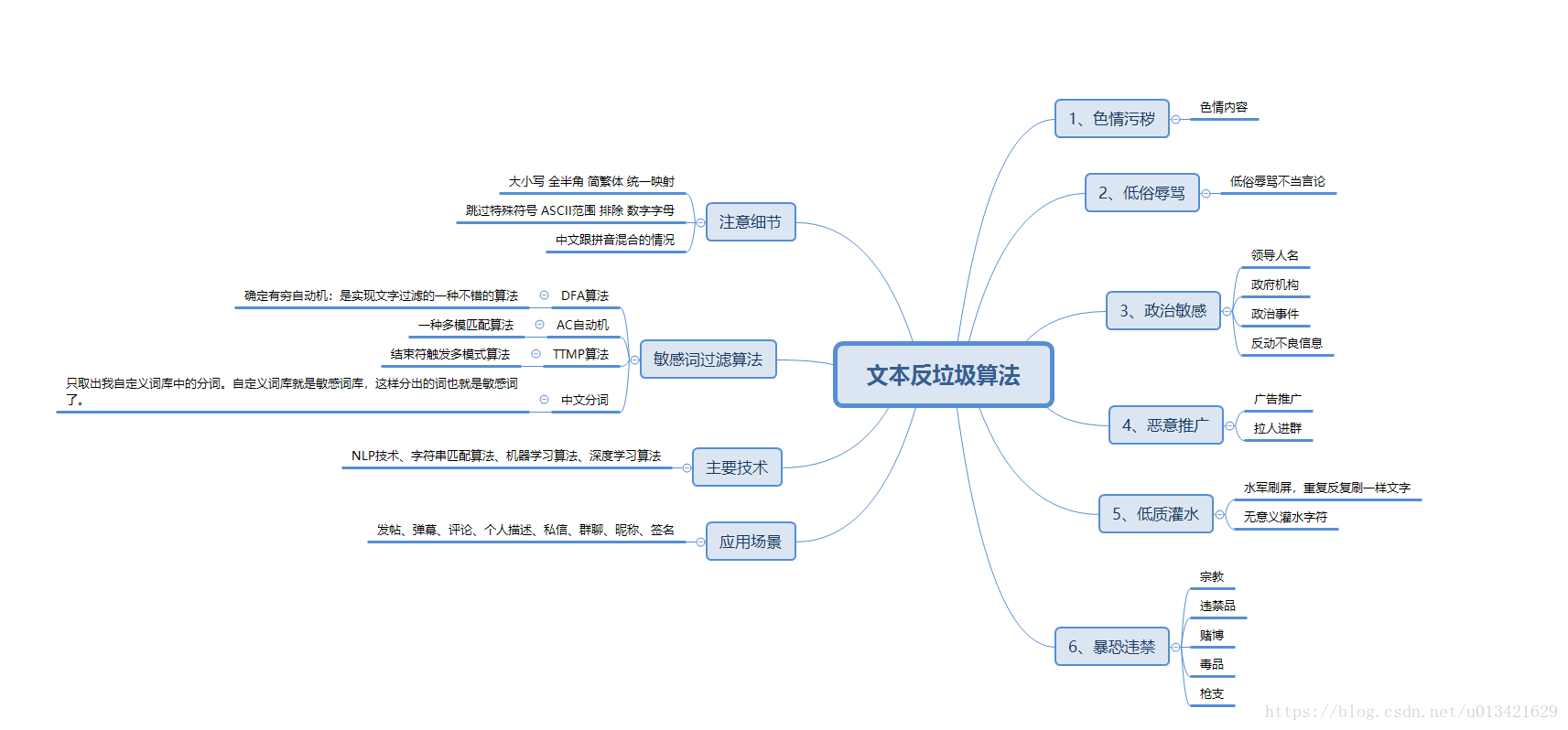
1、DFA过滤敏感词算法
在实现文字过滤的算法中,DFA是比较好的实现算法。DFA即Deterministic Finite Automaton,也就是确定有穷自动机。
算法核心是建立了以敏感词为基础的许多敏感词树。
python 实现DFA算法:
# -*- coding:utf-8 -*-
import time
time1=time.time()
# DFA算法
class DFAFilter():
def __init__(self):
self.keyword_chains = {}
self.delimit = '\x00'
def add(self, keyword):
keyword = keyword.lower()
chars = keyword.strip()
if not chars:
return
level = self.keyword_chains
for i in range(len(chars)):
if chars[i] in level:
level = level[chars[i]]
else:
if not isinstance(level, dict):
break
for j in range(i, len(chars)):
level[chars[j]] = {}
last_level, last_char = level, chars[j]
level = level[chars[j]]
last_level[last_char] = {self.delimit: 0}
break
if i == len(chars) - 1:
level[self.delimit] = 0
def parse(self, path):
with open(path,encoding='utf-8') as f:
for keyword in f:
self.add(str(keyword).strip())
def filter(self, message, repl="*"):
message = message.lower()
ret = []
start = 0
while start < len(message):
level = self.keyword_chains
step_ins = 0
for char in message[start:]:
if char in level:
step_ins += 1
if self.delimit not in level[char]:
level = level[char]
else:
ret.append(repl * step_ins)
start += step_ins - 1
break
else:
ret.append(message[start])
break
else:
ret.append(message[start])
start += 1
return ''.join(ret)
if __name__ == "__main__":
gfw = DFAFilter()
path="F:/文本反垃圾算法/sensitive_words.txt"
gfw.parse(path)
text="新疆骚乱苹果新品发布会雞八"
result = gfw.filter(text)
print(text)
print(result)
time2 = time.time()
print('总共耗时:' + str(time2 - time1) + 's')运行效果:
E:\laidefa\python.exe "E:/Program Files/pycharmproject/敏感词过滤算法/敏感词过滤算法DFA.py"
新疆骚乱苹果新品发布会雞八
****苹果新品发布会**
总共耗时:0.0010344982147216797s
Process finished with exit code 02、AC自动机过滤敏感词算法
AC自动机:一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。
简单地讲,AC自动机就是字典树+kmp算法+失配指针
# -*- coding:utf-8 -*-
import time
time1=time.time()
# AC自动机算法
class node(object):
def __init__(self):
self.next = {}
self.fail = None
self.isWord = False
self.word = ""
class ac_automation(object):
def __init__(self):
self.root = node()
# 添加敏感词函数
def addword(self, word):
temp_root = self.root
for char in word:
if char not in temp_root.next:
temp_root.next[char] = node()
temp_root = temp_root.next[char]
temp_root.isWord = True
temp_root.word = word
# 失败指针函数
def make_fail(self):
temp_que = []
temp_que.append(self.root)
while len(temp_que) != 0:
temp = temp_que.pop(0)
p = None
for key,value in temp.next.item():
if temp == self.root:
temp.next[key].fail = self.root
else:
p = temp.fail
while p is not None:
if key in p.next:
temp.next[key].fail = p.fail
break
p = p.fail
if p is None:
temp.next[key].fail = self.root
temp_que.append(temp.next[key])
# 查找敏感词函数
def search(self, content):
p = self.root
result = []
currentposition = 0
while currentposition < len(content):
word = content[currentposition]
while word in p.next == False and p != self.root:
p = p.fail
if word in p.next:
p = p.next[word]
else:
p = self.root
if p.isWord:
result.append(p.word)
p = self.root
currentposition += 1
return result
# 加载敏感词库函数
def parse(self, path):
with open(path,encoding='utf-8') as f:
for keyword in f:
self.addword(str(keyword).strip())
# 敏感词替换函数
def words_replace(self, text):
"""
:param ah: AC自动机
:param text: 文本
:return: 过滤敏感词之后的文本
"""
result = list(set(self.search(text)))
for x in result:
m = text.replace(x, '*' * len(x))
text = m
return text
if __name__ == '__main__':
ah = ac_automation()
path='F:/文本反垃圾算法/sensitive_words.txt'
ah.parse(path)
text1="新疆骚乱苹果新品发布会雞八"
text2=ah.words_replace(text1)
print(text1)
print(text2)
time2 = time.time()
print('总共耗时:' + str(time2 - time1) + 's')E:\laidefa\python.exe "E:/Program Files/pycharmproject/敏感词过滤算法/AC自动机过滤敏感词算法.py"
新疆骚乱苹果新品发布会雞八
****苹果新品发布会**
总共耗时:0.0010304450988769531s
Process finished with exit code 03、java 实现参考链接:
https://www.cnblogs.com/AlanLee/p/5329555.html
4、敏感词生成
# -*- coding:utf-8 -*-
path = 'F:/文本反垃圾算法/sensitive_worlds7.txt'
from 敏感词过滤算法.langconv import *
import pandas as pd
import pypinyin
# 文本转拼音
def pinyin(text):
"""
:param text: 文本
:return: 文本转拼音
"""
gap = ' '
piny = gap.join(pypinyin.lazy_pinyin(text))
return piny
# 繁体转简体
def tradition2simple(text):
"""
:param text: 要过滤的文本
:return: 繁体转简体函数
"""
line = Converter('zh-hans').convert(text)
return line
data=pd.read_csv(path,sep='\t')
chinise_lable=[]
chinise_type=data['type']
for i in data['lable']:
line=tradition2simple(i)
chinise_lable.append(line)
chg_data=pd.DataFrame({'lable':chinise_lable,'type':chinise_type})
eng_lable=[]
eng_type=data['type']
for i in data['lable']:
# print(i)
piny=pinyin(i)
# print(piny)
eng_lable.append(piny)
eng_data=pd.DataFrame({'lable':eng_lable,'type':eng_type})
# print(eng_data)
# 合并
result=chg_data.append(eng_data,ignore_index=True)
# 数据框去重
res = result.drop_duplicates()
print(res)
# 输出
res.to_csv('F:/文本反垃圾算法/中英混合的敏感词10.txt',header=True,index=False,sep='\t',encoding='utf-8')(转)两种高效过滤敏感词算法--DFA算法和AC自动机算法的更多相关文章
- 聚类算法K-Means算法和Mean Shift算法介绍及实现
Question:什么是聚类算法 1.聚类算法是一种非监督学习算法 2.聚类是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法 3.理论上,相同的组的数据之间有相同的属性或者是特征,不 ...
- 高效Java敏感词、关键词过滤工具包_过滤非法词句
敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有必要的.前段时间我一个朋友(马上毕业,接触编程不久)要我帮他看一个文字过滤的东西,它说检索效率非常慢.我把它程序拿过来 ...
- 【SpringBoot】前缀树 Trie 过滤敏感词
1.过滤敏感词 Spring Boot实践,开发社区核心功能 完成过滤敏感词 Trie 名称:Trie也叫做字典树.前缀树(Prefix Tree).单词查找树 特点:查找效率高,消耗内存大 应用:字 ...
- web前端js过滤敏感词
web前端js过滤敏感词 这里是用文本输入框还有文本域绑定了失去焦点事件,然后再遍历敏感词数组进行匹配和替换. var keywords=["阿扁","呵呵", ...
- 两种高效的事件处理模式(Proactor和Reactor)
典型的多线程服务器的线程模型 1. 每个请求创建一个线程,使用阻塞式 I/O 操作 这是最简单的线程模型,1个线程处理1个连接的全部生命周期.该模型的优点在于:这个模型足够简单,它可以实现复杂的业务场 ...
- SpringBoot开发十四-过滤敏感词
项目需求-过滤敏感词 利用 Tire 树实现过滤敏感词 定义前缀树,根据敏感词初始化前缀树,编写过滤敏感词的方法 代码实现 我们首先把敏感词存到一个文件 sensitive.txt: 赌博 嫖娼 吸毒 ...
- 过滤敏感词工具类SensitiveFilter
网上过滤敏感词工具类有的存在挺多bug,这是我自己改用的过滤敏感词工具类,目前来说没啥bug,如果有bug欢迎在评论指出 使用前缀树 Trie 实现的过滤敏感词,树节点用静态内部类表示了,都写在一个 ...
- AC自动机-算法详解
What's Aho-Corasick automaton? 一种多模式串匹配算法,该算法在1975年产生于贝尔实验室,是著名的多模式匹配算法之一. 简单的说,KMP用来在一篇文章中匹配一个模式串:但 ...
- AC自动机算法详解
首先简要介绍一下AC自动机:Aho-Corasick automation,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一.一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章, ...
随机推荐
- cesium添加多个geojson文件并分别控制显示和隐藏
/*获取geojson数据*/ function get_geojson(name,h,n){ let x=document.getElementById(n); if(x.className === ...
- 解惑Python模块学习,该如何着手操作...
Python模块 晚上和朋友聊天,说到公司要求精兵计划,全员都要有编程能力.然后C.Java.Python-对于零基础入门的,当然是选择Python的人较多了.可朋友说他只是看了简单的语法,可pyth ...
- CentOS7.4系统下,手动安装MySQL5.7的方法
MySQL数据库应用广泛,尤其对于JAVA程序员,不会陌生.如果在不想采购云数据库的情况下,可以自行安装MySQL数据库.文章将介绍,手动在CentOS7.4环境下,安装MySQL5.7版本的方法. ...
- go基础之json格式数据处理
go基础之json格式数据处理 1.结构体小写问题导致出错 2.struct没有正确加tag 3.struct加上tag 4.struct tag扩展 go基础之json格式数据处理 go标准库里面提 ...
- 【重温基础】11.Map和Set对象
本文是 重温基础 系列文章的第十一篇. 今日感受:注意身体,生病花钱又难受. 系列目录: [复习资料]ES6/ES7/ES8/ES9资料整理(个人整理) [重温基础]1.语法和数据类型 [重温基础]2 ...
- scikit-learn与数据预处理
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- Jmeter性能测试配置
目录 Jmeter检查点/断言 Jmeter事务 Jmeter集合点 Jmeter检查点/断言 在上一章节中,我们通过调试脚本,通过人工验证脚本可以完成业务功能, 但在性能测试中,我们希望能通过自动验 ...
- Linux源码编译安装httpd
Linux安装软件采用源码编译安装灵活自由,适用于不同平台,维护也十分方便. 源码编译的安装方式一般由3个步骤组成: 1.配置(configure) 2.编译(make) 3.安装(make inst ...
- JS基础-DOM
DOM DOM 事件的级别 DOM 事件模型 DOM 事件流 DOM 事件捕获的具体流程 Event 对象的常见应用 自定义事件 DOM概述 | MDN DOM | MDN DOM操作 DOM事件级别 ...
- pcntl_signal(): Error assigning signal
错误原因:SIGSTOP(19)和SIGKILL(6)两个信号不能使用,进程间通信换成其他信号量就好了.