详解Kafka Producer
上一篇文章我们主要介绍了什么是 Kafka,Kafka 的基本概念是什么,Kafka 单机和集群版的搭建,以及对基本的配置文件进行了大致的介绍,还对 Kafka 的几个主要角色进行了描述,我们知道,不管是把 Kafka 用作消息队列、消息总线还是数据存储平台来使用,最终是绕不过消息这个词的,这也是 Kafka 最最核心的内容,Kafka 的消息从哪里来?到哪里去?都干什么了?别着急,一步一步来,先说说 Kafka 的消息从哪来。
生产者概述
在 Kafka 中,我们把产生消息的那一方称为生产者,比如我们经常回去淘宝购物,你打开淘宝的那一刻,你的登陆信息,登陆次数都会作为消息传输到 Kafka 后台,当你浏览购物的时候,你的浏览信息,你的搜索指数,你的购物爱好都会作为一个个消息传递给 Kafka 后台,然后淘宝会根据你的爱好做智能推荐,致使你的钱包从来都禁不住诱惑,那么这些生产者产生的消息是怎么传到 Kafka 应用程序的呢?发送过程是怎么样的呢?
尽管消息的产生非常简单,但是消息的发送过程还是比较复杂的,如图
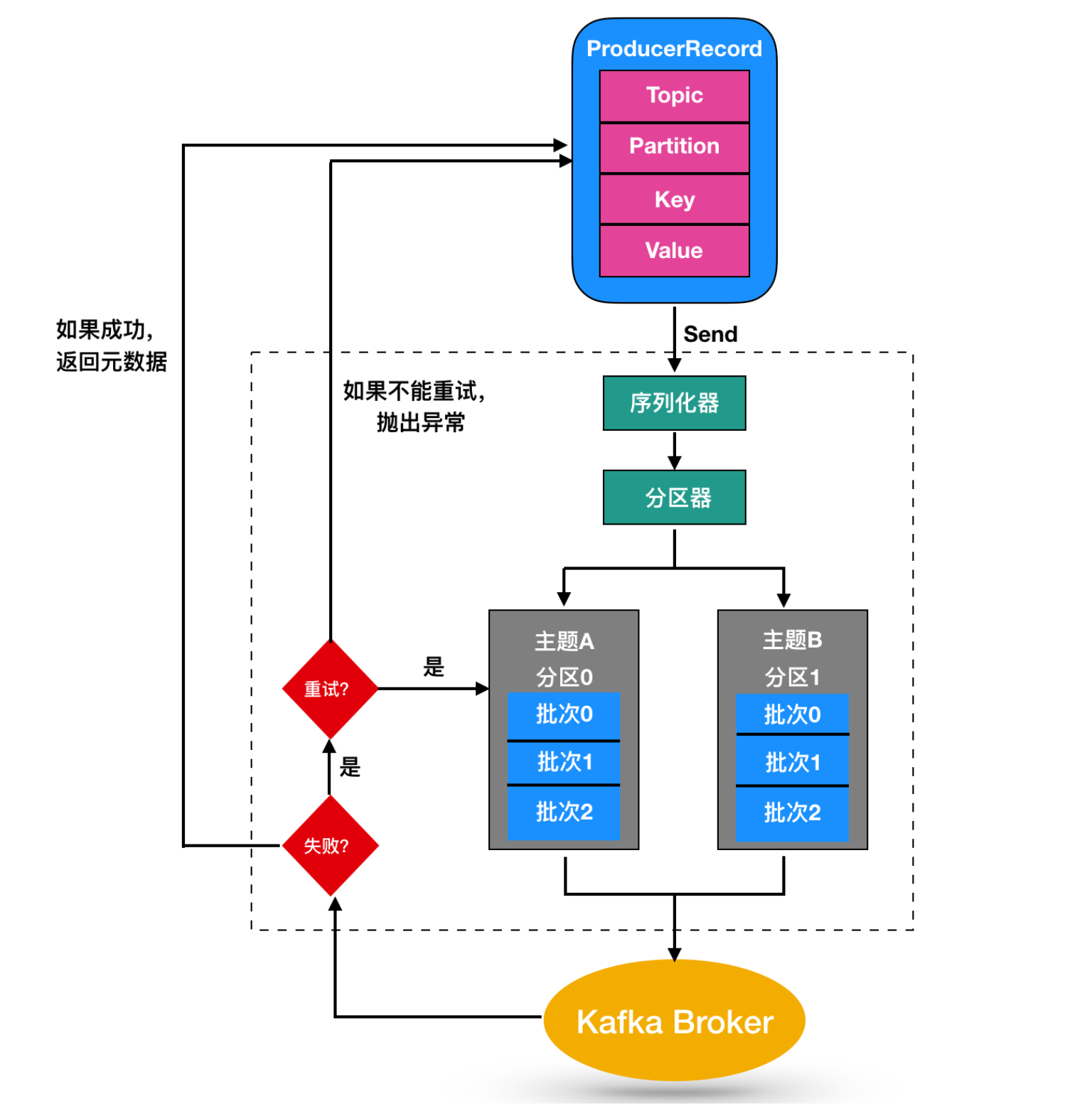
我们从创建一个ProducerRecord 对象开始,ProducerRecord 是 Kafka 中的一个核心类,它代表了一组 Kafka 需要发送的 key/value 键值对,它由记录要发送到的主题名称(Topic Name),可选的分区号(Partition Number)以及可选的键值对构成。
在发送 ProducerRecord 时,我们需要将键值对对象由序列化器转换为字节数组,这样它们才能够在网络上传输。然后消息到达了分区器。
如果发送过程中指定了有效的分区号,那么在发送记录时将使用该分区。如果发送过程中未指定分区,则将使用key 的 hash 函数映射指定一个分区。如果发送的过程中既没有分区号也没有,则将以循环的方式分配一个分区。选好分区后,生产者就知道向哪个主题和分区发送数据了。
ProducerRecord 还有关联的时间戳,如果用户没有提供时间戳,那么生产者将会在记录中使用当前的时间作为时间戳。Kafka 最终使用的时间戳取决于 topic 主题配置的时间戳类型。
- 如果将主题配置为使用
CreateTime,则生产者记录中的时间戳将由 broker 使用。 - 如果将主题配置为使用
LogAppendTime,则生产者记录中的时间戳在将消息添加到其日志中时,将由 broker 重写。
然后,这条消息被存放在一个记录批次里,这个批次里的所有消息会被发送到相同的主题和分区上。由一个独立的线程负责把它们发到 Kafka Broker 上。
Kafka Broker 在收到消息时会返回一个响应,如果写入成功,会返回一个 RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区里的偏移量,上面两种的时间戳类型也会返回给用户。如果写入失败,会返回一个错误。生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败的话,就返回错误消息。
创建 Kafka 生产者
要往 Kafka 写入消息,首先需要创建一个生产者对象,并设置一些属性。Kafka 生产者有3个必选的属性
- bootstrap.servers
该属性指定 broker 的地址清单,地址的格式为 host:port。清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找到其他的 broker 信息。不过建议至少要提供两个 broker 信息,一旦其中一个宕机,生产者仍然能够连接到集群上。
- key.serializer
broker 需要接收到序列化之后的 key/value 值,所以生产者发送的消息需要经过序列化之后才传递给 Kafka Broker。生产者需要知道采用何种方式把 Java 对象转换为字节数组。key.serializer 必须被设置为一个实现了org.apache.kafka.common.serialization.Serializer 接口的类,生产者会使用这个类把键对象序列化为字节数组。这里拓展一下 Serializer 类
Serializer 是一个接口,它表示类将会采用何种方式序列化,它的作用是把对象转换为字节,实现了 Serializer 接口的类主要有 ByteArraySerializer、StringSerializer、IntegerSerializer ,其中 ByteArraySerialize 是 Kafka 默认使用的序列化器,其他的序列化器还有很多,你可以通过 这里 查看其他序列化器。要注意的一点:key.serializer 是必须要设置的,即使你打算只发送值的内容。
- value.serializer
与 key.serializer 一样,value.serializer 指定的类会将值序列化。
下面代码演示了如何创建一个 Kafka 生产者,这里只指定了必要的属性,其他使用默认的配置
private Properties properties = new Properties();
properties.put("bootstrap.servers","broker1:9092,broker2:9092");
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties = new KafkaProducer<String,String>(properties);
来解释一下这段代码
- 首先创建了一个 Properties 对象
- 使用
StringSerializer序列化器序列化 key / value 键值对 - 在这里我们创建了一个新的生产者对象,并为键值设置了恰当的类型,然后把 Properties 对象传递给他。
实例化生产者对象后,接下来就可以开始发送消息了,发送消息主要由下面几种方式
直接发送,不考虑结果
使用这种发送方式,不会关心消息是否到达,会丢失一些消息,因为 Kafka 是高可用的,生产者会自动尝试重发,这种发送方式和 UDP 运输层协议很相似。
同步发送
同步发送仍然使用 send() 方法发送消息,它会返回一个 Future 对象,调用 get() 方法进行等待,就可以知道消息时候否发送成功。
异步发送
异步发送指的是我们调用 send() 方法,并制定一个回调函数,服务器在返回响应时调用该函数。
下一节我们会重新讨论这三种实现。
向 Kafka 发送消息
简单消息发送
Kafka 最简单的消息发送如下:
ProducerRecord<String,String> record =
new ProducerRecord<String, String>("CustomerCountry","West","France");
producer.send(record);
代码中生产者(producer)的 send() 方法需要把 ProducerRecord 的对象作为参数进行发送,ProducerRecord 有很多构造函数,这个我们下面讨论,这里调用的是
public ProducerRecord(String topic, K key, V value) {}
这个构造函数,需要传递的是 topic主题,key 和 value。
把对应的参数传递完成后,生产者调用 send() 方法发送消息(ProducerRecord对象)。我们可以从生产者的架构图中看出,消息是先被写入分区中的缓冲区中,然后分批次发送给 Kafka Broker。
发送成功后,send() 方法会返回一个 Future(java.util.concurrent) 对象,Future 对象的类型是 RecordMetadata 类型,我们上面这段代码没有考虑返回值,所以没有生成对应的 Future 对象,所以没有办法知道消息是否发送成功。如果不是很重要的信息或者对结果不会产生影响的信息,可以使用这种方式进行发送。
我们可以忽略发送消息时可能发生的错误或者在服务器端可能发生的错误,但在消息发送之前,生产者还可能发生其他的异常。这些异常有可能是 SerializationException(序列化失败),BufferedExhaustedException 或 TimeoutException(说明缓冲区已满),又或是 InterruptedException(说明发送线程被中断)
同步发送消息
第二种消息发送机制如下所示
ProducerRecord<String,String> record =
new ProducerRecord<String, String>("CustomerCountry","West","France");
try{
RecordMetadata recordMetadata = producer.send(record).get();
}catch(Exception e){
e.printStackTrace();
}
这种发送消息的方式较上面的发送方式有了改进,首先调用 send() 方法,然后再调用 get() 方法等待 Kafka 响应。如果服务器返回错误,get() 方法会抛出异常,如果没有发生错误,我们会得到 RecordMetadata 对象,可以用它来查看消息记录。
生产者(KafkaProducer)在发送的过程中会出现两类错误:其中一类是重试错误,这类错误可以通过重发消息来解决。比如连接的错误,可以通过再次建立连接来解决;无主错误则可以通过重新为分区选举首领来解决。KafkaProducer 被配置为自动重试,如果多次重试后仍无法解决问题,则会抛出重试异常。另一类错误是无法通过重试来解决的,比如消息过大对于这类错误,KafkaProducer 不会进行重试,直接抛出异常。
异步发送消息
同步发送消息都有个问题,那就是同一时间只能有一个消息在发送,这会造成许多消息无法直接发送,造成消息滞后,无法发挥效益最大化。
比如消息在应用程序和 Kafka 集群之间一个来回需要 10ms。如果发送完每个消息后都等待响应的话,那么发送100个消息需要 1 秒,但是如果是异步方式的话,发送 100 条消息所需要的时间就会少很多很多。大多数时候,虽然Kafka 会返回 RecordMetadata 消息,但是我们并不需要等待响应。
为了在异步发送消息的同时能够对异常情况进行处理,生产者提供了回掉支持。下面是回调的一个例子
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("CustomerCountry", "Huston", "America");
producer.send(producerRecord,new DemoProducerCallBack());
class DemoProducerCallBack implements Callback {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception != null){
exception.printStackTrace();;
}
}
}
首先实现回调需要定义一个实现了org.apache.kafka.clients.producer.Callback的类,这个接口只有一个 onCompletion方法。如果 kafka 返回一个错误,onCompletion 方法会抛出一个非空(non null)异常,这里我们只是简单的把它打印出来,如果是生产环境需要更详细的处理,然后在 send() 方法发送的时候传递一个 Callback 回调的对象。
生产者分区机制
Kafka 对于数据的读写是以分区为粒度的,分区可以分布在多个主机(Broker)中,这样每个节点能够实现独立的数据写入和读取,并且能够通过增加新的节点来增加 Kafka 集群的吞吐量,通过分区部署在多个 Broker 来实现负载均衡的效果。
上面我们介绍了生产者的发送方式有三种:不管结果如何直接发送、发送并返回结果、发送并回调。由于消息是存在主题(topic)的分区(partition)中的,所以当 Producer 生产者发送产生一条消息发给 topic 的时候,你如何判断这条消息会存在哪个分区中呢?
这其实就设计到 Kafka 的分区机制了。
分区策略
Kafka 的分区策略指的就是将生产者发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略。
如果要自定义分区策略的话,你需要显示配置生产者端的参数 Partitioner.class,我们可以看一下这个类它位于 org.apache.kafka.clients.producer 包下
public interface Partitioner extends Configurable, Closeable {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
public void close();
default public void onNewBatch(String topic, Cluster cluster, int prevPartition) {}
}
Partitioner 类有三个方法,分别来解释一下
- partition(): 这个类有几个参数:
topic,表示需要传递的主题;key表示消息中的键值;keyBytes表示分区中序列化过后的key,byte数组的形式传递;value表示消息的 value 值;valueBytes表示分区中序列化后的值数组;cluster表示当前集群的原数据。Kafka 给你这么多信息,就是希望让你能够充分地利用这些信息对消息进行分区,计算出它要被发送到哪个分区中。 - close() : 继承了
Closeable接口能够实现 close() 方法,在分区关闭时调用。 - onNewBatch(): 表示通知分区程序用来创建新的批次
其中与分区策略息息相关的就是 partition() 方法了,分区策略有下面这几种
顺序轮训
顺序分配,消息是均匀的分配给每个 partition,即每个分区存储一次消息。就像下面这样

上图表示的就是轮训策略,轮训策略是 Kafka Producer 提供的默认策略,如果你不使用指定的轮训策略的话,Kafka 默认会使用顺序轮训策略的方式。
随机轮训
随机轮训简而言之就是随机的向 partition 中保存消息,如下图所示
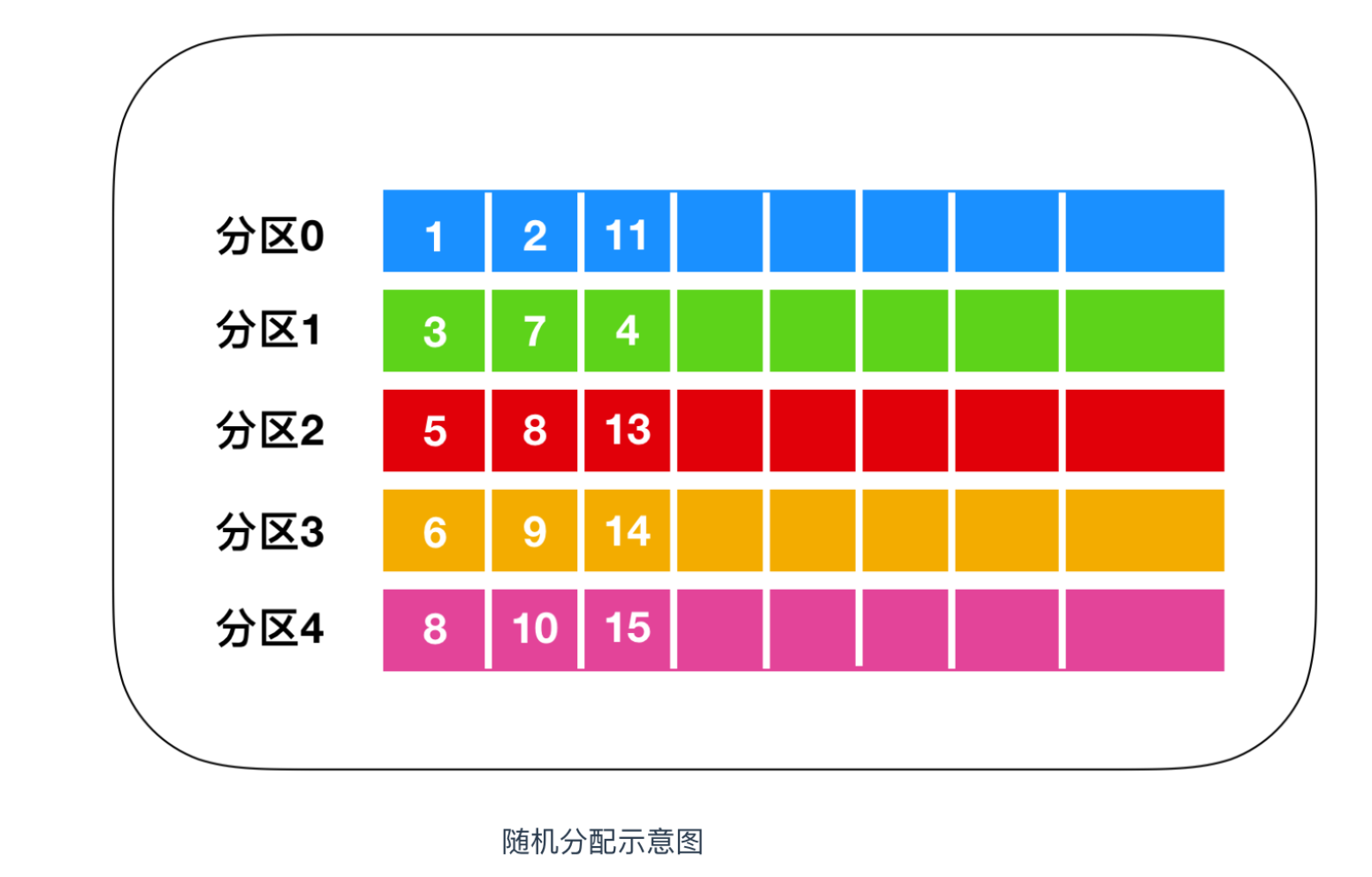
实现随机分配的代码只需要两行,如下
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
先计算出该主题总的分区数,然后随机地返回一个小于它的正整数。
本质上看随机策略也是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。事实上,随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了。
按照 key 进行消息保存
这个策略也叫做 key-ordering 策略,Kafka 中每条消息都会有自己的key,一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略,如下图所示
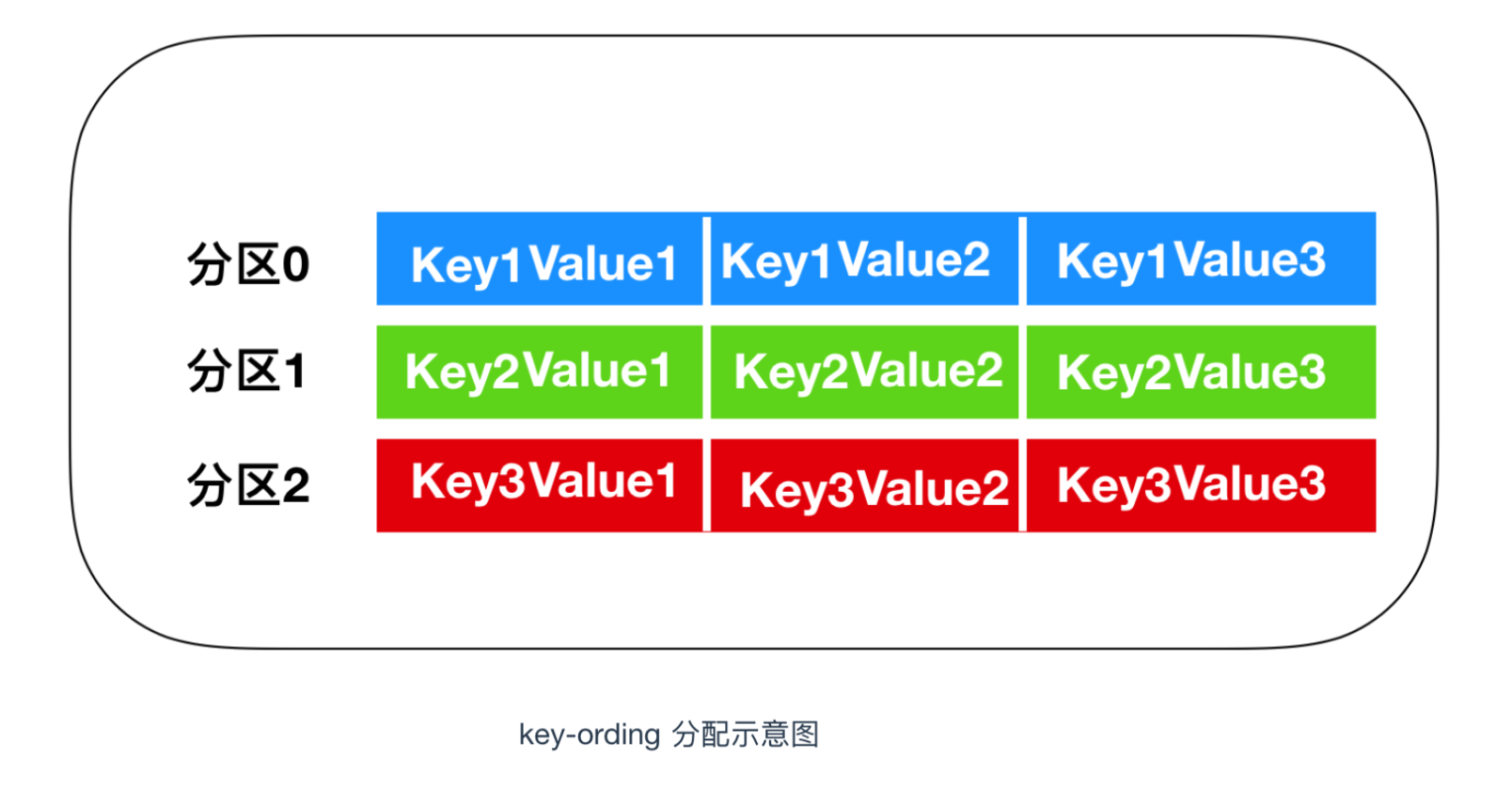
实现这个策略的 partition 方法同样简单,只需要下面两行代码即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();
上面这几种分区策略都是比较基础的策略,除此之外,你还可以自定义分区策略。
生产者压缩机制
压缩一词简单来讲就是一种互换思想,它是一种经典的用 CPU 时间去换磁盘空间或者 I/O 传输量的思想,希望以较小的 CPU 开销带来更少的磁盘占用或更少的网络 I/O 传输。如果你还不了解的话我希望你先读完这篇文章 程序员需要了解的硬核知识之压缩算法,然后你就明白压缩是怎么回事了。
Kafka 压缩是什么
Kafka 的消息分为两层:消息集合 和 消息。一个消息集合中包含若干条日志项,而日志项才是真正封装消息的地方。Kafka 底层的消息日志由一系列消息集合日志项组成。Kafka 通常不会直接操作具体的一条条消息,它总是在消息集合这个层面上进行写入操作。
在 Kafka 中,压缩会发生在两个地方:Kafka Producer 和 Kafka Consumer,为什么启用压缩?说白了就是消息太大,需要变小一点 来使消息发的更快一些。
Kafka Producer 中使用 compression.type 来开启压缩
private Properties properties = new Properties();
properties.put("bootstrap.servers","192.168.1.9:9092");
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("compression.type", "gzip");
Producer<String,String> producer = new KafkaProducer<String, String>(properties);
ProducerRecord<String,String> record =
new ProducerRecord<String, String>("CustomerCountry","Precision Products","France");
上面代码表明该 Producer 的压缩算法使用的是 GZIP
有压缩必有解压缩,Producer 使用压缩算法压缩消息后并发送给服务器后,由 Consumer 消费者进行解压缩,因为采用的何种压缩算法是随着 key、value 一起发送过去的,所以消费者知道采用何种压缩算法。
Kafka 重要参数配置
在上一篇文章 带你涨姿势的认识一下kafka中,我们主要介绍了一下 kafka 集群搭建的参数,本篇文章我们来介绍一下 Kafka 生产者重要的配置,生产者有很多可配置的参数,在文档里(http://kafka.apache.org/documentation/#producerconfigs)都有说明,我们介绍几个在内存使用、性能和可靠性方面对生产者影响比较大的参数进行说明
key.serializer
用于 key 键的序列化,它实现了 org.apache.kafka.common.serialization.Serializer 接口
value.serializer
用于 value 值的序列化,实现了 org.apache.kafka.common.serialization.Serializer 接口
acks
acks 参数指定了要有多少个分区副本接收消息,生产者才认为消息是写入成功的。此参数对消息丢失的影响较大
- 如果 acks = 0,就表示生产者也不知道自己产生的消息是否被服务器接收了,它才知道它写成功了。如果发送的途中产生了错误,生产者也不知道,它也比较懵逼,因为没有返回任何消息。这就类似于 UDP 的运输层协议,只管发,服务器接受不接受它也不关心。
- 如果 acks = 1,只要集群的 Leader 接收到消息,就会给生产者返回一条消息,告诉它写入成功。如果发送途中造成了网络异常或者 Leader 还没选举出来等其他情况导致消息写入失败,生产者会受到错误消息,这时候生产者往往会再次重发数据。因为消息的发送也分为
同步和异步,Kafka 为了保证消息的高效传输会决定是同步发送还是异步发送。如果让客户端等待服务器的响应(通过调用Future中的get()方法),显然会增加延迟,如果客户端使用回调,就会解决这个问题。 - 如果 acks = all,这种情况下是只有当所有参与复制的节点都收到消息时,生产者才会接收到一个来自服务器的消息。不过,它的延迟比 acks =1 时更高,因为我们要等待不只一个服务器节点接收消息。
buffer.memory
此参数用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果应用程序发送消息的速度超过发送到服务器的速度,会导致生产者空间不足。这个时候,send() 方法调用要么被阻塞,要么抛出异常,具体取决于 block.on.buffer.null 参数的设置。
compression.type
此参数来表示生产者启用何种压缩算法,默认情况下,消息发送时不会被压缩。该参数可以设置为 snappy、gzip 和 lz4,它指定了消息发送给 broker 之前使用哪一种压缩算法进行压缩。下面是各压缩算法的对比
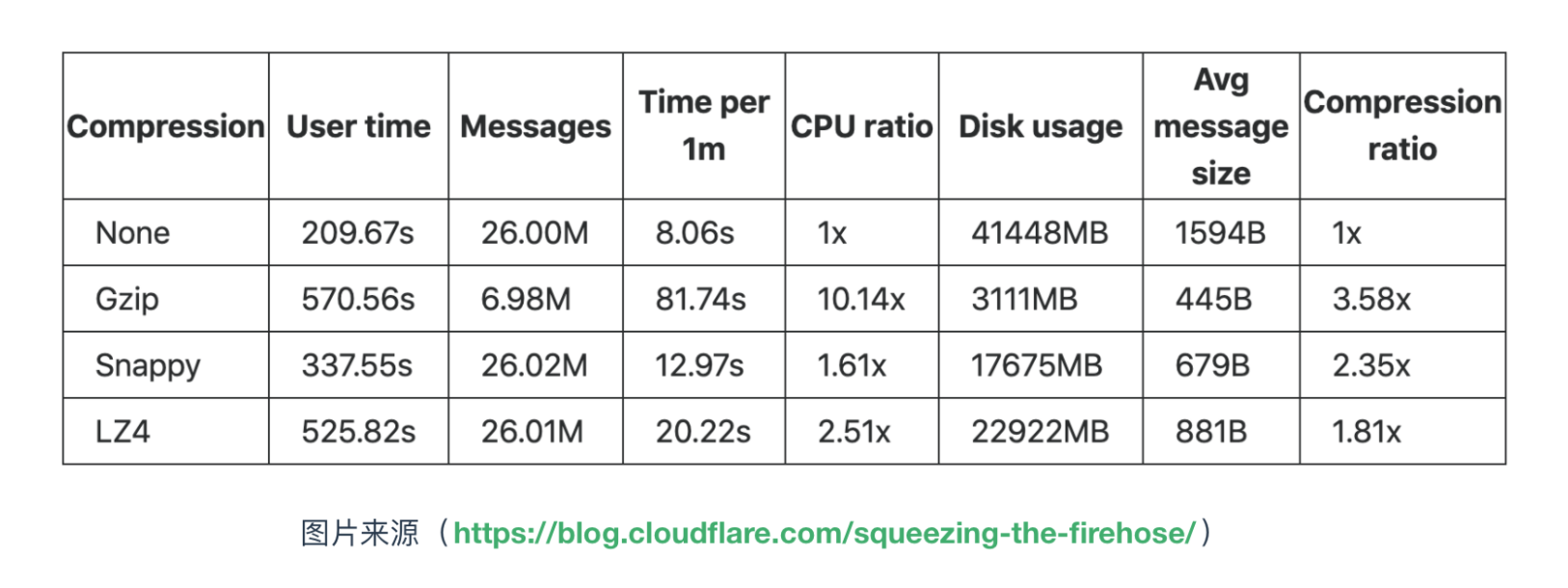
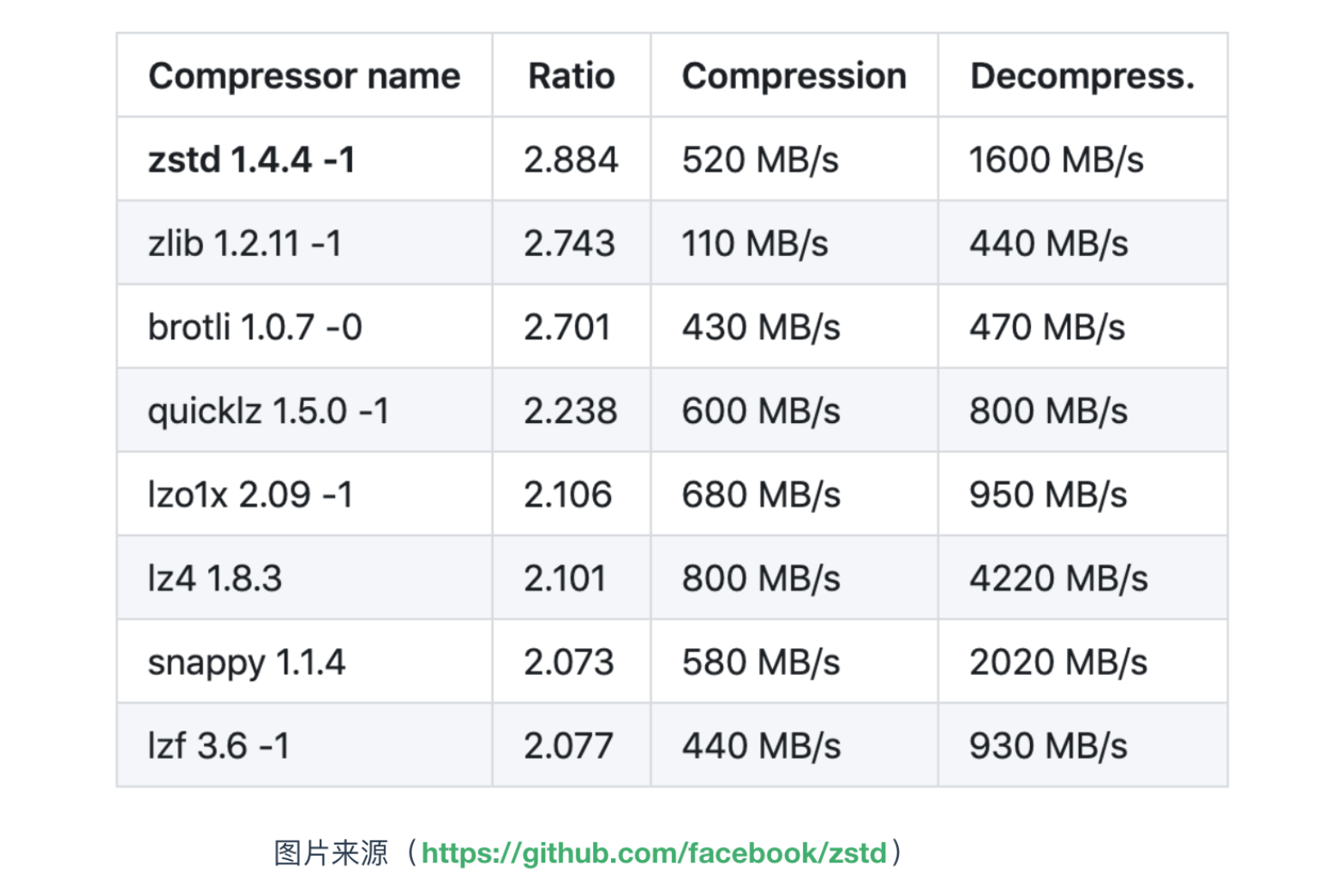
retries
生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到首领),在这种情况下,reteis 参数的值决定了生产者可以重发的消息次数,如果达到这个次数,生产者会放弃重试并返回错误。默认情况下,生产者在每次重试之间等待 100ms,这个等待参数可以通过 retry.backoff.ms 进行修改。
batch.size
当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。当批次被填满,批次里的所有消息会被发送出去。不过生产者井不一定都会等到批次被填满才发送,任意条数的消息都可能被发送。
client.id
此参数可以是任意的字符串,服务器会用它来识别消息的来源,一般配置在日志里
max.in.flight.requests.per.connection
此参数指定了生产者在收到服务器响应之前可以发送多少消息,它的值越高,就会占用越多的内存,不过也会提高吞吐量。把它设为1 可以保证消息是按照发送的顺序写入服务器。
timeout.ms、request.timeout.ms 和 metadata.fetch.timeout.ms
request.timeout.ms 指定了生产者在发送数据时等待服务器返回的响应时间,metadata.fetch.timeout.ms 指定了生产者在获取元数据(比如目标分区的首领是谁)时等待服务器返回响应的时间。如果等待时间超时,生产者要么重试发送数据,要么返回一个错误。timeout.ms 指定了 broker 等待同步副本返回消息确认的时间,与 asks 的配置相匹配----如果在指定时间内没有收到同步副本的确认,那么 broker 就会返回一个错误。
max.block.ms
此参数指定了在调用 send() 方法或使用 partitionFor() 方法获取元数据时生产者的阻塞时间当生产者的发送缓冲区已捕,或者没有可用的元数据时,这些方法就会阻塞。在阻塞时间达到 max.block.ms 时,生产者会抛出超时异常。
max.request.size
该参数用于控制生产者发送的请求大小。它可以指能发送的单个消息的最大值,也可以指单个请求里所有消息的总大小。
receive.buffer.bytes 和 send.buffer.bytes
Kafka 是基于 TCP 实现的,为了保证可靠的消息传输,这两个参数分别指定了 TCP Socket 接收和发送数据包的缓冲区的大小。如果它们被设置为 -1,就使用操作系统的默认值。如果生产者或消费者与 broker 处于不同的数据中心,那么可以适当增大这些值。
文章参考:
《Kafka 权威指南》
极客时间 -《Kafka 核心技术与实战》
http://kafka.apache.org/documentation
Kafka 源码
https://blog.cloudflare.com/squeezing-the-firehose/
https://github.com/facebook/zstd
关注公众号获取更多优质电子书,关注一下你就知道资源是有多好了

详解Kafka Producer的更多相关文章
- 【转】 详解Kafka生产者Producer配置
粘贴一下这个配置,与我自己的程序做对比,看看能不能完善我的异步带代码: ----------------------------------------- 详解Kafka生产者Produce ...
- 详解Kafka: 大数据开发最火的核心技术
详解Kafka: 大数据开发最火的核心技术 架构师技术联盟 2019-06-10 09:23:51 本文共3268个字,预计阅读需要9分钟. 广告 大数据时代来临,如果你还不知道Kafka那你就真 ...
- 一文详解Kafka API
摘要:Kafka的API有Producer API,Consumer API还有自定义Interceptor (自定义拦截器),以及处理的流使用的Streams API和构建连接器的Kafka Con ...
- kafka原理和实践(五)spring-kafka配置详解
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- RabbitMQ,Apache的ActiveMQ,阿里RocketMQ,Kafka,ZeroMQ,MetaMQ,Redis也可实现消息队列,RabbitMQ的应用场景以及基本原理介绍,RabbitMQ基础知识详解,RabbitMQ布曙
消息队列及常见消息队列介绍 2017-10-10 09:35操作系统/客户端/人脸识别 一.消息队列(MQ)概述 消息队列(Message Queue),是分布式系统中重要的组件,其通用的使用场景可以 ...
- kafka启动时出现FATAL Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer) java.io.IOException: Permission denied错误解决办法(图文详解)
首先,说明,我kafk的server.properties是 kafka的server.properties配置文件参考示范(图文详解)(多种方式) 问题详情 然后,我启动时,出现如下 [hadoop ...
- kafka的server.properties配置文件参考示范(图文详解)(多种方式)
简单点的,就是 kafka_2.11-0.8.2.2.tgz的3节点集群的下载.安装和配置(图文详解) 但是呢,大家在实际工作中,会一定要去牵扯到调参数和调优问题的.以下,是我给大家分享的kafka的 ...
- SpringBoot2 整合Kafka组件,应用案例和流程详解
本文源码:GitHub·点这里 || GitEE·点这里 一.搭建Kafka环境 1.下载解压 -- 下载 wget http://mirror.bit.edu.cn/apache/kafka/2.2 ...
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
随机推荐
- 1.linux系统基础笔记(互斥量、信号量)
操作系统是很多人每天必须打交道的东西,因为在你打开电脑的一刹那,随着bios自检结束,你的windows系统已经开始运行了.如果问大家操作系统是什么?可能有的人会说操作系统就是windows,就是那些 ...
- windows服务器多端口Redis安装步骤
1.从官网获取最新稳定版redis文件.按端口号复制多个文件,比如6379和6380端口的文件包, 修改各自Conf文件的port号,分别为6379和6380.然后重命名为redis6379.conf ...
- Map集合(双列集合)
Map集合(双列集合)Map集合是键值对集合. 它的元素是由两个值组成的,元素的格式是:key=value. Map集合形式:{key1=value1 , key2=value2 , key3=val ...
- Fiddle弱网测试
1.打开Fiddler,Rules->Performance->勾选 Simulate Modem Speeds,勾选之后访问网站会发现网络慢了很多: 接下来给大家解释一下这些个都是什么意 ...
- PHP call_user_func的一些用法和注意点
版本:PHP 5.6.28 在call_user_func的调用中: 1.参数的传递过程,并不是引用传值. 1 error_reporting(E_ERROR); // 此处不是E_ALL 2 $cu ...
- [NOIp2012] luogu P1083 借教室
该*的英语,这么长还要背. 题目描述 你有 nnn 个数 ai{a_i}ai,mmm 次操作,每次操作将 [l,r][l,r][l,r] 区间的每个数减去 ccc.要求任何时刻 ∀x∈[1,n]\f ...
- WPF实现放大镜
这是一个之前遗留的问题.wpf里面有很多很多的东西,我以前用的真的只是其中很小的一个角落都不到. 需求背景:图片来源于相机拍摄,由于对像素要求,拍出来的图像素比较高,原图尺寸为30722048,以目前 ...
- C# Halcon联合编程问题(二)
避免重复编辑同一篇随笔,有问题就开一个新的,哪怕会很短. 还是之前那个问题,halcon中的HObject转换为Bitmap的问题,在全网找相关的办法,三通道图像的HObject转换为C#中的Bitm ...
- Python之文件的使用
文件概述 读写文件是最常见的IO操作.Python内置了读写文件的函数,用法和C是兼容的. 读写文件前,我们先必须了解一下,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接 ...
- 5分钟彻底理解Redis持久化
Redis持久化 RDB快照 在默认情况下,Redis将内存数据库快照保存到dump.rdb的二进制文件中. 可以对Redis进行设置,让它在"N秒内数据集至少有N个改动", 这一 ...