python之爬取练习
练习要求爬取http://yuedu.anyv.net/网址的最大页码数和文章标题和链接
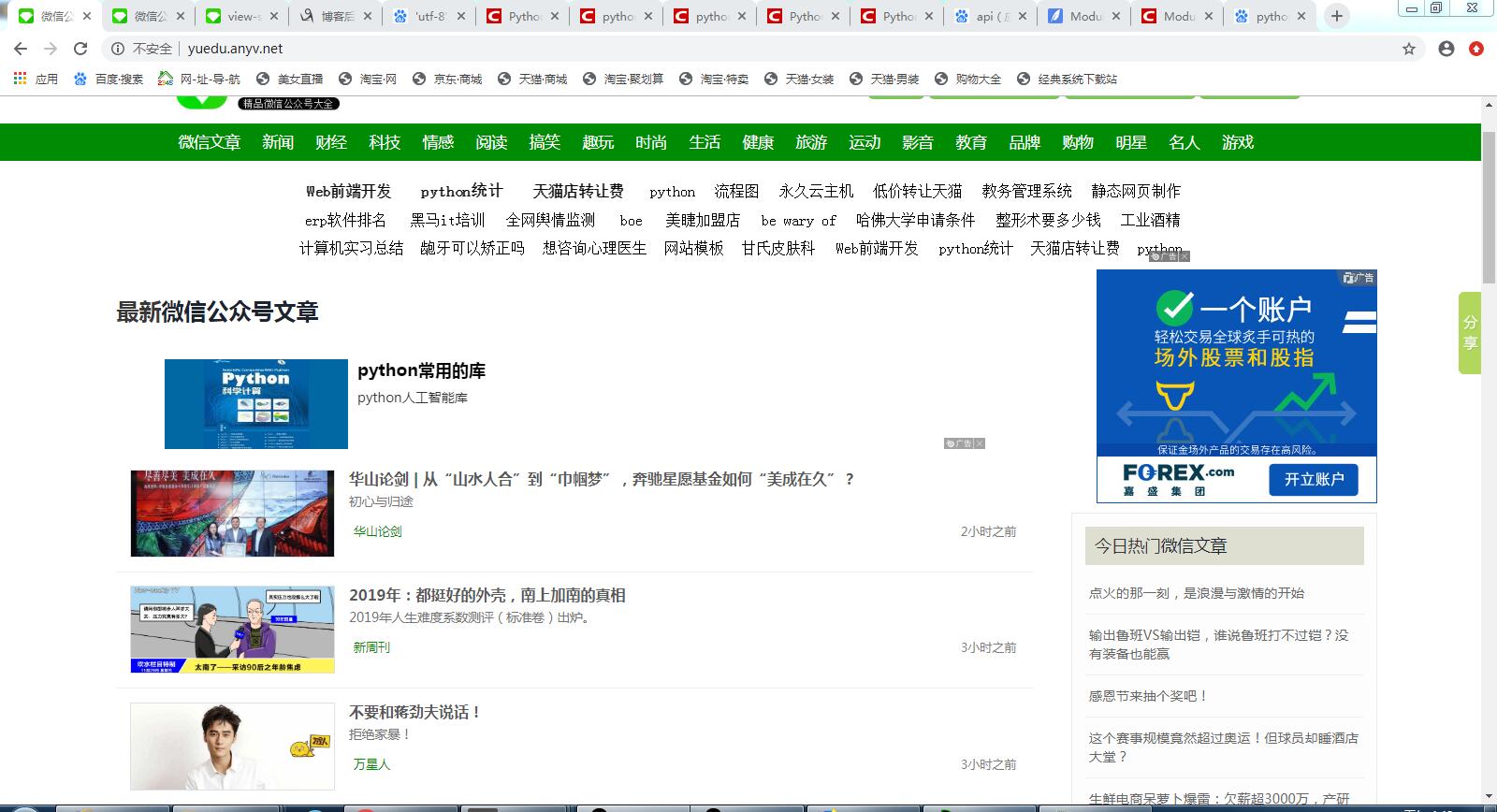
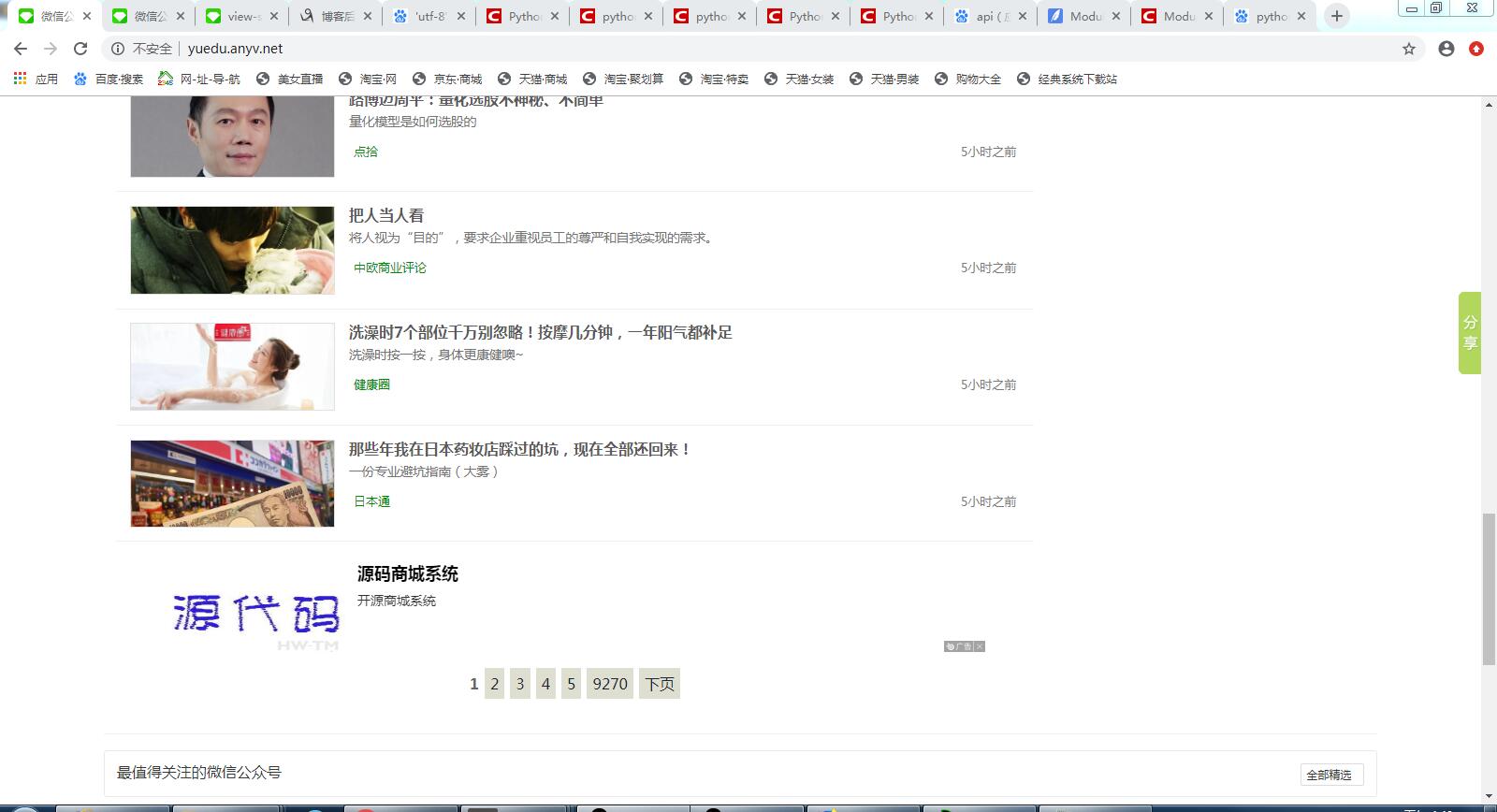
网址页面截图:
代码截图:
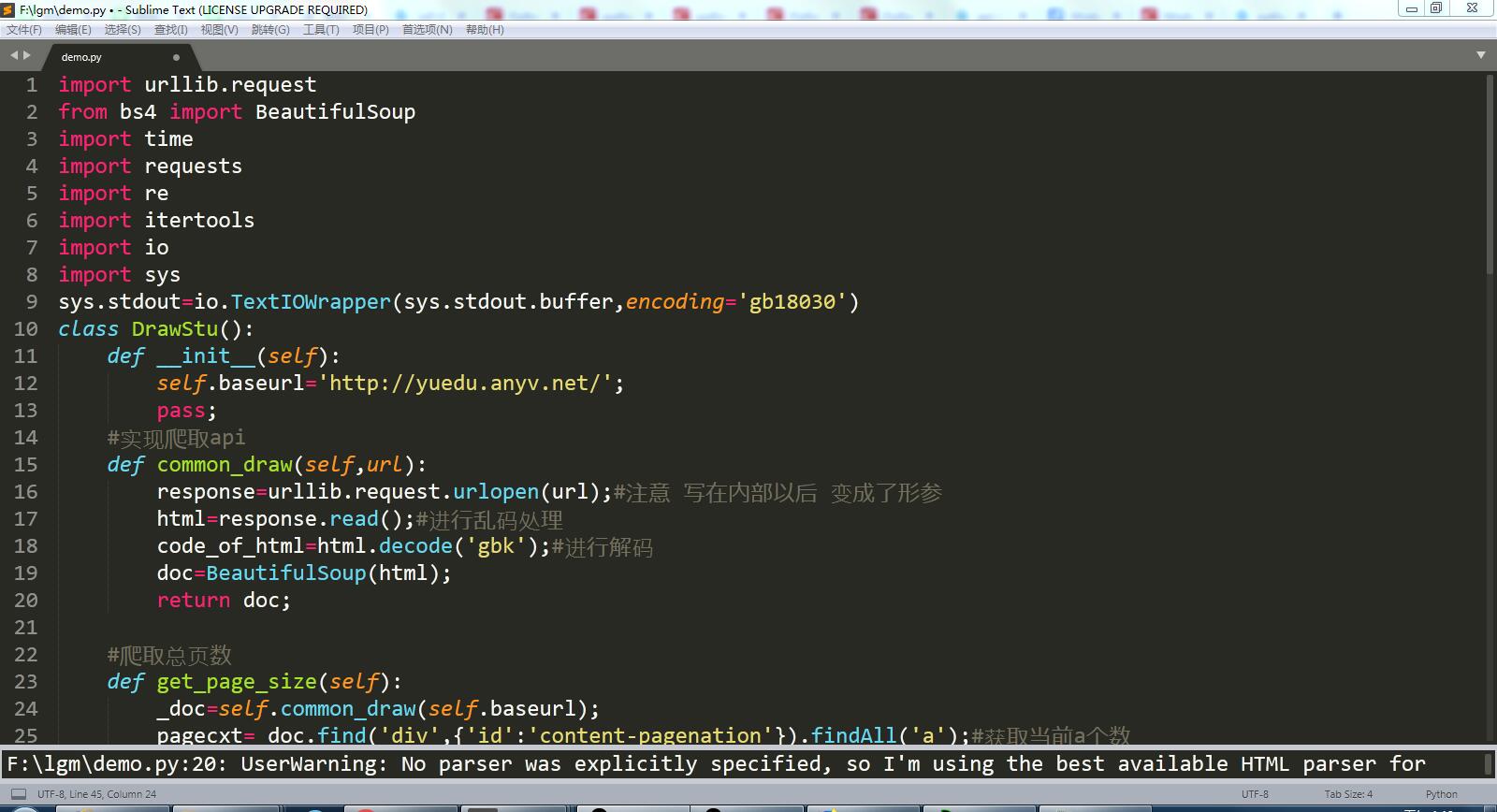

完整代码:
根据网页显示页码的方式,爬取的所有页码中倒数第二个页码是最大页码。
import urllib.request
from bs4 import BeautifulSoup
import time
import requests
import re
import itertools
import io
import sys
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
class DrawStu():
def __init__(self):
self.baseurl='http://yuedu.anyv.net/';
pass;
#实现爬取api
def common_draw(self,url):
response=urllib.request.urlopen(url);#注意 写在内部以后 变成了形参
html=response.read();#进行乱码处理
code_of_html=html.decode('gbk');#进行解码
doc=BeautifulSoup(html);
return doc; #爬取总页数
def get_page_size(self):
_doc=self.common_draw(self.baseurl);
pagecxt=_doc.find('div',{'id':'content-pagenation'}).findAll('a');#获取当前a个数
size=len(pagecxt);
maxsize=pagecxt[size-].text;#获取倒数第二个进行获取里面值就是最大值
maxsize=int(maxsize)
return maxsize; #爬取文章标题和链接
def get_title(self):
r=requests.get("http://yuedu.anyv.net/")
r.encoding=r.apparent_encoding
result=r.text
bs=BeautifulSoup(result,'html.parser')
pagecxt=bs.find('div',{'class':'content'}).findAll('div',{'class':'image group'});
for x in pagecxt:
pageinfo=x.find('div',{'class':'grid news_desc'});
title=pageinfo.find('h3').find('a').text;
print("文章标题:")
print(title)
link=pageinfo.find('h3').find('a').get('href');
print("文章链接:")
print(link) D=DrawStu();
if __name__ == '__main__':
size=D.get_page_size();
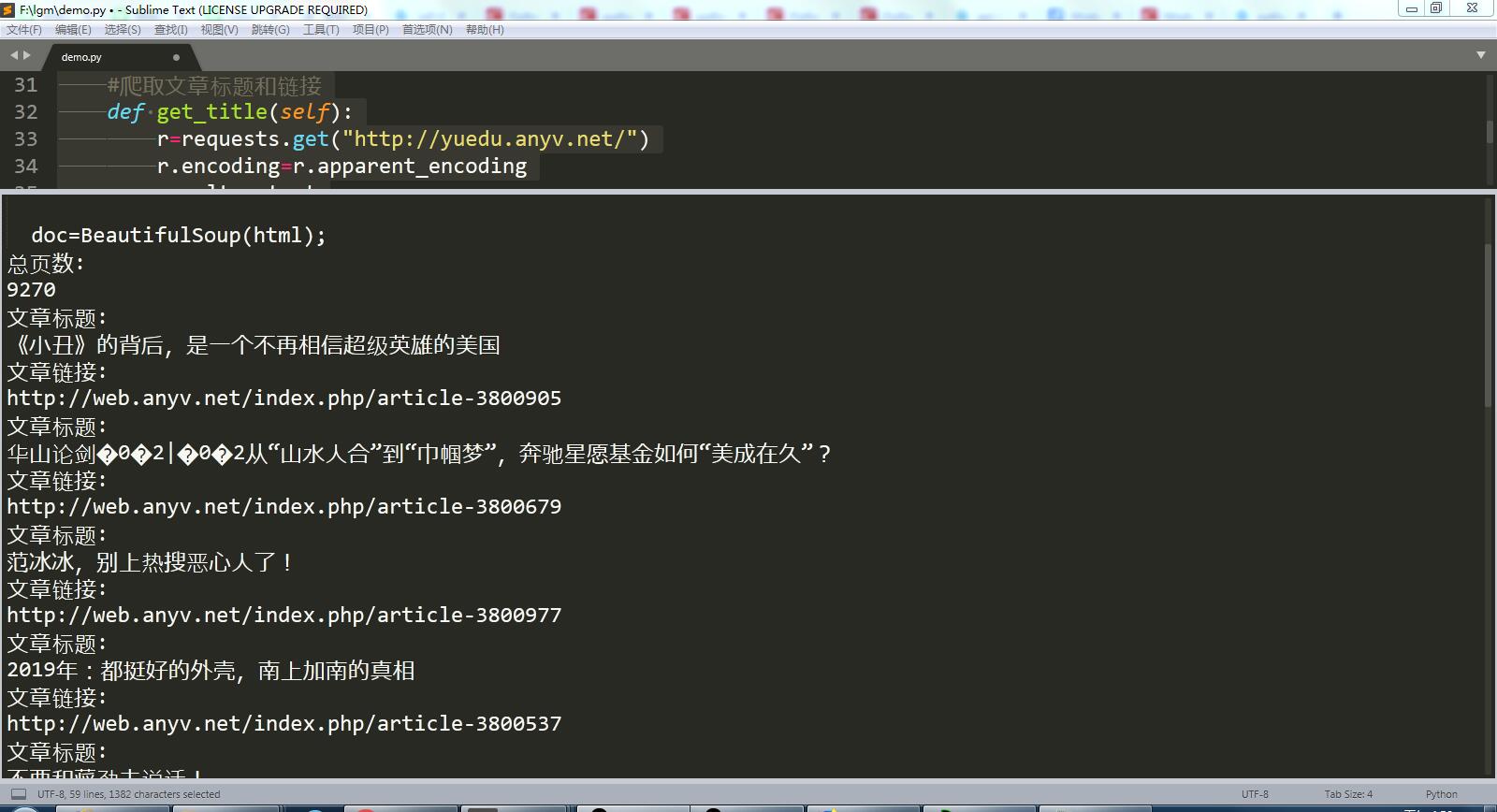
print("总页数:")
print(size)
title=D.get_title();
print(title)
运行结果截图:
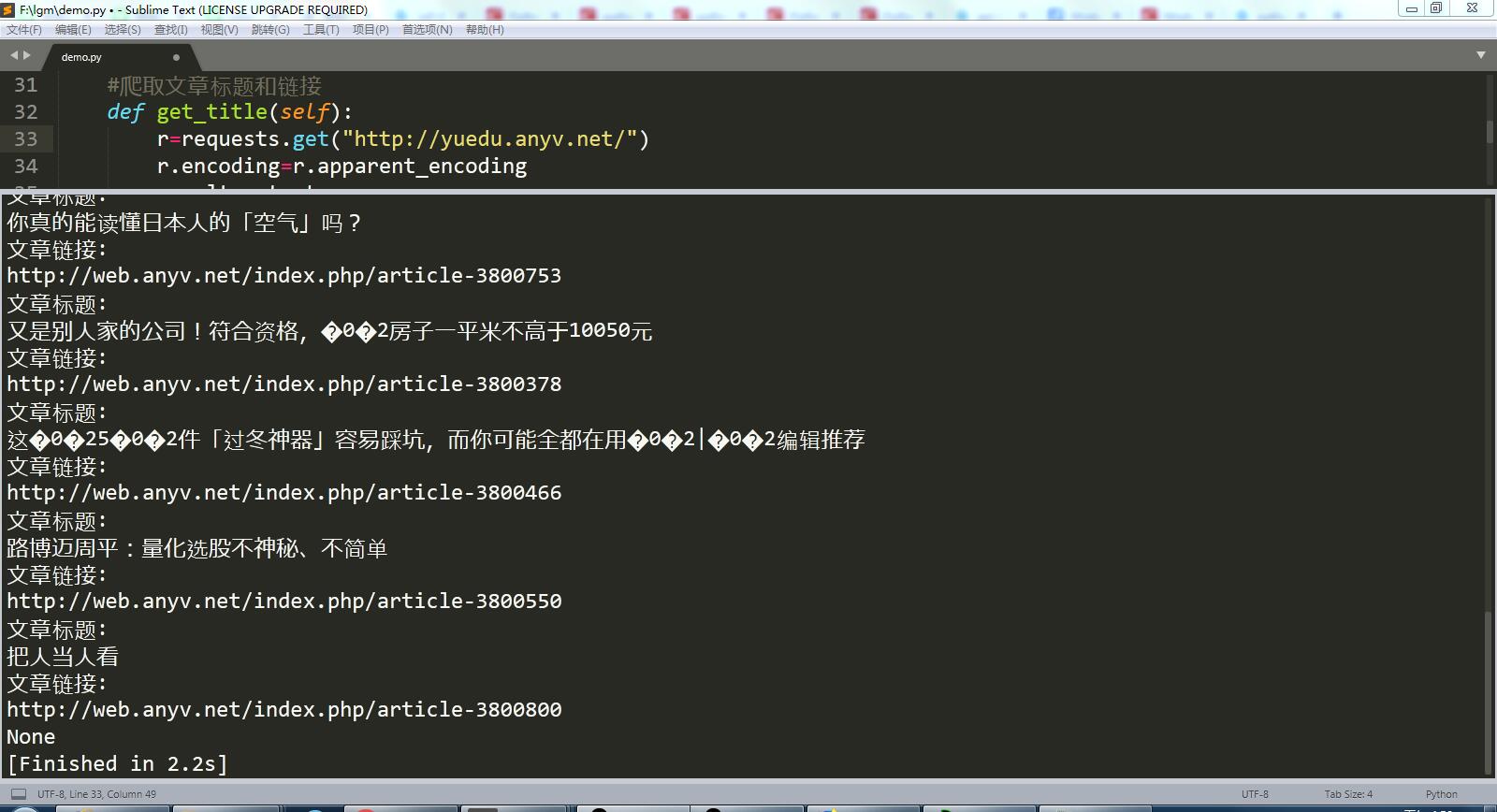
python之爬取练习的更多相关文章
- 大神:python怎么爬取js的页面
大神:python怎么爬取js的页面 可以试试抓包看看它请求了哪些东西, 很多时候可以绕过网页直接请求后面的API 实在不行就上 selenium (selenium大法好) selenium和pha ...
- python连续爬取多个网页的图片分别保存到不同的文件夹
python连续爬取多个网页的图片分别保存到不同的文件夹 作者:vpoet mail:vpoet_sir@163.com #coding:utf-8 import urllib import ur ...
- python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet mail:vpoet_sir@163.com 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 # ...
- python大规模爬取京东
python大规模爬取京东 主要工具 scrapy BeautifulSoup requests 分析步骤 打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点 我们可以看到这个页面 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
- python 3 爬取百度图片
python 3 爬取百度图片 学习了:https://blog.csdn.net/X_JS612/article/details/78149627
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
随机推荐
- springcloud~配置中心~对敏感信息加密
简介 RSA非对称加密有着非常强大的安全性,HTTPS的SSL加密就是使用这种方法进行HTTPS请求加密传输的.因为RSA算法会涉及Private Key和Public Key分别用来加密和解密,所以 ...
- ionic项目使用Google FCM插件和Google maps插件打包android报错冲突问题
这段时间在调FCM推送服务的插件 ,原本以为去年调通过,应该很容易,没想到还是出问题了.现将问题及解决方法整理如下,仅供参考: 先看打包报错截图: 详细报错信息:Please fix ...
- Ubuntu 18.04安装MySQL
安装 MySQL 服务端 sudo apt-get install mysql-server 等待安装完成. 检查 mysql 服务状态 servive mysql status 登录 mysql 客 ...
- java编译报错: 找不到或无法加载主类 Demo.class 的解决方法
原因:java 命令后面的文件不能有后缀名. 解决方法:运行java时候,后面的文件去掉后缀名.
- Django使用MySQL数据库的流程
Django使用MySQL数据库的流程 手动创建一个MySQL数据库 配置数据库 ENGINE MySQL NAME 数据库的名字 HOST ip PORT 3306 USER 用户名 PASSWOR ...
- java之子类对象实例化过程
假设现在有这么一个父类: public class Person{ public Person(){} public String name = "tom"; public int ...
- Linux下部署SSM,通过启动tomcat即可运行
Linux下部署SSM项目 1. Java环境配置(JRE&JDK) 安装JDK8:sudo yum install java-1.8.0-openjdk 将操作系统配置为默认使用JDK8:s ...
- IT兄弟连 HTML5教程 设置IE9以下版本浏览器支持HTML5
HTML2.HTML5刚发布时由于各浏览器之间的标准不统一,开发者的时间都浪费在解决Web浏览器之间的兼容性上.但由于W3C和WHATWG对HTML5新版本的制定,以及近年来对HTML5的使用,再加上 ...
- MySQL数据以全量和增量方式,同步到ES搜索引擎
本文源码:GitHub·点这里 || GitEE·点这里 一.配置详解 场景描述:MySQL数据表以全量和增量的方式向ElasticSearch搜索引擎同步. 1.下载内容 elasticsearch ...
- Nginx安装及配置反向代理
本片博客记录在ubuntu16下安装nginx,以及如何实现负载均衡 安装nginx 如果是新机器,安装相关依赖环境 sudo apt install build-essential sudo apt ...