用Python操作文件
用Python操作文件
用word操作一个文件的流程如下:
1、找到文件,双击打开。
2、读或修改。
3、保存&关闭。
用Python操作文件也差不多:
f=open(filename) # 打开文件
f.write("我是野生程序员") # 写操作
f.read() #读操作
f.close() #保存并关闭
不过有一点跟人肉操作word文档不同,就是word文档只要打开了,就即可以读、又可以修改。 但Python比较变态,只能以读、创建、追加 3种模式中的任意一种打开文件,不能即写又读。
一、操作模式
- r 只读模式
- w 创建模式,若文件已存在,则覆盖旧文件
- a 追加模式,新数据会写到文件末尾
二、创建文件
f = open(file='C:/工作日常/staff.txt',mode='w')
f.write("Kwan CEO 100W\n")
f.write("KK 人事 5000\n")
f.close()
三、只读模式
f = open(file='兼职白领学生空姐模特护士联系方式.txt',mode='r')
print(f.readline()) # 读一行
print('------分隔符-------')
data = f.read() # 读所有,剩下的所有
print(data)
f.close()
执行结果:
马纤羽 深圳 173 50 13744234523
------分隔符-------
乔亦菲 广州 172 52 15823423525
罗梦竹 北京 175 49 18623423421
刘诺涵 北京 170 48 18623423765
岳妮妮 深圳 177 54 18835324553
贺婉萱 深圳 174 52 18933434452
叶梓萱 上海 171 49 18042432324
你得有这么个文件才能用上面的代码。。。
四、追加模式
f = open(file='兼职白领学生空姐模特护士联系方式.txt',mode='a')
f.write("黑姑娘 北京 168 48\n") # 会追加到文件尾部
f.close()
五、循环文件
f = open(file='兼职白领学生空姐模特护士联系方式.txt',mode='r')
for line in f:
line = line.split()
name,addr,height,weight,phone = line
height = int(height)
weight = int(weight)
if height > 170 and weight <= 50:
print(line)
f.close()
输出:
['马纤羽', '深圳', '173', '50', '13744234523']
['罗梦竹', '北京', '175', '49', '18623423421']
['叶梓萱', '上海', '171', '49', '18042432324']
六、其它功能
def mode(self) -> str:
# 返回文件打开的模式
def name(self) -> str:
# 返回文件名
def fileno(self, *args, **kwargs): # real signature unknown
# 返回文件句柄在内核中的索引值,以后做IO多路复用时可以用到
def flush(self, *args, **kwargs): # real signature unknown
# 把文件从内存buffer里强制刷新到硬盘
def readable(self, *args, **kwargs): # real signature unknown
# 判断是否可读
def readline(self, *args, **kwargs): # real signature unknown
# 只读一行,遇到\r or \n为止
def seek(self, *args, **kwargs): # real signature unknown
'''
把操作文件的光标移到指定位置
*注意seek的长度是按字节算的, 字符编码存每个字符所占的字节长度不一样。
如“路飞学城” 用gbk存是2个字节一个字,用utf-8就是3个字节,因此以gbk打开时,seek(4) 就把光标切换到了“飞”和“学”两个字中间。
但如果是utf8,seek(4)会导致,拿到了飞这个字的一部分字节,打印的话会报错,因为处理剩下的文本时发现用utf8处理不了了,因为编码对不上了。少了一个字节
'''
def seekable(self, *args, **kwargs): # real signature unknown
# 判断文件是否可进行seek操作
def tell(self, *args, **kwargs): # real signature unknown
# 返回当前文件操作光标位置
def truncate(self, *args, **kwargs): # real signature unknown
# 按指定长度截断文件
# *指定长度的话,就从文件开头开始截断指定长度,不指定长度的话,就从当前位置到文件尾部的内容全去掉。
def writable(self, *args, **kwargs): # real signature unknown
# 判断文件是否可写
七、混合模式
- w+ 写读 , 这个功能基本没什么意义,它会创建一个新文件 ,写一段内容,可以再把写的内容读出来,没什么卵用。
- r+ 读写,能读能写,但都是写在文件最后,跟追加一样。
- a+ 追加读,文件一打开时光标会在文件尾部,写的数据全会是追加的形式。
r+ 模式示例:
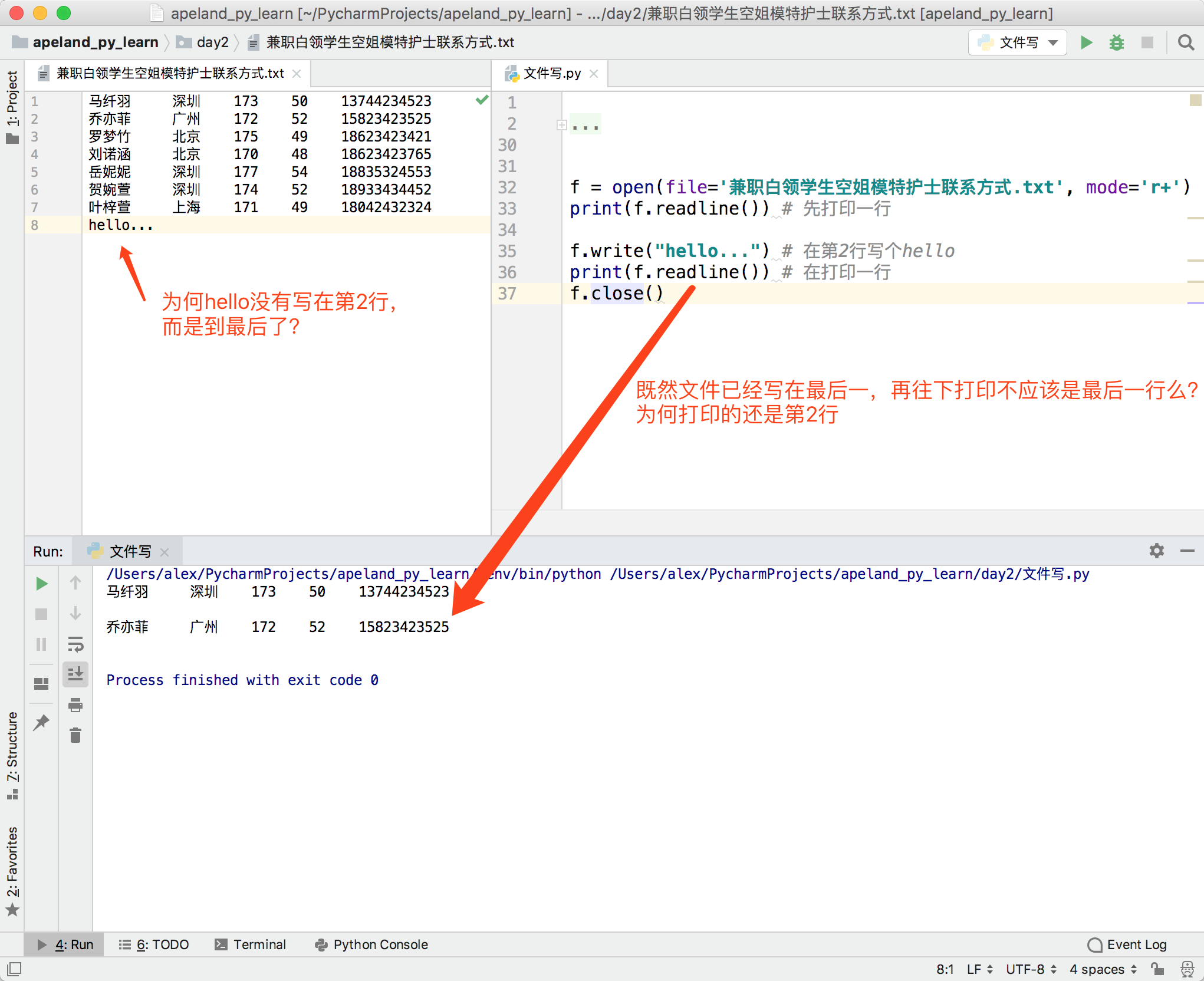
因为默认就是往文件尾部写入。
八、修改文件
尝试直接以r+模式打开文件,默认会把新增的内容追加到文件最后面。但我想要的是修改中间的内容 ,怎么办? 为什么会把内容添加到尾部呢?(最新测试r+会从头覆盖,测试代码如下)

问:为什么原有数据会被覆盖呢?
这是硬盘的存储原理导致的,当你把文件存到硬盘上,就在硬盘上划了一块空间,存数据,等你下次打开这个文件 ,seek到一个位置,每改一个字,就是把原来的覆盖掉,如果要插入,是不可能的,因为后面的数据在硬盘上不会整体向后移。所以就出现 当前这个情况 ,你想插入,却变成了会把旧内容覆盖掉。
问:但是人家word, vim 都可以修改文件 呀,你这不能修改算个什么玩意?
并没说就不能修改了,你想修改当然可以,就是不要在硬盘上修改,把内容全部读到内存里,数据在内存里可以随便增删改查,修改之后,把内容再全部写回硬盘,把原来的数据全部覆盖掉。vim word等各种文本编辑器都是这么干的。
问:说的好像有道理,但你又没看过word软件的源码,你凭什么这么笃定?
不需要看源码,硬盘的存储原理决定了word必须这么干 ,不信的话,还有个简单的办法来确认我说的,就是用word or vim读一个编辑一个大文件 ,至少几百MB的,你 会发现,加载过程会花个数十秒,这段时间干嘛了? cpu 去玩了?去上厕所啦? 当然不是,是在努力把数据 从硬盘上读到内存里。
问:还有更好的方式么?
没有。
占硬盘方式的文件修改代码示例:
f_name = "兼职白领学生空姐模特护士联系方式.txt"
f_new_name = "%s.new" % f_name
old_str = "刘诺涵"
new_str = "[黑姑娘]"
f = open(f_name,'r')
f_new = open(f_new_name,'w')
for line in f:
if old_str in line:
new_line = line.replace(old_str,new_str)
else:
new_line = line
f_new.write(new_line)
f.close()
f_new.close()
上面的代码,会生成一个修改后的新文件 ,原文件不动,若想覆盖原文件:
import os
f_name = "兼职白领学生空姐模特护士联系方式.txt"
f_new_name = "%s.new" % f_name
old_str = "刘诺涵"
new_str = "[黑姑娘]"
f = open(f_name,'r')
f_new = open(f_new_name,'w')
for line in f:
if old_str in line:
new_line = line.replace(old_str,new_str)
else:
new_line = line
f_new.write(new_line)
f.close()
f_new.close()
os.rename(f_new_name,f_name) #把新文件名字改成原文件 的名字,就把之前的覆盖掉了,windows使用os.replace # 帮助文档说明replace会覆盖原文件
用Python操作文件的更多相关文章
- Python操作文件、文件夹、字符串
Python 字符串操作 去空格及特殊符号 s.strip().lstrip().rstrip(',') 复制字符串 #strcpy(sStr1,sStr2) sStr1 = 'strcpy' sSt ...
- Python操作文件和目录
Python操作文件和目录 读写文件比较简单,有一点特别注意就好了 windows下Python默认打开的文件以gbk解码,而一般我们的文件是utf-8编码的,所以如果文本含有中文,就会出现异常或者乱 ...
- python操作文件练习,配置haproxy
在使用python操作文件的时候,特别是对于网络设备,通常操作配置文件,会简化配置量,配置文件加载到内存中,运行时使用的是内存中的配置,内存中配置修改后立即生效,如果不将配置内容保存到硬盘中,则下次重 ...
- Python操作文件-20181121
Python操作文件 Python操作文件和其他语言一样,操作的过程无非是先定位找到文件.打开文件,然后对文件进行操作,操作完成后关闭文件即可. 文件操作方式:对文件进行操作,主要就是读.写的方式,p ...
- 使用python操作文件实现购物车程序
使用python操作文件实现购物车程序 题目要求如下: 实现思路 始终维护一张字典,该字典里保存有用户账号密码,购物车记录等信息.在程序开始的时候读进来,程序结束的时候写回文件里去.在登录注册的部分, ...
- python操作文件案例二则
前言 python 对于文件及文件夹的操作. 涉及到 遍历文件夹下所有文件 ,文件的读写和操作 等等. 代码一 作用:查找文件夹下(包括子文件夹)下所有文件的名字,找出 名字中含有中文或者空格的文件 ...
- open -python操作文件
一打开文件 二操作文件 三关闭文件 open(文件,模式,编码),打开文件----->0101010(以二进制的方式打开)------>编码(open默认utf-8编码)------> ...
- Python操作文件文档
需要帮老师将44G的图书分类一下,人工当然累死了.所以用Python大法处理一下. 思路是读取文件目录下的书名,然后去百度百科查分类,如果还没有就去豆瓣,当当查.哪一个先找到其余的就不用找了.如果没有 ...
- Python 操作文件、文件夹、目录大全
# -*- coding: utf-8 -*- import os import shutil # 一. 路径操作:判断.获取和删除 #1. 得到当前工作目录,即当前Python脚本工作的目录路径: ...
随机推荐
- 请使用switch语句和if...else语句,计算2008年8月8日这一天,是该年中的第几天。
请使用switch语句和if...else语句,计算2008年8月8日这一天,是该年中的第几天. #include <stdio.h> int main() { /* 定义需要计算的日期 ...
- C#中属性的解析
一.域的概念 C#中域是指成员变量和方法,在OOP编程中(面向对象编程)我们要求用户只知道类是干什么的,而不许知道如何完成的,或者说不允许访问类的内部,对于有必要在类外可见的域,我们用属性来表达,所以 ...
- go杂货铺
json序列化 内存中变成可存储或传输的过程称之为序列化(dict,split,struct转string) package main import ( "encoding/json&quo ...
- Python3 反射
反射 python面向对象中的反射:通过字符串的形式操作对象相关的属性 hasattr(obj,name) # hasattr(obj, name) # 判断一个对象是否有指定的属性name,返回Tr ...
- HelloDjango 第 07 篇:创作后台开启,请开始你的表演!
作者:HelloGitHub-追梦人物 文中涉及的示例代码,已同步更新到 HelloGitHub-Team 仓库 在此之前我们完成了 django 博客首页视图的编写,我们希望首页展示发布的博客文章列 ...
- 记一次上线部分docker不打日志的问题排查
一次正常的上线,发了几台docker后,却发现有的机器打了info.log里面有日志,有的没有.排查问题开始: 第一:确认这台docker是否有流量进来,确认有流量进来. 第二:确认这台docker磁 ...
- ggplot2 |legend参数设置,图形精雕细琢
本文首发于微信公众号“生信补给站”,https://mp.weixin.qq.com/s/A5nqo6qnlt_5kF3_GIrjIA 学习了ggplot2|详解八大基本绘图要素后,就可以根据自己的需 ...
- 还在用if else?策略模式了解一下!
在公司负责的就是订单取消业务,老系统中各种类型订单取消都是通过if else 判断不同的订单类型进行不同的逻辑.在经历老系统的折磨和产品需求的不断变更,决定进行一次大的重构:消灭 if else. 接 ...
- Windos 上逆天又好用的软件有哪些?
谷歌浏览器 Chrome 浏览器是大名鼎鼎的科技公司谷歌开发的一款浏览器,国内的360浏览器等大多都是基于谷歌开源出的浏览器内核,然后给他穿了一层360的衣服.至于性能和启动速度上来讲,我个人觉得Ch ...
- Spring Boot 与 Mybatis、Mysql整合使用的例子
第一步: 创建一个SpringBoot的工程,在其中的Maven依赖配置中添加对JDBC.MyBatis.Mysql Driver的依赖具体如下: <!-- JDBC --> <de ...