GC回收算法&&GC回收器
GC回收算法
什么是垃圾?
类比日常生活中,如果一个东西经常没被使用,那么就可以说是垃圾。
同理,如果一个对象不可能再被引用,那么这个对象就是垃圾,应该被回收。
垃圾:不可能再被引用的对象。
finalize方法
- 在对象没有被引用时调用
- 在Object类里定义
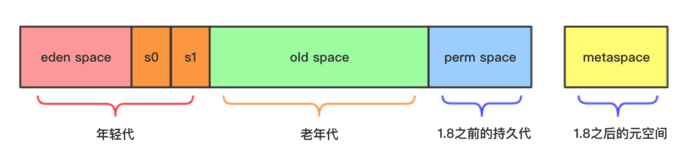
新生代与老年代
IBM公司的研究表明,在新生代中的对象 98% 是朝生夕死的。
在实际的 JVM 新生代划分中,不是采用等分为两块内存的形式。而是分为:Eden 区域、Survivorfrom 区域、Survivorto 区域 这三个区域。
所以在HotSpot虚拟机中,JVM 将内存划分为一块较大的Eden空间和两块较小的Survivor空间,其大小占比是8:1:1。当回收时,将Eden和Survivofrom中还存活的对象一次性复制到Survivorto空间上,最后清理掉Survivorfrom和刚才用过的Eden空间。
新生代一般占据堆的1/3空间,老年代占据2/3。
判断对象是否存活
引用计数法
在一个对象被引用时加一,被去除引用时减一,这样我们就可以通过判断引用计数是否为零来判断一个对象是否为垃圾。这种方法我们一般称之为「引用计数法」。主流的Java虚拟机里面都没有选用引用计数算法来管理内存
什么是循环引用?(环)
A 引用了 B,B 引用了 C,C 引用了 A,它们各自的引用计数都为 1。但是它们三个对象却从未被其他对象引用,(假设有1000个对象时,这三个就是垃圾;如果只有4个对象,那么另外一个就是垃圾)只有它们自身互相引用。从垃圾的判断思想来看,它们三个确实是不被其他对象引用的,但是此时它们的引用计数却不为零。
可达性分析算法
通过一系列名为”GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的。
GC Roots:
- 虚拟机栈中引用的对象
- 方法区静态属性引用的对象
- 方法区常量引用的对象
- JNI引用的对象(Native方法)
根搜索算法:一种通过遍历的方式判断对象是否可达的垃圾标记算法。
垃圾回收算法
垃圾回收——标记清除算法(适用老年代)
它将垃圾回收分为两个阶段:标记阶段和清除阶段。
在标记阶段,标记所有从根节点出发的可达对象。因此,所有未被标记的对象就是未被引用的垃圾对象。
在清除阶段,清除所有未被标记的对象。
问题:产生空间碎片。
垃圾回收——复制算法(适合年轻代)
将内存分为两部分,每次只使用其中一部分。在垃圾回收时,将正在使用的内存中的存活对象复制到未使用的内存块中,之后清除正在使用的内存块中的所有对象,交换两个内存的角色,完成垃圾回收。
问题:不会产生空间碎片,但内存折半
垃圾回收——标记整理算法(适合老年代。)
对比于标记清除算法,在清除阶段,它会将所有的存活对象移动到内存的另一端。之后清理边界之外的所有空间。
这种算法既避免了碎片的产生,又不需要两块相同的内存空间,因此性价比较高。
“因地制宜”——分代算法
分代算法,就是根据 JVM 内存的不同内存区域,采用不同的垃圾回收算法。
例如对于存活对象少的新生代区域,比较适合采用复制算法。这样只需要复制少量对象,便可完成垃圾回收,并且还不会有内存碎片。
而对于老年代这种存活对象多的区域,比较适合采用标记压缩算法或标记清除算法,这样不需要移动太多的内存对象。
GC回收器
Serial 回收器
- 单线程串行回收
- 使用复制算法
- 会产生较长时间的停顿(Stop the world)
- 不会产生线程切换的开销
通过JVM参数-XX:+UseSerialGC可以使用串行垃圾回收器。
ParNew回收器
- 多线程并行回收
- 新生代回收器,采用复制算法
参数控制:-XX:+UseParNewGC
Parallel Scavenge回收器
- 多线程并行回收
- 新生代回收器,采用复制算法
- 追求高吞吐量,充分利用CPU资源【吞吐量优先】
开启参数:-XX:+UseParallelGC
GC自适应调节策略:Parallel Scavenge收集器可设置-XX:+UseAdptiveSizePolicy参数
当开关打开时不需要手动指定新生代的大小(-Xmn)、Eden与Survivor区的比例(-XX:SurvivorRation)、晋升老年代的对象年龄(-XX:PretenureSizeThreshold)等,虚拟机会根据系统的运行状况收集性能监控信息,动态设置这些参数以提供最优的停顿时间和最高的吞吐量,这种调节方式称为GC的自适应调节策略。
Serial Old 回收器
- 老年代单线程回收
- 使用标记整理算法
Parallel Old回收器
- 老年代多线程回收
- 使用标记整理算法
串行与并行的效率分析:
以新生登记为例,假设新生人数较多,数量在5000,使用串行的方式,可以理解为一个人复制5000的登记工作;
效率可想而知。
使用并行的方式可以理解为有100个人负责登记,效率就会显著提升。
但如果新生只有50个人,一个人登记就绰绰有余了。
新生的数量可以理解为GC回收对象的数量,而负责登记的人就是CPU的核心计算数量。
对于新生代,回收次数频繁,使用并行方式高效。
对于老年代,回收次数少,使用串行方式节省资源。(CPU并行需要切换线程,串行可以省去切换线程的资源)
CMS回收器
- 并发低停顿收集器
- 使用标记清除算法
- 四个阶段
- 初始标记 (标记GC Roots可以直接关联的对象,速度很快)
- 并发标记 (进行GC Roots Tracing,判断对象是否存活)
- 重新标记 (校准并发标记对象的存活状态)
- 并发清除 (回收标记的对象)
- 初始标记和重新标记仍然需要Stop The World
- CMS缺点
- 由于并发带来的CPU资源消耗
- 由于并发收集在回收过程中产生的浮动垃圾无法清除
- 使用标记清除算法带来的空间碎片问题
G1回收器
- 使用于JDK1.7。
- 使用分代垃圾回收策略。
- 新特性:使用分区算法。使内存不再连续。
- 支持很大的堆,高吞吐量。
通过JVM参数 -XX:+UseG1GC 使用G1垃圾回收器
G1特点:
并行与并发:并行体现在G1可以利用CPU的多个核心,缩短stop the world时间;并发体现在某些收集器和Java线程可以同时执行。
分代收集
空间整合,G1收集器采用标记整理算法,不会产生内存空间碎片。分配大对象时不会因为无法找到连续空间而提前触发下一次GC。
能建立可预测的时间停顿模型,可以指定在M时间段内,垃圾回收时间不能超过N
并行与并发:
并行:同时处理多个任务。
并发:串行处理多个任务,但任务之间的切换很快,感觉上是并行执行。
并行是建立在多核CPU上的,多核指的是在一块CPU上集成多个计算引擎。引擎之间可同时进行运算。
举例:
单核运算时代就好比400米短跑,每跑完一个400米执行完一个任务。
多核运算时代可以理解为4*100接力,虽然单个任务的执行和单核一样,但对于多个任务来说,单核是需要完成400的全部距离才能进行第二个任务。但多核只要第一个人跑完了100米,就可以开始第二个任务了。
并行处理多个任务的能力可以理解为核心之间的接力赛。
并发是指通过CPU在多个任务之间快速切换来达到同时执行的效果。
- 分区算法(G1内存结构)
在G1回收器之前,垃圾回收器分配的内存都是连续的。
在G1回收器中,垃圾回收器将内存分为大量区块。
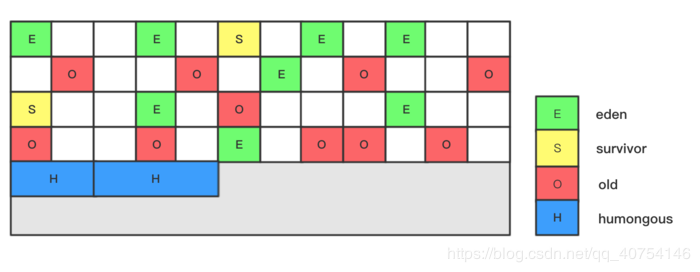
humongous:存储巨型对象,当对象超过普通区块的一半时,分配一个巨型区块。
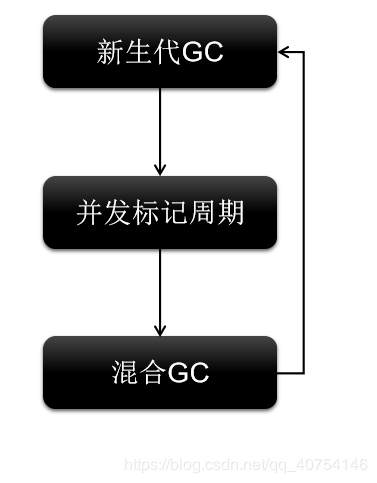
- G1回收器工作步骤
- 新生代 GC
- 并发标记周期
- 混合收集
- 如果需要,可能进行 FullGC
新生代GC
Eden区被占满,新生代GC启动,回收Eden和Survivor。
注:survivor会被回收掉一部分,但回收后至少有一个survivor区存在。
为什么???
新生代GC采用复制算法,将Eden区中的存活对象复制到Survivor区中。
并发标记周期
- 初始标记:标记从根节点直接可达的对象。(会产生全局停顿)
- 根区域扫描:扫描Survivor区直接可达的老年代区域对象,并标记。(和应用程序并发,但不能和新生代GC同时执行【新生代GC有修改Survivor的操作】)
- 并发标记:扫描并查找整个堆内存存活对象,并标记。(可以被新生代GC打断)
- 再次标记:由于应用程序持续进行,需要修正标记结果。(会产生全局停顿)
- 独占清理:计算各个区域的存活对象和GC回收比例,并进行排序,识别可以混合回收的区域。为下阶段做铺垫。(有停顿)
- 并发清理阶段:识别并清理完全空闲的区域。
混合回收
优先回收垃圾比例高的区域。(GC:Garbage First)
执行年轻代和老年代GC。
混合GC执行多次之后,会触发新生代GC。然后循环:
GC的两种触发情况
Minor GC:新对象产生,申请Eden区失败后会触发Minor GC
Full GC:对整个堆的对象进行清理。
触发条件
System.gc()方法的调用
老年代空间不足
方法区空间不足
了解GC日志
查看JDK8默认使用哪种回收器
java -XX:+PrintCommandLineFlags -version
-XX:+UseParallelGC
使用Parallel Scavenge新生代回收器和Parallel Old老年代回收器

[GC (Allocation Failure) [PSYoungGen: 5986K->696K(8704K)] 5986K->704K(9216K), 0.0018526 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 4792K->696K(8704K)] 4800K->704K(9216K), 0.0031653 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 4945K->680K(8704K)] 4953K->688K(9216K), 0.0022002 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 4776K->712K(8704K)] 4784K->720K(9216K), 0.0007493 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 4808K->648K(8704K)] 4816K->656K(9216K), 0.0008800 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 4744K->664K(8704K)] 4752K->672K(9216K), 0.0008349 secs] [Times: user=0.00 sys=0.02, real=0.00 secs]
[GC (Allocation Failure) --[PSYoungGen: 4760K->4760K(8704K)] 4768K->5268K(9216K), 0.0022344 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Ergonomics) [PSYoungGen: 4760K->113K(8704K)] [ParOldGen: 508K->496K(512K)] 5268K->609K(9216K), [Metaspace: 3222K->3222K(1056768K)], 0.0069196 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[GC (Allocation Failure) [PSYoungGen: 4209K->192K(8704K)] 4705K->688K(9216K), 0.0007751 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 4288K->160K(8704K)] 4784K->656K(9216K), 0.0018608 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Allocation Failure
表明本次引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了。
PSYoungGen
新生代Eden和FromSpace,PS指Parallel Scavenge ,
PSOldGen
老年代
[PSYoungGen: 5986K->696K(8704K)] 5986K->704K(9216K)
中括号内:GC回收前年轻代堆大小,回收后大小,(年轻代堆总大小)
括号外:GC回收前年轻代和老年代大小,回收后大小,(年轻代和老年代总大小)
user代表用户态回收耗时,sys内核态回收耗时,rea实际耗时。
GC回收算法&&GC回收器的更多相关文章
- JVM总括二-垃圾回收:GC Roots、回收算法、回收器
JVM总括二-垃圾回收:GC Roots.回收算法.回收器 目录:JVM总括:目录 一.判断对象是否存活 为了判断对象是否存活引入GC Roots,如果一个对象与GC Roots没有直接或间接的引用关 ...
- GC回收算法
GC回收算法 https://www.cnblogs.com/missOfAugust/p/9528166.html Java语言引入了垃圾回收机制,让C++语言中令人头疼的内存管理问题迎刃而解,使得 ...
- GC回收算法--当女友跟你提分手!
Java语言引入了垃圾回收机制,让C++语言中令人头疼的内存管理问题迎刃而解,使得我们Java狗每天开开心心地创建对象而不用管对象死活,这些都是Java的垃圾回收机制带来的好处.但是Java的垃圾回收 ...
- java虚拟机学习总结之GC回收算法与GC收集器
GC回收算法 1.标记清除算法分为标记阶段和清除阶段标记阶段:通过特定的判断方式找出无用的对象实例并将其标记清除阶段:将已标记的对象所占用的内存回收缺点:运行多次以后容易产生空间碎片,当需要一整段连续 ...
- JVM内存模型及GC回收算法
该篇博客主要对JVM内存模型以及GC回收算法以自己的理解和认识做以记录. 内存模型 GC垃圾回收 1.内存模型 从上图可以看出,JVM分为 方法区,虚拟机栈,本地方法栈,堆,计数器 5个区域.其中最为 ...
- JVM垃圾回收算法及回收器详解
引言 本文主要讲述JVM中几种常见的垃圾回收算法和相关的垃圾回收器,以及常见的和GC相关的性能调优参数. GC Roots 我们先来了解一下在Java中是如何判断一个对象的生死的,有些语言比如Pyth ...
- 初步了解JVM第三篇(堆和GC回收算法)
在<初步了解JVM第一篇>和<初步了解JVM第二篇>中,分别介绍了: 类加载器:负责加载*.class文件,将字节码内容加载到内存中.其中类加载器的类型有如下:执行引擎:负责解 ...
- JVM完整详解:内存分配+运行原理+回收算法+GC参数等
不管是BAT面试,还是工作实践中的JVM调优以及参数设置,或者内存溢出检测等,都需要涉及到Java虚拟机的内存模型.内存分配,以及回收算法机制等,这些都是必考.必会技能. JVM内存模型 JVM内存模 ...
- JVM中的垃圾回收算法GC
GC是分代收集算法:因为Young区,需要回收垃圾对象的次数操作频繁:Old区次数上较少收集:基本不动Perm区.每个区特点不一样,所以就没有通用的最好算法,只有合适的算法. GC的4大算法 1.引用 ...
随机推荐
- 腾讯云centos7 从零搭建laravel项目
目标,访问网站出现: -----------------------分割线---------------------------------------- 一.Laravel Homestead 环境 ...
- JavaScript基础学习第六天
目标: 能够使用对象的方式处理数据 ☞ 代码预解析: 1. 变量提升 :当程序中遇到定义变量后,就会将该变量的定义提升到当前作用域的开始位置,不包括变量的赋值 2. 函数提升:当程序中遇到函数的声明时 ...
- Hive映射HBase表的几种方式
1.Hive内部表,语句如下 CREATE TABLE ods.s01_buyer_calllogs_info_ts( key string comment "hbase rowkey&qu ...
- Spring cloud Feign不支持对象传参解决办法[完美解决]
spring cloud 使用 Feign 进行服务调用时,不支持对象参数. 通常解决方法是,要么把对象每一个参数平行展开,并使用 @RequestParam 标识出每一个参数,要么用 @Reques ...
- 浏览器输入URL到返回页面的全过程
[问题描述] 在浏览器输入www.baidu.com,然后,浏览器显示相应的百度页面,这个过程究竟发生了什么呢? [第一步,解析域名,找到主机] 正常情况下,浏览器会缓存DNS一段时间,一般2分钟到3 ...
- C#的委托事件总结
什么是委托?1.委托是C#中由用户自定义的一个类型.2.类表示的是数据和方法的集合,而委托实际上是一个能持有对某个或某些方法的引用的类.3.与其他的类不同,委托类能拥有一个签名,并且他只能持有与他的签 ...
- Android使用xUtils3上传图片报错解决:java.lang.ArrayIndexOutOfBoundsException: 70918
今天在使用安卓xUtils3框架配合SmartUpload框架上传图片到Java服务端时,遇到了一个莫名其妙的错误: 安卓端代码如下: 似乎并没有发现什么问题,以前在用xUtils2.6老版本时也是这 ...
- Liunx查看后1000行的命令以及查看中间部分
linux 如何显示一个文件的某几行(中间几行) [一]从第3000行开始,显示1000行.即显示3000~3999行 cat filename | tail -n +3000 | head -n 1 ...
- 如何实现css渐变圆角边框
最近设计师的风格发生突变,一句话概括就是,能用渐变的地方绝对不用纯色.这不,就整出了一个渐变圆角边框.这渐变好做,圆角好做,渐变圆角也没问题,可是在加个边框还是有点坑的.没办法,看看怎么实现吧 bor ...
- API开发之接口安全(三)----sign有效时间
之前生成的sign和校验sign我们已经完全掌握了.但是仅仅凭借这样的sign是无法满足我们的需求的,如果一个黑客通过抓包抓到你的数据 他可以去修改你的header为这样的 body为那样的 也是可以 ...