Oracle 分区表管理之组合分区(分区索引失效与性能比较)
整体结构如下:
Oracle 分区表管理之组合分区(分区索引失效与性能比较)
虽然老早就使用了分区表,终于有时间写有关分区表的内容;不是所有的场景数据量变大需要用到分区表,一般单表数据超过2g可以考虑使用分区表,有关oracle分区表,其中单个字段作为分区比较简单,就不作说明,Oracle 11g之前只有两种组合分区,即rangeàhash,rangeàlist;而11g之后新增四种组合分区rangeàrange,listàrange,listàhash,listàlist;当然12c自动分区更强大了,没有分区字段的值也可以插入该表,自动建一个分区。
分区表能够更好的进行数据的管理以及进行性能的优化(减少访问路径,相当于大表切成多个小表,减少IO开销),其中分区中重点关注的是那些字段应该作为分区字段以及分区的管理以及分区索引
在建分区的时候,也可以建立联合分区,比如:
create table range_part_mult_col_tab (id number,deal_date date,area_code number,nbr number,contents varchar2(4000))
partition by range (area_code,deal_date)
(
partition p_591_201901 values less than (591,TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_591_201902 values less than (591,TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_591_201903 values less than (591,TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_591_201904 values less than (591,TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_591_201905 values less than (591,TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_591_201906 values less than (591,TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_591_201907 values less than (591,TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_591_201908 values less than (591,TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_591_201909 values less than (591,TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_591_201910 values less than (591,TO_DATE('2019-11-01', 'YYYY-MM-DD')),
partition p_591_201911 values less than (591,TO_DATE('2019-12-01', 'YYYY-MM-DD')),
partition p_591_201912 values less than (591,TO_DATE('2020-01-01', 'YYYY-MM-DD')),
partition p_591_202001 values less than (591,TO_DATE('2020-02-01', 'YYYY-MM-DD')),
partition p_591_202002 values less than (591,TO_DATE('2020-03-01', 'YYYY-MM-DD')),
partition p_591_max values less than (591,maxvalue),
partition p_592_201901 values less than (592,TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_592_201902 values less than (592,TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_592_201903 values less than (592,TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_592_201904 values less than (592,TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_592_201905 values less than (592,TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_592_201906 values less than (592,TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_592_201907 values less than (592,TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_592_201908 values less than (592,TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_592_201909 values less than (592,TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_592_201910 values less than (592,TO_DATE('2019-11-01', 'YYYY-MM-DD')),
partition p_592_201911 values less than (592,TO_DATE('2019-12-01', 'YYYY-MM-DD')),
partition p_592_201912 values less than (592,TO_DATE('2020-01-01', 'YYYY-MM-DD')),
partition p_592_202001 values less than (592,TO_DATE('2020-02-01', 'YYYY-MM-DD')),
partition p_592_202002 values less than (592,TO_DATE('2020-03-01', 'YYYY-MM-DD')),
partition p_592_max values less than (592,maxvalue),
partition p_593_201901 values less than (593,TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_593_201902 values less than (593,TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_593_201903 values less than (593,TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_593_201904 values less than (593,TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_593_201905 values less than (593,TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_593_201906 values less than (593,TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_593_201907 values less than (593,TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_593_201908 values less than (593,TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_593_201909 values less than (593,TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_593_201910 values less than (593,TO_DATE('2019-11-01', 'YYYY-MM-DD')),
partition p_593_201911 values less than (593,TO_DATE('2019-12-01', 'YYYY-MM-DD')),
partition p_593_201912 values less than (593,TO_DATE('2020-01-01', 'YYYY-MM-DD')),
partition p_593_202001 values less than (593,TO_DATE('2020-02-01', 'YYYY-MM-DD')),
partition p_593_202002 values less than (593,TO_DATE('2020-03-01', 'YYYY-MM-DD')),
partition p_593_max values less than (593,maxvalue)
);
还有就是可以简化建分区的语句(TEMPLATE关键字,不过每个主分区只有子分区的这些字段,使用有很大的局限性):
create table range_list_part_tab (
id number,
deal_date date,
area_code number,
nbr number,
contents varchar2(4000)
)
partition by range (deal_date)
subpartition by list (area_code)
subpartition TEMPLATE
(subpartition p_591 values (591),
subpartition p_592 values (592),
subpartition p_593 values (593),
subpartition p_594 values (594),
subpartition p_595 values (595),
subpartition p_596 values (596),
subpartition p_597 values (597),
subpartition p_598 values (598),
subpartition p_599 values (599),
subpartition p_other values (DEFAULT)
)
( partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_201910 values less than (TO_DATE('2019-11-01', 'YYYY-MM-DD')),
partition p_201911 values less than (TO_DATE('2019-12-01', 'YYYY-MM-DD')),
partition p_201912 values less than (TO_DATE('2020-01-01', 'YYYY-MM-DD')),
partition p_202001 values less than (TO_DATE('2020-02-01', 'YYYY-MM-DD')),
partition p_202002 values less than (TO_DATE('2020-03-01', 'YYYY-MM-DD')),
partition p_max values less than (maxvalue))
;
一.组合分区管理:
truncate
新建一张表组合分区的表进行truncate 操作:
create table range_list_part_tab (id number,deal_date date,area_code number,nbr number,contents varchar2(4000))
partition by range (deal_date)
subpartition by list (area_code)
subpartition TEMPLATE
(subpartition p_591 values (591),
subpartition p_592 values (592),
subpartition p_593 values (593),
subpartition p_594 values (594),
subpartition p_595 values (595),
subpartition p_596 values (596),
subpartition p_597 values (597),
subpartition p_598 values (598),
subpartition p_599 values (599),
subpartition p_other values (DEFAULT))
( partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_201910 values less than (TO_DATE('2019-11-01', 'YYYY-MM-DD')),
partition p_201911 values less than (TO_DATE('2019-12-01', 'YYYY-MM-DD')),
partition p_201912 values less than (TO_DATE('2020-01-01', 'YYYY-MM-DD')),
partition p_202001 values less than (TO_DATE('2020-02-01', 'YYYY-MM-DD')),
partition p_202002 values less than (TO_DATE('2020-03-01', 'YYYY-MM-DD'))
);
--数据的插入
insert into range_list_part_tab(id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 100000;
commit;
比如我现在需要清理2019年一月分的数据(truncate)操作。
1) 可以逐个清理子分区表
查看主分区包含的子分区
SELECT subpartition_name FROM USER_TAB_SUBPARTITIONS WHERE partition_name='P_201901' GROUP BY subpartition_name;

select count(*) from range_list_part_tab partition(P_201901);

select count(*) from range_list_part_tab subpartition(P_201901_P_591);

alter table range_list_part_tab truncate SUBPARTITION P_201901_P_591;
alter table range_list_part_tab truncate SUBPARTITION P_201901_P_592;

这个操作只适合某些子分区数据操作,如果子分区数量一多就需要进行主分区操作
2) 清理分区
alter table range_list_part_tab truncate PARTITION P_201901;

drop
1) 删除子分区
select count(*) from range_list_part_tab partition(P_201902);
SELECT subpartition_name FROM USER_TAB_SUBPARTITIONS WHERE partition_name='P_201902' GROUP BY subpartition_name;

删除一下几个分区:
alter table range_list_part_tab drop subpartition P_201902_P_591;
alter table range_list_part_tab drop subpartition P_201902_P_592;
alter table range_list_part_tab drop subpartition P_201902_P_593;
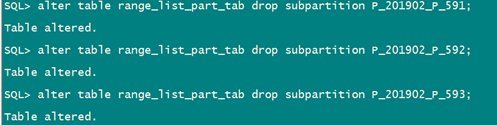
查看该分区数据减少了

删除的分区进入回收站,如果回收站开着的话,如果误删,可以进行闪回,或者查询插入。
SELECT * FROM DBA_RECYCLEBIN;

2) 删除主分区
alter table range_list_part_tab drop partition P_201902;

alter table range_list_part_tab drop partition P_201902;
select count(*) from range_list_part_tab partition(P_201902);
add
如果主分区是介于最小以及最大分区之间,那么添加不了(有max的需要删掉在添加),只能添加值大于最后一个分区的主分区以及相对应的子分区。
1) 组合分区添加主分区(添加主分区必须加至少一个子分区)
其中在以后的分区表中添加主分区和子分区,注意:添加的分区必须是表中主分区是最大的分区才能添加,而且添加主分区的时候,至少要添加一个子分区,否则后面添加不了子分区,只能算一级主分区,不能加子分区。
alter table range_list_part_tab add partition P_202003 values less than (TO_DATE(' 2020-04-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS')) (subpartition P_202003_p_591 values (591));
也可以一部到位添加主分区和子分区。
2) 组合分区添加子分区(单独添加子分区)
这个是单独的添加子分区
alter table range_list_part_tab MODIFY PARTITION P_202003 add subpartition P_202003_p_592 values (592);
alter table range_list_part_tab MODIFY PARTITION P_202003 add subpartition P_202003_p_593 values (593);

这个是加主分区的时候没有添加子分区,后面加不了子分区

split(分裂)
为啥会用到分区的分裂,大多数情况是分区数据分布的不均衡,其中一个分区数据量特别大,分区表并没有提升性能,而需要的结果往往是只需要比较小的结果集。
1) 只有主分区的分裂
查看语法:


---分区表数值分区的SPLIT
drop table part_tab_split purge;
create table part_tab_split (id int,col2 int ,col3 int ,contents varchar2(4000))
partition by range (id)
(
partition p1 values less than (10000),
partition p2 values less than (20000),
partition p_max values less than (maxvalue)
)
;
insert into part_tab_split select rownum ,rownum+1,rownum+2,rpad('*',400,'*') from dual connect by rownum <=90000;
commit;
select partition_name, segment_type, bytes
from user_segments
where segment_name ='PART_TAB_SPLIT';

此种情况在某些场景中,需要p_max 分区进行分裂成多个分区,便于提升性能;
select max(id) from part_tab_split partition(p1);
select max(id) from part_tab_split partition(p2);
select max(id) from part_tab_split partition(p_max);

打算分裂成7个分区,每个分区10000值递增。
alter table part_tab_split SPLIT PARTITION P_MAX at (30000) into (PARTITION p3 ,PARTITION P_MAX);
alter table part_tab_split SPLIT PARTITION P_MAX at (40000) into (PARTITION p4 ,PARTITION P_MAX);
alter table part_tab_split SPLIT PARTITION P_MAX at (50000) into (PARTITION p5 ,PARTITION P_MAX);
alter table part_tab_split SPLIT PARTITION P_MAX at (60000) into (PARTITION p6 ,PARTITION P_MAX);
alter table part_tab_split SPLIT PARTITION P_MAX at (70000) into (PARTITION p7 ,PARTITION P_MAX);
alter table part_tab_split SPLIT PARTITION P_MAX at (80000) into (PARTITION p8 ,PARTITION P_MAX);
alter table part_tab_split SPLIT PARTITION P_MAX at (90000) into (PARTITION p9 ,PARTITION P_MAX);

select max(id) from part_tab_split partition(p1);
select max(id) from part_tab_split partition(p2);
select max(id) from part_tab_split partition(p3);
select max(id) from part_tab_split partition(p4);
select max(id) from part_tab_split partition(p5);
select max(id) from part_tab_split partition(p6);
select max(id) from part_tab_split partition(p7);
select max(id) from part_tab_split partition(p8);
select max(id) from part_tab_split partition(p9);
select max(id) from part_tab_split partition(p_max);


以上是数字的,当然比较好split,如果是时间分区呢?大多数是用range时间分区
---分区表时间分区的SPLIT
drop table range_part_tab purge;
create table range_part_tab (id number,deal_date date,area_code number,nbr number,contents varchar2(4000))
partition by range (deal_date)
(
partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_max values less than (maxvalue)
)
;
--以下是插入2019年一整年日期随机数和表示福建地区号含义(591到599)的随机数记录,共有15万条,如下:
insert into range_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(591,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 100000;
commit;
insert into range_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
(sysdate+DBMS_RANDOM.VALUE(0,90)),
ceil(dbms_random.value(591,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 60000;
commit;
select count(*) from range_part_tab partition (p_201901);
select count(*) from range_part_tab partition (p_201902);
select count(*) from range_part_tab partition (p_201903);
select count(*) from range_part_tab partition (p_201904);
select count(*) from range_part_tab partition (p_201905);
select count(*) from range_part_tab partition (p_201906);
select count(*) from range_part_tab partition (p_201907);
select count(*) from range_part_tab partition (p_201908);
select count(*) from range_part_tab partition (p_201909);
select count(*) from range_part_tab partition (p_max);
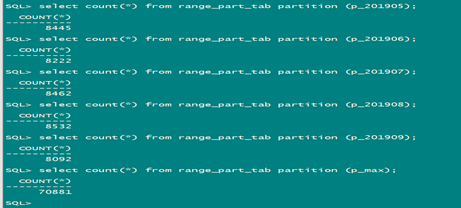
很明显最后一个分区数据量是其它分区的10倍左右。
alter table range_part_tab SPLIT PARTITION P_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (PARTITION p_201910 ,PARTITION P_MAX);
alter table range_part_tab SPLIT PARTITION P_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (PARTITION p_201911 ,PARTITION P_MAX);
alter table range_part_tab SPLIT PARTITION P_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (PARTITION p_201912 ,PARTITION P_MAX);
查看分裂后的分区值:
select count(*) from range_part_tab partition (p_201910);
select count(*) from range_part_tab partition (p_201911);
select count(*) from range_part_tab partition (p_201912);
select count(*) from range_part_tab partition (p_max);
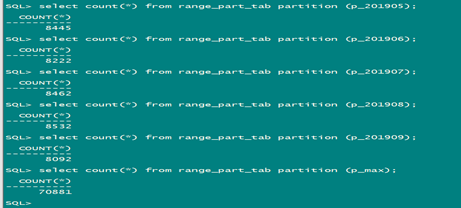
2) 有子分区的分裂
1) 分裂只有一级分区
drop table range_list_part_tab;
create table range_list_part_tab (
id number,
deal_date date,
area_code number,
nbr number,
contents varchar2(4000)
)
partition by range (deal_date)
subpartition by list (area_code)
subpartition TEMPLATE
(subpartition p_591 values (591),
subpartition p_592 values (592),
subpartition p_593 values (593),
subpartition p_594 values (594),
subpartition p_595 values (595),
subpartition p_596 values (596),
subpartition p_597 values (597),
subpartition p_598 values (598),
subpartition p_599 values (599),
subpartition p_other values (DEFAULT)
)
( partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_max values less than (maxvalue));
进行数据的插入:
--以下是插入2019年一整年日期随机数和表示福建地区号含义(591到599)的随机数记录,共有10万条,如下:
insert into range_list_part_tab(id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 100000;
commit;
insert into range_list_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
(sysdate+DBMS_RANDOM.VALUE(0,90)),
ceil(dbms_random.value(591,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 60000;
commit;
select count(*) from range_list_part_tab partition (p_201901);
select count(*) from range_list_part_tab partition (p_201902);
select count(*) from range_list_part_tab partition (p_201903);
select count(*) from range_list_part_tab partition (p_201904);
select count(*) from range_list_part_tab partition (p_201905);
select count(*) from range_list_part_tab partition (p_201906);
select count(*) from range_list_part_tab partition (p_201907);
select count(*) from range_list_part_tab partition (p_201908);
select count(*) from range_list_part_tab partition (p_201909);
select count(*) from range_list_part_tab partition (p_max);

其中max里面么有数据:
进行分裂:
最后一个分区p_max数据相对于其他分区较大,现在需要把该分区进行分裂成多个分区(以及子分区)
语法如下:

alter table range_list_part_tab SPLIT PARTITION P_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (PARTITION p_201910 ,PARTITION P_MAX);
alter table range_list_part_tab SPLIT PARTITION P_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (PARTITION p_201911 ,PARTITION P_MAX);
alter table range_list_part_tab SPLIT PARTITION P_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (PARTITION p_201912 ,PARTITION P_MAX);
跟上面的只有主分区分裂的一样的语法


2) 分裂主分区中的子分区
我现在新建一张表,需要分裂子分区的。
drop table list_range_part_tab purge;
create table list_range_part_tab (id number,deal_date date,area_code number,nbr number,contents varchar2(4000))
partition by list (area_code)
subpartition by range (deal_date)
(
partition p_591 values (591)
(
subpartition p591_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
subpartition p591_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
subpartition p591_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
subpartition p591_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
subpartition p591_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
subpartition p591_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
subpartition p591_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
subpartition p591_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
subpartition p591_max values less than (maxvalue)
),
partition p_592 values (592)
(
subpartition p592_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
subpartition p592_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
subpartition p592_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
subpartition p592_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
subpartition p592_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
subpartition p592_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
subpartition p592_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
subpartition p592_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
subpartition p592_max values less than (maxvalue)
),
partition p_593 values (593)
(
subpartition p593_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
subpartition p593_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
subpartition p593_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
subpartition p593_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
subpartition p593_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
subpartition p593_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
subpartition p593_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
subpartition p593_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
subpartition p593_max values less than (maxvalue)
),
partition p_594 values (594)
(
subpartition p594_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
subpartition p594_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
subpartition p594_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
subpartition p594_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
subpartition p594_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
subpartition p594_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
subpartition p594_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
subpartition p594_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
subpartition p594_max values less than (maxvalue)
),
partition p_595 values (595)
(
subpartition p595_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
subpartition p595_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
subpartition p595_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
subpartition p595_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
subpartition p595_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
subpartition p595_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
subpartition p595_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
subpartition p595_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
subpartition p595_max values less than (maxvalue)
)
);
数据插入:
insert into list_range_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,595)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 100000;
commit;
insert into list_range_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
(sysdate+DBMS_RANDOM.VALUE(0,90)),
ceil(dbms_random.value(590,595)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 60000;
commit;
查看总的分区数据以及p_max子分区数据:
SELECT 'select count(*) from LIST_RANGE_PART_TAB partition'||'('||partition_name||');' FROM USER_TAB_PARTITIONS WHERE table_name='LIST_RANGE_PART_TAB';
select count(*) from LIST_RANGE_PART_TAB partition(P_591);
select count(*) from LIST_RANGE_PART_TAB partition(P_592);
select count(*) from LIST_RANGE_PART_TAB partition(P_593);
select count(*) from LIST_RANGE_PART_TAB partition(P_594);
select count(*) from LIST_RANGE_PART_TAB partition(P_595);

P_max子分区:
SELECT 'select count(*) from LIST_RANGE_PART_TAB subpartition '||'('|| SUBPARTITION_name ||');' FROM USER_TAB_SUBPARTITIONS WHERE table_name='LIST_RANGE_PART_TAB' AND SUBPARTITION_name LIKE '%MAX%' ;
select count(*) from LIST_RANGE_PART_TAB subpartition (P591_MAX);
select count(*) from LIST_RANGE_PART_TAB subpartition (P592_MAX);
select count(*) from LIST_RANGE_PART_TAB subpartition (P593_MAX);
select count(*) from LIST_RANGE_PART_TAB subpartition (P594_MAX);
select count(*) from LIST_RANGE_PART_TAB subpartition (P595_MAX);

很明显故意让max子分区占整个主分区的一般数据量,现在进行max子分区的分裂
由于我设置的时间是9月份的,所以把max子分区分裂成10,11,12三个月就好了。
语句如下:
alter table LIST_RANGE_PART_TAB split SUBPARTITION P591_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (subpartition P591_201910,subPARTITION P591_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P591_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (subpartition P591_201911,subPARTITION P591_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P591_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (subpartition P591_201912,subPARTITION P591_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P592_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (subpartition P592_201910,subPARTITION P592_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P592_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (subpartition P592_201911,subPARTITION P592_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P592_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (subpartition P592_201912,subPARTITION P592_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P593_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (subpartition P593_201910,subPARTITION P593_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P593_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (subpartition P593_201911,subPARTITION P593_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P593_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (subpartition P593_201912,subPARTITION P593_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P594_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (subpartition P594_201910,subPARTITION P594_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P594_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (subpartition P594_201911,subPARTITION P594_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P594_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (subpartition P594_201912,subPARTITION P594_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P595_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (subpartition P595_201910,subPARTITION P595_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P595_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (subpartition P595_201911,subPARTITION P595_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P595_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (subpartition P595_201912,subPARTITION P595_MAX);

查看分裂后的分区:
SELECT 'select count(*) from LIST_RANGE_PART_TAB subpartition '||'('|| SUBPARTITION_name ||');' FROM USER_TAB_SUBPARTITIONS
WHERE table_name='LIST_RANGE_PART_TAB' AND (SUBPARTITION_name LIKE '%MAX%' or SUBPARTITION_name LIKE '%_20191_');
select count(*) from LIST_RANGE_PART_TAB subpartition (P591_201910);
select count(*) from LIST_RANGE_PART_TAB subpartition (P591_201911);
select count(*) from LIST_RANGE_PART_TAB subpartition (P591_201912);
select count(*) from LIST_RANGE_PART_TAB subpartition (P591_MAX);
select count(*) from LIST_RANGE_PART_TAB subpartition (P592_201910);
select count(*) from LIST_RANGE_PART_TAB subpartition (P592_201911);
select count(*) from LIST_RANGE_PART_TAB subpartition (P592_201912);
select count(*) from LIST_RANGE_PART_TAB subpartition (P592_MAX);
select count(*) from LIST_RANGE_PART_TAB subpartition (P593_201910);
select count(*) from LIST_RANGE_PART_TAB subpartition (P593_201911);
select count(*) from LIST_RANGE_PART_TAB subpartition (P593_201912);
select count(*) from LIST_RANGE_PART_TAB subpartition (P593_MAX);
select count(*) from LIST_RANGE_PART_TAB subpartition (P594_201910);
select count(*) from LIST_RANGE_PART_TAB subpartition (P594_201911);
select count(*) from LIST_RANGE_PART_TAB subpartition (P594_201912);
select count(*) from LIST_RANGE_PART_TAB subpartition (P594_MAX);
select count(*) from LIST_RANGE_PART_TAB subpartition (P595_201910);
select count(*) from LIST_RANGE_PART_TAB subpartition (P595_201911);
select count(*) from LIST_RANGE_PART_TAB subpartition (P595_201912);
select count(*) from LIST_RANGE_PART_TAB subpartition (P595_MAX);

很明显,分后成功,分裂后的分区每个对应相应的数据;如果一张分区表主分区和子分区都需要进行分裂,建议先主分区进行分裂,然后在对子分区进行分裂。
exchange
分区表和普通表交换
1) 有子分区的和普通表进行交换
drop table range_list_part_tab;
create table range_list_part_tab (
id number,
deal_date date,
area_code number,
nbr number,
contents varchar2(4000)
)
partition by range (deal_date)
subpartition by list (area_code)
subpartition TEMPLATE
(subpartition p_591 values (591),
subpartition p_592 values (592),
subpartition p_593 values (593),
subpartition p_594 values (594),
subpartition p_595 values (595),
subpartition p_596 values (596),
subpartition p_597 values (597),
subpartition p_598 values (598),
subpartition p_599 values (599),
subpartition p_other values (DEFAULT)
)
( partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_max values less than (maxvalue));
--进行数据的插入:
--以下是插入2019年一整年日期随机数和表示福建地区号含义(591到599)的随机数记录,共有10万条,如下:
insert into range_list_part_tab(id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 100000;
commit;
insert into range_list_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
(sysdate+DBMS_RANDOM.VALUE(0,90)),
ceil(dbms_random.value(591,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 60000;
commit;
新建一张空表,把分区表中的数据交换到该空表中:
drop table range_list_tab;
create table range_list_tab (
id number,
deal_date date,
area_code number,
nbr number,
contents varchar2(4000)
);

进行交换:
alter table range_list_part_tab exchange SUBPARTITION P_201901_P_599 with table range_list_tab including indexes update global indexes;


很明显进行数据交换后,由于空表里面没有数据,所以range_list_part_tab 没有增加数据,range_list_tab数据增加了,其中,进行了数据的交换,子分区分区结构仍然还在。注意,有子分区的表不能只和普通表交换主分区(也就是必须要带上子分区)

2) 无子分区的和普通表进行交换
重新新建表:
drop table part_tab_exch purge;
create table part_tab_exch (id int,col2 int,col3 int,contents varchar2(4000))
partition by range (id)
(
partition p1 values less than (10000),
partition p2 values less than (20000),
partition p3 values less than (30000),
partition p4 values less than (40000),
partition p5 values less than (50000),
partition p_max values less than (maxvalue)
);
insert into part_tab_exch select rownum ,rownum+1,rownum+2, rpad('*',400,'*') from dual connect by rownum <=60000;
commit;
create index idx_part_exch_col2 on part_tab_exch(col2) local;
create index idx_part_exch_col3 on part_tab_exch (col3);
drop table normal_tab purge;
create table normal_tab (id int,col2 int,col3 int,contents varchar2(4000));
create index idx_norm_col2 on normal_tab (col2);
create index idx_norm_col3 on normal_tab (col3);
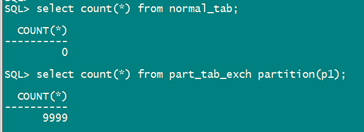
--其中including indexes 可选,为了保证全局索引不要失效
alter table part_tab_exch exchange partition p1 with table normal_tab including indexes update global indexes;

同理,交换的分区表,分区结构还在,不过数据没有了。
分区表之间的交换(分区表之间不能进行交换)
drop table range_list_subpart_tab;
create table range_list_subpart_tab (
id number,
deal_date date,
area_code number,
nbr number,
contents varchar2(4000)
)
partition by range (deal_date)
subpartition by list (area_code)
subpartition TEMPLATE
(subpartition p_591 values (591),
subpartition p_592 values (592),
subpartition p_593 values (593),
subpartition p_594 values (594),
subpartition p_595 values (595),
subpartition p_596 values (596),
subpartition p_597 values (597),
subpartition p_598 values (598),
subpartition p_599 values (599),
subpartition p_other values (DEFAULT)
)
( partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_max values less than (maxvalue));
--以下是插入2019年一整年日期随机数和表示福建地区号含义(591到599)的随机数记录,共有10万条,如下:
insert into range_list_subpart_tab(id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 100000;
commit;
drop table range_list_part_tab;
create table range_list_part_tab (
id number,
deal_date date,
area_code number,
nbr number,
contents varchar2(4000)
)
partition by range (deal_date)
( partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_max values less than (maxvalue)
);
SELECT count(*) FROM range_list_subpart_tab SUBPARTITION (P_201901_P_599);

alter table range_list_subpart_tab exchange SUBPARTITION P_201901_P_599 with table range_list_part_tab including indexes update global indexes;

由此可出结论(被交换的表一定不能是分区表)
二.分区表索引操作失效与否
分区表有两种索引:全局索引和本地索引(global索引和local 索引),有关全局索引和本地索引具体怎么用,以及那种更好的结合场景,下面是实验操作。
drop table local_part_tab;
create table local_part_tab (
id number,
deal_date date,
area_code number,
nbr number,
contents varchar2(4000)
)
partition by range (deal_date)
subpartition by list (area_code)
subpartition TEMPLATE
(subpartition p_591 values (591),
subpartition p_592 values (592),
subpartition p_593 values (593),
subpartition p_594 values (594),
subpartition p_595 values (595),
subpartition p_596 values (596),
subpartition p_597 values (597),
subpartition p_598 values (598),
subpartition p_599 values (599),
subpartition p_other values (DEFAULT)
)
( partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_max values less than (maxvalue));
--以下是插入2019年一整年日期随机数和表示福建地区号含义(591到599)的随机数记录,共有100万条,如下:
insert into local_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 1000000;
commit;
--建一个本地索引。
CREATE INDEX id_local_idx ON local_part_tab (ID) LOCAL;
--建另外一张表:
drop table global_part_tab;
create table global_part_tab (
id number,
deal_date date,
area_code number,
nbr number,
contents varchar2(4000)
)
partition by range (deal_date)
subpartition by list (area_code)
subpartition TEMPLATE
(subpartition p_591 values (591),
subpartition p_592 values (592),
subpartition p_593 values (593),
subpartition p_594 values (594),
subpartition p_595 values (595),
subpartition p_596 values (596),
subpartition p_597 values (597),
subpartition p_598 values (598),
subpartition p_599 values (599),
subpartition p_other values (DEFAULT)
)
( partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_max values less than (maxvalue));
--以下是插入2019年一整年日期随机数和表示福建地区号含义(591到599)的随机数记录,共有100万条,如下:
insert into global_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 1000000;
commit;
--建一个全局索引。
--CREATE INDEX id_global_idx ON global_part_tab (ID);
收集两张表的统计信息。
exec dbms_stats.gather_table_stats('hr','local_part_tab');
exec dbms_stats.gather_table_stats('hr','global_part_tab');
truncate分区
查看操作local索引的状态(注意:11.2.0.4版本sys用户global_stats字段不能够判断是不是本地索引):
N/A索引分区是USABLE还是UNUSABLE
VAILD说明这个索引可用;
UNUSABLE说明这个索引不可用;
USABLE 说明这个索引的分区是可用的。
select index_name, partition_name, status,global_stats
from user_ind_partitions
where index_name IN ('ID_LOCAL_IDX');
有子分区的可以查看user_IND_subPARTITIONS这个视图:
select index_name, partition_name, status,global_stats
from user_ind_subpartitions
where index_name IN ('ID_LOCAL_IDX');

select index_name, status
from user_indexes
where index_name IN ('ID_GLOBAL_IDX');
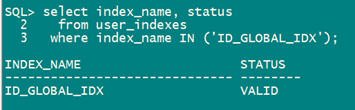
Truncate 分区 p_201901
alter table local_part_tab truncate partition p_201901;
alter table global_part_tab truncate partition p_201901;

可以看出truncate 分区操作,本地索引仍然有效,全局索引不可用,需要重建
alter index ID_GLOBAL_IDX rebuild nologging; --nologging 线上不用记录重做日志会快一点。
drop 分区
删除表local_part_tab , global_part_tab 表P_MAX分区
alter table local_part_tab drop partition P_MAX;
alter table global_part_tab drop partition P_MAX;
select index_name, partition_name, status,global_stats
from user_ind_partitions
where index_name IN ('ID_LOCAL_IDX');
select index_name, status
from user_indexes
where index_name IN ('ID_GLOBAL_IDX');

可以看出drop分区操作,本地索引仍然有效,全局索引不可用,需要重建;
alter index ID_GLOBAL_IDX rebuild nologging;

add 分区
添加p_max分区
alter table local_part_tab add partition p_max values less than (maxvalue) (subpartition p591_max values (591));
alter table global_part_tab add partition p_max values less than (maxvalue) (subpartition p591_max values (591));


可以看出add分区操作,本地索引仍然有效,全局索引也可用;
split 分区
用前面的split有子分区的语句,在list_range_part_tab,id和nbr列上分别建本地和全局索引进行对比。
list_range_part_tab表进行建索引。
create index id_idx_local on list_range_part_tab(id) local;
create index nbr_idx_global on list_range_part_tab(nbr);
select index_name, partition_name, status,global_stats
from user_ind_partitions
where lower(index_name) IN ('id_idx_local');
select index_name, status
from user_indexes
where lower(index_name) IN ('nbr_idx_global');

进行分裂操作:
alter table LIST_RANGE_PART_TAB split SUBPARTITION P591_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (subpartition P591_201910,subPARTITION P591_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P591_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (subpartition P591_201911,subPARTITION P591_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P591_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (subpartition P591_201912,subPARTITION P591_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P592_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (subpartition P592_201910,subPARTITION P592_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P592_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (subpartition P592_201911,subPARTITION P592_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P592_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (subpartition P592_201912,subPARTITION P592_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P593_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (subpartition P593_201910,subPARTITION P593_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P593_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (subpartition P593_201911,subPARTITION P593_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P593_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (subpartition P593_201912,subPARTITION P593_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P594_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (subpartition P594_201910,subPARTITION P594_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P594_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (subpartition P594_201911,subPARTITION P594_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P594_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (subpartition P594_201912,subPARTITION P594_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P595_MAX at (TO_DATE('2019-11-01', 'YYYY-MM-DD')) into (subpartition P595_201910,subPARTITION P595_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P595_MAX at (TO_DATE('2019-12-01', 'YYYY-MM-DD')) into (subpartition P595_201911,subPARTITION P595_MAX);
alter table LIST_RANGE_PART_TAB split SUBPARTITION P595_MAX at (TO_DATE('2020-01-01', 'YYYY-MM-DD')) into (subpartition P595_201912,subPARTITION P595_MAX);
查看分裂后的索引:

可以看出spilt分区操作,本地索引仍然有效,全局索引不可用,需要重建;
alter index nbr_idx_global rebuild;
exchange分区
无global indexes
利用前面的exchange分区语句建表(有子分区的)part_tab_exch,normal_tab purge;以及建索引。
create index idx_part_exch_col2 on part_tab_exch(col2) local;
create index idx_part_exch_col3 on part_tab_exch (col3);
create index idx_norm_col2 on normal_tab (col2);
create index idx_norm_col3 on normal_tab (col3);
select index_name, partition_name, status,global_stats
from user_ind_partitions
where lower(index_name) IN ('idx_part_exch_col2');
select index_name, status
from user_indexes
where lower(index_name) IN ('idx_part_exch_col3','idx_norm_col2','idx_norm_col3');

USABLE表示idx_part_exch_*分区索引可用。
现在进行交换。
首先不带上including indexes update global indexes;
alter table part_tab_exch exchange partition p1 with table normal_tab;

结论:
在分区表和普通变进行分区交换的时候,不带上including indexes update global indexes参数,交换后,分区表交换的分区索引变成不可用(不管是本地还是全局索引),同时普通表索引也会变成不可用。需要重建全局索引,或者按照分区重建分区索引。
alter index IDX_NORM_COL2 rebuild;
alter index IDX_NORM_COL3 rebuild;
alter index IDX_PART_EXCH_COL3 rebuild;
alter index IDX_PART_EXCH_COL2 rebuild partition P1;
重建后查看:

有global indexes
删除相应的表,重建建part_tab_exch,normal_tab purge;以及建索引。
create index idx_part_exch_col2 on part_tab_exch(col2) local;
create index idx_part_exch_col3 on part_tab_exch (col3);
create index idx_norm_col2 on normal_tab (col2);
create index idx_norm_col3 on normal_tab (col3);
part_tab_exch,normal_tab purge;以及建索引。
create index idx_part_exch_col2 on part_tab_exch(col2) local;
create index idx_part_exch_col3 on part_tab_exch (col3);
create index idx_norm_col2 on normal_tab (col2);
create index idx_norm_col3 on normal_tab (col3);

现在进行交换,带上including indexes update global indexes;
alter table part_tab_exch exchange partition p1 with table normal_tab including indexes update global indexes;

由于分区表的全局索引和普通表碎银类型不一样,索引不能够再普通表normal_tab上建idx_norm_col3索引。
drop index idx_norm_col3;
alter table part_tab_exch exchange partition p1 with table normal_tab including indexes update global indexes;
select index_name, partition_name, status,global_stats
from user_ind_partitions
where lower(index_name) IN ('idx_part_exch_col2');
select index_name, status
from user_indexes
where lower(index_name) IN ('idx_part_exch_col3','idx_norm_col2');

结论:神奇吧,除了把数据交换之外,分区表交换的分区索引也变成全局索引了。
综上结论
总结一下,先说说local索引,除了exchange交换分区的不带上including indexes update global indexes参数时候,本地索引会变成不可用,需要重建对应的交换分区索引alter index index_name rebuild partition P1;其它情况均可用;
Global全局索引,除了add, exchange交换分区的带上including indexes update global indexes参数时候有效,其它操作均会失效(drop,truncate,split,exchange不带including indexes update global indexes)。
三.分区表local与全局索引之性能比较
既然存在local与global索引,存在即是合理,那什么时候我们应该再那些场景中使用这两种索引呢?
新建两种表:
drop table local_part_tab purge;
create table local_part_tab (id number,deal_date date,area_code number,nbr number,contents varchar2(4000))
partition by range (deal_date)
subpartition by list (area_code)
subpartition TEMPLATE
(subpartition p_591 values (591),
subpartition p_592 values (592),
subpartition p_593 values (593),
subpartition p_594 values (594),
subpartition p_595 values (595),
subpartition p_596 values (596),
subpartition p_597 values (597),
subpartition p_598 values (598),
subpartition p_599 values (599),
subpartition p_other values (DEFAULT))
( partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_201910 values less than (TO_DATE('2019-11-01', 'YYYY-MM-DD')),
partition p_201911 values less than (TO_DATE('2019-12-01', 'YYYY-MM-DD')),
partition p_201912 values less than (TO_DATE('2020-01-01', 'YYYY-MM-DD')),
partition p_202001 values less than (TO_DATE('2020-02-01', 'YYYY-MM-DD')),
partition p_202002 values less than (TO_DATE('2020-03-01', 'YYYY-MM-DD'))
);
--数据的插入
insert into local_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 1000000;
commit;
--在local_part_tab表建本地索引:
create index id_idx_local on local_part_tab(id) local;
--建另外一张表:
drop table global_part_tab purge;
create table global_part_tab (id number,deal_date date,area_code number,nbr number,contents varchar2(4000))
partition by range (deal_date)
subpartition by list (area_code)
subpartition TEMPLATE
(subpartition p_591 values (591),
subpartition p_592 values (592),
subpartition p_593 values (593),
subpartition p_594 values (594),
subpartition p_595 values (595),
subpartition p_596 values (596),
subpartition p_597 values (597),
subpartition p_598 values (598),
subpartition p_599 values (599),
subpartition p_other values (DEFAULT))
( partition p_201901 values less than (TO_DATE('2019-02-01', 'YYYY-MM-DD')),
partition p_201902 values less than (TO_DATE('2019-03-01', 'YYYY-MM-DD')),
partition p_201903 values less than (TO_DATE('2019-04-01', 'YYYY-MM-DD')),
partition p_201904 values less than (TO_DATE('2019-05-01', 'YYYY-MM-DD')),
partition p_201905 values less than (TO_DATE('2019-06-01', 'YYYY-MM-DD')),
partition p_201906 values less than (TO_DATE('2019-07-01', 'YYYY-MM-DD')),
partition p_201907 values less than (TO_DATE('2019-08-01', 'YYYY-MM-DD')),
partition p_201908 values less than (TO_DATE('2019-09-01', 'YYYY-MM-DD')),
partition p_201909 values less than (TO_DATE('2019-10-01', 'YYYY-MM-DD')),
partition p_201910 values less than (TO_DATE('2019-11-01', 'YYYY-MM-DD')),
partition p_201911 values less than (TO_DATE('2019-12-01', 'YYYY-MM-DD')),
partition p_201912 values less than (TO_DATE('2020-01-01', 'YYYY-MM-DD')),
partition p_202001 values less than (TO_DATE('2020-02-01', 'YYYY-MM-DD')),
partition p_202002 values less than (TO_DATE('2020-03-01', 'YYYY-MM-DD'))
);
--数据的插入
insert into global_part_tab (id,deal_date,area_code,nbr,contents)
select rownum,
to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),
ceil(dbms_random.value(590,599)),
ceil(dbms_random.value(18900000001,18999999999)),
rpad('*',400,'*')
from dual
connect by rownum <= 1000000;
commit;
--在global_part_tab表建本地索引:
create index id_idx_global on global_part_tab(id) ;
然后收集两张表的统计信息:
exec dbms_stats.gather_table_stats('sys','global_part_tab');
exec dbms_stats.gather_table_stats('sys','local_part_tab');
首先我们来比较运行时间以及执行计划:
select index_name, partition_name, status,global_stats
from user_ind_partitions
where index_name='ID_IDX_LOCAL';

select index_name, status
from user_indexes
where index_name='ID_IDX_GLOBAL';

1) 查看不知道分区条件的特定值
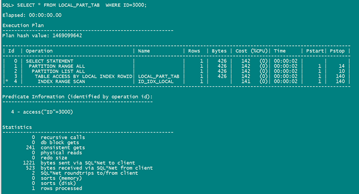
SELECT * FROM LOCAL_PART_TAB WHERE ID=3000;
SELECT * FROM global_PART_TAB WHERE ID=3000;

这个cpu 成本差距差的不是一点点呀!!
第一个本地索引是利用索引范围扫描,在通过rowid回表,但是后面还通过分区内的扫描;
第二个全局索引直接是索引范围扫描,通过全局索引rowid回表返回结果。
前者cpu成本142,后者才4,几十倍的差距。
2) 查看不知道分区条件的查看多个值
SELECT * FROM LOCAL_PART_TAB WHERE ID>=3000 and id <=3500;
SELECT * FROM global_PART_TAB WHERE ID>=3000 and id <=3500;
3) 查看某个分区条件的值
SELECT *
FROM LOCAL_PART_TAB
WHERE DEAL_DATE >= TO_DATE('2019-03-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND DEAL_DATE <= TO_DATE('2019-05-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND AREA_CODE IN (591, 592)
AND ID BETWEEN 2000 AND 2300;

SELECT *
FROM GLOBAL_PART_TAB
WHERE DEAL_DATE >= TO_DATE('2019-03-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND DEAL_DATE <= TO_DATE('2019-05-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND AREA_CODE IN (591, 592)
AND ID BETWEEN 2000 AND 2300;

本次是查看单个主分区里面,两个子分区的值。
同样的语句可以看出,
第一个是通过索引范围扫面,在通过rowid,最后通过分区内的扫描取得所需要的值,11行,且cpu 消耗26;
而利用全局索引扫面却索引范围扫面,在通过rowid直接就取得所需要的结果集,9行,cpu消耗302;
这两个,单个分区以及子分区的的性能差距不是一点点的差异,10多倍
4) 查看多个分区条件的多个值
SELECT *
FROM LOCAL_PART_TAB
WHERE DEAL_DATE >= TO_DATE('2019-03-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND DEAL_DATE <= TO_DATE('2019-08-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND AREA_CODE IN (591, 592,593,594,595,596)
AND ID BETWEEN 2000 AND 2200;

SELECT *
FROM GLOBAL_PART_TAB
WHERE DEAL_DATE >= TO_DATE('2019-03-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND DEAL_DATE <= TO_DATE('2019-08-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND AREA_CODE IN (591, 592,593,594,595,596)
AND ID>100 AND ID<1000;

此种上面哪个实验一样,全局索引完败差距不是一点点!
第一个是通过索引范围扫面,在通过rowid,最后通过分区内的扫描取得所需要的值;
而利用全局索引扫面却索引范围扫面,在通过rowid直接就取得所需要的结果集(注意,一样的不通过分区范围扫描);
5) 结论
全局索引适中的场景
在整张表中按照(某个特定的值)要求快速得出特定的值(比如我要查询一个会员账号名字为xyz的人信息,恰好user_info这张表是分区表,且不知道时间,需要全表找,恰好姓名做了全局索引,相当于整张表找某个值),因为。
本地索引适用场景:
不需要进行全表查找某个值,比如需要查找特定的时间特定的值,此时本地索引占优势,其中本地索引还有一个优点就是维护起来比较方便,除了exchange交换分区的不带上including indexes update global本地索引会不可用,其他的都可用,维护成本更低,但是全局索引除了增加分区和exchange交换分区的带上including indexes update global有效之外,其他的操作均会不可用,需要重建。
四.12.2c分区表新特性
这些是Oracle数据库12 c第2版(12.2.0.1)中的新功能,官网:
https://docs.oracle.com/en/database/oracle/oracle-database/12.2/vldbg/partition-create-tables-indexes.html#GUID-12150FFB-48E4-4169-9EBE-64974C1CEF2A
自动列表分区
自动列表分区方法允许按需创建列表分区。自动列表分区表与常规列表分区表相似,不同之处在于此分区表更易于管理。您可以仅使用已知的分区键值来创建自动列表分区表。在将数据加载到表中时,如果所加载的分区键值与任何现有分区都不对应,则数据库会自动创建一个新分区。由于分区是根据需要自动创建的,因此自动列表分区方法类似于现有的间隔分区方法。
CREATE TABLE sales_auto_list
(
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_state VARCHAR2(20),
sales_amount NUMBER(10),
sales_date DATE
)
PARTITION BY LIST (sales_state) AUTOMATIC
(PARTITION P_CAL VALUES ('CALIFORNIA')
);
多列列表分区
多列列表分区使您可以基于多列的列表值对表进行分区。与单列列表分区类似,单个分区可以包含包含值列表的集合。
CREATE TABLE sales_by_region_and_channel
(deptno NUMBER,
deptname VARCHAR2(20),
quarterly_sales NUMBER(10,2),
state VARCHAR2(2),
channel VARCHAR2(1)
)
PARTITION BY LIST (state, channel)
(
PARTITION q1_northwest_direct VALUES (('OR','D'), ('WA','D')),
PARTITION q1_northwest_indirect VALUES (('OR','I'), ('WA','I')),
PARTITION q1_southwest_direct VALUES (('AZ','D'),('UT','D'),('NM','D')),
PARTITION q1_ca_direct VALUES ('CA','D'),
PARTITION rest VALUES (DEFAULT)
);
自动列表分区和间隔子分区的延迟段创建
自动列表组合分区表和间隔子分区仅在存在数据的情况下创建子分区。此操作可以节省空间。在按需创建新分区时推迟创建子分区段可确保仅在插入第一个匹配行时才创建子分区段。
有关创建自动列表分区表的信息,请参阅创建表和索引时指定分区。
只读分区
您可以将表,分区和子分区设置为只读状态,以防止任何用户或触发器对数据进行意外的DML操作。
有关创建具有只读分区的表的信息,请参阅创建具有只读分区或子分区的表。
将非分区表转换为分区表
通过将MODIFY子句添加到ALTER TABLESQL语句,可以将非分区表转换为分区表。另外,ONLINE可以指定关键字,从而在进行转换时启用并发DML操作。
有关在线转换为分区表的信息,请参阅将非分区表转换为分区表。
创建用于分区表交换的表
可以使用该FOR EXCHANGE WITH子句创建表,使其与分区表的形状完全匹配,并且符合分区交换命令的要求,但不创建索引作为此命令的操作。由于此功能提供了未分区表和分区表之间的精确匹配,因此是对CREATE TABLE AS SELECT语句的改进。
有关创建与分区表进行交换的表的信息,请参阅创建与分区表进行交换的表。
筛选的分区维护操作
分区维护操作支持添加数据过滤,从而实现分区和数据维护的结合。过滤后的分区维护操作仅保留满足数据过滤要求的数据,作为分区维护的一部分。数据过滤的能力适用于MOVE PARTITION,MERGE PARTITION,和SPLIT PARTITION。
有关过滤维护操作的信息,请参阅过滤维护操作。
使用SPLIT操作进行在线分区维护
SPLIT支持将操作进行分区维护作为在线操作,并使用ONLINE针对堆组织表的关键字,从而在进行分区维护操作时启用并发DML操作。
有关拆分分区的信息,请参阅关于拆分分区和子分区。
创建一个分区的外部表
支持对外部表进行分区,以更好地优化已分区外部表上的查询。
Oracle 分区表管理之组合分区(分区索引失效与性能比较)的更多相关文章
- oracle 使用ID关键字作列名导致索引失效
oracle表空间变更导致主键索引失效,重建索引即可
- Oracle分区表管理的一些笔记
[转自] http://www.linuxidc.com/Linux/2011-07/38381.htm Oracle分区表的管理笔记(仅限于对普通表,即堆表的分区管理,IOT跟CLUSTER TAB ...
- oracle分区表(附带按照月自动分区、按天自动分区)
--list_range 示例 drop table list_range_tab purge; create table list_range_tab(n1 number,n2 date)pa ...
- 深入学习Oracle分区表及分区索引
关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类: • Range(范围)分区 • Has ...
- oracle 分区表和分区索引
很复杂的样子,自己都没有看完,以备后用 http://hi.baidu.com/jsshm/item/cbfed8491d3863ee1e19bc3e ORACLE分区表.分区索引ORACLE对于分区 ...
- ORACLE分区表、分区索引详解
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt160 ORACLE分区表.分区索引ORACLE对于分区表方式其实就是将表分段 ...
- 【三思笔记】 全面学习Oracle分区表及分区索引
[三思笔记]全面学习Oracle分区表及分区索引 2008-04-15 关于分区表和分区索引(About PartitionedTables and Indexes) 对于 10gR2 而言,基本上可 ...
- 简单ORACLE分区表、分区索引
前一段听说CSDN.COM里面很多好东西,同事建议看看合适自己也可以写一写,呵呵,今天第一次开通博客,随便写点东西,就以第一印象分区表简单写第一个吧. ORACLE对于分区表方式其实就是将表分段存储, ...
- 转:深入学习Oracle分区表及分区索引
转自:http://database.ctocio.com.cn/tips/286/8104286.shtml 关于分区表和分区索引(About Partitioned Tables and Inde ...
随机推荐
- Sqlsever新增作业执行计划傻瓜式操作
开启数据库代理,启动不了请检查数据库服务的代理是否开启 建议Sqlserver2008以上的版本 完整步骤如下: 查看效果: 10秒以后再来查询:发现数据有多了一些,是不是很简单,嘻嘻!
- 接口 IEnumerable
C#提供了可供类继承的接口,在此解释一下经常遇到的IEnumerable,在此首相解释一下接口,如下例所示: /// <summary> /// 简述Interface的用法 /// &l ...
- django-Views之类视图 (六)
book/urls.py from django.urls import path from . import views urlpatterns = [ path('',views.IndexVie ...
- js更高文档的样式
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- python str的一些操作及处理
一.str的定义:Python中凡是用引号引起来的数据可以称为字符串类型,组成字符串的每个元素称之为字符,将这些字符一个一个连接起来,然后在用引号起来就是字符串. 二.str的简单操作方法: conu ...
- 使用promise封装ajax
直接上代码: function Ajax(method, headers, url, data, progress = null) { return new Promise(function (res ...
- php经典设计模式和Trait类代码的复用
PHP经典设计模式 <?php /** * 单例模式 */ class Site { #定义属性 public $siteName; #定义本类的静态实例 protected static $i ...
- 实现ARM——Linux的自动登录
在使用Linux系统嵌入式开发时,往往需要设备绕过Linux的登录系统使其自动启动,比如我们常用的SSH客户端等.网上确实有很多方法,不知道是因为我们的ARM9板子是私人订制的缘故还是什么原因,试了很 ...
- Anaconda的安装和详细介绍(带图文)
Anacond的介绍 Anaconda指的是一个开源的Python发行版本,其包含了conda.Python等180多个科学包及其依赖项. 因为包含了大量的科学包,Anaconda 的下载文件比较大( ...
- Apache Flink任意Jar包上传导致远程代码执行漏洞复现
0x00 简介 Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎.Flink以数据并行和流水线方式执行任意流数据程序,Fl ...