机器学习实战:基于Scikit-Learn和TensorFlow 读书笔记 第6章 决策树
数据挖掘作业,要实现决策树,现记录学习过程
win10系统,Python 3.7.0
构建一个决策树,在鸢尾花数据集上训练一个DecisionTreeClassifier:
- from sklearn.datasets import load_iris
- from sklearn.tree import DecisionTreeClassifier
- iris = load_iris()
- X = iris.data[:,2:]
- y = iris.target
- tree_clf = DecisionTreeClassifier(max_depth=2)
- tree_clf.fit(X,y)
要将决策树可视化,首先,使用export_graphviz()方法输出一个图形定义文件,命名为iris_tree.dot
这里需要安装graphviz
安装方式:
① conda install python-graphviz
② pip install graphviz
在当前目录下新建images/decision_trees目录
不然会报错
Traceback (most recent call last):
File "decisiontree.py", line 21, in <module>
filled=True)
File "E:\Anaconda\lib\site-packages\sklearn\tree\export.py", line 762, in export_graphviz
out_file = open(out_file, "w", encoding="utf-8")
FileNotFoundError: [Errno 2] No such file or directory: '.\\images\\decision_trees\\iris_tree.dot'
- from sklearn.tree import export_graphviz
- import os
- PROJECT_ROOT_DIR = "."
- CHAPTER_ID = "decision_trees"
- def image_path(fig_id):
- return os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id)
export_graphviz(tree_clf,- out_file=image_path("iris_tree.dot"),
- feature_names=iris.feature_names[2:],
- class_names=iris.target_names,
- rounded=True,
- filled=True)
运行过后生成了一个dot文件

使用命令dot -Tpng iris_tree.dot -o iris_tree.png 将dot文件转换为png文件方便显示
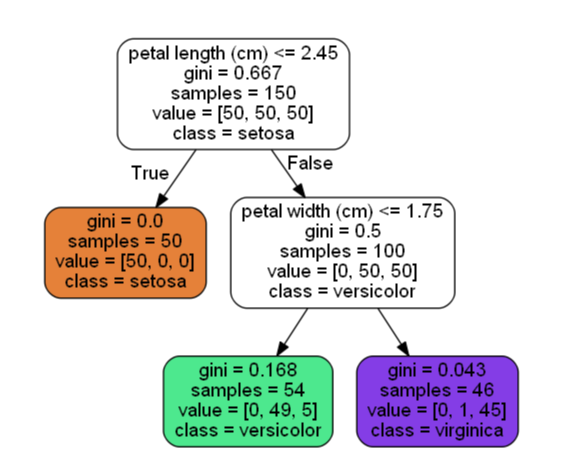
决策树如上图所示
petal length:花瓣长度 petal width:花瓣宽度
samples:统计出它应用于多少个训练样本实例
value:这个节点对于每一个类别的样例有多少个  这个叶结点显示包含0 个 Iris-Setosa,1 个 Iris-Versicolor 和 45 个 Iris-Virginica
这个叶结点显示包含0 个 Iris-Setosa,1 个 Iris-Versicolor 和 45 个 Iris-Virginica
Gini:用于测量它的纯度,如果一个节点包含的所有训练样例全都是同一类别的,我们就说这个节点是纯的( Gini=0 )
Gini公式:
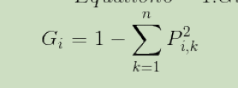 Pik是第i个节点上,类别为k的训练实例占比
Pik是第i个节点上,类别为k的训练实例占比
进行预测
当找到了一朵鸢尾花并且想对它进行分类时,从根节点开始,询问花朵的花瓣长度是否小于2.45厘米。如果是,将向下移动到根的左侧子节点,在这种情况下,它是一片叶子节点,它不会再继续问任何问题,决策树预测你的花是iris-setosa
假设你找到了另一朵花,但这次的花瓣长度是大于2.45厘米的。必须向下移动到根的右侧子节点,而这个节点不是叶节点,它会问另一个问题,花瓣宽度是否小于1.75厘米?如果是,则将这朵花分类成iris-versicolor ,不是,则分类成iris-versicolor
注意:scikit-learn使用的是CART算法,该算法仅生成二叉树;非叶节点永远只有两个子节点。
估计分类概率
新样本:花瓣长5厘米,花瓣宽1.5厘米,预测具体的类
- print(tree_clf.predict_proba([[5,1.5]]))
- print(tree_clf.predict([[5,1.5]]))

此处说明分类为iris-setosa的概率为0,分类为iris-versicolor的概率为0.90740741,分类为iris-virginica的概率为0.09259259
通过predict预测该花为iris-versicolor
完整代码
- #在鸢尾花数据集上进行一个决策树分类器的训练
- from sklearn.datasets import load_iris
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.tree import export_graphviz
- import os
- PROJECT_ROOT_DIR = "."
- CHAPTER_ID = "decision_trees"
- def image_path(fig_id):
- return os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id)
- iris = load_iris()
- X = iris.data[:,2:]
- y = iris.target
- tree_clf = DecisionTreeClassifier(max_depth=2)
- tree_clf.fit(X,y)
- export_graphviz(tree_clf,
- out_file=image_path("iris_tree.dot"),
- feature_names=iris.feature_names[2:],
- class_names=iris.target_names,
- rounded=True,
- filled=True)
- print(tree_clf.predict_proba([[5,1.5]]))
- #[0]:iris-setosa, [1]:iris-versicolor, [2]:iris-virginica"
- print(tree_clf.predict([[5,1.5]]))
CART训练算法原理介绍:

机器学习实战:基于Scikit-Learn和TensorFlow 读书笔记 第6章 决策树的更多相关文章
- Java多线程编程实战指南(核心篇)读书笔记(二)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76651408冷血之心的博客) 博主准备恶补一番Java高并发编程相 ...
- Java多线程编程实战指南(核心篇)读书笔记(五)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76730459冷血之心的博客) 博主准备恶补一番Java高并发编程相 ...
- Java多线程编程实战指南(核心篇)读书笔记(四)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76690961冷血之心的博客) 博主准备恶补一番Java高并发编程相 ...
- Java多线程编程实战指南(核心篇)读书笔记(三)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76686044冷血之心的博客) 博主准备恶补一番Java高并发编程相 ...
- Java多线程编程实战指南(核心篇)读书笔记(一)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76422930冷血之心的博客) 博主准备恶补一番Java高并发编程相 ...
- 《黑客攻防技术宝典Web实战篇@第2版》读书笔记1:了解Web应用程序
读书笔记第一部分对应原书的第一章,主要介绍了Web应用程序的发展,功能,安全状况. Web应用程序的发展历程 早期的万维网仅由Web站点构成,只是包含静态文档的信息库,随后人们发明了Web浏览器用来检 ...
- 《Linux内核设计与实现》第八周读书笔记——第四章 进程调度
<Linux内核设计与实现>第八周读书笔记——第四章 进程调度 第4章 进程调度35 调度程序负责决定将哪个进程投入运行,何时运行以及运行多长时间,进程调度程序可看做在可运行态进程之间分配 ...
- 《Linux内核设计与实现》 第八周读书笔记 第四章 进程调度
20135307 张嘉琪 第八周读书笔记 第四章 进程调度 调度程序负责决定将哪个进程投入运行,何时运行以及运行多长时间,进程调度程序可看做在可运行态进程之间分配有限的处理器时间资源的内核子系统.只有 ...
- 《Linux内核分析》读书笔记(四章)
<Linux内核分析>读书笔记(四章) 标签(空格分隔): 20135328陈都 第四章 进程调度 调度程序负责决定将哪个进程投入运行,何时运行以及运行多长时间,进程调度程序可看做在可运行 ...
随机推荐
- robot用例执行常用命令(转)
执行命令 执行一个用例 robot -t “testcase_name“ data_test.robot 按用例文件执行 robot data_test.robot或者 robot --suite “ ...
- C++ 面向对象程序设计复习大纲
这是我在准备C++考试时整理的提纲,如果是通过搜索引擎搜索到这篇博客的师弟师妹,建议还是先参照PPT和课本,这个大纲也不是很准确,自己总结会更有收获,多去理解含义,不要死记硬背,否则遇到概念辨析题会 ...
- three.js实现土星绕太阳体系
概况如下: 1.SphereGeometry实现自转的太阳,土星: 2.RingGeometry实现土星公转轨道: 3.ImageUtils加载球体贴图: 4.canvas中createRadialG ...
- Selenium(一):原理与安装、简单的使用
1. selenium原理 1.1 selenium介绍 Selenium是一个Web应用的自动化框架. 通过它,我们可以写出自动化程序,像人一样在浏览器里操作web界面. 比如点击界面按钮,在文本框 ...
- Python中7个不一样的代码写法
打印index 对于一个列表,或者说一个序列我们经常需要打印它的index,一般传统的做法或者说比较low的写法: 更优雅的写法是多用enumerate 两个序列的循环 我们会经常对两个序列进行计算或 ...
- 在python操作数据库中游标的使用方法
cursor就是一个Cursor对象,这个cursor是一个实现了迭代器(def__iter__())和生成器(yield)的MySQLdb对象,这个时候cursor中还没有数据,只有等到fetcho ...
- Gradle之FTP文件下载
Gradle之FTP文件下载 1.背景 项目上需要使用本地web,所以我们直接将web直接放入assets资源文件夹下.但是随着开发进行web包越来越大:所以我们想着从版本库里面去掉web将其忽略掉, ...
- [20191115]oracle实例占用内存计算.txt
[20191115]oracle实例占用内存计算.txt --//以前学习oracle数据库时,总想了解实例占用内存多少,我曾经在一些会议底下问过一位高手,对方说计算这个相对很难,许多东西是共享的.- ...
- go语言设计模式之builder
builder.go package builder type BuildProcess interface { SetWheels() BuildProcess SetSeats() BuildPr ...
- NOIP 2016 玩具谜题
洛谷 P1563 玩具谜题 洛谷传送门 JDOJ 3136: [NOIP2016]玩具谜题 D1 T1 JDOJ传送门 Description 小南有一套可爱的玩具小人, 它们各有不同的职业. 有一天 ...