Redis缓存系列
一、缓存雪崩
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,
而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
缓存正常从Redis中获取,示意图如下:

缓存失效瞬间示意图如下:
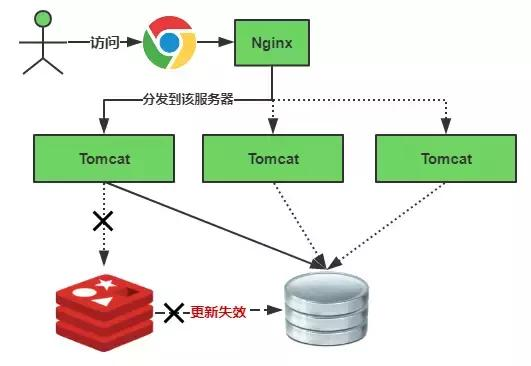
缓存雪崩的解决方案:
(1)碰到这种情况,一般并发量不是特别多的时候,使用最多的解决方案是加锁排队,伪代码如下:

加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法!
注意:加锁排队的解决方式分布式环境的并发问题,有可能还要解决分布式锁的问题;线程还会被阻塞,用户体验很差!因此,在真正的高并发场景下很少使用!
(2)给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存,实例伪代码如下:

解释说明:
1、缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际key的缓存;
2、缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。 这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
关于缓存崩溃的解决方法,这里提出了三种方案:使用锁或队列、设置过期标志更新缓存、为key设置不同的缓存失效时间,还有一各被称为“二级缓存”的解决方法,有兴趣的读者可以自行研究。
二、缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。
这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
缓存穿透解决方案:
(1)采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
(2)如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
通过这个直接设置的默认值存放到缓存,这样第二次到缓存中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴!

把空结果也给缓存起来,这样下次同样的请求就可以直接返回空了,即可以避免当查询的值为空时引起的缓存穿透。同时也可以单独设置个缓存区域存储空值,对要查询的key进行预先校验,然后再放行给后面的正常缓存处理逻辑。
三、缓存预热
缓存预热就是系统上线后,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
缓存预热解决方案:
(1)直接写个缓存刷新页面,上线时手工操作下;
(2)数据量不大,可以在项目启动的时候自动进行加载;
(3)定时刷新缓存;
四、缓存更新
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
(1)定时去清理过期的缓存;
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
五、缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
Redis缓存系列的更多相关文章
- 分布式缓存技术redis学习系列(五)——redis实战(redis与spring整合,分布式锁实现)
本文是redis学习系列的第五篇,点击下面链接可回看系列文章 <redis简介以及linux上的安装> <详细讲解redis数据结构(内存模型)以及常用命令> <redi ...
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- ABP入门系列(13)——Redis缓存用起来
ABP入门系列目录--学习Abp框架之实操演练 源码路径:Github-LearningMpaAbp 1. 引言 创建任务时我们需要指定分配给谁,Demo中我们使用一个下拉列表用来显示当前系统的所有用 ...
- 分布式缓存技术redis学习系列
分布式缓存技术redis学习系列(一)--redis简介以及linux上的安装以及操作redis问题整理 分布式缓存技术redis学习系列(二)--详细讲解redis数据结构(内存模型)以及常用命令 ...
- 高并发架构系列:Redis缓存和MySQL数据一致性方案详解
一.需求起因 在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节.所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库. 这个业务场景, ...
- Spring+SpringMVC+MyBatis+easyUI整合进阶篇(十四)Redis缓存正确的使用姿势
作者:13 GitHub:https://github.com/ZHENFENG13 版权声明:本文为原创文章,未经允许不得转载. 简介 这是一篇关于Redis使用的总结类型文章,会先简单的谈一下缓存 ...
- redis缓存雪崩、缓存穿透、数据库和redis数据一致性
一.缓存雪崩 回顾一下我们为什么要用缓存(Redis):减轻数据库压力或尽可能少的访问数据库. 在前面学习我们都知道Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据设 ...
- 缓存系列之二:CDN与其他层面缓存
缓存系列之二:CDN与其他层面缓存 一:内容分发网络(Content Delivery Network),通过将服务内容分发至全网加速节点,利用全球调度系统使用户能够就近获取,有效降低访问延迟,提升服 ...
- spring-boot-2.0.3之redis缓存实现,不是你想的那样哦!
前言 开心一刻 小白问小明:“你前面有一个5米深的坑,里面没有水,如果你跳进去后该怎样出来了?”小明:“躺着出来呗,还能怎么出来?”小白:“为什么躺着出来?”小明:“5米深的坑,还没有水,跳下去不死就 ...
随机推荐
- Nginx图片防盗链配置
如果我们自己网站内的图片资源被其它网站所盗用,这会增加自己网站的带宽资源,增加很多额外的消耗,而且会对我们系统的稳定性有影响,为了防止自己网站上的图片资源被其它网站所盗用,我们需要给自己的服务器配置防 ...
- [WPF 自定义控件]使用WindowChrome自定义RibbonWindow
1. 为什么要自定义RibbonWindow 自定义Window有可能是设计或功能上的要求,可以是非必要的,而自定义RibbonWindow则不一样: 如果程序使用了自定义样式的Window,为了统一 ...
- CentOS 7安装配置MySQL 5.7
概述 前文记录了在Windows系统中安装配置MySQL 5.7(前文连接:https://www.cnblogs.com/Dcl-Snow/p/10513925.html),由于安装部署大数据环境需 ...
- SpringBoot+MyBatisPlus整合时提示:Invalid bound statement(not found):**.dao.UserDao.queryById
场景 在使用SpringBoot+MyBatisPlus搭建后台启动项目时,使用EasyCode自动生成代码. 在访问后台接口时提示: Invilid bound statement (not fou ...
- 如何在CAD图纸中进行线性标注
在CAD中,都会在图纸中进行CAD标注,一般都是有CAD标注样式.CAD标注文字等.那其中有一个就是CAD线性标注?可以标注图纸间的距离?那如何在CAD图纸中进行线性标注呢?具体要怎么来进行操作?本篇 ...
- 【C#】学习笔记 Linq相关
Language-Integrated Query(语言集成查询) 写了个demo,具体看
- html-css___table属性(设置细线边框)
border-collapse 属性设置表格的边框是否被合并为一个单一的边框 //设置table实线边框 table,td{ /*边框合并*/ border-collapse: collapse; b ...
- ABP入门教程4 - 初始化运行
点这里进入ABP入门教程目录 编译解决方案 重新生成解决方案,确保生成成功. 连接数据库 打开JD.CRS.Web.Host / appsettings.json,修改数据库连接设置Connectio ...
- 【JDBC】工具类的抽取
jdbc.properties属性文件 driverClass=com.mysql.jdbc.Driver url=jdbc:mysql:///jdbctest username=root passw ...
- 解决vue修改路由的查询字符串(query)url不改变,页面不刷新问题
我个人猜测可能是对路由的数据检测深度不够吧,单纯修改query里面的属性是不能触发数据驱动的,因此要直接给query赋值新的对象才能驱动数据更新,做法如下 第一种 var query=JSON.par ...