Elasticsearch系列---补充几个知识点
概要
bulk api有趣的json格式
前面《简单入门实战》一节中,有介绍bulk的使用示例,大家一定很奇怪,还有这么有趣的JSON格式,必须严格照他的换行来做,我想把JSON搞得美观可读性好一点,居然给我报错!
{"action": {"meta"}}\n
{"data"}\n
{"action": {"meta"}}\n
{"data"}\n
它为什么要这样规定?
我们想想bulk设计的初衷,批处理的执行效率肯定是第一优先级,此时效率>可读性,如果我们允许随意换行,用标准格式的JSON串,会有什么区别?
如果是标准格式的JSON串,处理流程一般会是这样:
- 将整个json数组全部加载,解析为JSONArray对象,这时内存中同时有json串文本和JSONArray对象。
- 循环遍历JSONArray对象,获取每个请求中的document进行路由信息。
- 把路由到同一个shard的请求合在一组,开辟一个新的请求数组,将JSONObject放在数组里。
- 序列化请求数组,发送到对应的节点上去。
- 收集各节点的响应,汇总后返回给Coordinate Node。
- Coordinate Node收到所有的汇总信息,返回给客户端。
这种方式唯一的缺点就是占用内存多,一份json串,解析为JSONArray对象,内存占用翻番,bulk里面多则几千条请求,如果JSON报文大一点,这内存耗费不是开玩笑的,如果bulk占用的内存过多,就可能会挤压其他请求的内存使用量,如搜索请求、数据分析请求等,整体性能会急速下降,严重的情况可能会触发Full GC,会导致整个JVM工作线程暂停。
再看看现有的格式定义:除了delete操作占一行,其他操作都是占两行的,ES收到bulk请求时,就可以简单的按行进行切割,也不用转成json对象了,切割完的JSON读取里面的meta信息,直接路由到相应的shard,收集完响应返回即可。
这样的好处切割逻辑更简单,都是处理小json字符串,内存快拿快放,整个ES避免对内存的大块占用,尽可能保证性能。
增删改文档内部原理
增删改的过程整体与查询文档过程一致,只是多了一个数据同步的步骤,整个过程如图所示:
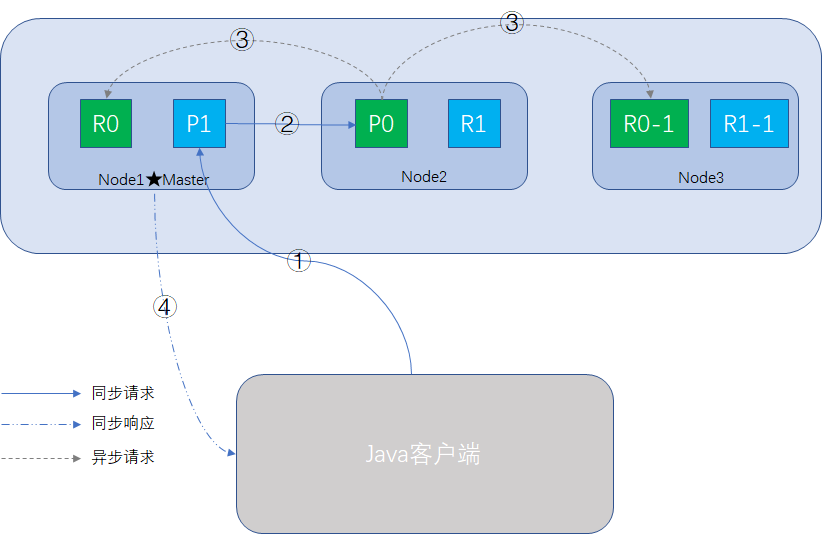
相似的步骤不赘述。
步骤3的前提是primary shard操作成功,异步请求,所有的replica都返回成功后,node2响应操作成功的消息给Coordinate Node,最后Coordinate Node向客户端返回成功消息,此时所有的primary shard和replica shard均已完成数据同步,数据是一致的。
查询文档内部原理
当我们使用客户端(Java或Restful API)向Elasticsearch搜索文档数据时,可以向任意一个node发送请求,此时接受请求的node就是Coordinate Node,整个过程如图所示:
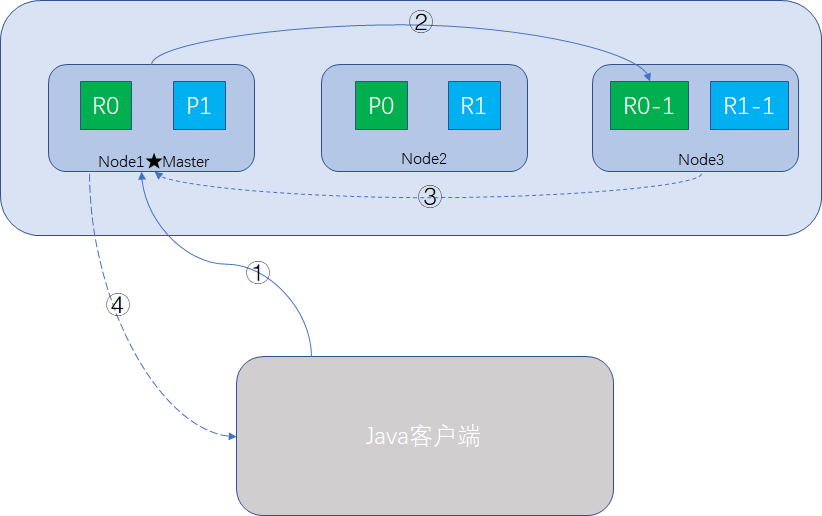
- Coordinate Node接收到请求后,根据_id信息或routing信息,确定该document的路由信息,即在哪个shard里,比如说P0。
- Coordinate Node转发请求,使用round-robin随机轮询算法 ,在primary shard或replica shard随机挑一个,让读请求负载均衡,如node-3的R0-1
- 接收请求的node-3搜索完成后,响应结果给Coordinate Node。
- Coordinate Node将响应结果返回给客户端。
注意一个问题,如果document还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时可能会无法读取到document,但是等document完成索引建立后,primary shard和replica shard就都有了,这个时间间隔,大概1秒左右。
写一致性要求
Elasticsearch在尝试执行一个写操作时,可以带上consistency参数,声明我们的写一致性的级别,正确地使用这个级别,为了避免因分区故障执行写操作,导致数据不一致,这个参数有三个值供选择:
- one:只要有一个primary shard是active活跃可用的,就可以执行写操作
- all:必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作
- quorum:默认的值,要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作
这个大部分,该怎么算呢?
这个大部分,叫规定数量(quorum),有个计算公式:
int( (primary + number_of_replicas) / 2 ) + 1
- primary 即一个索引下的primary shard数量;
- number_of_replicas即每个primary shard拥有的副本数量,注意不是一个索引所有的副本数量。
如果一个索引有3个primary shard,每个shard拥有1个replica shard,共6个shard,这样number_of_replicas就是1,代入公式计算:
quorum = int ((3 + 1) / 2) + 1 = 3
所以6个shard中必须有3个是活跃的,才让你写,如果你只启用2个node,这样活跃的replica shard只会有1个,加上primarys shard ,结果最多是2。这样是达不到quorun的值,因此将无法索引和删除任何文档。
此时你必须启动3个节点,才能满足quorum写一致性的要求。
quorum不够时的超时处理
如果写操作检查前,活跃的shard不够导致无法写入时,Elasticsearch会等待,希望宕机的node能够恢复,默认60秒,可以使用timeout参数修改默认值。
单node的写一致性
照上面的公式算,1个node的,1个索引1个primary shard,number_of_replicas为1的情况,计算公式:
quorum = int ((1 + 1) / 2) + 1 = 2
实际只有一个primary shard是活跃的,岂不是永远无法写入?我研发机器只启动一个node,不照样增删改查?
原来是Elasticsearch为了避免单一node的无法写入问题,加了判断逻辑:只有number_of_replicas大于1的时候,quorum才会生效。
小结
本篇从性能优先的角度简单对bulk的设计作了一些补充,并对文档查询,写操作的原理过程,一致性级别,quorum的计算做了一些简单讲解,谢谢。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区

Elasticsearch系列---补充几个知识点的更多相关文章
- Atitit s2018.6 s6 doc list on com pc.docx Atitit s2018.6 s6 doc list on com pc.docx Aitit algo fix 算法系列补充.docx Atiitt 兼容性提示的艺术 attilax总结.docx Atitit 应用程序容器化总结 v2 s66.docx Atitit file cms api
Atitit s2018.6 s6 doc list on com pc.docx Atitit s2018.6 s6 doc list on com pc.docx Aitit algo fi ...
- javacpp-FFmpeg系列补充:FFmpeg拉流截图实现在线演示demo(视频截图并返回base64图像,支持jpg/png/gif/bmp等多种格式)
javacpp-ffmpeg系列: javacpp-FFmpeg系列之1:视频拉流解码成YUVJ420P,并保存为jpg图片 javacpp-FFmpeg系列之2:通用拉流解码器,支持视频拉流解码并转 ...
- javacpp-FFmpeg系列补充:FFmpeg解决avformat_find_stream_info检索时间过长问题
javacpp-ffmpeg系列: javacpp-FFmpeg系列之1:视频拉流解码成YUVJ420P,并保存为jpg图片 javacpp-FFmpeg系列之2:通用拉流解码器,支持视频拉流解码并转 ...
- 【SpringBoot MQ 系列】RabbitMq 核心知识点小结
[MQ 系列]RabbitMq 核心知识点小结 以下内容,部分取材于官方教程,部分来源网络博主的分享,如有兴趣了解更多详细的知识点,可以在本文最后的文章列表中获取原地址 RabbitMQ 是一个基于 ...
- Elasticsearch 系列文章汇总(持续更新...)
系列文章列表 Query DSL Query DSL 概要,MatchAllQuery,全文查询简述 Match Query Match Phrase Query 和 Match Phrase Pre ...
- jvm系列四、jvm知识点总结
原文链接:http://www.cnblogs.com/ityouknow/p/6482464.html jvm 总体梳理 jvm体系总体分四大块: 类的加载机制 jvm内存结构 GC算法 垃圾回收 ...
- Elasticsearch系列---分布式架构机制讲解
概要 本篇主要介绍Elasticsearch的数据索引时的分片机制,集群发现机制,primary shard与replica shard是如何分工合作的,如何对集群扩容,以及集群的容错机制. 分片机制 ...
- Elasticsearch系列---搜索分页和deep paging问题
概要 本篇从介绍搜索分页为起点,简单阐述分页式数据搜索与原有集中式数据搜索思维方式的差异,就分页问题对deep paging问题的现象进行分析,最后介绍分页式系统top N的案例. 搜索分页语法 El ...
- Elasticsearch系列---实战零停机重建索引
前言 我们使用Elasticsearch索引文档时,最理想的情况是文档JSON结构是确定的,数据源源不断地灌进来即可,但实际情况中,没人能够阻拦需求的变更,在项目的某个版本,可能会对原有的文档结构造成 ...
随机推荐
- ansible-template
template简介 template功能: 根据模板文件动态生成对应的配置文件 template文件必须存放于templates目录下,且命名为 .j2 结尾 ansible的template模板使 ...
- docker入门篇
在网上的教程中,大多数是建议利用linux来安装docker,在此我也建议大家用linux安装,为什么?请看下图 docker使用go语言开发,并且运行在linux系统下,而如果想用window运行, ...
- 0xe7f001f0!?NDK调试过程,无故抛出SIGSEGV。
arm调试过程,如果抛一个SIGSEGV,地址在 0xe7f001f0 附近,原因居然是因为我在调试.当我使用n指令跳到下一行代码时,往往变成了continue指令一样地执行.还不确定地抛出SIGSE ...
- HTML的标签认识
<!-- html标签 h1~h6 标题标签(只有1~6,依次减小) p 段落标签 span 无意义的行标签 div 无意义的块标签 b 加粗 ...
- LoadRunner 录制问题集锦
关键词:各路录制小白汇集于此 虽然知道君对录制不感冒,但总是看到扎堆的人说这些问题,忍不住要站出来了. 百度虽好,帮助了很多小白,但关键是百度并没有排除错误内容,经过历史的几年传播,错的都快变对的了, ...
- TensorFlow2.0极简安装(亲测有效)
x相信每一个学习深度学习的人来说都知道Google的深度学习框架TensorFlow,估计每个人都想成为一个TF Boy(TensorFlow Boy).我也是这个想法,于是我踏上了安装TensorF ...
- mac 安装zmap
mac安装zmap有两种方式 1.命令行安装 brew install zmap export PATH=$PATH:/usr/local/sbin 很多人安装的时候只有第一步,然后直接bash:zm ...
- django-migrate一败再败
python3 manage.py makemigrations # 生成数据库迁移文件 python3 manage.py migrate # 迁移数据库 简简单单两条命令就完成了django的数据 ...
- Vue引入
Vue引入 概念: 1.el:实例 new Vue({ el: '#app' }) // 实例与页面挂载点一一对应 // 一个页面中可以出现多个实例对应多个挂载点 // 实例只操作挂载点内部内容 2. ...
- C语言I作业11
C语言 博客作业11 问题 回答 C语言程序设计II 博客作业11 这个作业要求在哪里 作业要求 我在这个课程的目标是 理解和弄懂局部变量和全局变量,静态变量和动态变量 这个作业在哪个具体方面帮助我实 ...