CSAPP:代码优化【矩阵读写】
写程序最主要的目标就是使它在所有可能的情况下都正确工作,另一方面,在很多情况下,让程序运行得很快也是一个重要的考虑因素。运算优化
编写高效程序需要做到以下两点:
- 选择一组合适的算法和数据结构
- 编写编译器能够有效优化以转换成高效可执行代码的源代码
第一点合适的算法和数据结构往往是大家写程序时会首先考虑到的,而第二点常被忽略。这里我们就代码优化而言,主要讨论如何编写能够被编译器有效优化的源代码,其中理解优化编译器的能力和局限性是很重要的。
以下我们将举例对常见的矩阵操作进行代码优化。
目标函数:图像逆时针旋转90°
旋转操作用下面两步操作完成:
- Transpose: 对第(i,j)个像素,执行Mij和Mji交换
- Exchange rows:行i和行N-1-i交换
原理图:

即对原有图像矩阵先进行一次对折,然后再进行一次翻转,就可以得到我们需要的逆时针旋转90°之后的矩阵。
其中我们用以下结构体表示一张图像的像素点:
typedef struct {
unsigned short red; /* R value */
unsigned short green; /* G value */
unsigned short blue; /* B value */
} pixel;
red、green、blue分别表示一张彩色图像的红绿蓝三个通道。
原旋转函数如下:
#define RIDX(i,j,n) ((i)*(n)+(j))
void naive_rotate(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(dim-1-j,i,dim)] = src[RIDX(i,j,dim)];
return;
}
图像是标准的正方形,用一维数组表示,第(i,j)个像素表示为I[RIDX(i,j,n)],n为图像边长。
参数:
- dim:图像的边长
- src: 指向原始图像数组首地址
- dst: 指向目标图像数组首地址
RIDX(i,j,dim)读取目标像素点,RIDX(dim-1-j,i,dim)将i、j参数位置互换,实现了斜角对折,dim-1-j实现了上下翻转。
优化目标:使旋转操作运行的更快
当前我们拥有一个driver.c文件,可以对原函数和我们优化的函数进行测试,得到表示程序运行性能的CPE(每元素周期数)参数。
我们的任务就是实现优化代码,与原有代码同时运行进行参数的对比,查看代码优化情况。
优化的主要方法
- 循环展开
- 并行计算
- 提前计算
- 分块运算
- 避免复杂运算
- 减少函数调用
- 提高Cache命中率
循环主体只存在一条语句,该语句为内存的读写(读取一个源像素,再写入目标像素),不涉及函数调用与计算。所以我们的优化手段有提高Cache命中率、避免复杂运算、分块运算、循环展开与并行计算。
优化一:提高Cache命中率
在矩阵运算中,提高Cache命中率是最容易想到的方法,常见的是外循环按行遍历与外循环按列遍历的对比,因为存储顺序是行序,所以前者的运行速度会明显优于后者。
在已给出的naive_rotate函数中,核心循环语句涉及到读取一个像素点与写入一个像素点,显然写入像素点比读取像素点更耗费时间,这是由存储器的性质决定的,所以我们应该优先对写入像素点的索引进行优化。

上图描述了8种数组索引顺序,位于上方的蓝色方块代表原始图像,黄色箭头表示原始像素的读取顺序,位于下方的蓝色方块代表旋转后图像,红色箭头表示目标像素的写入顺序。
由于循环体执行速度主要与数据写入相关,所以我们优先考虑红色箭头也就是写入像素的cache命中率。
第一组到第四组的写入像素都是按照列序,理论上写入效果应该最差,第五第六组正向行序写入执行效果应该是最好的,第七第八组逆向行序应该稍差。下面我们给出分别按照8种不同顺序索引的代码,使用driver测试出他们的运行效率:
void rotate_leftup(int dim, pixel *src, pixel *dst)
{
int i, j;
for (i = 0; i < dim; i++)
for (j = 0; j < dim; j++)
dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j, dim)];
}
void rotate_leftdown(int dim, pixel *src, pixel *dst)
{
int i, j;
for (i = dim-1; i > -1; i--)
for (j = 0; j < dim; j++)
dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j, dim)];
}
void rotate_rightup(int dim, pixel *src, pixel *dst)
{
int i, j;
for (i = 0; i < dim; i++)
for (j = dim-1; j > -1; j--)
dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j, dim)];
}
void rotate_rightdown(int dim, pixel *src, pixel *dst)
{
int i, j;
for (i = dim-1; i > -1; i--)
for (j = dim-1; j > -1; j--)
dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j, dim)];
}
void rotate_upleft(int dim, pixel *src, pixel *dst)
{
int i, j;
for (j = 0; j < dim; j++)
for (i = 0; i < dim; i++)
dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j, dim)];
}
void rotate_upright(int dim, pixel *src, pixel *dst)
{
int i, j;
for (j = dim-1; j > -1; j--)
for (i = 0; i < dim; i++)
dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j, dim)];
}
void rotate_downleft(int dim, pixel *src, pixel *dst)
{
int i, j;
for (j = 0; j < dim; j++)
for (i = dim-1; i > -1; i--)
dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j, dim)];
}
void rotate_downright(int dim, pixel *src, pixel *dst)
{
int i, j;
for (j = dim-1; j > -1; j--)
for (i = dim-1; i > -1; i--)
dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j, dim)];
}
CPE与机器运行速度有关,测试机比较老,又是虚拟机环境,所以测得的CPE很低


- Dim:图像大小
- Your CPEs:对应函数CPE
- Baseline CPEs:参考基线CPE
- Speedup:加速比 = Baseline CPEs / Your CPEs
与理论估计的一样,前4组表现明显最差,其中的第一组正是原始待优化的函数,与理论估计相符。
第5-8组差异不大,第五第六组比第七第八组效果略好,但总体优化效果很不明显,重新检查循环体的执行语句,发现在索引时宏定义中包含了乘法运算,严重阻碍了程序的执行效率。
优化二:避免复杂运算
之前在索引像素点时,是通过乘法运算进行索引,加大了不必要的开销。如果使用矩阵的分块运算,虽然能够利用局部性原理在一定程度上优化程序,但依旧会受到乘法运算的严重影响,于是我们打算避免复杂运算通过循环展开的方式来对程序进一步优化。
具体的操作逻辑是,使用指针对元素进行索引,可以把之前的8种图像索引中的箭头,分拆成32个平行的箭头,通过指针运算一次处理32个像素,下面给出代码来更好的理解:
//1
void rotate_pleftup(int dim, pixel *src, pixel *dst)
{
int i,j;
for(i=0;i<dim;i+=32)
for(j=0;j<dim;j++){
pixel *dptr=dst+RIDX(dim-1-j,i,dim);
pixel *sptr=src+RIDX(i,j,dim);
int step = -1;
while(++step < 32){
*(dptr++) = *sptr;
sptr += dim;
}
}
}
//2
void rotate_pleftdown(int dim, pixel *src, pixel *dst)
{
int i,j;
for(i=dim-1;i>30;i-=32)
for(j=0;j<dim;j++){
pixel *dptr=dst+RIDX(dim-1-j,i,dim);
pixel *sptr=src+RIDX(i,j,dim);
int step = 1;
while(--step > -32){
*(dptr--) = *sptr;
sptr -= dim;
}
}
}
//3
void rotate_prightup(int dim, pixel *src, pixel *dst)
{
int i,j;
for(i=0;i<dim;i+=32)
for(j=dim-1;j>-1;j--){
pixel *dptr=dst+RIDX(dim-1-j,i,dim);
pixel *sptr=src+RIDX(i,j,dim);
int step = -1;
while(++step < 32){
*(dptr++) = *sptr;
sptr += dim;
}
}
}
//4
void rotate_prightdown(int dim, pixel *src, pixel *dst)
{
int i,j;
for(i=dim-1;i>30;i-=32)
for(j=dim-1;j>-1;j--){
pixel *dptr=dst+RIDX(dim-1-j,i,dim);
pixel *sptr=src+RIDX(i,j,dim);
int step = 1;
while(--step > -32){
*(dptr--) = *sptr;
sptr -= dim;
}
}
}
//5
void rotate_pupleft(int dim, pixel *src, pixel *dst)
{
int i,j;
for(j=0;j<dim;j+=32)
for(i=0;i<dim;i++){
pixel *dptr=dst+RIDX(dim-1-j,i,dim);
pixel *sptr=src+RIDX(i,j,dim);
int step = -1;
while(++step < 32){
*dptr = *(sptr++);
dptr -= dim;
}
}
}//6
void rotate_pupright(int dim, pixel *src, pixel *dst)
{
int i,j;
for(j=dim-1;j>30;j-=32)
for(i=0;i<dim;i++){
pixel *dptr=dst+RIDX(dim-1-j,i,dim);
pixel *sptr=src+RIDX(i,j,dim);
int step = -1;
while(++step < 32){
*dptr = *(sptr--);
dptr += dim;
}
}
}
//7
void rotate_pdownleft(int dim, pixel *src, pixel *dst)
{
int i,j;
for(j = 0; j < dim; j+=32)
for(i = dim-1; i > -1; i--){
pixel *dptr=dst+RIDX(dim-1-j,i,dim);
pixel *sptr=src+RIDX(i,j,dim);
int step = -1;
while(++step < 32){
*dptr = *(sptr++);
dptr -= dim;
}
}
}
//8
void rotate_pdownright(int dim, pixel *src, pixel *dst)
{
int i,j;
for(j = dim-1; j > 30; j -= 32)
for(i = dim-1; i > -1; i--){
pixel *dptr=dst+RIDX(dim-1-j,i,dim);
pixel *sptr=src+RIDX(i,j,dim);
int step = -1;
while(++step < 32){
*dptr = *(sptr--);
dptr += dim;
}
}
}
指针每循环找到一个像素,会对其所在的某一行或某一列的32个像素进行变换,这样既通过局部性提高了cache命中率,也能够有效的避开乘法运算造成的性能损失。以下是对优化一中的8个函数进行循环展开的优化情况:


可以看到,1、3的运行效果最好,2、4的运行效果相对略低,5-8运行效果最差,但即便是按照最差的顺序循环展开,也远远超过了优化一中最好的索引顺序,这也证明了乘法运算是阻碍之前优化的主要因素。
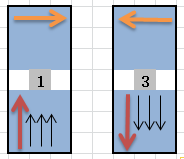
优化二中为什么变成了1、3运行效率最好?
通过之前的8种循环次序的分析图,我们可以看到1、3两组在写入的时候,如果使用32路循环展开,每次都可以通过指针索引到后面31个像素(黑色箭头代表其余31路的写入),cache命中率最高:
优化三:并行计算
优化二中的循环展开,其实也可以看作是一种特殊的分块运算,分块大小为1*32的小矩阵,各种优化方法之间总体来说具有相关性,大多都是基于cache缓存考虑。
优化三中我们提高循环主语句运行的并行性,这里我们需要在32路循环时加入一个新的指针,在宏观上来看循环主体每条语句是无法并行的,但每一行代码并不是一个原子操作,微观到线程级别来看是可以出现并行的,这里我们只对优化二中最好的第一组进行修改:
void rotate_pleftup_4(int dim, pixel *src, pixel *dst)
{
int i,j;
for(i=0;i<dim;i+=32)
for(j=0;j<dim;j++)
{
pixel* dptr=dst+RIDX(dim-1-j,i,dim);
pixel* sptr=src+RIDX(i,j,dim);
pixel* dptr_ = dptr+1;
pixel* sptr_ = sptr+dim;
int step = -1;
while(++step < 16){
*dptr = *sptr;
sptr += dim+dim;
dptr += 2;
*dptr_ = *sptr_;
sptr_ += dim+dim;
dptr_ += 2;
}
}
}
测试结果如下:

多次运行的话,得到的测试结果基本没有性能差距,但是如果将循环指针继续增加,使用4指针或者8指针循环,反而会出现性能下降的情况。
重新对原函数进行分析,函数主要执行的只是像素点的读写而已,并且我们已经去掉了耗时的乘法运算。这样一来,没什么能并行运算的地方,代码的并行性实际上并没有什么提升的空间,反而会随着多个指针的加入使得循环过程变得复杂增大开销,甚至可能会降低程序编译时的效率。
另外,在没什么性能提升的情况下,采用多个指针变量使得代码可读性变差,所以这里我们选择优化二的版本。
这并不意味着提高并行性的方法不好,只是在当前环境下不适用而已,如果使用得当会在原有基础上给程序带来更好的性能提升。
下面对比一下优化前和优化后的代码:

多出了5行循环语句,但加速比却从1.2到了7.8,提升了6.5倍,不采用并行优化的情况下代码可读性也未下降,这显然是值得的。
我们经常会涉及到关于矩阵的处理,特别是图像处理方面,而图像处理对性能有很高的需求。这只是一个矩阵操作/二维数组的简单例子,代码优化不局限于此,我们平时编码中很多时候并没有考虑那么多,都是按照常规写法逐步实现,这并没有什么不妥。但是当开始对自己的程序有提升性能的需求时,尝试对自己的代码做出优化不妨是一种更好的选择,这是写出高质量代码的必要途径。
转载请注明出处:https://www.cnblogs.com/ustca/p/11790314.html
CSAPP:代码优化【矩阵读写】的更多相关文章
- CSAPP:代码优化【矩阵运算】
编程除了使程序在所有可能的情况下都正确工作,还需要考虑程序的运行效率,上一节主要介绍了关于读写的优化,本节将对运算的优化进行分析.读写优化 编写高效程序需要做到以下两点: 选择一组合适的算法和数据结构 ...
- 【原创】开源Math.NET基础数学类库使用(01)综合介绍
本博客所有文章分类的总目录:[总目录]本博客博文总目录-实时更新 开源Math.NET基础数学类库使用总目录:[目录]开源Math.NET基础数学类库使用总目录 前言 ...
- 开源Math.NET基础数学类库使用(01)综合介绍
原文:[原创]开源Math.NET基础数学类库使用(01)综合介绍 开源Math.NET基础数学类库使用系列文章总目录: 1.开源.NET基础数学计算组件Math.NET(一)综合介绍 2. ...
- .NET数据挖掘与机器学习开源框架
1. 数据挖掘与机器学习开源框架 1.1 框架概述 1.1.1 AForge.NET AForge.NET是一个专门为开发者和研究者基于C#框架设计的,他包括计算机视觉与人工智能,图像处理,神经 ...
- 【CSAPP笔记】10. 代码优化
写程序的主要目标是使它在所有可能的情况下都能正确运行(bug free),一个运行得很快但有 bug 的程序是毫无用处的.在 bug free 的基础上,程序员必须写出清晰简洁的代码,这样做是为了今后 ...
- OpenCV 编程简单介绍(矩阵/图像/视频的基本读写操作)
PS. 因为csdn博客文章长度有限制,本文有部分内容被截掉了.在OpenCV中文站点的wiki上有可读性更好.而且是完整的版本号,欢迎浏览. OpenCV Wiki :<OpenCV 编程简单 ...
- 系统级编程(csapp)
系统级编程漫游 系统级编程提供学生从用户级.程序员的视角认识处理器.网络和操作系统,通过对汇编器和汇编代码.程序性能评测和优化.内存组织层次.网络协议和操作以及并行编程的学习,理解底层计算机系统对应用 ...
- 【转载】C代码优化方案
C代码优化方案 1.选择合适的算法和数据结构2.使用尽量小的数据类型3.减少运算的强度 (1)查表(游戏程序员必修课) (2)求余运算 (3)平方运算 (4)用移位实现乘除法运算 (5)避免不必要的整 ...
- CSAPP HITICS 大作业 hello's P2P by zsz
摘 要 摘要是论文内容的高度概括,应具有独立性和自含性,即不阅读论文的全文,就能获得必要的信息.摘要应包括本论文的目的.主要内容.方法.成果及其理论与实际意义.摘要中不宜使用公式.结构式.图表和非公知 ...
随机推荐
- 基于Docker搭建大数据集群(五)Mlsql部署
主要内容 mlsql部署 前提 zookeeper正常使用 spark正常使用 hadoop正常使用 安装包 微云下载 | tar包目录下 mlsql-cluster-2.4_2.11-1.4.0.t ...
- ZK 网络故障应对法
网络故障可以说是分布式系统天生的宿敌.如果永远不发生网络故障,我们实际上可以设计出高可用强一致的分布式系统.可惜的是不发生网络故障的分布式环境还不存在,ZK 使用过程中也需要小心的应付网络故障. 让我 ...
- com.rabbitmq.client.impl.ForgivingExceptionHandler.log:119 -An unexpected connection driver error occured
在服务器上安装了一个RabbitMq,并新创建了一个用户授予了管理员角色,登录控制台查看一切正常,兴高采烈启动项目进行连接,结果一盆冷水下来,报如下错误: o.s.a.r.l.SimpleMessag ...
- jar 命令使用
1.jar命令一般用来对jar包文件处理,jar包是由JDK安装目录\bin\jar.exe命令生成的,当我们安装好JDK,设置好path路径,就可以正常使用jar.exe命令,它会用lib\tool ...
- Flask基础(07)-->正则自定义转换器
正则自定义转换器 为什么要自定义正则转换器? 因为默认转换器太过于笨重,往往不能满足我们实际业务的需求,这时候我们就需要自定义正则转换器了. 那么我们怎么自定义正则转换器呢? from flask i ...
- 基于HTML5 WebGL的工业化3D电子围栏
前言 现代工业化的推进在极大加速现代化进程的同时也带来的相应的安全隐患,在传统的可视化监控领域,一般都是基于 Web SCADA 的前端技术来实现 2D 可视化监控,本系统采用 Hightopo 的 ...
- Weex项目快速打包
安装最新稳定版的Node.js 运行 cnpm install -g weex-toolkit 安装Weex 官方提供的 weex-toolkit 脚手架工具到全局环境中 运行 weex create ...
- java架构之路-(分布式zookeeper)zookeeper真实使用场景
上几次博客,我说了一下Zookeeper的简单使用和API的使用,我们接下来看一下他的真实场景. 一.分布式集群管理✨✨✨ 我们现在有这样一个需求,请先抛开Zookeeper是集群还是单机的概念,下面 ...
- Android 总结:ContentProvider 的使用
一.概述 ContentProvider:为存储和获取数据提供统一的接口,可以在不同的应用程序之间共享数据. Android内置的许多数据都是使用ContentProvider形式,供开发者调用的 ( ...
- MRP进程起不来, 报错:ORA-00600: internal error code, arguments: [2619], [227424], [], [], [], [], [], [], [], [], [], []
问题背景:客户数据库服务架构为一主一备,某日备库操作系统意外重启,重启后Oracle MRP进程起不来,报错:ORA-00600: internal error code, arguments: [2 ...