百万年薪python之路 -- 并发编程之 多线程 二
1. 死锁现象与递归锁
进程也有死锁与递归锁,进程的死锁和递归锁与线程的死锁递归锁同理。
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因为争夺资源而造成的一种互相等待的现象,在无外力的作用下,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在相互等待的进程称为死锁进程
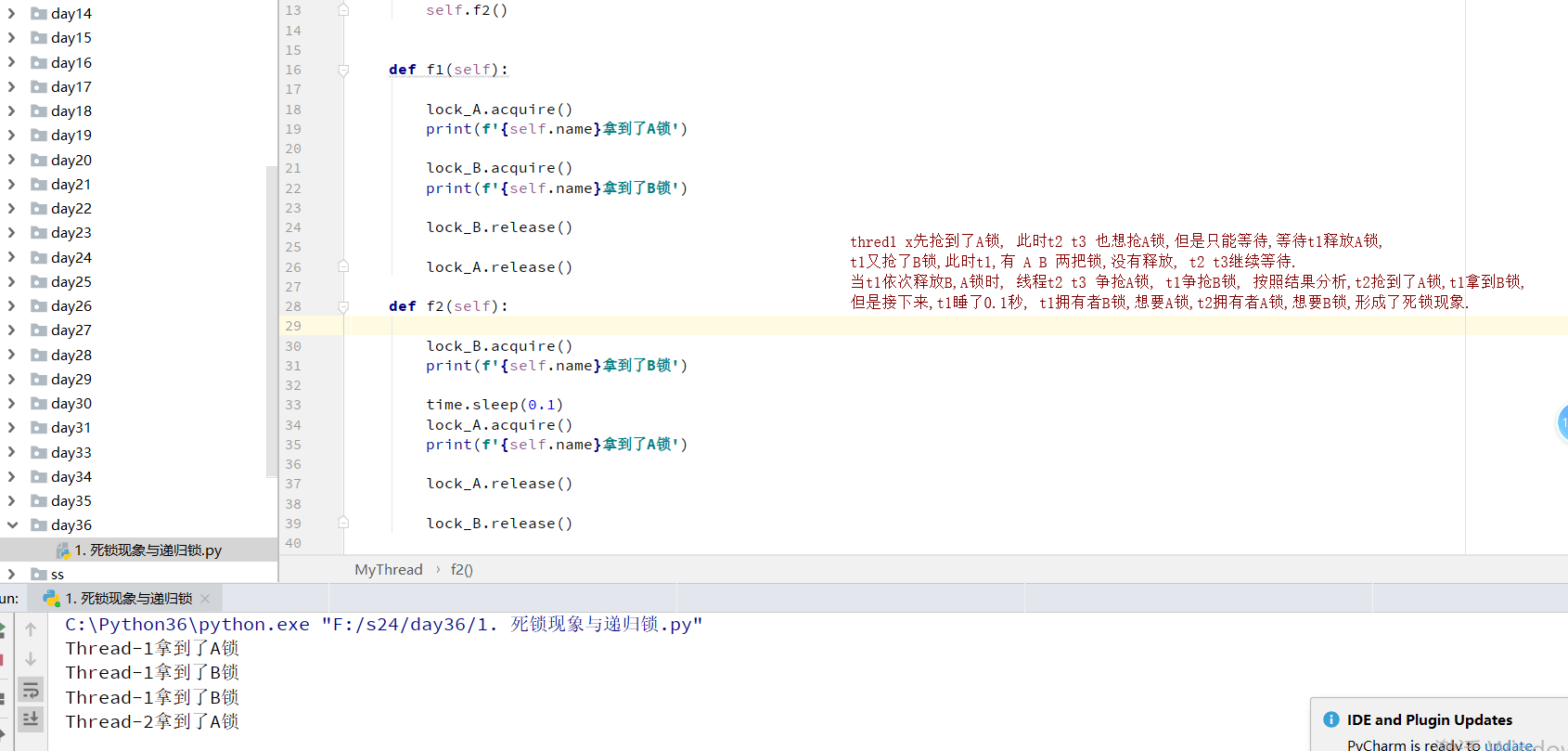
# 多个线程多个锁可能会产生死锁
from threading import Thread
from threading import Lock
import time
lock_A = Lock()
lock_B = Lock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f'{self.name}拿到A锁')
lock_B.acquire()
print(f'{self.name}拿到B锁')
lock_B.release()
lock_A.release()
def f2(self):
lock_B.acquire()
print(f'{self.name}拿到B锁')
time.sleep(0.1)
lock_A.acquire()
print(f'{self.name}拿到A锁')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()
print('主....')解决方法: 递归锁,在Python中为了支持在同一个线程中多次请求同一个资源,python提供了 可重复锁RLock,这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次acquire。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
from threading import Thread
from threading import RLock
import time
lock_A = lock_B = RLock() # 递归锁
# lock_A = RLock() # 这两行还是会死锁,原因不明
# lock_B = RLock() # 这两行还是会死锁,原因不明
# 递归锁有一个计数的功能, 原数字为0,上一次锁,计数+1,释放一次锁,计数-1,
# 只要递归锁上面的数字不为零,其他线程就不能抢锁.
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f'{self.name}拿到了A锁')
lock_B.acquire()
print(f'{self.name}拿到了B锁')
lock_B.release()
lock_A.release()
def f2(self):
lock_B.acquire()
print(f'{self.name}拿到了B锁')
time.sleep(0.1)
lock_A.acquire()
print(f'{self.name}拿到了A锁')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()递归锁可以解决死锁现象,任务需要多个锁时,先考虑递归锁
2. 信号量
也是一种锁,控制并发数量
同进程的一样
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
from threading import Thread,Semaphore,currentThread
import time
import random
sem = Semaphore(5)
def task():
sem.acquire()
print(f"{currentThread().name} WCing.....")
time.sleep(random.randint(1,3))
sem.release()
if __name__ == '__main__':
for i in range(20):
t = Thread(target=task)
t.start()进程池和信号量的区别:
进程池和信号量的区别:
进程池是多个需要被执行的任务在进程池外面排队等待获取进程对象去执行自己,而信号量是一堆进程等待着去执行一段逻辑代码。
信号量不能控制创建多少个进程,但是可以控制同时多少个进程能够执行,但是进程池能控制你可以创建多少个进程。
信号量:一次只允许固定的进程进行操作,进程的内存空间和创建时间都没减少,只减轻了操作系统的压力
进程池: 最多开启多少进程,节省内存空间和创建时间
举例:就像那些开大车拉煤的,信号量是什么呢,就好比我只有五个车道,你每次只能过5辆车,但是不影响你创建100辆车,但是进程池相当于什么呢?相当于你只有5辆车,每次5个车拉东西,拉完你再把车放回来,给别的人拉煤用。
其他语言里面有更高级的进程池,在设置的时候,可以将进程池中的进程动态的创建出来,当需求增大的时候,就会自动在进程池中添加进程,需求小的时候,自动减少进程,并且可以设置进程数量的上线,最多为多,python里面没有3. GIL全局解释器锁
好多自称大神的说,GIL锁就是python的致命缺陷,Python不能多核,并发不行等等 .....
首先,一些语言(java、c++、c)是支持同一个进程中的多个线程是可以应用多核CPU的,也就是我们会听到的现在4核8核这种多核CPU技术的牛逼之处。那么我们之前说过应用多进程的时候如果有共享数据是不是会出现数据不安全的问题啊,就是多个进程同时一个文件中去抢这个数据,大家都把这个数据改了,但是还没来得及去更新到原来的文件中,就被其他进程也计算了,导致数据不安全的问题啊,所以我们是不是通过加锁可以解决啊,多线程大家想一下是不是一样的,并发执行就是有这个问题。但是python最早期的时候对于多线程也加锁,但是python比较极端的(在当时电脑cpu确实只有1核)加了一个GIL全局解释锁,是解释器级别的,锁的是整个线程,而不是线程里面的某些数据操作,每次只能有一个线程使用cpu,也就说多线程用不了多核,但是他不是python语言的问题,是CPython解释器的特性,如果用Jpython解释器是没有这个问题的,Cpython是默认的,因为速度快,Jpython是java开发的,在Cpython里面就是没办法用多核,这是python的弊病,历史问题,虽然众多python团队的大神在致力于改变这个情况,但是暂没有解决。(这和解释型语言(python,php)和编译型语言有关系吗???待定!,编译型语言一般在编译的过程中就帮你分配好了,解释型要边解释边执行,所以为了防止出现数据不安全的情况加上了这个锁,这是所有解释型语言的弊端??)
首先了解一下,一个py文件的执行过程:
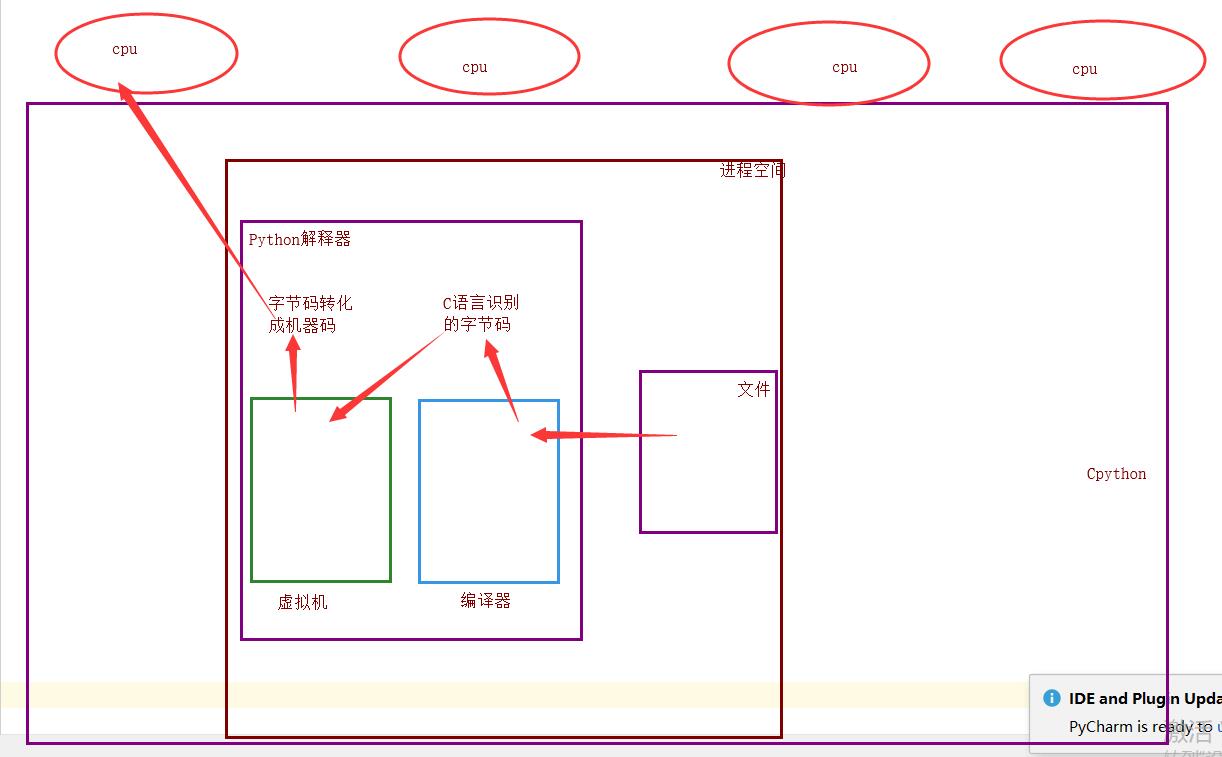
理论上python的单个进程应该可以使用多核,但CPython解释器在最初开发时,设置了GIL锁,同一时刻单进程只能有一个线程能进入CPython编译器.
为什么加锁?
当时都是单核时代,而且cpu价格非常贵.
如果不加全局解释器锁, 开发Cpython解释器的程序员就会在源码内部各种主动加锁,解锁,非常麻烦,各种死锁现象等等.他为了省事儿,直接进入解释器时给线程加一个锁.
优点: 保证了Cpython解释器的数据资源的安全.
缺点: 单个进程的多线程不能利用多核.
Jython没有GIL锁.
pypy也没有GIL锁.
现在多核时代, 我将Cpython的GIL锁去掉行么?
因为Cpython解释器所有的业务逻辑都是围绕着单个线程实现的,去掉这个GIL锁,几乎不可能.
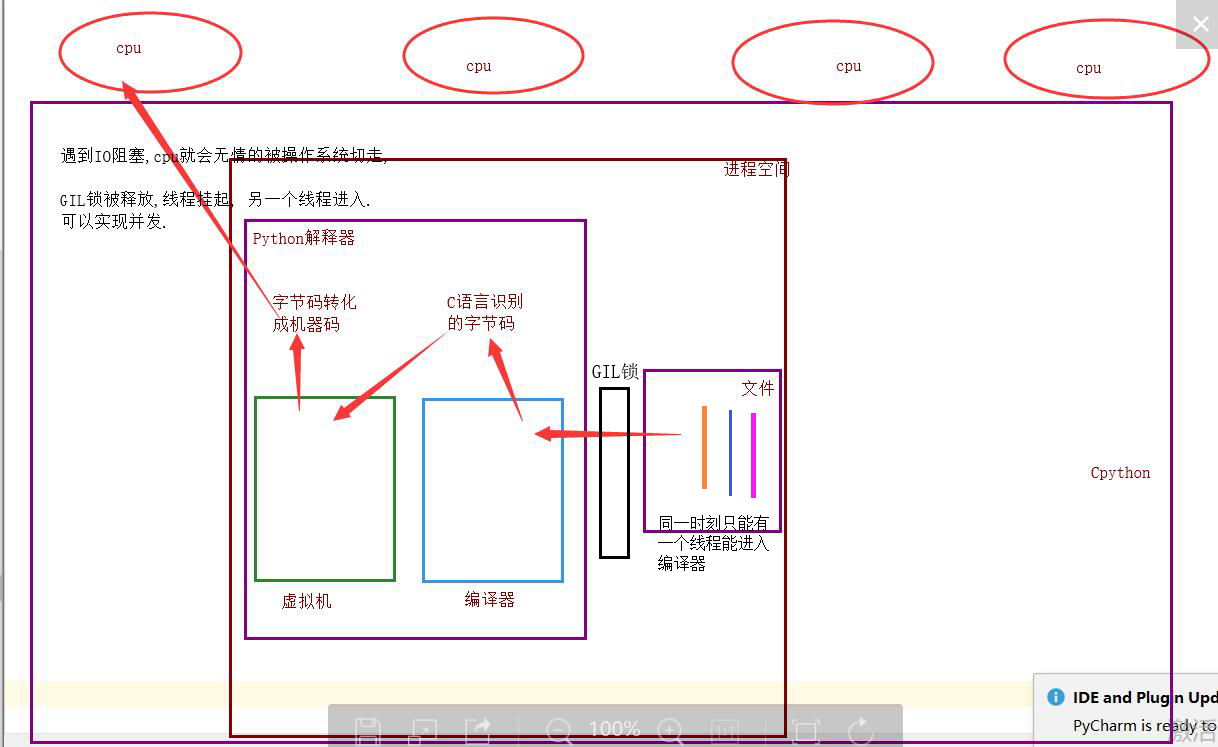
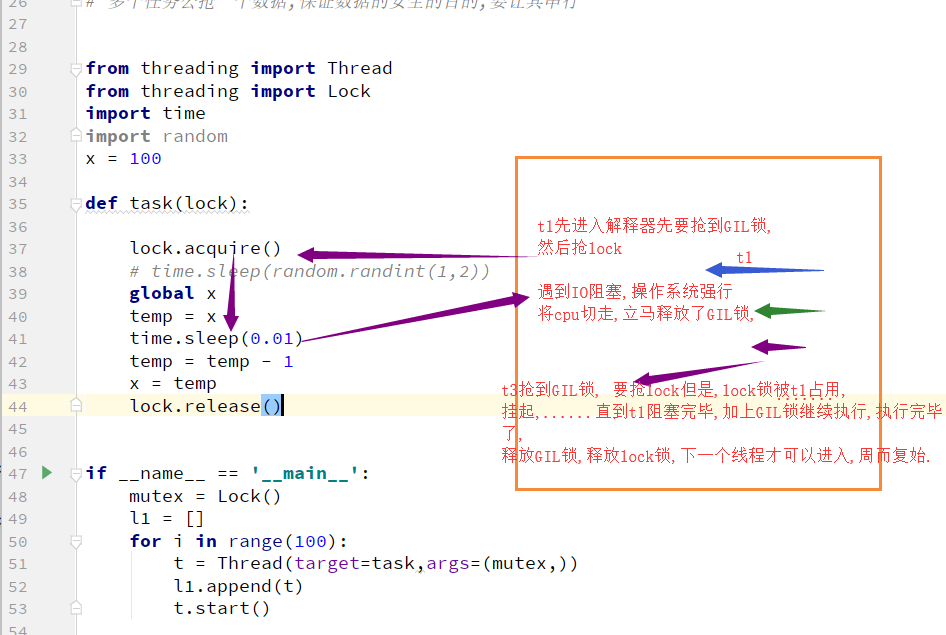
单个进程的多线程可以并发,但是不能利用多核,不能并行.但不同的进程的线程可以同一时刻进入多个CPU
但是有了这个锁我们就不能并发了吗?当我们的程序是偏计算的,也就是cpu占用率很高的程序(cpu一直在计算),就不行了,但是如果你的程序是I/O型的(一般你的程序都是这个)(input、访问网址网络延迟、打开/关闭文件读写),在什么情况下用的到高并发呢(金融计算会用到,人工智能(阿尔法狗),但是一般的业务场景用不到,爬网页,多用户网站、聊天软件、处理文件),I/O型的操作很少占用CPU,那么多线程还是可以并发的,因为cpu只是快速的调度线程,而线程里面并没有什么计算,就像一堆的网络请求,我cpu非常快速的一个一个的将你的多线程调度出去,你的线程就去执行I/O操作了,
IO密集型: 适合使用
计算密集型: 不适合使用
详细的GIL锁介绍:https://www.cnblogs.com/jin-xin/articles/11232225.html
4. GIL与lock锁的区别
相同点: 都是互斥锁
不同点:
GIL全局解释器锁,保护解释器内部的资源数据的安全.
GIL锁的上锁和释放无需手动操作.
自己代码中的互斥锁保护进程中的资源数据的安全.
自己定义的互斥锁必须自己手动上锁和释放锁.
5. 验证计算密集型IO密集型的效率
代码验证:
计算密集型: 单个进程的多线程并发 VS 多个进程的并发
## 计算密集型: 单个进程的多线程并发 VS 多个进程的并发
from threading import Thread
from multiprocessing import Process
import time
import random
def task():
count = 0
for i in range(10000000):
count += 1
if __name__ == '__main__':
# 多进程的并发
start_time = time.time()
l = []
for i in range(4):
p = Process(target=task)
l.append(p)
t.start()
for i in l:
i.join()
print(f"执行时间:{time.time() - start_time}")
# 执行时间:1.6398890018463135
# # 多线程的并发
# start_time = time.time()
# l = []
# for i in range(4):
# t = Thread(target=task)
# l.append(t)
# t.start()
#
# for i in l:
# i.join()
#
# print(f"执行时间:{time.time() - start_time}")
# # 执行时间:2.6619932651519775
# 结论: 计算密集型: 多进程的并发并行效率高.IO密集型: 单个进程的多个线程并发 VS 多个进程的并发并行
# IO密集型: 单个进程的多个线程并发 VS 多个进程的并发并行
from threading import Thread
from multiprocessing import Process
import time
import random
def task():
count = 0
time.sleep(random.randint(1,3))
count += 1
if __name__ == '__main__':
# 多进程的并发并行
# start_time = time.time()
# l = []
# for i in range(50):
# p = Process(target=task)
# l.append(p)
# p.start()
#
# for i in l:
# i.join()
#
# print(f"执行效率:{time.time() - start_time}")
# 执行效率:8.976764440536499
# 多线程的并发并行
start_time = time.time()
l = []
for i in range(50):
t = Thread(target=task)
l.append(t)
t.start()
for i in l:
i.join()
print(f"执行效率:{time.time() - start_time}")
# 执行效率:3.0085208415985107
# 对于IO密集型: 单个进程的多线程的并发效率高.6. 多线程实现socket通信
import socket
from threading import Thread
def communicate(conn,addr):
while 1:
try:
from_client_data = conn.recv(1024)
print(f'来自客户端{addr[1]}的消息: {from_client_data.decode("utf-8")}')
to_client_data = input('>>>').strip()
conn.send(to_client_data.encode('utf-8'))
except Exception:
break
conn.close()
def _accept():
server = socket.socket()
server.bind(('127.0.0.1', 8848))
server.listen(5)
while 1:
conn, addr = server.accept()
t = Thread(target=communicate,args=(conn,addr))
t.start()
if __name__ == '__main__':
_accept()# client
import socket
client = socket.socket()
client.connect(('127.0.0.1',8848))
while 1:
try:
to_server_data = input('>>>').strip()
client.send(to_server_data.encode('utf-8'))
from_server_data = client.recv(1024)
print(f'来自服务端的消息: {from_server_data.decode("utf-8")}')
except Exception:
break
client.close()7. 进程池,线程池
Python标准模块 -- concurrent.futures
使用threadPollExecutor和ProcessPollExecutor的方式一样,而且只要通过这个concurrent.futures导入就可以直接用他们两个了.
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
Both implement the same interface, which is defined by the abstract Executor class.
#2 基本方法
#submit(fn, *args, **kwargs)
异步提交任务
#map(func, *iterables, timeout=None, chunksize=1)
取代for循环submit的操作
#shutdown(wait=True)
相当于进程池的pool.close()+pool.join()操作
wait=True,等待池内所有任务执行完毕回收完资源后才继续
wait=False,立即返回,并不会等待池内的任务执行完毕
但不管wait参数为何值,整个程序都会等到所有任务执行完毕
submit和map必须在shutdown之前
#result(timeout=None)
取得结果
#add_done_callback(fn)
回调函数ThreadPoolExecutor简单使用:
import time
import os
import threading
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
def func(n):
time.sleep(2)
print('%s打印的:'%(threading.get_ident()),n)
return n*n
tpool = ThreadPoolExecutor(max_workers=5) #默认一般起线程的数据不超过CPU个数*5
# tpool = ProcessPoolExecutor(max_workers=5) #进程池的使用只需要将上面的ThreadPoolExecutor改为ProcessPoolExecutor就行了,其他都不用改
#异步执行
t_lst = []
for i in range(5):
t = tpool.submit(func,i) #提交执行函数,返回一个结果对象,i作为任务函数的参数 def submit(self, fn, *args, **kwargs): 可以传任意形式的参数
t_lst.append(t) #
# print(t.result())
#这个返回的结果对象t,不能直接去拿结果,不然又变成串行了,可以理解为拿到一个号码,等所有线程的结果都出来之后,我们再去通过结果对象t获取结果
tpool.shutdown() #起到原来的close阻止新任务进来 + join的作用,等待所有的线程执行完毕
print('主线程')
for ti in t_lst:
print('>>>>',ti.result())
# 我们还可以不用shutdown(),用下面这种方式
# while 1:
# for n,ti in enumerate(t_lst):
# print('>>>>', ti.result(),n)
# time.sleep(2) #每个两秒去去一次结果,哪个有结果了,就可以取出哪一个,想表达的意思就是说不用等到所有的结果都出来再去取,可以轮询着去取结果,因为你的任务需要执行的时间很长,那么你需要等很久才能拿到结果,通过这样的方式可以将快速出来的结果先拿出来。如果有的结果对象里面还没有执行结果,那么你什么也取不到,这一点要注意,不是空的,是什么也取不到,那怎么判断我已经取出了哪一个的结果,可以通过枚举enumerate来搞,记录你是哪一个位置的结果对象的结果已经被取过了,取过的就不再取了
#结果分析: 打印的结果是没有顺序的,因为到了func函数中的sleep的时候线程会切换,谁先打印就没准儿了,但是最后的我们通过结果对象取结果的时候拿到的是有序的,因为我们主线程进行for循环的时候,我们是按顺序将结果对象添加到列表中的。
# 37220打印的: 0
# 32292打印的: 4
# 33444打印的: 1
# 30068打印的: 2
# 29884打印的: 3
# 主线程
# >>>> 0
# >>>> 1
# >>>> 4
# >>>> 9
# >>>> 16
ThreadPoolExecutor的简单使用ProcessPoolExcutor的使用:
只需要将这一行代码改为下面这一行就可以了,其他的代码都不用变
tpool = ThreadPoolExecutor(max_workers=5) #默认一般起线程的数据不超过CPU个数*5
# tpool = ProcessPoolExecutor(max_workers=5)
你就会发现为什么将线程池和进程池都放到这一个模块里面了,用法一样
对,就是鸭子类型.map的使用:
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import threading
import os,time,random
def task(n):
print('%s is runing' %threading.get_ident())
time.sleep(random.randint(1,3))
return n**2
if __name__ == '__main__':
executor=ThreadPoolExecutor(max_workers=3)
# for i in range(11):
# future=executor.submit(task,i)
s = executor.map(task,range(1,5)) #map取代了for+submit
print([i for i in s])
map的使用回调函数的简单使用:
import time
import os
import threading
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
def func(n):
time.sleep(2)
return n*n
def call_back(m):
print('结果为:%s'%(m.result()))
tpool = ThreadPoolExecutor(max_workers=5)
t_lst = []
for i in range(5):
t = tpool.submit(func,i).add_done_callback(call_back)
回调函数简单应用回调函数的简单练习:
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from multiprocessing import Pool
import requests
import json
import os
def get_page(url):
print('<进程%s> get %s' %(os.getpid(),url))
respone=requests.get(url)
if respone.status_code == 200:
return {'url':url,'text':respone.text}
def parse_page(res):
res=res.result()
print('<进程%s> parse %s' %(os.getpid(),res['url']))
parse_res='url:<%s> size:[%s]\n' %(res['url'],len(res['text']))
with open('db.txt','a') as f:
f.write(parse_res)
if __name__ == '__main__':
urls=[
'https://www.baidu.com',
'https://www.python.org',
'https://www.openstack.org',
'https://help.github.com/',
'http://www.sina.com.cn/'
]
# p=Pool(3)
# for url in urls:
# p.apply_async(get_page,args=(url,),callback=pasrse_page)
# p.close()
# p.join()
p=ProcessPoolExecutor(3)
for url in urls:
p.submit(get_page,url).add_done_callback(parse_page) #parse_page拿到的是一个future对象obj,需要用obj.result()拿到结果
回调函数的应用,需要你自己去练习的线程池: 一个容器,这个容器限制住你开启线程的数量,比如4个,第一次肯定只能并发的处理4个任务,只要有任务完成,线程马上就会接下一个任务.
以时间换空间.
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import os
import time
import random
# print(os.cpu_count()) # 查看电脑的CPU数
def task(n):
print(f"{os.getpid()} 处理任务!")
time.sleep(random.randint(1,3))
if __name__ == '__main__':
# # 开启进程池 (并行(并发+并行))
# p = ProcessPoolExecutor() # 默认不写,进程池里面的进程数与CPU个数相等. # 8
# for i in range(20):
# p.submit(task,i)
# 开启多线程(并发)
# t = ThreadPoolExecutor() # 默认不写,就是开启CPU个数*5个线程数 # 8*5=40
t = ThreadPoolExecutor(100)
for i in range(20):
t.submit(task,i)由于生活中,一个服务器不可能同时接收太多请求(如1个亿),所有就采用线程池进行限制,如下有个小例子:
server端:
from threading import Thread
from concurrent.futures import ThreadPoolExecutor
import os
import socket
import time
import random
def communicate(conn, addr):
while 1:
try:
from_client_data = conn.recv(1024).decode("utf-8")
if from_client_data.lower() == "q":
print(f"客户端{addr}正常退出!")
break
print(f"来自客户端{addr}的消息:{from_client_data}")
msg = input(">>>").encode("utf-8")
conn.send(msg)
except Exception:
print(f"客户端{addr}非正常中断")
break
conn.close()
def accept_():
sk = socket.socket()
sk.bind(("127.0.0.1", 8080))
sk.listen(5)
t = ThreadPoolExecutor(3)
while 1:
conn, addr = sk.accept()
# t = Thread(target=communicate,args=(conn,addr))
t.submit(communicate, conn, addr)
sk.close()
if __name__ == '__main__':
accept_()client端:
import socket
sk = socket.socket()
sk.connect(("127.0.0.1",8080))
while 1:
try:
msg = input(">>>")
if msg == "":
print("输入不能为空,请重新输入!")
continue
sk.send(msg.encode("utf-8"))
if msg.lower() == "q":
break
from_server_data = sk.recv(1024).decode('UTF-8')
print(from_server_data)
except Exception:
break
sk.close()
百万年薪python之路 -- 并发编程之 多线程 二的更多相关文章
- 百万年薪python之路 -- 并发编程之 多线程 三
1. 阻塞,非阻塞,同步,异步 进程运行的三个状态: 运行,就绪,阻塞. 从执行的角度: 阻塞: 进程运行时,遇到IO了,进程挂起,CPU被切走. 非阻塞: 进程没有遇到IO 当进程遇到IO, ...
- 百万年薪python之路 -- 并发编程之 多线程 一
多线程 1.进程: 生产者消费者模型 一种编程思想,模型,设计模式,理论等等,都是交给你一种编程的方法,以后遇到类似的情况,套用即可 生产者与消费者模型的三要素: 生产者:产生数据的 消费者:接收数据 ...
- 百万年薪python之路 -- 并发编程之 多进程二
1. 僵尸进程和孤儿进程 基于unix的环境(linux,macOS) 主进程需要等待子进程结束之后,主进程才结束 主进程时刻检测子进程的运行状态,当子进程结束之后,一段时间之内,将子进程进行回收. ...
- 百万年薪python之路 -- 并发编程之 多进程 一
并发编程之 多进程 一. multiprocessing模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大 ...
- 百万年薪python之路 -- 并发编程之 协程
协程 一. 协程的引入 本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两 ...
- 百万年薪python之路 -- 数据库初始
一. 数据库初始 1. 为什么要有数据库? 先来一个场景: 假设现在你已经是某大型互联网公司的高级程序员,让你写一个火车票购票系统,来hold住十一期间全国的购票需求,你怎么写? 由于在同一时 ...
- 百万年薪python之路 -- Socket
Socket 1. 为什么学习socket 你自己现在完全可以写一些小程序了,但是前面的学习和练习,我们写的代码都是在自己的电脑上运行的,虽然我们学过了模块引入,文件引入import等等,我可以在程序 ...
- 百万年薪python之路 -- 面向对象之三大特性
1.面向对象之三大特性 1.1封装 封装:就是把一堆代码和数据,放在一个空间,并且可以使用 对于面向对象的封装来说,其实就是使用构造方法将内容封装到 对象 中,然后通过对象直接或者self间接获取被封 ...
- 百万年薪python之路 -- 面向对象之继承
面向对象之继承 1.什么是面向对象的继承 继承(英语:inheritance)是面向对象软件技术当中的一个概念. 通俗易懂的理解是:子承父业,合法继承家产 专业的理解是:子类可以完全使用父类的方法和属 ...
随机推荐
- 接口测试返回数据为JSONP格式时如何处理
#需要被处理的jsonp数据 JSONP = "jsonpreturn({'c': 1, 'd': 2});" #处理方法 def jsonp_to_json(JSONP): JS ...
- 简述python的turtle绘画命令及解释
一 基础认识 turtle库是python的标准库之一,它是一个直观有趣的图形绘制数据库,turtle(海龟)图形绘制的概念诞生1969年.它的应用十分广,而且使用简单,只要在编写python程序时写 ...
- 规则引擎 - drools 使用讲解(简单版) - Java
drools规则引擎 项目链接 现状: 运维同学(各种同学)通过后台管理界面直接配置相关规则,这里是通过输入框.下拉框等完成输入的,非常简单: 规则配置完毕后,前端请求后端,此时服务端根据参数(即规则 ...
- MySQL8安装及使用当中的一些注意事项
前言 这两天构建新项目,在本地安装的mysql8(本地环境windows),期间忘了密码,又卸载重装了一番,然后捣鼓了一顿授权给别人访问,最后磕磕绊绊的搞好了,下面是在这过程中遇到的问题及解决办法小结 ...
- HTML5存储--离线存储
离线存储技术 HTML5提出了两大离线存储技术:localstorage与Application Cache,两者各有应用场景:传统还有离线存储技术为Cookie. 经过实践我们认为localstor ...
- STM32进阶之串口环形缓冲区实现
队列的概念 在此之前,我们来回顾一下队列的基本概念: 队列 (Queue):是一种先进先出(First In First Out ,简称 FIFO)的线性表,只允许在一端插入(入队),在另一端进行删除 ...
- C# 常见面试问题汇总
1.c#垃圾回收机制 从以下方面入手展开: 1.压缩合并算法 2.代的机制 3.GC调用终结器 Garbage Collector . NET采用了和Java类似的方法由CLR(Common ...
- 爬虫 xpath
xpath简介 1.xpath使用路径表达式在xml和html中进行导航 2.xpath包含标准函数库 3.xpath是一个w3c的标准 xpath节点关系 1.父节点 2.字节点 3.同胞节点 4. ...
- webstrom 永久激活方法 ,长期可用
打开hosts文件:C:\Windows\System32\drivers\etc 在最后一行添加 0.0.0.0 account.jetbrains.com 打开webstorm,选择Activat ...
- Centos7安装及配置DHCP服务
DHCP服务概述: 名称:DHCP - Dynamic Host Configuration Protocol 动态主机配置协议. 功能:DHCP(Dynamic Host Configurati ...