Linux0.11源码学习(三)
Linux0.11源码学习(三)
linux0.11源码学习笔记
参考资料:
https://github.com/sunym1993/flash-linux0.11-talk
https://github.com/Akagi201/linux-0.11/blob/master/boot/head.s
源码查看:
https://elixir.bootlin.com/linux/latest/source
/boot/head.s
_pg_dir:
startup_32:
movl $0x10,%eax #0x10传入到32位eax寄存器
#置ds,es,fs,gs 中的选择符为setup.s 中构造的数据段(全局段描述符表的第2项)=0x10,
mov %ax,%ds
mov %ax,%es
mov %ax,%fs
mov %ax,%gs
lss _stack_start,%esp
解释:
对于GNU 汇编来说,每个直接数要以'$'开始,否则是表示地址。
每个寄存器名都要以'%'开头,eax 表示是32 位的ax 寄存器。
lss 指令相当于让 ss:esp 这个栈顶指针指向了 _stack_start 这个标号的位置。
疑问1:前面两个文件不是GNU汇编吗?前面寄存器名似乎没加"%"。
解答:
是的,由makefile文件,bootsect.s文件和setup.s文件通过8086汇编器和连接器进行编译和链接。而
head.s文件使用的是GNU汇编器。
疑问2:段寄存器赋值那边没看懂,mov不是把源操作数(逗号右侧)赋值给目标操作数(逗号左侧)吗?加了个"%"就颠倒了?
解答:
上面提到这是GNU汇编,GNU格式的汇编使用AT&T汇编,语句格式与 intel 格式的汇编不同,所谓的intel 格式也就是一般的 8086汇编(16bit),x86汇编(32bit)等。
疑问2提出的mov的用法正是intel格式的汇编,而head.s文件使用GNU汇编编译器编译,因此应符合GNU格式,GNU格式的源操作数和目标操作数的位置正好和Intel格式相反。详情参考他人博文。
call setup_idt # 设置中断描述符表
call setup_gdt # 设置全局描述符表
movl $0x10,%eax # reload all the segment registers
mov %ax,%ds # after changing gdt. CS was already
mov %ax,%es # reloaded in 'setup_gdt'
mov %ax,%fs
mov %ax,%gs
lss _stack_start,%esp
解释:
先设置了 idt 和 gdt,然后又重新执行了一遍刚刚执行过的代码。
为什么要重新设置这些段寄存器呢?因为上面修改了 gdt,所以要重新设置一遍以刷新才能生效。
/*
* setup_idt
*
* sets up a idt with 256 entries pointing to
* ignore_int, interrupt gates. It then loads
* idt. Everything that wants to install itself
* in the idt-table may do so themselves. Interrupts
* are enabled elsewhere, when we can be relatively
* sure everything is ok. This routine will be over-
* written by the page tables.
*/
setup_idt:
lea ignore_int,%edx
movl $0x00080000,%eax
movw %dx,%ax /* selector = 0x0008 = cs */
movw $0x8E00,%dx /* interrupt gate - dpl=0, present */
lea _idt,%edi
mov $256,%ecx
rp_sidt:
movl %eax,(%edi)
movl %edx,4(%edi)
addl $8,%edi
dec %ecx
jne rp_sidt
lidt idt_descr
ret
/*
* setup_gdt
*
* This routines sets up a new gdt and loads it.
* Only two entries are currently built, the same
* ones that were built in init.s. The routine
* is VERY complicated at two whole lines, so this
* rather long comment is certainly needed :-).
* This routine will be overwritten by the page tables.
*/
setup_gdt:
lgdt gdt_descr
ret
解释:
这里是定义的各个子程序。
中断描述符表 idt 里面存储着一个个中断描述符,每一个中断号就对应着一个中断描述符,而中断描述符里面存储着主要是中断程序的地址,这样一个中断号过来后,CPU 就会自动寻找相应的中断程序,然后去执行它。
看英文注释,setup_idt子程序设置了 256 个中断描述符,并且让每一个中断描述符中的中断程序例程都指向一个 ignore_int 的函数地址,这个是个默认的中断处理程序,之后会逐渐被各个具体的中断程序所覆盖。比如之后键盘模块会将自己的键盘中断处理程序,覆盖过去。
setup_gdt子程序设置了新的全局描述符表,即gdt表。
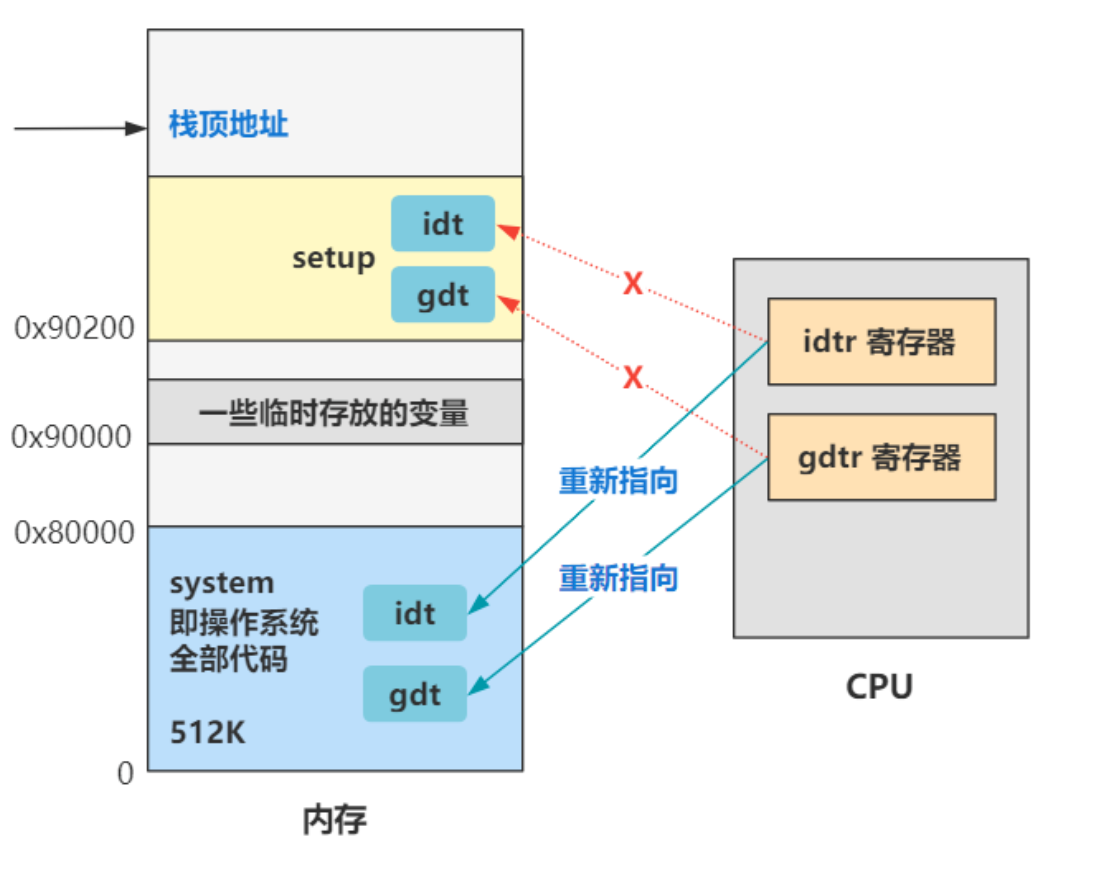
记得setup.s文件里设置过了idt和gdt了。
为什么原来已经设置过一遍了,这里又要重新设置一遍?
就是因为原来设置的 gdt 是在 setup 程序中,之后这个地方要被缓冲区覆盖掉,所以这里重新设置在 head 程序中,这块内存区域之后就不会被其他程序用到并且覆盖了。
图解:
xorl %eax,%eax
1: incl %eax # check that A20 really IS enabled
movl %eax,0x000000 # loop forever if it isn't
cmpl %eax,0x100000
je 1b
解释:
emm,这里是用于测试A20 地址线是否已经开启。采用的方法是向内存地址0x000000 处写入任意一个数值,然后看内存地址0x100000(1M)处是否也是这个数值。如果一直相同的话,就一直比较下去,也即死循环、死机。表示地址A20 线没有选通,结果内核就不能使用1M 以上内存。
/*
* NOTE! 486 should set bit 16, to check for write-protect in supervisor
* mode. Then it would be unnecessary with the "verify_area()"-calls.
* 486 users probably want to set the NE (#5) bit also, so as to use
* int 16 for math errors.
*/
movl %cr0,%eax # check math chip
andl $0x80000011,%eax # Save PG,PE,ET
/* "orl $0x10020,%eax" here for 486 might be good */
orl $2,%eax # set MP
movl %eax,%cr0
call check_x87
jmp after_page_tables
...
...
after_page_tables:
pushl $0 # These are the parameters to main :-)
pushl $0
pushl $0
pushl $L6 # return address for main, if it decides to.
pushl $_main
jmp setup_paging
L6:
jmp L6 # main should never return here, but
# just in case, we know what happens.
解释:
注释翻译
注意! 在下面这段程序中,486 应该将位 16 置位,以检查在超级用户模式下的写保护,此后"verify_area()"调用中就不需要了。486 的用户通常也会想将NE(#5)置位,以便对数学协处理器的出错使用int 16。
接着这段程序用于检查数学协处理器芯片是否存在。方法是修改控制寄存器CR0,在假设存在协处理器的情况下执行一个协处理器指令,如果出错的话则说明协处理器芯片不存在,需要设置CR0 中的协处理器仿真位EM(位2),并复位协处理器存在标志MP(位1)。(说实话,没看懂)
然后跳到after_page_tables标签处。
这边,pushl入栈操作,用于为调用/init/main.c 程序和返回作准备。但是前三个入栈操作似乎没有明确的意义,《Linux内核0.11(0.95)完全注释》的作者赵炯推测是为了调试方便做的。
pushl $L6入栈操作是模拟调用 main.c 程序时首先将返回地址入栈的操作,所以如果 main.c 程序真的退出时,就会返回到这里的标号L6 处继续执行下去,也即死循环。
pushl $_main将 main.c 的地址压入堆栈,这样,在设置分页处理(setup_paging)结束后执行'ret'返回指令时就会将 main.c 程序的地址弹出堆栈,并去执行 main.c 程序去了。
然后就跳到setup_paging去设置分页了。
/*
* Setup_paging
*
* This routine sets up paging by setting the page bit
* in cr0. The page tables are set up, identity-mapping
* the first 16MB. The pager assumes that no illegal
* addresses are produced (ie >4Mb on a 4Mb machine).
*
* NOTE! Although all physical memory should be identity
* mapped by this routine, only the kernel page functions
* use the >1Mb addresses directly. All "normal" functions
* use just the lower 1Mb, or the local data space, which
* will be mapped to some other place - mm keeps track of
* that.
*
* For those with more memory than 16 Mb - tough luck. I've
* not got it, why should you :-) The source is here. Change
* it. (Seriously - it shouldn't be too difficult. Mostly
* change some constants etc. I left it at 16Mb, as my machine
* even cannot be extended past that (ok, but it was cheap :-)
* I've tried to show which constants to change by having
* some kind of marker at them (search for "16Mb"), but I
* won't guarantee that's all :-( )
*/
setup_paging:
movl $1024*5,%ecx /* 5 pages - pg_dir+4 page tables */
xorl %eax,%eax
xorl %edi,%edi /* pg_dir is at 0x000 */
cld;rep;stosl
movl $pg0+7,_pg_dir /* set present bit/user r/w */
movl $pg1+7,_pg_dir+4 /* --------- " " --------- */
movl $pg2+7,_pg_dir+8 /* --------- " " --------- */
movl $pg3+7,_pg_dir+12 /* --------- " " --------- */
movl $pg3+4092,%edi
movl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */
std
1: stosl /* fill pages backwards - more efficient :-) */
subl $0x1000,%eax
jge 1b
xorl %eax,%eax /* pg_dir is at 0x0000 */
movl %eax,%cr3 /* cr3 - page directory start */
movl %cr0,%eax
orl $0x80000000,%eax
movl %eax,%cr0 /* set paging (PG) bit */
ret /* this also flushes prefetch-queue */
解释:
注释翻译,看看Linus的解释
/*
* 这个子程序通过设置控制寄存器cr0 的标志(PG 位31)来启动对内存的分页处理功能,
* 并设置各个页表项的内容,以恒等映射前16 MB 的物理内存。分页器假定不会产生非法的
* 地址映射(也即在只有4Mb 的机器上设置出大于4Mb 的内存地址)。
* 注意!尽管所有的物理地址都应该由这个子程序进行恒等映射,但只有内核页面管理函数能
* 直接使用>1Mb 的地址。所有“一般”函数仅使用低于1Mb 的地址空间,或者是使用局部数据
* 空间,地址空间将被映射到其它一些地方去 -- mm(内存管理程序)会管理这些事的。
* 对于那些有多于16Mb 内存的家伙 - 太幸运了,我还没有,为什么你会有?。代码就在这里,
* 对它进行修改吧。(实际上,这并不太困难的。通常只需修改一些常数等。我把它设置为
* 16Mb,因为我的机器再怎么扩充甚至不能超过这个界限(当然,我的机器很便宜的?)。
* 我已经通过设置某类标志来给出需要改动的地方(搜索“16Mb”),但我不能保证作这些
* 改动就行了??)。
*/
解释一下分页模式。
在没有开启分页机制时,由程序员给出的逻辑地址,需要先通过分段机制转换成物理地址。但在开启分页机制后,逻辑地址仍然要先通过分段机制进行转换,只不过转换后不再是最终的物理地址,而是线性地址,然后再通过一次分页机制转换,得到最终的物理地址。
关于开启分页模式后的地址转换,看图:
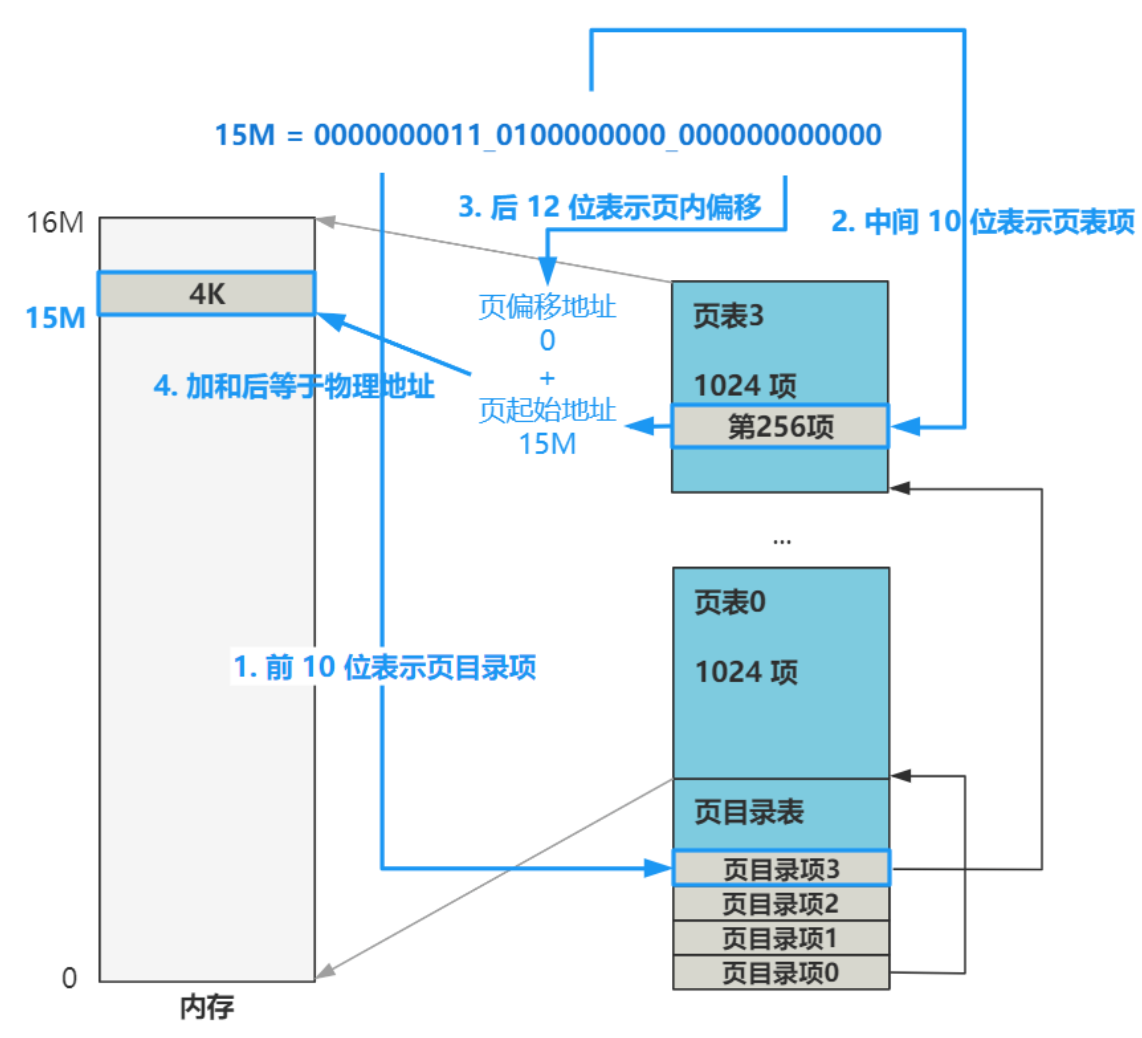
关于分页模式,可以参考一下我这篇博文
再看这段代码,其实Linus已经说明白了,这段代码就是帮我们把页表和页目录表在内存中写好,之后开启 cr0 寄存器的分页开关。但实际操作看起来还是有点麻烦的,就先囫囵吞枣的看一下吧(心虚:-).
这段子程序运行完之后,就会返回主程序了,按道理接下来就到main函数了。但为什么呢?记得我们把_main压栈了,那它是如何指向main的地址呢?
再看一下这段代码
after_page_tables:
pushl $0 # These are the parameters to main :-)
pushl $0
pushl $0
pushl $L6 # return address for main, if it decides to.
pushl $_main
jmp setup_paging
L6:
jmp L6 # main should never return here, but
# just in case, we know what happens.
解释:
setup_paging子程序最后一个指令是 ret,就是返回指令,返回到哪?
CPU 机械地把栈顶的元素值当做返回地址,跳转去那里执行。此时的栈顶元素是啥,要知道栈其实就是一个箱子,上面我们最后执行了pushl $_main,因此此时栈顶就是main函数的内存地址。
看图:
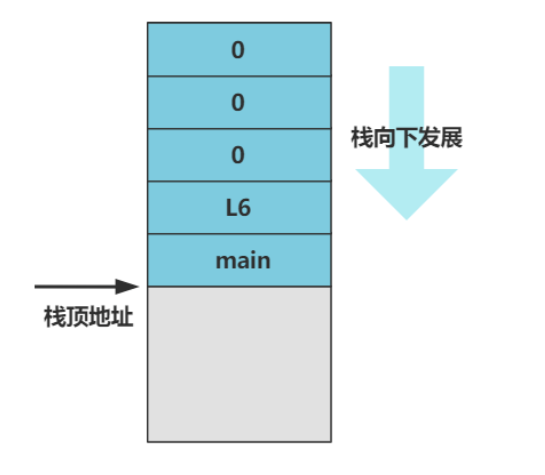
所以,setup_paging子程序设置好分页模式后返回,就会开始执行main函数啦。
位置在<init/main.c>
上一篇
Linux0.11源码学习(二)
下一篇
Linux0.11源码学习(四)
Linux0.11源码学习(三)的更多相关文章
- mybatis源码学习(三)-一级缓存二级缓存
本文主要是个人学习mybatis缓存的学习笔记,主要有以下几个知识点 1.一级缓存配置信息 2.一级缓存源码学习笔记 3.二级缓存配置信息 4.二级缓存源码 5.一级缓存.二级缓存总结 1.一级缓存配 ...
- Vue源码学习三 ———— Vue构造函数包装
Vue源码学习二 是对Vue的原型对象的包装,最后从Vue的出生文件导出了 Vue这个构造函数 来到 src/core/index.js 代码是: import Vue from './instanc ...
- spring源码学习(三)--spring循环引用源码学习
在spring中,是支持单实例bean的循环引用(循环依赖)的,循环依赖,简单而言,就是A类中注入了B类,B类中注入了A类,首先贴出我的代码示例 @Component public class Add ...
- [spring源码学习]三、IOC源码——自定义配置文件读取
一.环境准备 在文件读取的时候,第9步我们发现spring会根据标签的namespace来选择读取方式,联想spring里提供的各种标签,比如<aop:xxx>等应该会有不同的读取和解析方 ...
- linux0.11源码内核——系统调用,int80的实现细节
linux0.11添加系统调用的步骤 假设添加一个系统调用foo() 1.修改include/linux/sys.h 添加声明 extern int foo(); 同时在sys_call_table数 ...
- vue 源码学习三 vue中如何生成虚拟DOM
vm._render 生成虚拟dom 我们知道在挂载过程中, $mount 会调用 vm._update和vm._render 方法,vm._updata是负责把VNode渲染成真正的DOM,vm._ ...
- java集合类源码学习三——ArrayList
ArrayList无疑是java集合类中的一个巨头,而且或许是使用最多的集合类.ArrayList继承自AbstractList抽象类,实现了List<E>, RandomAccess, ...
- linux 0.11 源码学习+ IO模型
http://www.cnblogs.com/Fredric-2013/category/696688.html
- linuxlinux0.11源码学习——bootsect.s学习
由于一直想写一个自己的操作系统,网上推荐了<linux内核完全注释>.自学了一个星期,感觉这本书还是很好的,同时写下关于内核代码的理解,如果有什么不对的对方,欢迎大家一起来交流. 在内核引 ...
- Vue源码学习二 ———— Vue原型对象包装
Vue原型对象的包装 在Vue官网直接通过 script 标签导入的 Vue包是 umd模块的形式.在使用前都通过 new Vue({}).记录一下 Vue构造函数的包装. 在 src/core/in ...
随机推荐
- Windows MFC HTTP GET请求 函数流程
Windows MFC HTTP GET请求 函数流程 1 CString m_strHttpUrl(_T("http://10.200.80.86:8090/course/upload&q ...
- Byte流的压缩小技巧
使用Lz4: public class Lz4Tool { public static byte[] CompressBytes(byte[] bytes) { return LZ4Codec.Wra ...
- ZSTUOJ刷题11:Problem D.--零起点学算法106——首字母变大写
Problem D: 零起点学算法106--首字母变大写 Time Limit: 1 Sec Memory Limit: 64 MBSubmit: 18252 Solved: 5211 Descr ...
- HTML——VSCODE配置笔记
# 使用VSCODE编辑前端代码 ### 1.问题一:无法根据!快速生成html标准代码 (1).首先看文件命名是否出错,即文件名后缀名.html (2).第一步没出错,就在新建文件的编辑状态下拨动C ...
- CF546E
这题并不是太难 首先题目我们将每个城市拆点,由源点向一端连容量为初始人数的边,由另一端向汇点连容量为最后人数的边,然后按照题目要求从一端向另一端连容量无穷大的边 这样跑出最大流之后我们只需比较这个流量 ...
- Day14-封装、继承、多态
封装.继承.多态 一.封装 package Demo; //类 private私有 public class student { //属性私有 //名字 private String name; // ...
- Windows下配置Hadoop的Java开发环境
最近在学习用java来编写MapReduce程序,我是先在windows中开发完成,运行没有问题之后,再打成jar包,放到Linux集群中运行,由于在配置windows的开发环境的时候就花了大半天的时 ...
- 一键搭建dns
#!/bin/bash DOMAIN=wang.orgHOST=wwwHOST_IP=10.0.0.100LOCALHOST=`hostname -I | awk '{print $1}'` . /e ...
- vue+element 表格动态列添加点击事件与排序(/或者空值排最后)
<template> <div> <el-table ref="tableData" :data="tableData& ...
- 创建sqlSession对象操作数据库
1.加载核心配置文件 //加载mybatis核心配置文件,获取SqlSessionFactory String resource = "mybatis-config.xml"; I ...