DQL排序查询和DQL聚合函数
DQL:查询语句
排序查询
语法:
order by 字句
order by 排序字段1 排序方式1,排序字段2 排序方式2...
排序方式:
ASC:升序,默认的
DESC:降序
SELECT * FROM student ORDER BY math DESC;
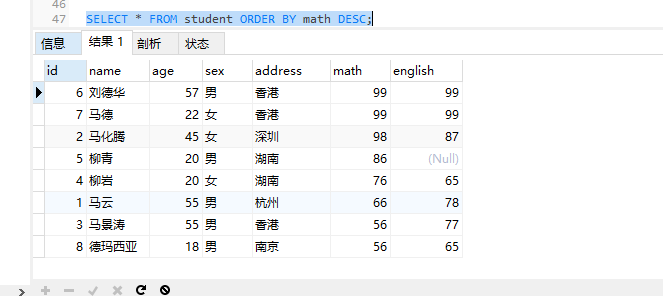
SELECT * FROM student ORDER BY math ASC;
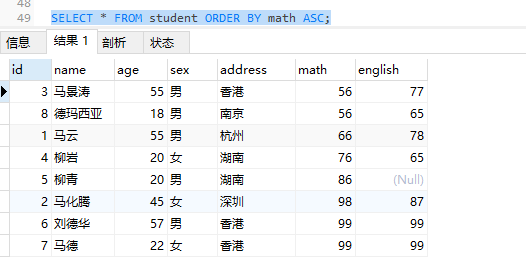
按照数学成绩排名,如果数学成绩异常,则按照英语成绩排名
SELECT * FROM student ORDER BY math ASC , english ASC;
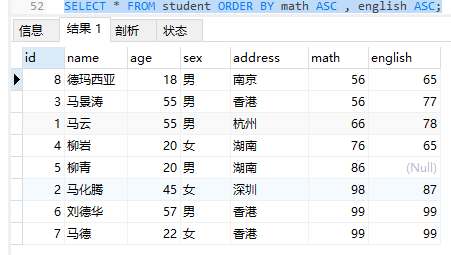
注意:如果有多个排序条件,则当前边的条件值一样的时候,才会判断第二条件。
聚合函数
聚合函数:将一列数据作为一个整体,进行纵向的计算
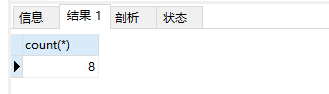
1.count:计算个数
select count(*) from student;
2.max:计算最大值
select max(math) from student;
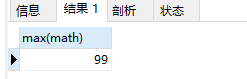
3.min:计算最小值
select min(math) from student;
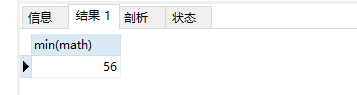
4.sum:计算和
select sum(math) from student;
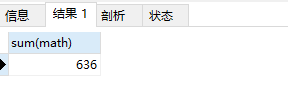
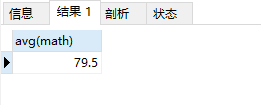
5.avg:计算平均值
select avg(math) from student;
注意:聚合函数的计算或排除null值
解决方案:
1.选择不包含非空的列进行计算
2.ifnull函数
DQL排序查询和DQL聚合函数的更多相关文章
- ef实现一次查询多个聚合函数的字段
想用ef来写一个统计字段的语句,如下所示 select sum(price) as price_total, sum(amount) as amount_total from table1 发现似乎实 ...
- MySQL查询语句详解,排序、分组、聚合函数、约束
create database day20; 查询的时候from前面的字段是需要显示出来的内容,后面是条件use day20;create table phones(id int,pinpai var ...
- Django模型层之字段查询参数及聚合函数
该系列教程系个人原创,并完整发布在个人官网刘江的博客和教程 所有转载本文者,需在顶部显著位置注明原作者及www.liujiangblog.com官网地址. 字段查询是指如何指定SQL WHERE子句的 ...
- django字段查询参数及聚合函数
字段查询是指如何指定SQL WHERE子句的内容.它们用作QuerySet的filter(), exclude()和get()方法的关键字参数. 默认查找类型为exact. 下表列出了所有的字段查询参 ...
- DQL分组查询和DQL分页查询
分组查询: 1.语法:group by 分组字段: 2.注意: 分组之后查询的字符按:分组字段.聚合函数 where 和having 的区别 where再分组前进行限定,如果不满足条件则不参与分组.h ...
- mysql 数据操作 单表查询 group by 聚合函数
强调: 如果我们用unique的字段作为分组的依据,则每一条记录自成一组,这种分组没有意义 多条记录之间的某个字段值相同,该字段通常用来作为分组的依据 如果按照每个字段都是唯一的进行分组,意味着按照这 ...
- mysql 数据操作 单表查询 group by 聚合函数 没有group by情况下
聚合函数只能用在组里使用 #没有group by 则默认算作一组 取出所有员工的最高工资 mysql> select max(salary) from employee; +---------- ...
- DQL基础查询和DQL条件查询
DQL:查询表中的记录 1.语法 select 字段列表 from 表名列表 where 条件列表 group by 分组字段 having 分组之后的条件 order by 排序 limit 分页限 ...
- sqlserver 模糊查询,连表,聚合函数,分组
use StudentManageDB go select StudentName,StudentAddress from Students where StudentAddress like '天津 ...
随机推荐
- CVE-2021-35042
CVE-2021-35042 漏洞介绍 Django 是 Python 语言驱动的一个开源模型-视图-控制器(MVC)风格的 Web 应用程序框架. 漏洞影响版本:django 3.1.3.2 202 ...
- JavaSE_关键字 接口 代码块 枚举
1 Java中的关键字 1.1 static关键字 static特点 : 静态成员被所在类的所有对象共享 随着类的加载而加载 , 优先于对象存在 可以通过对象调用 , 也可以通过类名调用 , 建议使用 ...
- 理“ Druid 元数据”之乱
vivo 互联网大数据团队-Zheng Xiaofeng 一.背景 Druid 是一个专为大型数据集上的高性能切片和 OLAP 分析而设计的数据存储系统. 由于Druid 能够同时提供离线和实时数据的 ...
- 【原创】项目一GoldenEye
实战流程 1,通过nmap查找本段IP中存活的机器 ┌──(root㉿whoami)-[/home/whoami/Desktop] └─# nmap -sP 192.168.186.0/24 排查网关 ...
- Spring IOC源码研究笔记(2)——ApplicationContext系列
1. Spring IOC源码研究笔记(2)--ApplicationContext系列 1.1. 继承关系 非web环境下,一般来说常用的就两类ApplicationContext: 配置形式为XM ...
- 《HALCON数字图像处理》第四章笔记
目录 第四章 HALCON数据结构 HALCON Image图像 图像通道 HALCON Region区域 Region的初步介绍 Region的点与线 Region的行程 Region的区域特征 H ...
- JAVA - 启动线程有哪几种方式
JAVA - 启动线程有哪几种方式 一.继承Thread类创建线程类 (1)定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务.因此把run()方法称为执行 ...
- 前端4BOM与DOM
内容概要 BOM操作(了解) DOM操作 DOM操作标签 获取值操作 属性操作 事件 -事件案例 内容详情 BOM操作(了解)
- Java实现http大文件流读取并批量插入数据库
1.概述 请求远程大文本,使用流的方式进行返回.需要设置http链接的超时时间 循环插入到List中,使用mybatis-plus批量插入到mysql中 2.需求 两台服务器 大文件放到其中一台服务器 ...
- numpy中shape的部分解释
转载自:https://blog.csdn.net/qq_28618765/article/details/78081959和https://www.jianshu.com/p/e083512e4f4 ...