Citus 分布式 PostgreSQL 集群 - SQL Reference(手动查询传播)
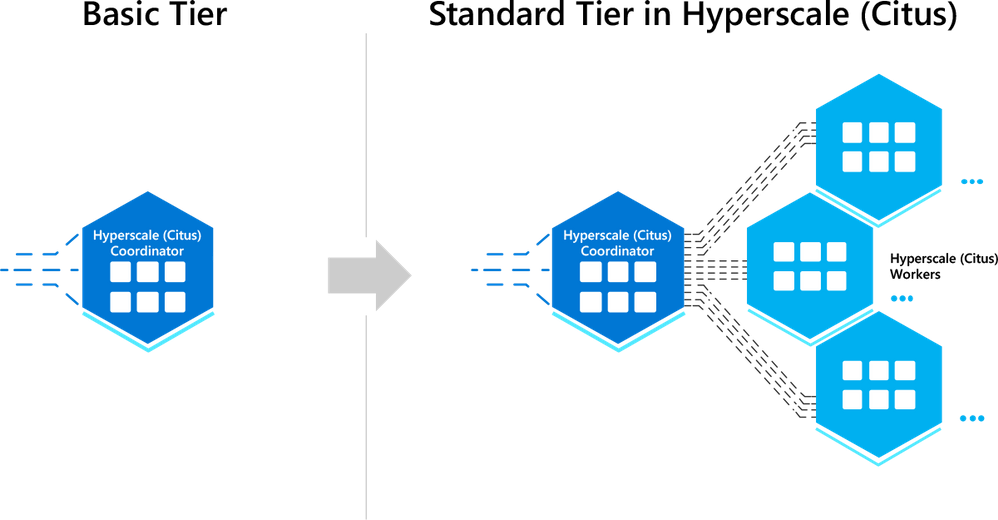
手动查询传播
当用户发出查询时,Citus coordinator 将其划分为更小的查询片段,其中每个查询片段可以在工作分片上独立运行。这允许 Citus 将每个查询分布在集群中。
但是,将查询划分为片段的方式(以及传播哪些查询)因查询类型而异。 在某些高级情况下,手动控制此行为很有用。 Citus 提供实用函数来将 SQL 传播到 workers、shards 或 placements。
手动查询传播绕过 coordinator 逻辑、锁定和任何其他一致性检查。 这些函数可作为最后的手段,以允许 Citus 否则不会在本机运行的语句。小心使用它们以避免数据不一致和死锁。
在所有 Worker 上运行
最小的执行级别是广播一条语句以在所有 worker 上执行。这对于查看整个工作数据库的属性很有用。
-- List the work_mem setting of each worker database
SELECT run_command_on_workers($cmd$ SHOW work_mem; $cmd$);
注意:
不应使用此命令在worker上创建数据库对象,因为这样做会使以自动方式添加worker节点变得更加困难。
注意:
本节中的run_command_on_workers函数和其他手动传播命令只能运行返回单列单行的查询。
在所有分片上运行
下一个粒度级别是在特定分布式表的所有分片上运行命令。例如,在直接在 worker 上读取表的属性时,它可能很有用。 在 worker 节点上本地运行的查询可以完全访问元数据,例如表统计信息。
run_command_on_shards 函数将 SQL 命令应用于每个分片,其中提供分片名称以在命令中进行插值。 这是一个估计分布式表行数的示例,通过使用每个 worker 上的 pg_class 表来估计每个分片的行数。 请注意将替换为每个分片名称的 %s。
-- Get the estimated row count for a distributed table by summing the
-- estimated counts of rows for each shard.
SELECT sum(result::bigint) AS estimated_count
FROM run_command_on_shards(
'my_distributed_table',
$cmd$
SELECT reltuples
FROM pg_class c
JOIN pg_catalog.pg_namespace n on n.oid=c.relnamespace
WHERE (n.nspname || '.' || relname)::regclass = '%s'::regclass
AND n.nspname NOT IN ('citus', 'pg_toast', 'pg_catalog')
$cmd$
);
在所有放置上运行
最精细的执行级别是在所有分片及其副本(也称为放置)上运行命令。它对于运行数据修改命令很有用,这些命令必须应用于每个副本以确保一致性。
例如,假设一个分布式表有一个 updated_at 字段,我们想要“触摸”所有行,以便在某个时间将它们标记为已更新。coordinator 上的普通 UPDATE 语句需要按分布列进行过滤,但我们可以手动将更新传播到所有分片和副本:
-- note we're using a hard-coded date rather than
-- a function such as "now()" because the query will
-- run at slightly different times on each replica
SELECT run_command_on_placements(
'my_distributed_table',
$cmd$
UPDATE %s SET updated_at = '2017-01-01';
$cmd$
);
run_command_on_placements 的一个有用伴侣是 run_command_on_colocated_placements。 它将位于共置的分布式表的两个位置的名称插入到查询中。放置对总是被选择为本地的同一个 worker,其中完整的 SQL 覆盖是可用的。因此,我们可以使用触发器等高级 SQL 功能来关联表:
-- Suppose we have two distributed tables
CREATE TABLE little_vals (key int, val int);
CREATE TABLE big_vals (key int, val int);
SELECT create_distributed_table('little_vals', 'key');
SELECT create_distributed_table('big_vals', 'key');
-- We want to synchronize them so that every time little_vals
-- are created, big_vals appear with double the value
--
-- First we make a trigger function, which will
-- take the destination table placement as an argument
CREATE OR REPLACE FUNCTION embiggen() RETURNS TRIGGER AS $$
BEGIN
IF (TG_OP = 'INSERT') THEN
EXECUTE format(
'INSERT INTO %s (key, val) SELECT ($1).key, ($1).val*2;',
TG_ARGV[0]
) USING NEW;
END IF;
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
-- Next we relate the co-located tables by the trigger function
-- on each co-located placement
SELECT run_command_on_colocated_placements(
'little_vals',
'big_vals',
$cmd$
CREATE TRIGGER after_insert AFTER INSERT ON %s
FOR EACH ROW EXECUTE PROCEDURE embiggen(%L)
$cmd$
);
限制
- 多语句事务没有防止死锁的安全措施。
- 没有针对中间查询失败和由此产生的不一致的安全措施。
- 查询结果缓存在内存中; 这些函数无法处理非常大的结果集。
- 如果无法连接到节点,这些函数会提前出错。
- 你可以做很坏的事情!
更多
- Citus 分布式 PostgreSQL 集群 - SQL Reference(创建和修改分布式表 DDL)
- Citus 分布式 PostgreSQL 集群 - SQL Reference(摄取、修改数据 DML)
- Citus 分布式 PostgreSQL 集群 - SQL Reference(查询分布式表 SQL)
- Citus 分布式 PostgreSQL 集群 - SQL Reference(查询处理)
Citus 分布式 PostgreSQL 集群 - SQL Reference(手动查询传播)的更多相关文章
- Citus 分布式 PostgreSQL 集群 - SQL Reference(摄取、修改数据 DML)
插入数据 要将数据插入分布式表,您可以使用标准 PostgreSQL INSERT 命令.例如,我们从 Github 存档数据集中随机选择两行. INSERT http://www.postgresq ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(查询分布式表 SQL)
如前几节所述,Citus 是一个扩展,它扩展了最新的 PostgreSQL 以进行分布式执行.这意味着您可以在 Citus 协调器上使用标准 PostgreSQL SELECT 查询进行查询. Cit ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(查询处理)
一个 Citus 集群由一个 coordinator 实例和多个 worker 实例组成. 数据在 worker 上进行分片和复制,而 coordinator 存储有关这些分片的元数据.向集群发出的所 ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(SQL支持和变通方案)
由于 Citus 通过扩展 PostgreSQL 提供分布式功能,因此它与 PostgreSQL 结构兼容.这意味着用户可以使用丰富且可扩展的 PostgreSQL 生态系统附带的工具和功能来处理使用 ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(创建和修改分布式表 DDL)
创建和分布表 要创建分布式表,您需要首先定义表 schema. 为此,您可以使用 CREATE TABLE 语句定义一个表,就像使用常规 PostgreSQL 表一样. CREATE TABLE ht ...
- 在 Kubernetes 上快速测试 Citus 分布式 PostgreSQL 集群(分布式表,共置,引用表,列存储)
准备工作 这里假设,你已经在 k8s 上部署好了基于 Citus 扩展的分布式 PostgreSQL 集群. 查看 Citus 集群(kubectl get po -n citus),1 个 Coor ...
- 分布式 PostgreSQL 集群(Citus),分布式表中的分布列选择最佳实践
确定应用程序类型 在 Citus 集群上运行高效查询要求数据在机器之间正确分布.这因应用程序类型及其查询模式而异. 大致上有两种应用程序在 Citus 上运行良好.数据建模的第一步是确定哪些应用程序类 ...
- 分布式 PostgreSQL 集群(Citus)官方安装指南
单节点 Citus Docker (Mac 与 Linux) Docker 镜像仅用于开发/测试目的, 并且尚未准备好用于生产用途. 您可以使用一个命令在 Docker 中启动 Citus: # st ...
- 分布式 PostgreSQL 集群(Citus)官方教程 - 迁移现有应用程序
将现有应用程序迁移到 Citus 有时需要调整 schema 和查询以获得最佳性能. Citus 扩展了 PostgreSQL 的分布式功能,但它不是扩展所有工作负载的直接替代品.高性能 Citus ...
随机推荐
- WPF中TabControl控件和ListBox控件的简单应用(MVVM)
本文主要实现下图所示的应用场景: 对于Class1页,会显示用户的age和address属性,对于Class2页,会显示用户的age,address和sex属性.在左边的ListBox中选择对应的用户 ...
- Redis原理再学习05:数据结构-整数集合intset
intset介绍 intset 整数集合,当一个集合只有整数元素,且元素数量不多时,Redis 就会用整数集合作为集合键的底层实现. redis> SADD numbers 1 3 5 7 9 ...
- java几种数据的默认扩容机制
当底层实现涉及到扩容时,容器或重新分配一段更大的连续内存(如果是离散分配则不需要重新分配,离散分配都是插入新元素时动态分配内存),要将容器原来的数据全部复制到新的内存上, 这无疑使效率大大降低.加载因 ...
- tensorflow源码解析之common_runtime-device
目录 核心概念 device device_factory device_mgr device_set 1. 核心概念 在framework部分,我们介绍了DeviceAttributes和Devic ...
- GO语言基础(结构+语法+类型+变量)
GO语言基础(结构+语法+类型+变量) Go语言结构 Go语言语法 Go语言类型 Go语言变量 Go 语言结构 Go 语言的基础组成有以下几个部分: 包声明 引入包 函数 变量 语句 &a ...
- Java编程学习笔记(基础篇)
一.Java中的数据类型 1.基本数据类型:四类 八种 byte(1) boolean(1) short(2) char(2) int(4) float(4) long(8) double(8) 2. ...
- Java实例变量、局部变量、静态变量
实例变量(成员变量) 成员变量定义在类中,在整个类中都可以被访问,但在方法.构造方法和语句块之外 当一个对象被实例化之后,每个实例变量的值就跟着确定 实例变量在对象创建的时候创建,在对象被销毁时销毁 ...
- BUU [GKCTF 2021]签到
BUU [GKCTF 2021]签到 1.题目概述 2.解题过程 追踪HTTP流 在下面发现了一串可疑字符 Base16转base64 放到010里看看 复制下来,去转字符 好像不是,再回去找找其他的 ...
- 配置 PackMan 镜像
一.参考链接 阿里云镜像站 二.PackMan 镜像介绍 Packman 是 OpenSUSE 最大的第三方软件源,主要为 OpenSUSE 提供额外的软件包,包括音视频解码器.多媒体应用.游戏等. ...
- Linux 显示文件大小的命令
ll显示的是字节,可以使用-h参数来提高文件大小的可读性,另外ll不是命令,是ls -l的别名ls -al 是以字节单位显示文件或者文件夹大小: 字节b,千字节kb, 1G=1024M=1024*10 ...