12月20日内容总结——ajax补充知识点、多对多外键的三种创建方式、django内置序列化组件、批量操作数据、分页器推导思路与自定义分页器的使用、form组件
一、ajax补充说明
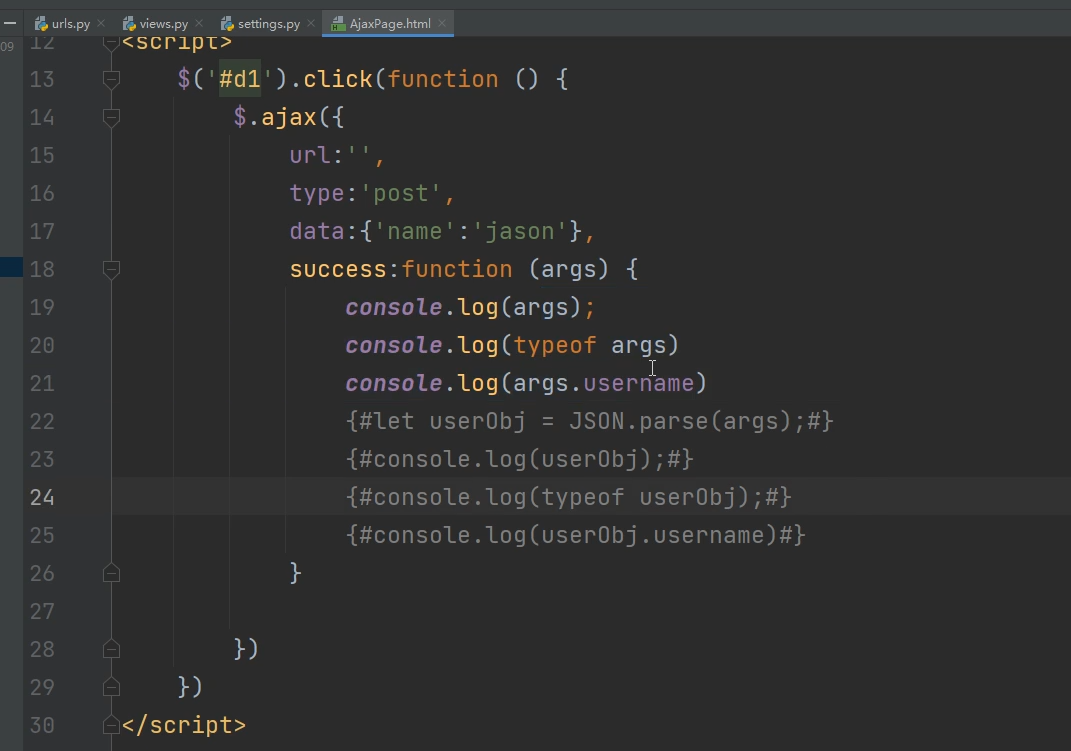
主要是针对回调函数args接收到的响应数据
1.后端request.is_ajax()
用于判断当前请求是否由ajax发出
2.后端返回的三板斧都会被args接收不再影响整个浏览器页面
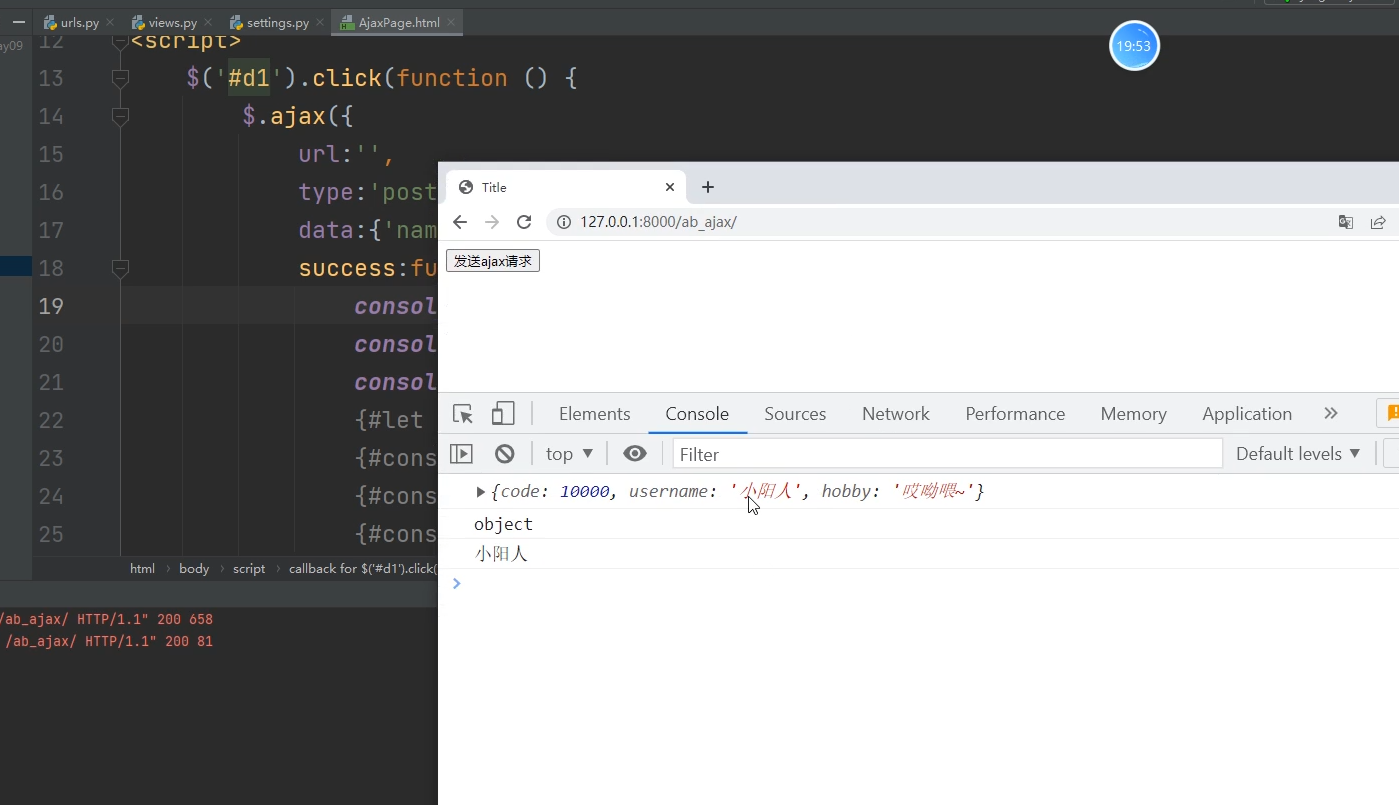
3.选择使用ajax做前后端交互的时候 后端一般返回的都是字典数据
user_dict = {'code': 10000, 'username': '小阳人', 'hobby': '哎呦喂~'}
ajax自动反序列化后端的json格式的bytes类型数据
dataType:'json',
4.回调函数
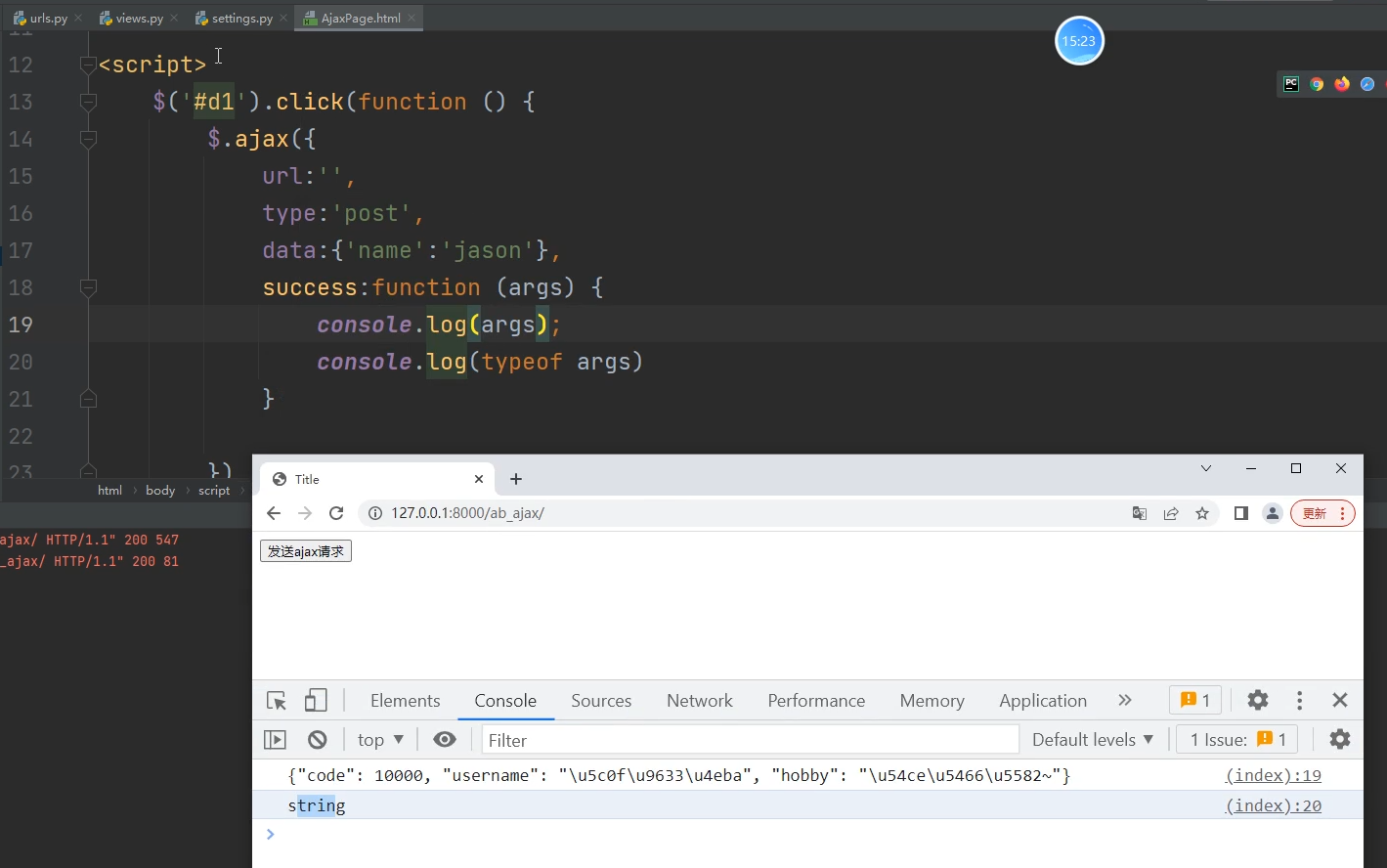
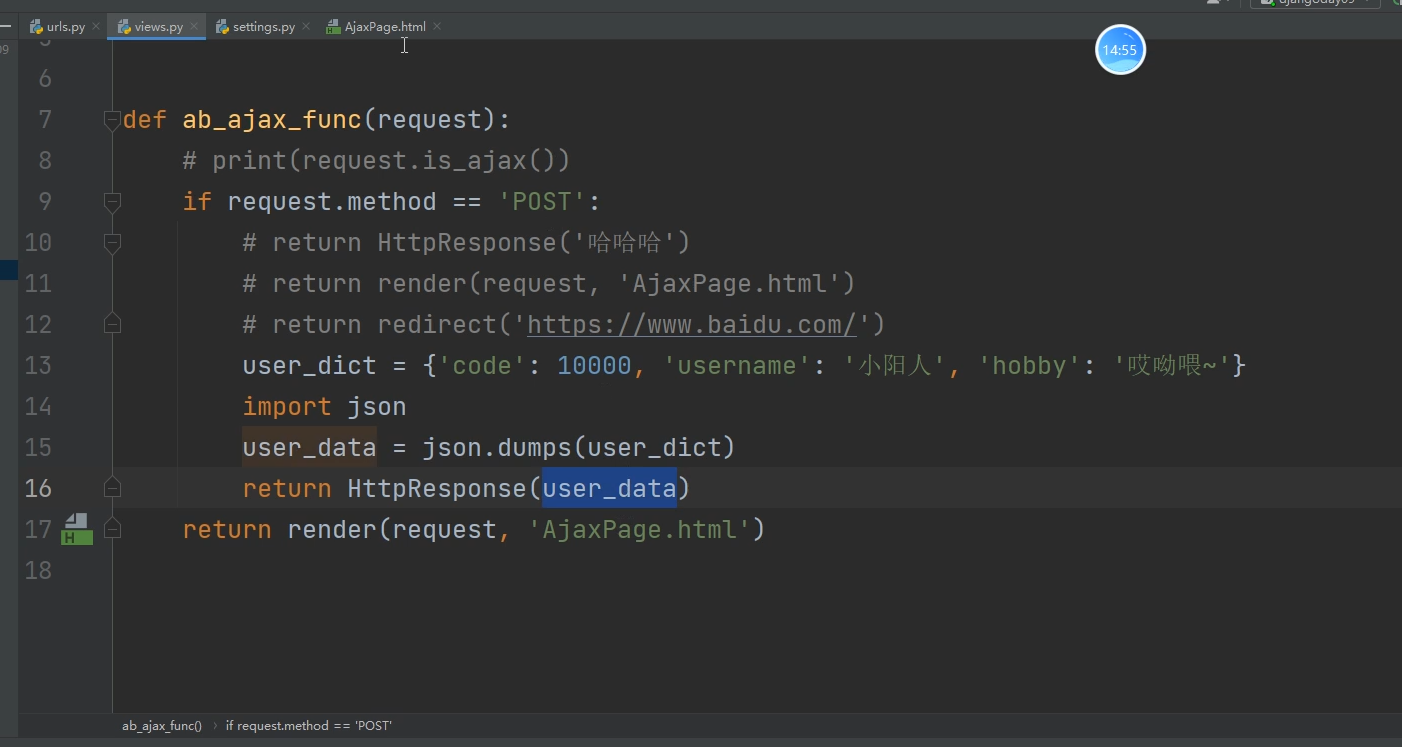
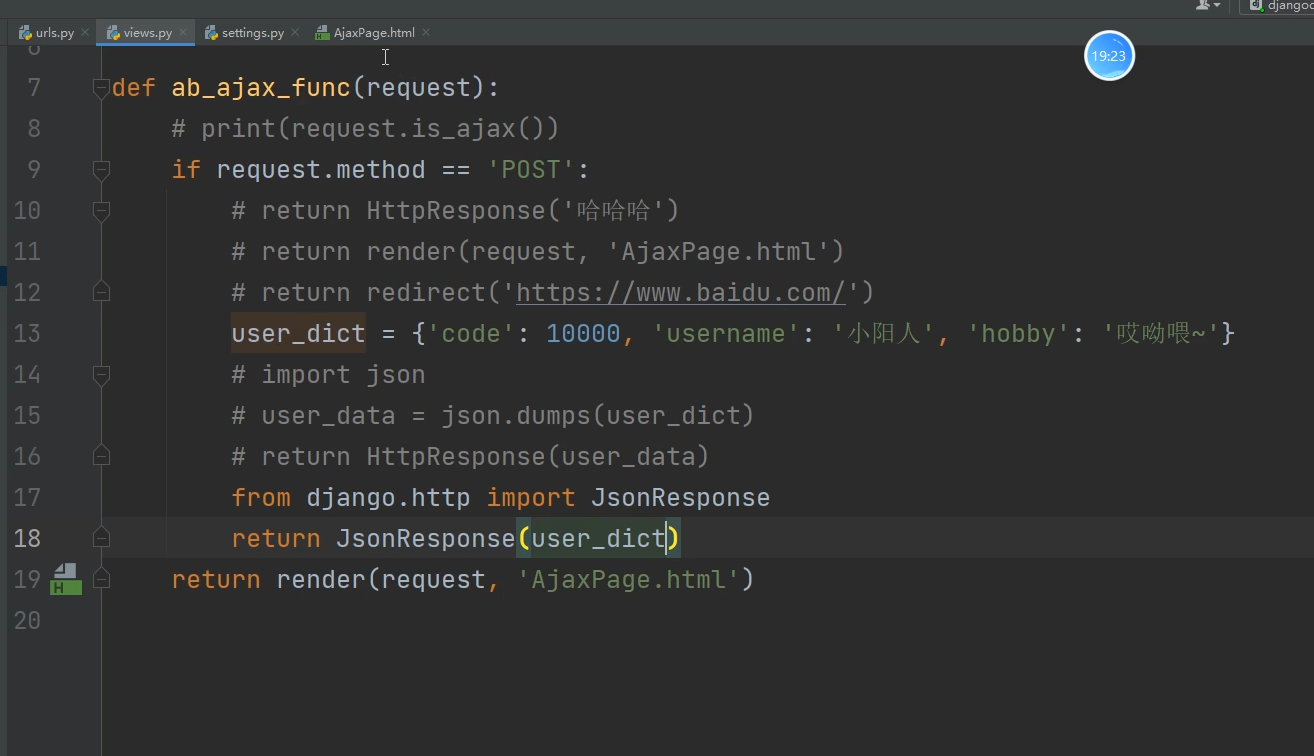
当我们使用Json格式的数据返回给前端,分别使用HttpResponse与JsonResponse两种方式。
我们会发现都能返回结果给前端,但是HttpResponse返回的数据会变成string类型,不再是Json格式的数据。
而JsonResponse则会自动反序列化
HttpResponse
JsonResponse
二、多对多三种创建方式
1.全自动创建
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author')
class Author(models.Model):
name = models.CharField(max_length=32)
优势:自动创建第三张表 并且提供了add、remove、set、clear四种操作
劣势:第三张表无法创建更多的字段 扩展性较差
2.纯手动创建
class Book(models.Model):
title = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
others = models.CharField(max_length=32)
join_time = models.DateField(auto_now_add=True)
优势:第三张表完全由自己创建 扩展性强
劣势:编写繁琐 并且不再支持add、remove、set、clear以及正反向概念
3.半自动创建
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author',through='Book2Author',through_fields=('book','author'))
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book = models.ForeignKey(to='Book', on_delete=models.CASCADE)
author = models.ForeignKey(to='Author', on_delete=models.CASCADE)
others = models.CharField(max_length=32)
join_time = models.DateField(auto_now_add=True)
优势:第三张表完全由自己创建 扩展性强 正反向概念依然清晰可用
劣势:编写繁琐不再支持add、remove、set、clear
三、django内置序列化组件(drf前身)
这里的内置序列化组件,其实就是实现将后端数据,存放到字典中或是存放到列表中有序输出。
这里是我们用JsonResponse模块自己实现的代码
'''前后端分离的项目 视图函数只需要返回json格式的数据即可'''
from app01 import models
from django.http import JsonResponse
def ab_ser_func(request):
# 1.查询所有的书籍对象
book_queryset = models.Book.objects.all() # queryset [对象、对象]
# 2.封装成大字典返回
data_dict = {}
for book_obj in book_queryset:
temp_dict = {}
temp_dict['pk'] = book_obj.pk
temp_dict['title'] = book_obj.title
temp_dict['price'] = book_obj.price
temp_dict['info'] = book_obj.info
data_dict[book_obj.pk] = temp_dict # {1:{},2:{},3:{},4:{}}
return JsonResponse(data_dict)
序列化组件(django自带的,后续会学更厉害的drf)
# 导入内置序列化模块
from django.core import serializers
# 调用该模块下的方法,第一个参数是你想以什么样的方式序列化你的数据
res = serializers.serialize('json', book_queryset)
return HttpResponse(res)
使用序列化模块,不仅节省代码,同时他封装的更精致

四、批量操作数据
当我们给数据库插入很多的数据时,如果我们使用orm操作一条条用for循环插入数据,效率很低。
这里就需要介绍两个批量操作数据的方法:
models.Books01.objects.bulk_create
models.Books01.objects.bulk_update
这里的create是批量创建数据,update是批量更新数据。
在进行批量操作数据之前,下方代码使用的方式是把数据封装到对象中,然后把对象添加到一个列表中,最后执行批量操作的时候把这个列表当作参数放到小括号内即可。
def ab_bk_func(request):
# 1.往books表中插入10万条数据
# for i in range(1, 100000):
# models.Books.objects.create(title='第%s本书' % i)
"""直接循环插入 10s 500条左右"""
book_obj_list = [] # 可以用列表生成式[... for i in ... if ...] 生成器表达式(... for i in ... if ...)
for i in range(1, 100000):
book_obj = models.Books01(title='第%s本书' % i) # 单纯的用类名加括号产生对象
book_obj_list.append(book_obj)
# 批量插入数据
models.Books01.objects.bulk_create(book_obj_list)
"""使用orm提供的批量插入操作 5s 10万条左右"""
# 2.查询出所有的表中并展示到前端页面
book_queryset = models.Books01.objects.all()
return render(request, 'BkPage.html', locals())
五、分页器思路
分页器主要听处理逻辑 代码最后很简单
推导流程
1.queryset支持切片操作(正数)
2.研究各个参数之间的数学关系
每页固定展示多少条数据、起始位置、终止位置
3.自定义页码参数
current_page = request.GET.get('page')
4.前端展示分页器样式
5.总页码数问题
divmod方法
6.前端页面页码个数渲染问题
后端产生 前端渲染(通常来说后端返回的都是奇数的页码个数)
部分代码展示
def ab_bk_func(request):
per_page_num = 10 # 每页展示多少条数据
current_page = request.GET.get('page', 1)
try:
current_page = int(current_page)
except BaseException:
current_page = 1
book_queryset = models.Books01.objects.all()
all_count = book_queryset.count()
all_page_num, more = divmod(all_count, per_page_num)
if more:
all_page_num += 1
# 由于模板语法没有range功能 但是我们需要循环产生很多分页标签 所以考虑后端生成传递给html页面
html_str = ''
xxx = current_page
if xxx < 6:
xxx = 6
for i in range(xxx - 5, xxx + 6):
if current_page == i:
html_str += '<li class="active"><a href="?page=%s">%s</a></li>' % (i, i)
else:
html_str += '<li><a href="?page=%s">%s</a></li>' % (i, i)
start_num = (current_page - 1) * per_page_num # 起始展示位置
end_num = current_page * per_page_num # 终止展示位置
book_queryset = book_queryset[start_num:end_num]
return render(request, 'BkPage.html', locals())
"""
per_page_num=10 all_count=100 page_num=10
per_page_num=10 all_count=101 page_num=11
per_page_num=10 all_count=99 page_num=10
我们想通过代码动态计算出总共需要多少页
"""
"""
per_page_num = 10
current_page start_num end_num
1 0 10
2 10 20
3 20 30
per_page_num = 5
current_page start_num end_num
1 0 5
2 5 10
3 10 15
start_num = (current_page - 1) * per_page_num
end_num = current_page * per_page_num
"""
六、自定义分页器的使用
django自带分页器模块但是使用起来很麻烦 所以我们自己封装了一个(只需要掌握使用方式即可,以后用的不多)
步骤一:在应用目录下创建一个文件夹,比如utils文件夹,并在该目录下创建一个py文件(如mypage.py)
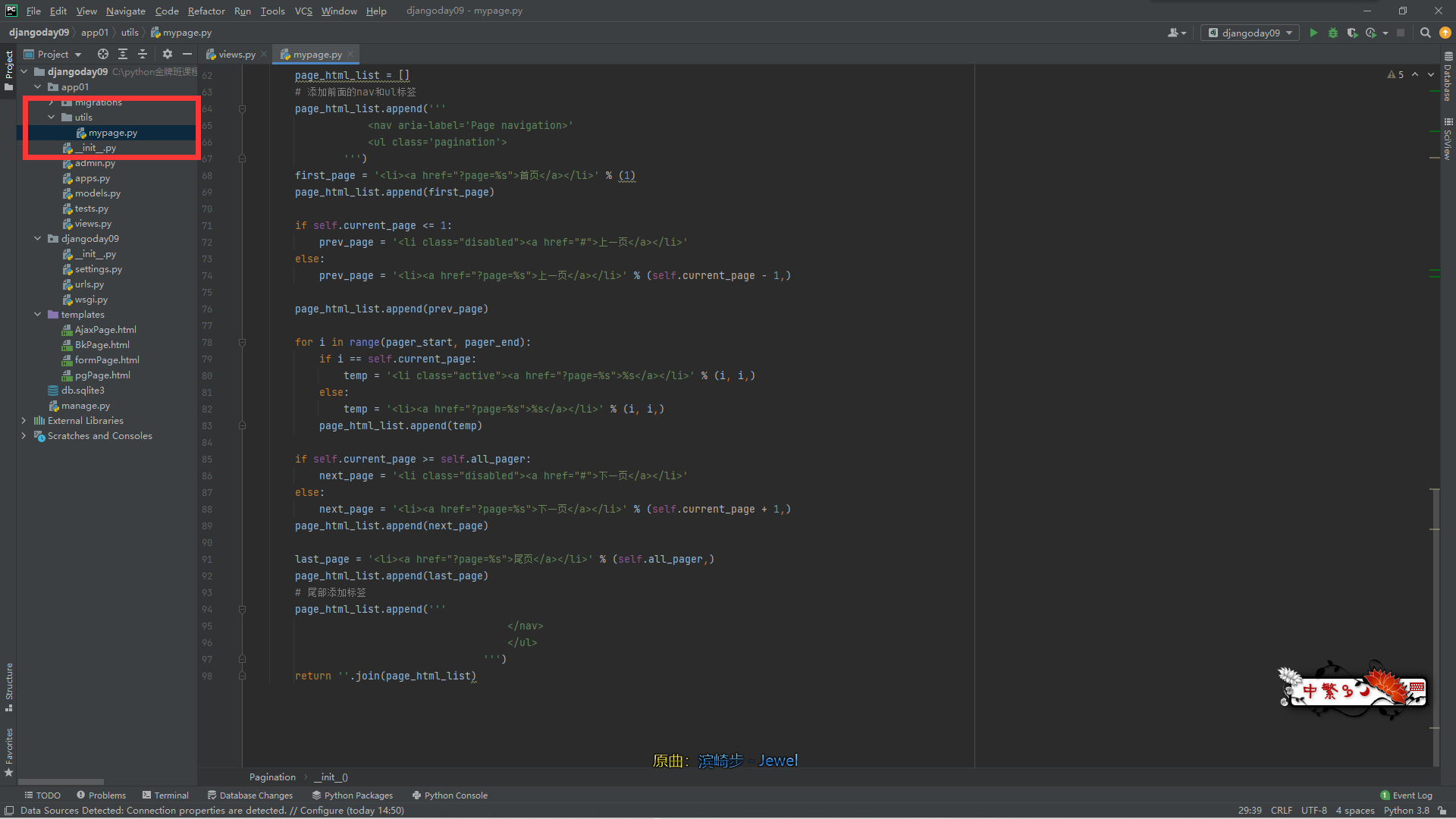
步骤二:复制自定义分页器的代码到我们创建的py文件中
class Pagination(object):
def __init__(self, current_page, all_count, per_page_num=2, pager_count=11):
"""
封装分页相关数据
:param current_page: 当前页
:param all_count: 数据库中的数据总条数
:param per_page_num: 每页显示的数据条数
:param pager_count: 最多显示的页码个数
"""
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
if current_page < 1:
current_page = 1
self.current_page = current_page
self.all_count = all_count
self.per_page_num = per_page_num
# 总页码
all_pager, tmp = divmod(all_count, per_page_num)
if tmp:
all_pager += 1
self.all_pager = all_pager
self.pager_count = pager_count
self.pager_count_half = int((pager_count - 1) / 2)
@property
def start(self):
return (self.current_page - 1) * self.per_page_num
@property
def end(self):
return self.current_page * self.per_page_num
def page_html(self):
# 如果总页码 < 11个:
if self.all_pager <= self.pager_count:
pager_start = 1
pager_end = self.all_pager + 1
# 总页码 > 11
else:
# 当前页如果<=页面上最多显示11/2个页码
if self.current_page <= self.pager_count_half:
pager_start = 1
pager_end = self.pager_count + 1
# 当前页大于5
else:
# 页码翻到最后
if (self.current_page + self.pager_count_half) > self.all_pager:
pager_end = self.all_pager + 1
pager_start = self.all_pager - self.pager_count + 1
else:
pager_start = self.current_page - self.pager_count_half
pager_end = self.current_page + self.pager_count_half + 1
page_html_list = []
# 添加前面的nav和ul标签
page_html_list.append('''
<nav aria-label='Page navigation>'
<ul class='pagination'>
''')
first_page = '<li><a href="?page=%s">首页</a></li>' % (1)
page_html_list.append(first_page)
if self.current_page <= 1:
prev_page = '<li class="disabled"><a href="#">上一页</a></li>'
else:
prev_page = '<li><a href="?page=%s">上一页</a></li>' % (self.current_page - 1,)
page_html_list.append(prev_page)
for i in range(pager_start, pager_end):
if i == self.current_page:
temp = '<li class="active"><a href="?page=%s">%s</a></li>' % (i, i,)
else:
temp = '<li><a href="?page=%s">%s</a></li>' % (i, i,)
page_html_list.append(temp)
if self.current_page >= self.all_pager:
next_page = '<li class="disabled"><a href="#">下一页</a></li>'
else:
next_page = '<li><a href="?page=%s">下一页</a></li>' % (self.current_page + 1,)
page_html_list.append(next_page)
last_page = '<li><a href="?page=%s">尾页</a></li>' % (self.all_pager,)
page_html_list.append(last_page)
# 尾部添加标签
page_html_list.append('''
</nav>
</ul>
''')
return ''.join(page_html_list)
步骤三:自定义分页器的使用
后端代码
每个变量名的含义可以参考源码的注释
封装分页相关数据
:param current_page: 当前页
:param all_count: 数据库中的数据总条数
:param per_page_num: 每页显示的数据条数
:param pager_count: 最多显示的页码个数
def get_book(request):
book_list = models.Book.objects.all()
current_page = request.GET.get("page",1)
all_count = book_list.count()
page_obj = Pagination(current_page=current_page,all_count=all_count,per_page_num=10)
page_queryset = book_list[page_obj.start:page_obj.end]
return render(request,'booklist.html',locals())
前端代码
ps:需要有bootstrap样式
<div class="container">
<div class="row">
<div class="col-md-8 col-md-offset-2">
{% for book in page_queryset %}
<p>{{ book.title }}</p>
{% endfor %}
{{ page_obj.page_html|safe }}
</div>
</div>
</div>
七、form组件
forms组件介绍
我们之前在HTML页面中利用form表单向后端提交数据时,都会写一些获取用户输入的标签并且用form标签把它们包起来.
与此同时我们在好多场景下都需要对用户的输入做校验,比如校验用户是否输入,输入的长度和格式等正不正确... 如果用户输入的内容有错误就需要在页面上相应的位置显示对应的错误信息.
Django form组件就实现了上面所述的功能, forms组件的主要功能如下:
- 自动校验数据
- 自动生成标签
- 自动展示信息
在用到forms组件的之前首先需要定义forms组件, 然后才能使用.
接下来都以用户注册作为示例.
Form定义
要定义Form组件, 需要与模型表一一对应, 下面是模型表的定义
from django import forms
class MyForm(forms.Form):
username = forms.CharField(min_length=3, max_length=8) # username字段最少三个字符最大八个字符
age = forms.IntegerField(min_value=0, max_value=200) # 年龄最小0 最大200
email = forms.EmailField() # 必须符合邮箱格式
校验数据的功能(初识)
小需求:获取用户数据并发送给后端校验 后端返回不符合校验规则的提示信息
这里我们使用测试的方式检验校验数据的功能,因此以下代码都写在测试文件中。
form_obj = views.MyForm({'username':'jason','age':18,'email':'123'})
form_obj.is_valid() # 1.判断数据是否全部符合要求
False # 只要有一个不符合结果都是False
form_obj.cleaned_data # 2.获取符合校验条件的数据
{'username': 'jason', 'age': 18}
form_obj.errors # 3.获取不符合校验规则的数据及原因
{'email': ['Enter a valid email address.']}
1.只校验类中定义好的字段对应的数据 多传的根本不做任何操作(即多传的数据不 校验功能的判断)
2.默认情况下类中定义好的字段都是必填的
八、作业
使用今日内容完善图书管理系统
12月20日内容总结——ajax补充知识点、多对多外键的三种创建方式、django内置序列化组件、批量操作数据、分页器推导思路与自定义分页器的使用、form组件的更多相关文章
- Django-多对多关系的三种创建方式-forms组件使用-cookie与session-08
目录 表模型类多对多关系的三种创建方式 django forms 组件 登录功能手写推理过程 整段代码可以放过来 forms 组件使用 forms 后端定义规则并校验结果 forms 前端渲染标签组件 ...
- 2016年12月20日 星期二 --出埃及记 Exodus 21:15
2016年12月20日 星期二 --出埃及记 Exodus 21:15 "Anyone who attacks his father or his mother must be put to ...
- 北京Uber优步司机奖励政策(12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 天津Uber优步司机奖励政策(12月14日到12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 南京Uber优步司机奖励政策(12月14日到12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 厦门Uber优步司机奖励政策(12月14日到12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 2019年6月14日 Web框架之Django_07 进阶操作(MTV与MVC、多对多表三种创建方式、前后端传输数据编码格式contentType、ajax、自定义分页器)
摘要 MTV与MVC 多对多表三种创建方式 ajax ,前后端传输数据编码格式contentType 批量插入数据和自定义分页器 一.MVC与MTV MVC(Model View Controller ...
- django----多对多三种创建方式 form组件
目录 多对多三种创建方式 全自动 全手动 半自动 form组件 基本使用 form_obj 及 is_valid() 前端渲染方式 取消前端自动校验 正则校验 钩子函数(Hook方法) cleaned ...
- Django学习——ajax发送其他请求、上传文件(ajax和form两种方式)、ajax上传json格式、 Django内置序列化(了解)、分页器的使用
1 ajax发送其他请求 1 写在form表单 submit和button会触发提交 <form action=""> </form> 注释 2 使用inp ...
- Django框架(十)--ORM多对多关联关系三种创建方式、form组件
多对多的三种创建方式 1.全自动(就是平常我们创建表多对多关系的方式) class Book(models.Model): title = models.CharField(max_length=32 ...
随机推荐
- 利用nginx自带的反向代理以及轮询功能实现应用的负载均衡
针对中间件部署的应用(war包),可使用nginx自带的反向代理以及轮询功能,实现应用的负载均衡. 一.架构图 二.环境准备 准备2套环境,如19.1.0.18:7001,19.1.0.16:7001 ...
- Azure Devops Create Project TF400711问题分析解决
前几天,团队使用Azure Devops创建团队项目出了一个奇怪的错误: TF400797: 作业扩展具有一个未处理的错误: Microsoft.TeamFoundation.Framework.Se ...
- @Retryable注解的使用
@Retryable 前言 在实际工作中,重处理是一个非常常见的场景,比如: 发送消息失败. 调用远程服务失败. 争抢锁失败. 这些错误可能是因为网络波动造成的,等待过后重处理就能成功.通常来说,会用 ...
- docker和docker-compose便捷安装
安装docker: curl -fsSL get.docker.com -o get-docker.sh&&sh get-docker.sh 或: curl -sSL https:// ...
- 在Linux配置git
生成ssh ssh-keygen -t rsa 可以不设置密码,一路回车就行,会在 ~/.ssh/下生成两个ssh key: ssh-add ~/.ssh/id_rsa.pub 这一步是使用刚才生成那 ...
- hashlib加密 logging日志 subprocess
Day23 hashlib加密 logging日志 hahlib加密模块 logging日志模块 subprocess模块 1.hahlib加密模块 1.什么是加密? 将明文数据处理成密文数据的过程 ...
- 学习ASP.NET Core Blazor编程系列十五——查询
学习ASP.NET Core Blazor编程系列一--综述 学习ASP.NET Core Blazor编程系列二--第一个Blazor应用程序(上) 学习ASP.NET Core Blazor编程系 ...
- 【每日一题】【DFS/回溯】2022年1月1日-113. 路径总和 II
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径. 叶子节点 是指没有子节点的节点. 来源:力扣(LeetCode)链接 ...
- python爬取网易云音乐评论及相关信息
python爬取网易云音乐评论及相关信息 urllib requests 正则表达式 爬取网易云音乐评论及相关信息 urllib了解 参考链接: https://www.liaoxuefeng.com ...
- python3 利用当前时间、随机数产生一个唯一的数字作为文件名
一.python3 利用当前时间.随机数产生一个唯一的数字作为文件名 代码如下: #-*-coding:utf-8-*- #python3自动生成文件名 from datetime import * ...