通过pdf模板,填充内容,生成pdf文件---JAVA
1 概述
我们通常会遇到需要生成某些固定格式,但是内容不同的文件,那么我们就可以使用⽤Adobe Acrobat DC来创建pdf模块,然后通过代码对模板进行填充,生成pdf文件
2 创建一个pdf模板文件
2.1 先创建一个word创建我们想要的表单
2.2 把word转换成pdf,如下图,创建了这么一个表单,转成了pdf

3 使⽤Adobe Acrobat DC打开PDF⽂件,来创建模板
3.1使用Adobe Acrobat DC打开文件(这个软件自己下载按照)
3.2 点击右边的功能准备表单

3.3 点击上面按钮-添加文本域
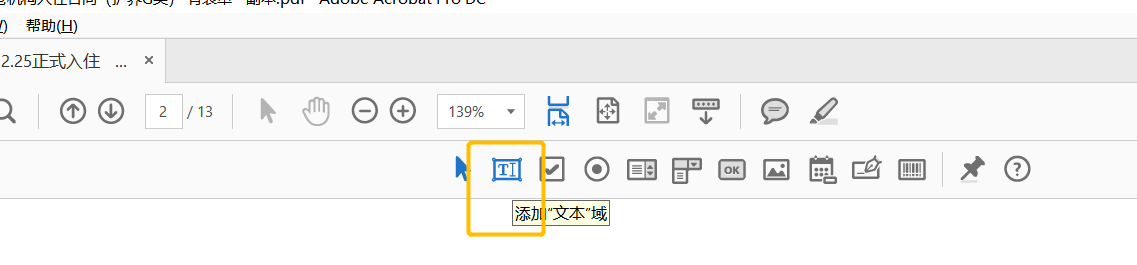
3.4 把文本域放到我们要填充的地方
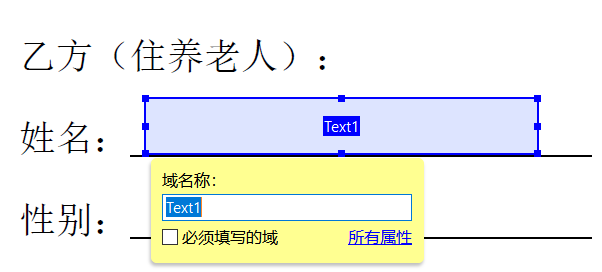
3.5 填写域名称(后面编码就是根据域名称来填入内容的)
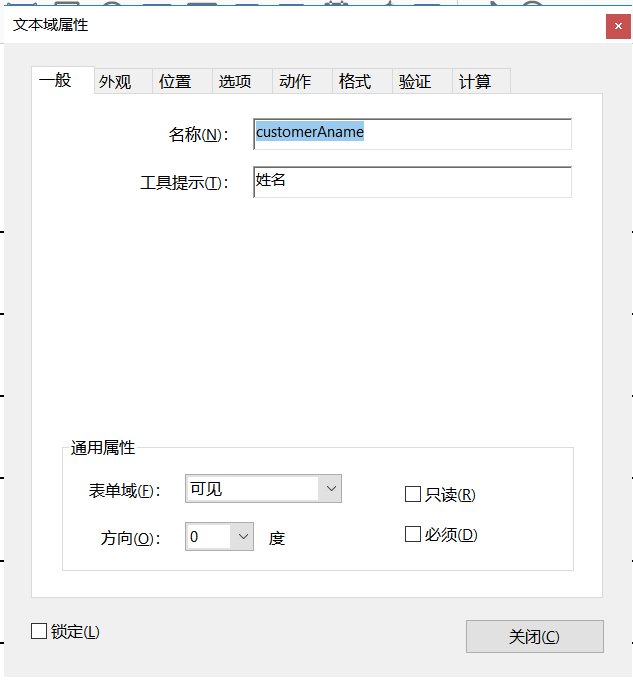
还可以双击这个框框打开设置,设置其他属性
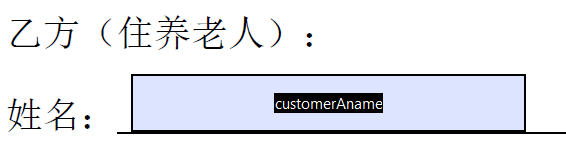
3.6 完成所有的文本域
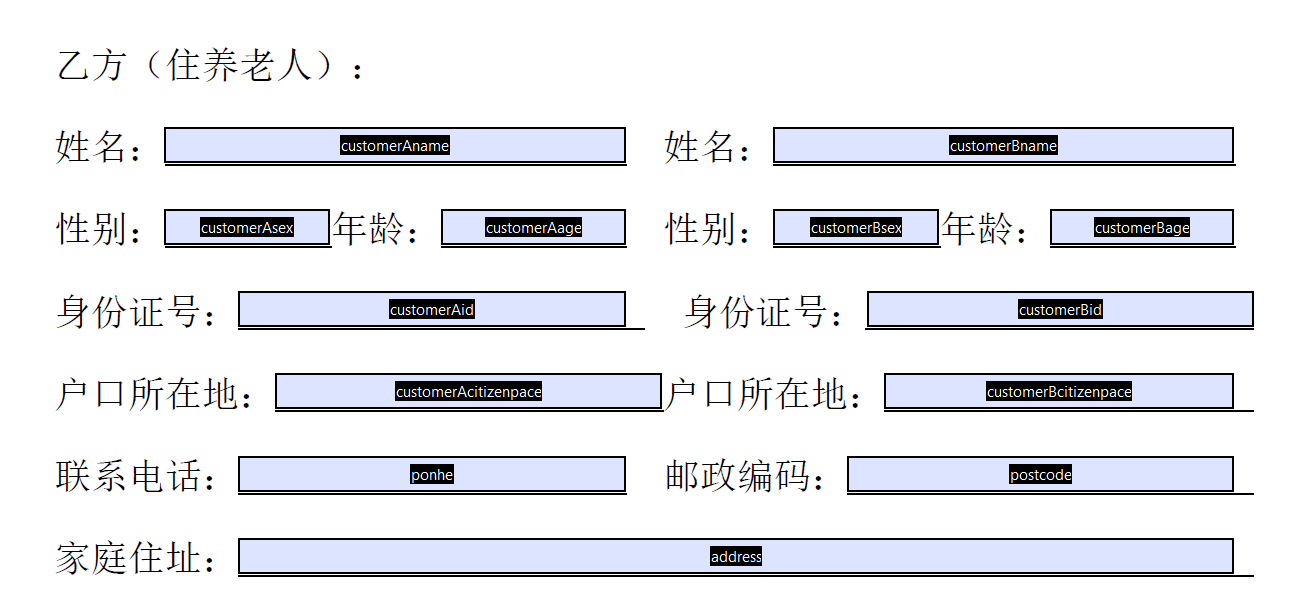
3.7 文件-另存为-保存文件(这个文件就是我们的模板文件了)
4 编码
4.1 pdf-图片工具类
package com.ruoyi.weixin.user.MyTest.Itext; import net.coobird.thumbnailator.Thumbnails;
import net.coobird.thumbnailator.geometry.Positions; import javax.imageio.ImageIO;
import java.io.*; /**
* @Classname ImageThumbUtil
* @Description TODO
* @Date 2022/5/6 0006 下午 4:34
* @Created by jcc
*/
public class ImageThumbUtils {
/**
* 缩略图⽚,图⽚质量为源图的80%
*
* @param originalImgPath 源图⽚存储路径
* @param w 图⽚压缩后的宽度
* @param h 图⽚压缩后的⾼度
* @param targetImgPath 缩略图的存放路径
*/
public static void thumbImage(String originalImgPath, int w, int h, String targetImgPath) throws Exception {
thumbImage(new FileInputStream(originalImgPath), w, h, targetImgPath, 0.8);
} /**
* 缩略图⽚,图⽚质量为源图的80%
*
* @param originalImgData 源图⽚字节数
* @param w 图⽚压缩后的宽度
* @param h 图⽚压缩后的⾼度
* @param targetImgPath 缩略图的存放路径
*/
public static void thumbImage(byte[] originalImgData, int w, int h, String targetImgPath) throws Exception {
thumbImage(new ByteArrayInputStream(originalImgData), w, h, targetImgPath, 0.8);
} /**
* 按⽐例压缩⽂件
*
* @param originalImgData 源⽂件
* @param compressQalitiy 压缩⽐例
* @param targetImgPath ⽬标路径
*/
public static void thumbImage(byte[] originalImgData, double compressQalitiy, String targetImgPath) throws Exception {
Thumbnails.of(new ByteArrayInputStream(originalImgData)).scale(1f).outputQuality(compressQalitiy).toFile(targetImgPath);
} /**
* 按⽐例压缩⽂件
*
* @param originalImgData 源⽂件
* @param compressQalitiy 压缩⽐例
*/
public static OutputStream thumbImage(byte[] originalImgData, double compressQalitiy) throws Exception {
OutputStream os = new ByteArrayOutputStream();
Thumbnails.of(new ByteArrayInputStream(originalImgData)).scale(1f).outputQuality(compressQalitiy).toOutputStream(os);
return os;
} /**
* 按尺⼨⽐例缩略
*
* @param originalInputSteam 源图输⼊流
* @param w 缩略宽
* @param h 缩略⾼
* @param targetImgPath 缩略图存储路径
* @param compressQalitiy 缩略质量⽐例,0~1之间的数
*/
public static void thumbImage(InputStream originalInputSteam, int w, int h, String targetImgPath, double compressQalitiy) throws Exception {
thumbImage(originalInputSteam, w, h, targetImgPath, compressQalitiy, true);
} /**
* @param originalImgInputSteam 源图⽚输⼊流
* @param w 图⽚压缩后的宽度
* @param h 图⽚压缩后的⾼度
* @param targetImgPath 缩略图的存放路径
* @param compressQalitiy 压缩⽐例,0~1之间的double数字
* @param keepAspectRatio 是否保持等⽐例压缩,是true,不是false
*/
public static void thumbImage(InputStream originalImgInputSteam, int w, int h, String targetImgPath, double compressQalitiy,
boolean keepAspectRatio) throws Exception {
Thumbnails.of(originalImgInputSteam).size(w, h).outputQuality(Double.valueOf(compressQalitiy)).keepAspectRatio(true).toFile(targetImgPath);
} /**
* 图⽚裁剪
*
* @param originalImgPath 源图⽚路径
* @param targetImgPath 新图⽚路径
* @param position 位置 0正中间,1中间左边,2中间右边,3底部中间,4底部左边,5底部右边,6顶部中间,7顶部左边,8顶部右边,
* 其他为默认正中间
* @param w 裁剪宽度
* @param h 裁剪⾼度
* @throws Exception
*/
public static void crop(String originalImgPath, int position, int w, int h, String targetImgPath) throws Exception {
Thumbnails.of(originalImgPath).sourceRegion(getPositions(position), w, h).size(w, h).outputQuality(1).toFile(targetImgPath);
} /**
* 给图⽚添加⽔印
*
* @param originalImgPath 将被添加⽔印图⽚ 路径
* @param targetImgPath 含有⽔印的新图⽚路径
* @param watermarkImgPath ⽔印图⽚
* @param position 位置 0正中间,1中间左边,2中间右边,3底部中间,4底部左边,5底部右边,6顶部中间,7顶部左边,8顶部右边,
* 其他为默认正中间
* @param opacity 不透明度,取0~1之间的float数字,0完全透明,1完全不透明
* @throws Exception
*/
public static void watermark(String originalImgPath, String watermarkImgPath, int position, float opacity, String targetImgPath)
throws Exception {
Thumbnails.of(originalImgPath).watermark(getPositions(position), ImageIO.read(new File(watermarkImgPath)), opacity).scale(1.0)
.outputQuality(1).toFile(targetImgPath);
} private static Positions getPositions(int position) {
Positions p = Positions.CENTER;
switch (position) {
case 0: {
p = Positions.CENTER;
break;
}
case 1: {
p = Positions.CENTER_LEFT;
break;
}
case 2: {
p = Positions.CENTER_RIGHT;
break;
}
case 3: {
p = Positions.BOTTOM_CENTER;
break;
}
case 4: {
p = Positions.BOTTOM_LEFT;
break;
}
case 5: {
p = Positions.BOTTOM_RIGHT;
break;
}
case 6: {
p = Positions.TOP_CENTER;
break;
}
case 7: {
p = Positions.TOP_LEFT;
break;
}
case 8: {
p = Positions.TOP_RIGHT;
break;
}
default: {
p = Positions.CENTER;
break;
}
}
return p;
} public static void main(String[] args) throws Exception {
thumbImage("d:/pdf/1.jpg", 600, 600, "d:/pdf/2.jpg");
crop("d:/pdf/1.jpg", 7, 200, 300, "d:/pdf/2.jpg");
watermark("d:/pdf/1.jpg", "d:/pdf/2.jpg", 7, 1, "d:/pdf/3.jpg");
}
}
4.2 根据模板,填充内容,生成pdf文件工具类
/**
* @Classname PdfUtils
* @Description TODO
* @Date 2022/5/6 0006 下午 4:40
* @Created by jcc
*/
import com.itextpdf.text.Document;
import com.itextpdf.text.pdf.*;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.PDFRenderer;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.*;
import java.util.*;
import java.util.List;
/**
* Description: PdfUtils <br>
* 依赖的包:itextpdf itext-asian
* commons-io,commons-codec
* @author mk
* @Date 2018-11-2 14:32 <br>
* @Param
* @return
*/
public class PdfUtils { public static void main(String[] args) throws IOException {
//注意,这里构建map,key和value都要是String
HashMap map = new HashMap<String, String>();
//姓名
map.put("customerAsex", "陈晓");
// 年龄
map.put("customerAage", "13");
// String path = PdfUtils.class.getResource("/template").getPath();
// System.out.println("path:"+path);
// String sourceFile = path + File.separator + "test.pdf";
//模板文件
String sourceFile = "C:\\Users\\Administrator\\Desktop\\muban.pdf";
//生成的pdf文件(自己随便定义)
String targetFile = "C:\\Users\\Administrator\\Desktop\\test_fill.pdf";
genPdf(map,sourceFile,targetFile);
// System.out.println("获取pdf表单中的fieldNames:"+getTemplateFileFieldNames(sourceFile));
// System.out.println("读取⽂件数组:"+fileBuff(sourceFile));
// System.out.println("pdf转图⽚:"+pdf2Img(new File(targetFile),imageFilePath));
} /*
*
* @Description TOOD
* @param map 我们要填充的内容,key是pdf模板文本域的名称,value是要填充内容
* @param sourceFile 模板文件路径
* @param targetFile 生成的pdf文件路径
* @return void
* @date 2022/5/6 0006 下午 5:39
* @author jcc
*/
private static void genPdf(HashMap map, String sourceFile, String targetFile) throws IOException {
File templateFile = new File(sourceFile);
fillParam(map, FileUtils.readFileToByteArray(templateFile), targetFile);
} /**
* Description: 使⽤map中的参数填充pdf,map中的key和pdf表单中的field对应 <br>
* @author mk
* @Date 2018-11-2 15:21 <br>
* @Param
* @return
*/
public static void fillParam(Map<String, String> fieldValueMap, byte[] file, String contractFileName) {
FileOutputStream fos = null;
try {
fos = new FileOutputStream(contractFileName);
PdfReader reader = null;
PdfStamper stamper = null;
BaseFont base = null;
try {
reader = new PdfReader(file);
stamper = new PdfStamper(reader, fos);
stamper.setFormFlattening(true);
base = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);
AcroFields acroFields = stamper.getAcroFields();
for (String key : acroFields.getFields().keySet()) {
acroFields.setFieldProperty(key, "textfont", base, null);
acroFields.setFieldProperty(key, "textsize", new Float(9), null);
}
if (fieldValueMap != null) {
for (String fieldName : fieldValueMap.keySet()) {
acroFields.setField(fieldName, fieldValueMap.get(fieldName));
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (stamper != null) {
try {
stamper.close();
} catch (Exception e) {
e.printStackTrace();
}
}
if (reader != null) {
reader.close();
}
}
} catch (Exception e) {
System.out.println("填充参数异常");
e.printStackTrace();
} finally {
IOUtils.closeQuietly(fos);
}
}
/**
* Description: 获取pdf表单中的fieldNames<br>
* @author mk
* @Date 2018-11-2 15:21 <br>
* @Param
* @return
*/
public static Set<String> getTemplateFileFieldNames(String pdfFileName) {
Set<String> fieldNames = new TreeSet<String>();
PdfReader reader = null;
try {
reader = new PdfReader(pdfFileName);
Set<String> keys = reader.getAcroFields().getFields().keySet();
for (String key : keys) {
int lastIndexOf = key.lastIndexOf(".");
int lastIndexOf2 = key.lastIndexOf("[");
fieldNames.add(key.substring(lastIndexOf != -1 ? lastIndexOf + 1 : 0, lastIndexOf2 != -1 ? lastIndexOf2 : key.length()));
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
reader.close();
}
}
return fieldNames;
}
/**
* Description: 读取⽂件数组<br>
* @author mk
* @Date 2018-11-2 15:21 <br>
* @Param
* @return
*/
public static byte[] fileBuff(String filePath) throws IOException {
File file = new File(filePath);
long fileSize = file.length();
if (fileSize > Integer.MAX_VALUE) {
//System.out.println("file too big...");
return null;
}
FileInputStream fi = new FileInputStream(file);
byte[] file_buff = new byte[(int) fileSize];
int offset = 0;
int numRead = 0;
while (offset < file_buff.length && (numRead = fi.read(file_buff, offset, file_buff.length - offset)) >= 0) {
offset += numRead;
}
// 确保所有数据均被读取
if (offset != file_buff.length) {
throw new IOException("Could not completely read file " + file.getName());
}
fi.close();
return file_buff;
} /**
* Description: 合并pdf <br>
* @author mk
* @Date 2018-11-2 15:21 <br>
* @Param
* @return
*/
public static void mergePdfFiles(String[] files, String savepath) {
Document document = null;
try {
document = new Document(); //默认A4⼤⼩
PdfCopy copy = new PdfCopy(document, new FileOutputStream(savepath));
document.open();
for (int i = 0; i < files.length; i++) {
PdfReader reader = null;
try {
reader = new PdfReader(files[i]);
int n = reader.getNumberOfPages();
for (int j = 1; j <= n; j++) {
document.newPage();
PdfImportedPage page = copy.getImportedPage(reader, j);
copy.addPage(page);
}
} finally {
if (reader != null) {
reader.close();
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//关闭PDF⽂档流,OutputStream⽂件输出流也将在PDF⽂档流关闭⽅法内部关闭
if (document != null) {
document.close();
}
}
}
/**
* pdf转图⽚
* @param file pdf
* @return
*/
public static boolean pdf2Img(File file,String imageFilePath) {
try {
//⽣成图⽚保存
byte[] data = pdfToPic(PDDocument.load(file));
File imageFile = new File(imageFilePath);
ImageThumbUtils.thumbImage(data, 1, imageFilePath); //按⽐例压缩图⽚
System.out.println("pdf转图⽚⽂件地址:" + imageFilePath);
return true;
} catch (Exception e) {
System.out.println("pdf转图⽚异常:");
e.printStackTrace();
}
return false;
}
/**
* pdf转图⽚
* pdf转图⽚
*/
private static byte[] pdfToPic(PDDocument pdDocument) {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
List<BufferedImage> piclist = new ArrayList<BufferedImage>();
try {
PDFRenderer renderer = new PDFRenderer(pdDocument);
for (int i = 0; i < pdDocument.getNumberOfPages(); i++) {//
// 0 表⽰第⼀页,300 表⽰转换 dpi,越⼤转换后越清晰,相对转换速度越慢
BufferedImage image = renderer.renderImageWithDPI(i, 108);
piclist.add(image);
}
// 总⾼度 总宽度 临时的⾼度 , 或保存偏移⾼度 临时的⾼度,主要保存每个⾼度
int height = 0, width = 0, _height = 0, __height = 0,
// 图⽚的数量
picNum = piclist.size();
// 保存每个⽂件的⾼度
int[] heightArray = new int[picNum];
// 保存图⽚流
BufferedImage buffer = null;
// 保存所有的图⽚的RGB
List<int[]> imgRGB = new ArrayList<int[]>();
// 保存⼀张图⽚中的RGB数据
int[] _imgRGB;
for (int i = 0; i < picNum; i++) {
buffer = piclist.get(i);
heightArray[i] = _height = buffer.getHeight();// 图⽚⾼度
if (i == 0) {
// 图⽚宽度
width = buffer.getWidth();
}
// 获取总⾼度
height += _height;
// 从图⽚中读取RGB
_imgRGB = new int[width * _height];
_imgRGB = buffer.getRGB(0, 0, width, _height, _imgRGB, 0, width);
imgRGB.add(_imgRGB);
}
// 设置偏移⾼度为0
_height = 0;
// ⽣成新图⽚
BufferedImage imageResult = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB);
int[] lineRGB = new int[8 * width];
int c = new Color(128, 128, 128).getRGB();
for (int i = 0; i < lineRGB.length; i++) {
lineRGB[i] = c;
}
for (int i = 0; i < picNum; i++) {
__height = heightArray[i];
// 计算偏移⾼度
if (i != 0)
_height += __height;
imageResult.setRGB(0, _height, width, __height, imgRGB.get(i), 0, width); // 写⼊流中
// 模拟页分隔
if (i > 0) {
imageResult.setRGB(0, _height + 2, width, 8, lineRGB, 0, width);
}
}
// 写流
ImageIO.write(imageResult, "jpg", baos);
} catch (Exception e) {
System.out.println("pdf转图⽚异常:");
e.printStackTrace();
} finally {
IOUtils.closeQuietly(baos);
try {
pdDocument.close();
} catch (Exception ignore) {
}
}
return baos.toByteArray();
}
}
4.3 测试结果
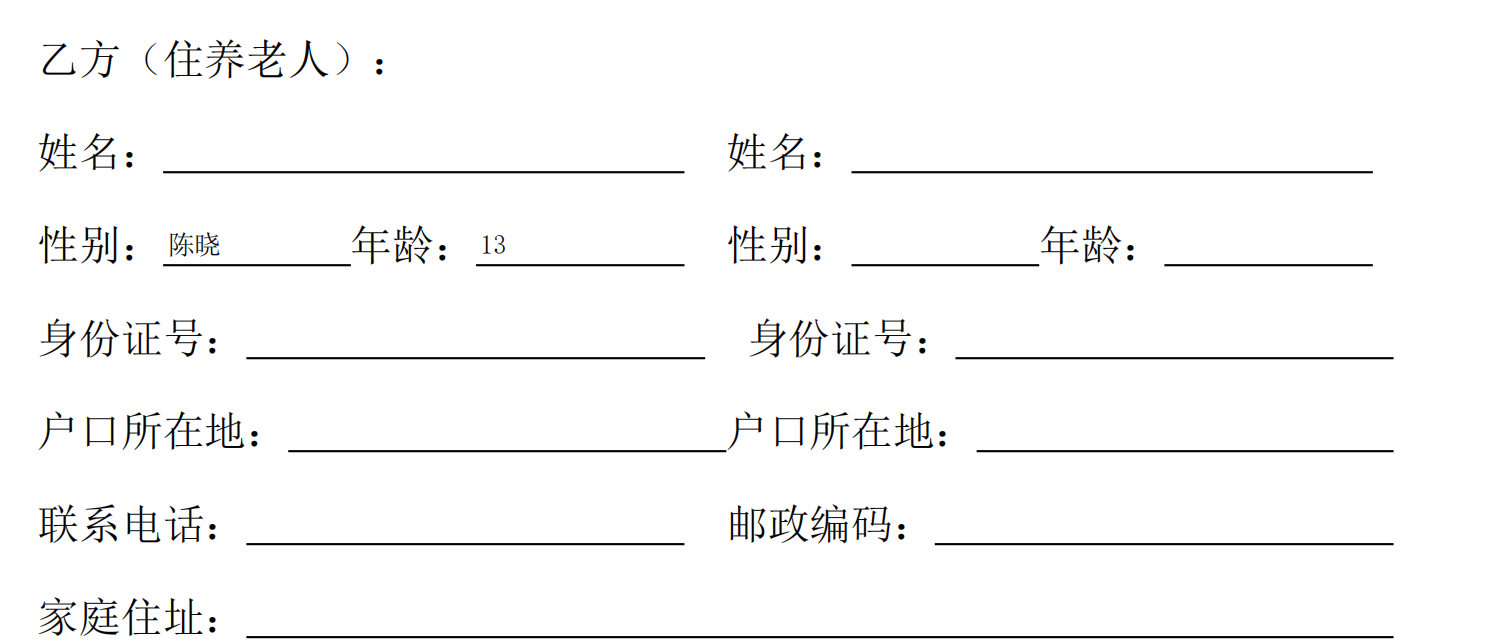
测试代码中,只填了customerAname和customerAage到map中,所以这里只填入了左边的姓名和年龄
通过pdf模板,填充内容,生成pdf文件---JAVA的更多相关文章
- 根据现有PDF模板填充信息(SpringBoot)
根据现有PDF模板填充信息(SpringBoot+maven) 首先得有一个pdf模板,建立pdf模板需要下载工具 红色框为文本框,filename为域名.java需要根据域名赋值 pom 文件配置 ...
- java根据模板HTML动态生成PDF
原文:https://segmentfault.com/a/1190000009160184 一.需求说明:根据业务需要,需要在服务器端生成可动态配置的PDF文档,方便数据可视化查看. 二.解决方案: ...
- 将html中的内容生成PDF并且下载
<head> @*需要引用的js库*@ <script src="https://cdnjs.cloudflare.com/ajax/libs/html2canvas/0. ...
- 使用Themleaf 模板引擎手动生成html文件
1.为什么要写这一篇呢? 在做一个邮件发送功能的时候,需要发送html邮件,javaMail 发送html 的时候需要有已经生成的html正文,所以需要提前将要发送的内容生成,所以就需要模板引擎来动态 ...
- [Web Pdf] flying-saucer + iText + Freemarker生成pdf 跨页问题
转载于: https://blog.csdn.net/qq_31980421/article/details/79662988 flying-saucer + iText + Freemarker实 ...
- 把内容生成txt文件
StringBuilder MailLog = new StringBuilder(); string logPath = txtFile + str + DateTime.No ...
- 根据PDF模板生成PDF文件(基于iTextSharp)
根据PDF模板生成PDF文件,这里主要借助iTextSharp工具来完成.场景是这样的,假如要做一个电子协议,用过通过在线填写表单数据,然后系统根据用户填写的数据,生成电子档的协议.原理很简单,但是每 ...
- java之数据填充PDF模板
声明:由于业务场景需要,所以根据一个网友的完成的. 1.既然要使用PDF模板填充,那么就需要制作PDF模板,可以使用Adobe Acrobat DC,下载地址:https://carrot.ctfil ...
- PDF模板报表导出(Java+Acrobat+itext)
1. 首先要安装Adobe Acrobat,装好之后用Acrobat从一个word,excel或者pdf中转换一个pdf模板,我做的模板很简单,直接写一个简单的word再生成一个pdf表单,之后编辑文 ...
- Spring Boot集成JasperReports生成PDF文档
由于工作需要,要实现后端根据模板动态填充数据生成PDF文档,通过技术选型,使用Ireport5.6来设计模板,结合JasperReports5.6工具库来调用渲染生成PDF文档.本人文采欠缺,写作能力 ...
随机推荐
- C#怎么在生成解决方案的过程中执行perl脚本(C#早期绑定)
转载 怎么在生成解决方案的过程中执行perl脚本 早期绑定在编译期间识别并检查方法.属性.函数,并在应用程序执行之前执行其他优化.在这个绑定中,编译器已经知道它是什么类型的对象以及它拥有的方法或属性. ...
- .NET周报【11月第2期 2022-11-15】
国内文章 统一的开发平台.NET 7正式发布 https://www.cnblogs.com/shanyou/archive/2022/11/09/16871945.html 在 2020 年规划的. ...
- CodeQL(1)
前言 开始学习使用CodeQL,做一些笔记,可供参考的资料还是比较少的,一个是官方文档,但是Google翻译过来,总觉得怪怪的,另一个就是别人的一个资源整合,其中可供参考的也不是很多,大多也是官方文档 ...
- 安装BurpSuite (专业版)
BurpSuite简介: Burp Suite 是用于攻击web 应用程序的集成平台.它包含了许多工具,并为这些工具设计了许多接口,以促进加快攻击应用程序的过程.所有的工具都共享一个能处理并显示HTT ...
- 《MySQL必知必会》知识汇总一
一.使用MYSQL 展示所有数据库 show databases; 选择数据库 use crashcourse; 展示该数据库中所有的表 show tables; 还可以展示表列的shema约束 sh ...
- C++四舍五入并且保留7为小数
问题描述给定圆的半径r,求圆的面积.输入格式输入包含一个整数r,表示圆的半径.输出格式输出一行,包含一个实数,四舍五入保留小数点后7位,表示圆的面积.说明:在本题中,输入是一个整数,但是输出是一个实数 ...
- 一篇文章教你实战Docker容器数据卷
在上一篇中,咱们对Docker中的容器数据卷做了介绍.已经知道了容器数据卷是什么?能干什么用.那么本篇咱们就来实战容器数据卷,Docker容器数据卷案例主要做以下三个案例 1:宿主机(也就是Docke ...
- windows GO语言环境配置
目录 GO语言下载 安装goland go目录简介 配置gopath goland里添加goroot和gopath GO语言下载 参考教程:https://www.cnblogs.com/Domini ...
- 从零入门项目集成Karate和Jacoco,配置测试代码覆盖率
解决问题 在SpringBoot项目中,如何集成Karate测试框架和Jacoco插件.以及编写了feature测试文件,怎么样配置才能看到被测试接口代码的覆盖率. 演示版本及说明 本次讲解,基于Sp ...
- MySQL字符编码、存储引擎、严格模式、字段类型之浮点 字符串 枚举与集合 日期类型
目录 字符编码与配置文件 数据路储存引擎 创建表的完整语法 字段类型之整型 严格模式 字段类型之浮点型 字段类型之字符串类型 数字的含义 字段类型之枚举与集合 字段类型之日期类型 字符编码与配置文件 ...