Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning
有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过程。 只要模型被确定,就可以应用到新的未知的数据上。
进一步可以分为 分类 classification 任务 和 回归 regression 任务。
分类任务: 标签是离散值。
回归任务: 标签是连续值。无监督学习: 指对不带任何标签的数据特征进行建模。 让数据自己介绍自己。 包括 聚类 clustering 任务 和 降维 dimensionality reduction 任务。
聚类算法: 将数据分成不同组。
降维算法:追求用更简洁的方式表现数据。半监督 学习 semi-supervised learning 。介于有监督学习和无监督学习之间, 在数据标签不完整时使用。
Scikit-Learn 简介
Scikit-Learn 的 数据表示 data representation
机器学习是从数据创建模型的学问。 因此你首先需要了解咋样表示数据才能让计算机理解。 Scikit-Learn认为 是数据表。
数据表
鸢尾花 数据集
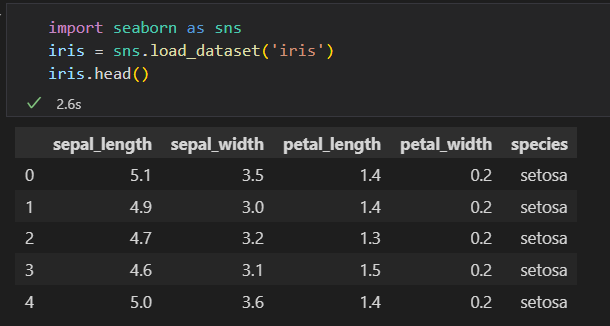
矩阵的行 称为 样本 samples. 行数记为 n_samples
每列数据表示每个样本 某个特征的量化值 。 矩阵的列 称为 特征 features 列数记为 n_features
特征矩阵。 features matrix
通过二维数据或举证的形式将信息清晰地表达出来。
间记为:X ,维度为 【n_samples, n_features】的 二维矩阵。一般用NumPy数组或Pandas 的DataFrame来表示。目标数据
需要一个标签 或 目标数组,通常 简记为 y
目标数组 一般是 一维数组。 长度就是样本总数 n_samples.
对数据进行可视化
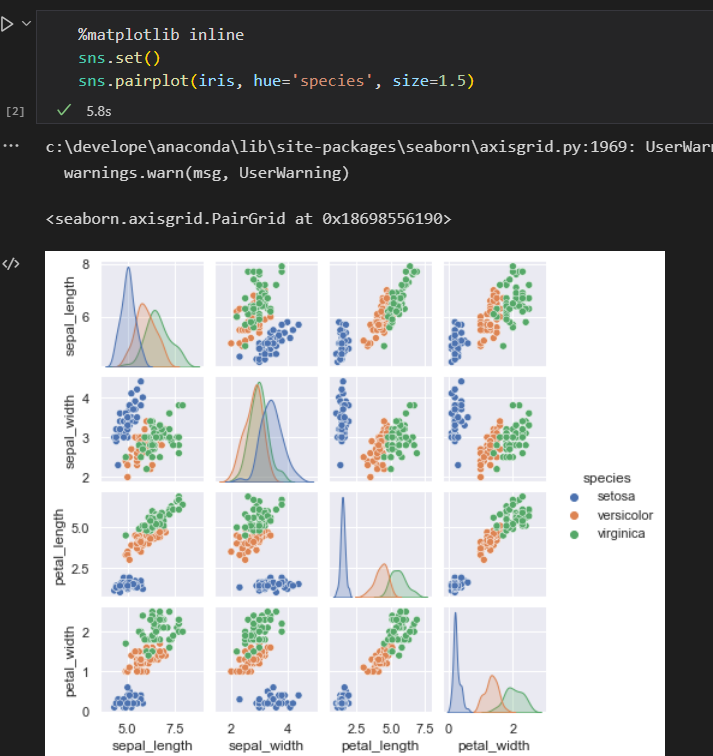
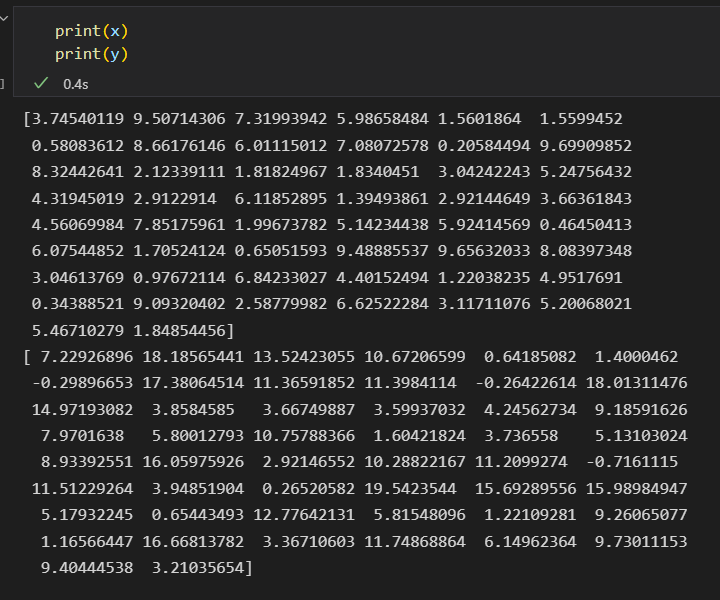
- 抽取特征矩阵 和目标数组
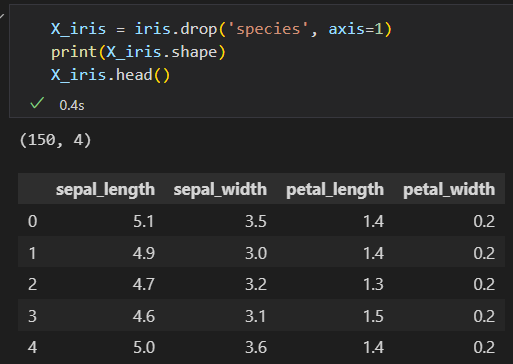
特征矩阵如下
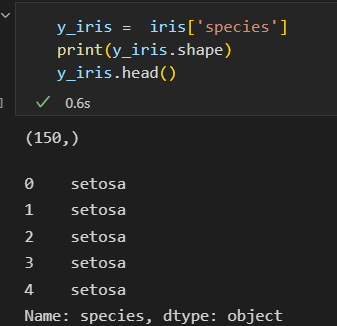
目标数组如下
Scikit-Learn 的评估器API
设计原则:
- 统一性
所有对象使用共同接口连接一组方法和统一文档 - 内省
所有参数值都是公共属性 - 限制对象层级
只有算法可以用python类表示。数据集都用标准数据类型 Numpy数组 DataFrame Scipy稀疏矩阵表示。 参数名称 用标准的Python字符串。 - 函数组合
- 明智的默认值
API基础知识
常用步骤如下
1)从Scikit-Learn 导入适当的评估器类, 选择模型类。
2)用合适 的数值对模型类 进行实例化,配置模型超参数 hyperparameter
3) 整理数据,获取 特征矩阵和 目标数组。
4) 调用模型实例 的fit()方法对数据进行 拟合
5)对新数据应用模型。
- 有监督学习模型中: 通常使用predict()方法预测新数据的标签
- 无监督学习模型中: 通常使用transform() 或 predict() 方法转换 或 推断数据的性质
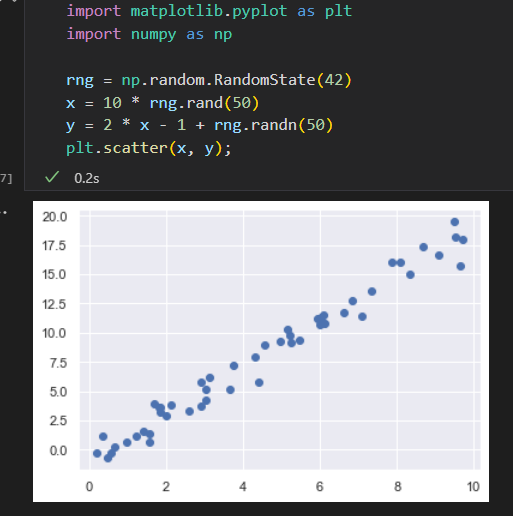
有监督学习实例:简单线性回归。
1)选择模型类
每个模型类都是一个Python类。 简单的线性回归模型。 直接导入 线性回归模型类
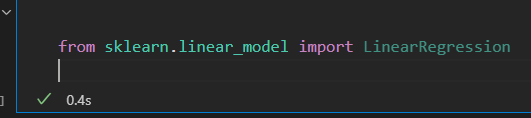
2)选择模型超参数
选择了模型之后,需要配置参数。
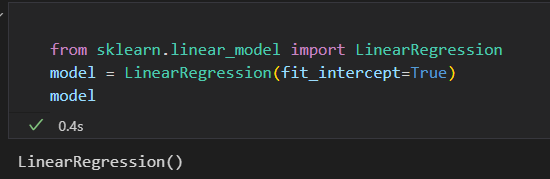
3)将数据整理成特征矩阵 和 目标数组
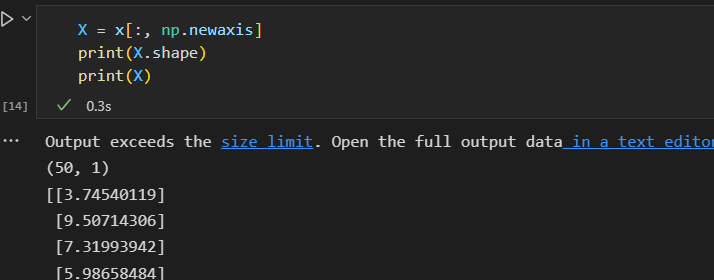
4)用模型拟合数据
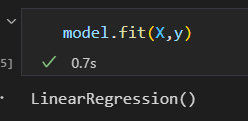
fit()方法获取的 模型参数都带一条下划线。
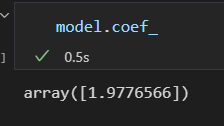
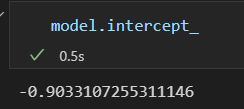
这俩个参数分别表示 对 样本数据 拟合直线的 斜率 和 截距 。
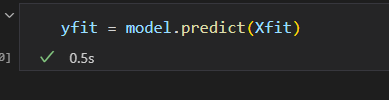
5)预测新数据的标签
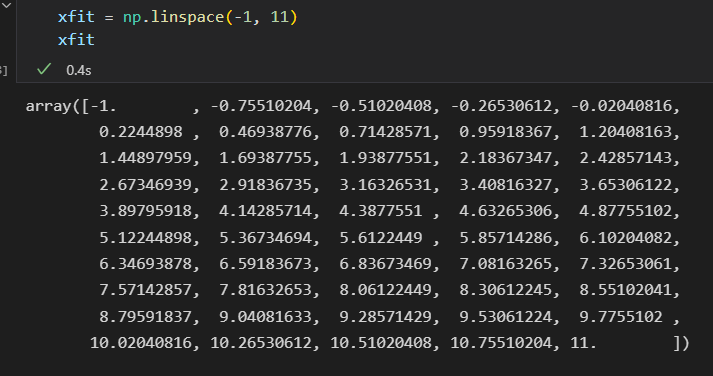
预测
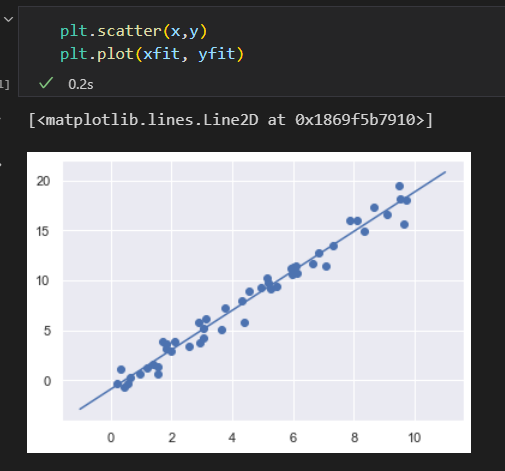
原始数据 和 拟合记过可视化
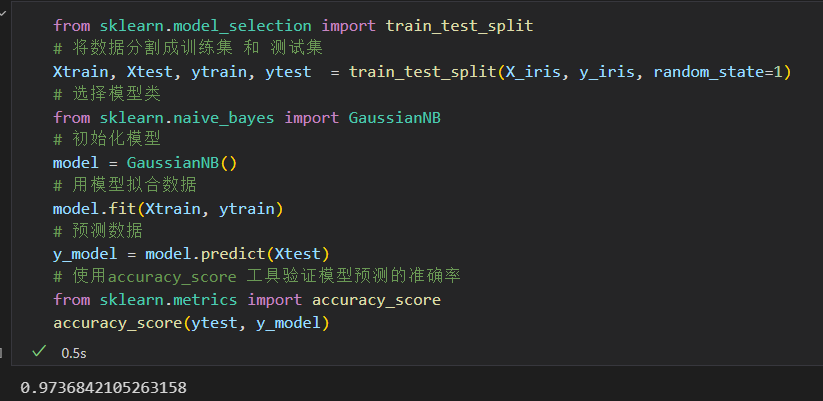
有监督学习示例:鸢尾花数据分类
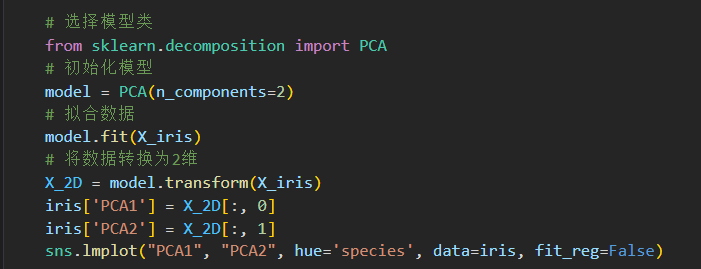
无监督学习示例:鸢尾花数据降维
对鸢尾花数据进行降维,以便更方便的对数据进行可视化,
降维的任务是要找到一个可以保留数据本质特征的 低维 矩阵来表示高维 数据。
使用 主成分 分析方法 PCA principal component analysis . 是一个快速线性降维技术。
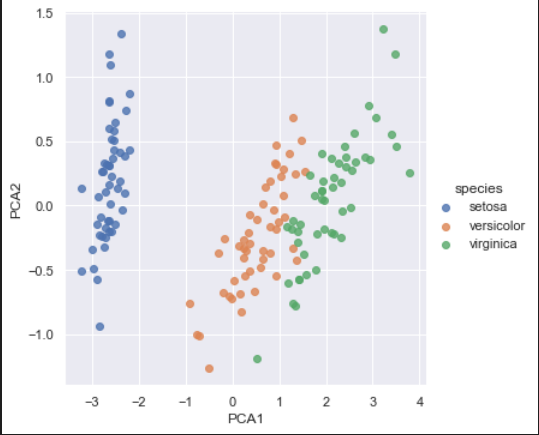
用模型返回俩个主成分。 用二维数据表示 鸢尾花的思维数据。
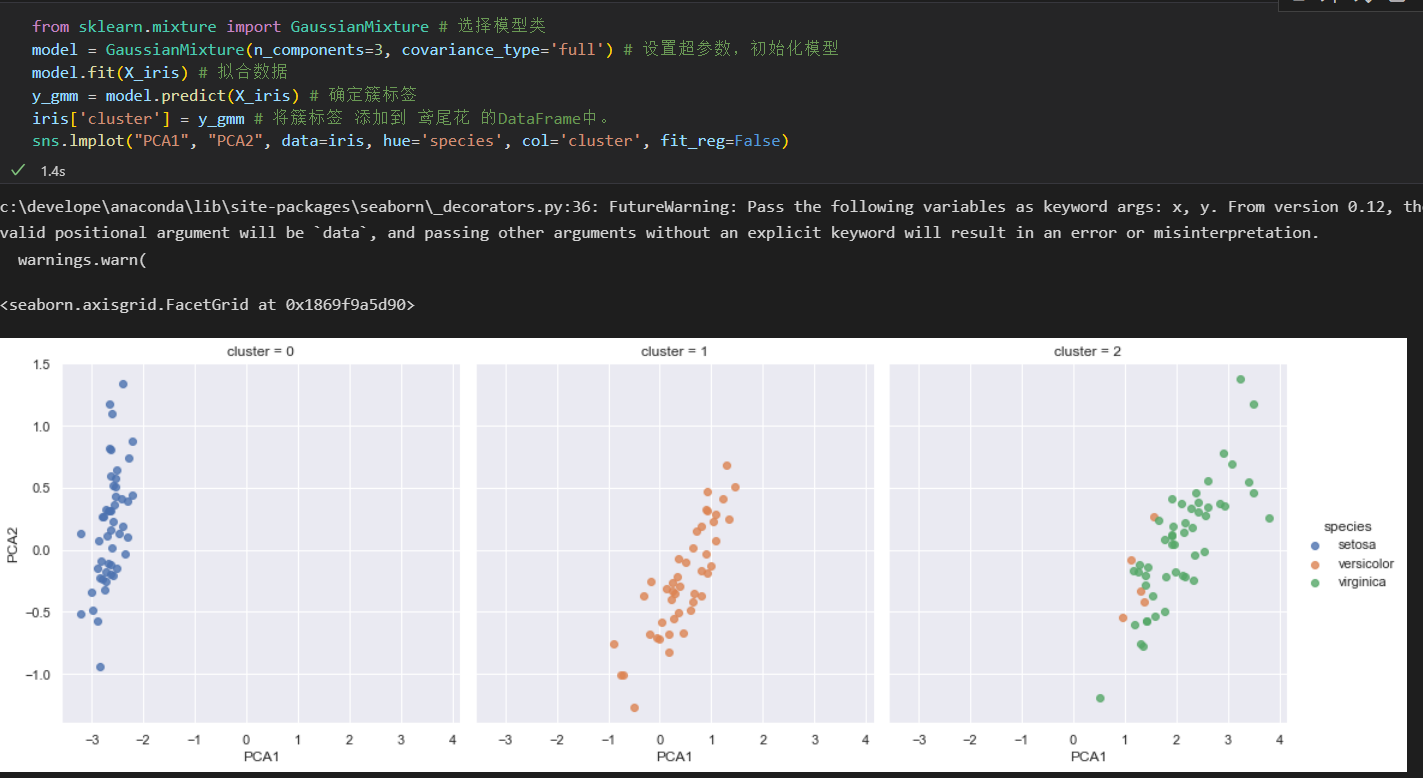
无监督学习示例: 鸢尾花数据聚类
聚类算法是要对没有任何标签的数据集 进行分组。
使用一个强大的聚类方法-高斯混合模型 Gaussian mixture model GMM
GMM 模型 试图将数据构造成若干服从高斯分布的概率密度函数簇。
手写数字探索。
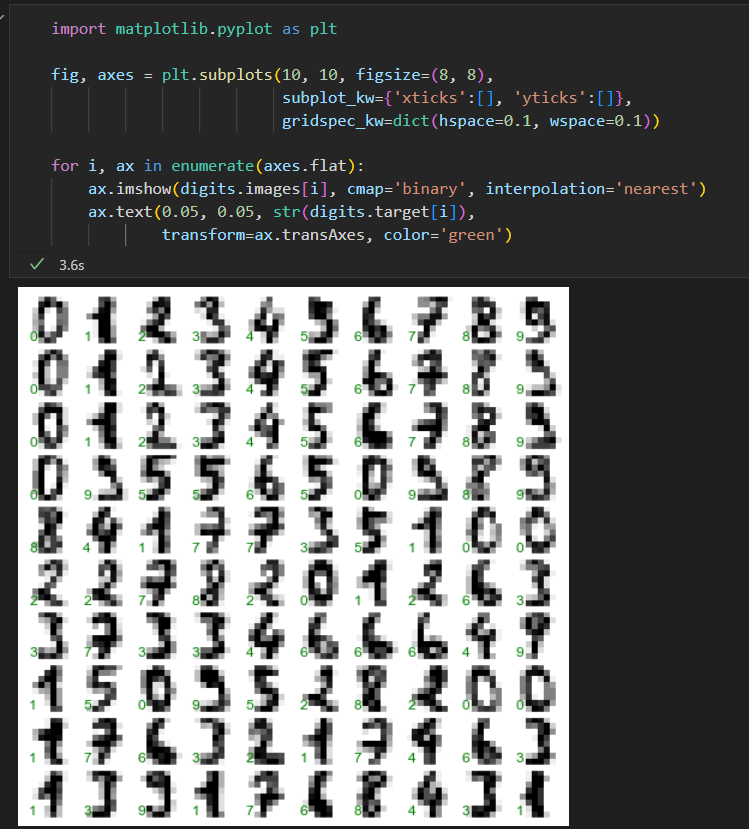
加载并可视化手写数字
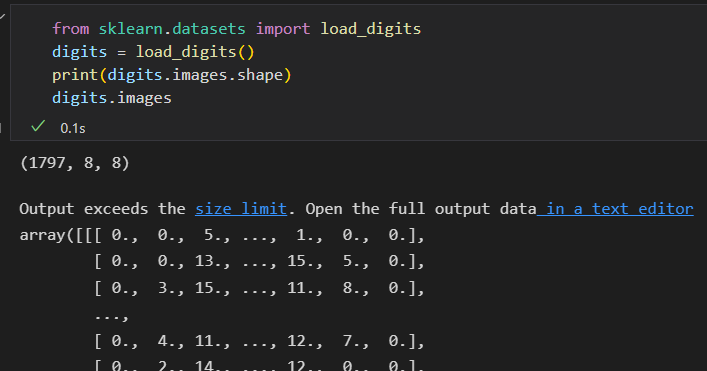
每张图像是 8 * 8 像素
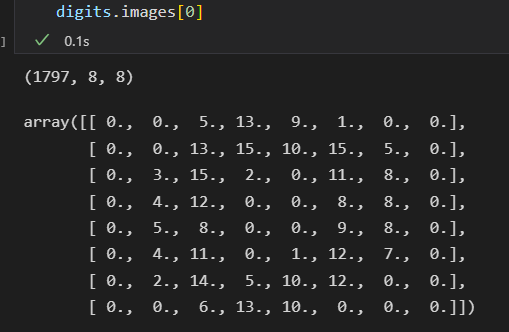
前一百张图可视化
为了在Scikit-Learn中使用数据,需要一个维度为【n_samples, n_features】的二维特征居住证。 可以将每个样本独享的所有像素作为特征。 8*8 = 64 个特征。 平铺成长度为64 的 一维数组。
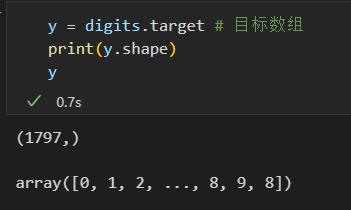
目标数组:表示每个数字的真实值。

无监督学习:降维
对64维参数进行可视化十分困难。 需要建筑 无监督学习方法将维度 降到 二维。
使用流形学习算法中的 lsomap 对数据进行降维
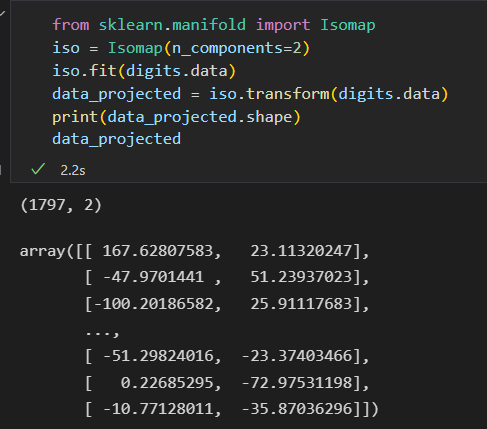
可视化
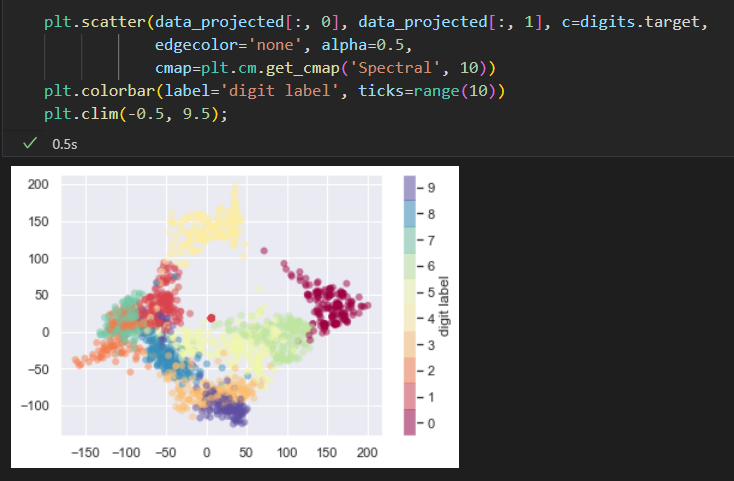
数字分类
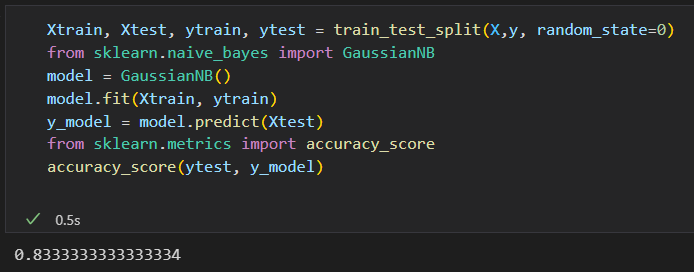
找到一个分类算法,对手写数字进行分类。
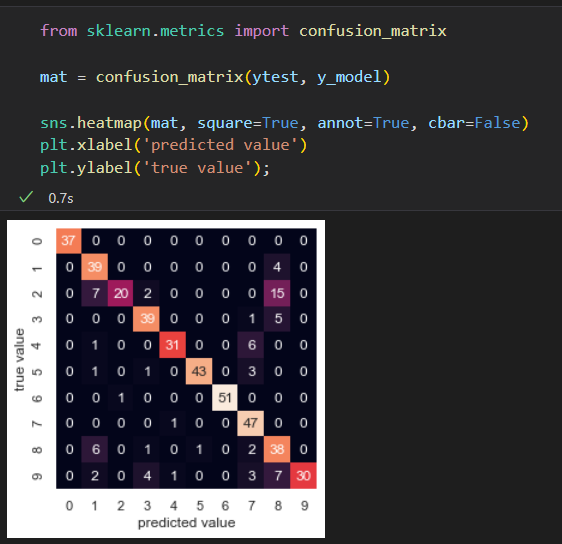
使用混淆矩阵 看哪里做的不好
Python数据科学手册-机器学习介绍的更多相关文章
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习: 支持向量机
support vector machine SVM 是非常强大. 灵活的有监督学习算法, 可以用于分类和回归. 贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签.是属于 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
随机推荐
- PHP生成图形验证码
在建站过程中,很多时候都会需要用户验证验证码等操作,比如:注册.登录.发表评论.获取资源等等,一方面可以验证当前用户的行为是否是爬虫.机器人等情况,给网站数据统计产生影响:另一方面可以防止用户大量刷取 ...
- 基于UniApp社区论坛多端开发实战
什么是移动端WebApp 移动端WebApp: 泛指手持设备移动端的web 特点: - 类App 应用,运行环境是浏览器 - 可以包一层壳,成为App - 常见的混合应用: ionic, Cordov ...
- Tapdata 与阿里云 PolarDB 开源数据库社区联合共建开放数据技术生态
近日,阿里云 PolarDB 开源数据库社区宣布将与 Tapdata 联合共建开放数据技术生态.在此之际,一直专注实时数据服务平台的 Tapdata ,也宣布开源其数据源开发框架--PDK(Plu ...
- Tapdata “设擂招贤”携手 LeetCode 举办全球极客技术竞赛
2021年11月28日 Tapdata 专场全球极客技术竞赛将在 LeetCode 平台开赛,面向程序员"设擂招贤",打擂成功的前50名挑战者将优先获得 Tapdata 高端技 ...
- MySQL--SELECT检索语句
1.检索单个列 SELECT prod_name FROM products; --上述语句利用 SELECT语句从 products表中检索一个名为prod_name的列. 结束SQL:多条SQL语 ...
- CMU15445 (Fall 2019) 之 Project#4 - Logging & Recovery 详解
前言 这是 Fall 2019 的最后一个实验,要求我们实现预写式日志.系统恢复和存档点功能,这三个功能分别对应三个类 LogManager.LogRecovery 和 CheckpointManag ...
- DelayQueue达到定时触发效果
DelayQueue的特点就是插入Queue中的数据可以按照自定义的delay时间进行排序.只有delay时间小于0的元素才能够被取出. 这样子,只要开启一个线程循环从DelayQueue中取值执行, ...
- ShardingSphere数据分片
码农在囧途 坚持是一件比较难的事,坚持并不是自欺欺人的一种自我麻痹和安慰,也不是做给被人的,我觉得,坚持的本质并没有带着过多的功利主义,如果满是功利主义,那么这个坚持并不会长久,也不会有好的收获,坚持 ...
- Collection集合和Collection的常用功能
boolean add(E e); 向集合里添加元素 boolean remove(E e); 删除集合中的某个元素 void clear(); 清空集合的所有元素 boolean contains( ...
- Thingsboard硬网关金鸽BL102采集三菱PLC步骤
PLC网关金鸽BL102:采集三菱FX-5U数据如何转成MQTT上报?金鸽BL102PLC网关时一款功能强大的PLC数据采集网关,南向可以采集主流的PLC,如三菱.西门子.台达.欧姆龙.施耐德等等PL ...