ShardingSphere-proxy-5.0.0建立mysql读写分离的连接(六)
一、修改配置文件config-sharding.yaml,并重启服务
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ######################################################################################################
#
# Here you can configure the rules for the proxy.
# This example is configuration of sharding rule.
#
######################################################################################################
#
#schemaName: sharding_db
#
#dataSources:
# ds_0:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_0
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# minPoolSize: 1
# ds_1:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_1
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# minPoolSize: 1
#
#rules:
#- !SHARDING
# tables:
# t_order:
# actualDataNodes: ds_${0..1}.t_order_${0..1}
# tableStrategy:
# standard:
# shardingColumn: order_id
# shardingAlgorithmName: t_order_inline
# keyGenerateStrategy:
# column: order_id
# keyGeneratorName: snowflake
# t_order_item:
# actualDataNodes: ds_${0..1}.t_order_item_${0..1}
# tableStrategy:
# standard:
# shardingColumn: order_id
# shardingAlgorithmName: t_order_item_inline
# keyGenerateStrategy:
# column: order_item_id
# keyGeneratorName: snowflake
# bindingTables:
# - t_order,t_order_item
# defaultDatabaseStrategy:
# standard:
# shardingColumn: user_id
# shardingAlgorithmName: database_inline
# defaultTableStrategy:
# none:
#
# shardingAlgorithms:
# database_inline:
# type: INLINE
# props:
# algorithm-expression: ds_${user_id % 2}
# t_order_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_${order_id % 2}
# t_order_item_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_item_${order_id % 2}
#
# keyGenerators:
# snowflake:
# type: SNOWFLAKE
# props:
# worker-id: 123 ######################################################################################################
#
# If you want to connect to MySQL, you should manually copy MySQL driver to lib directory.
#
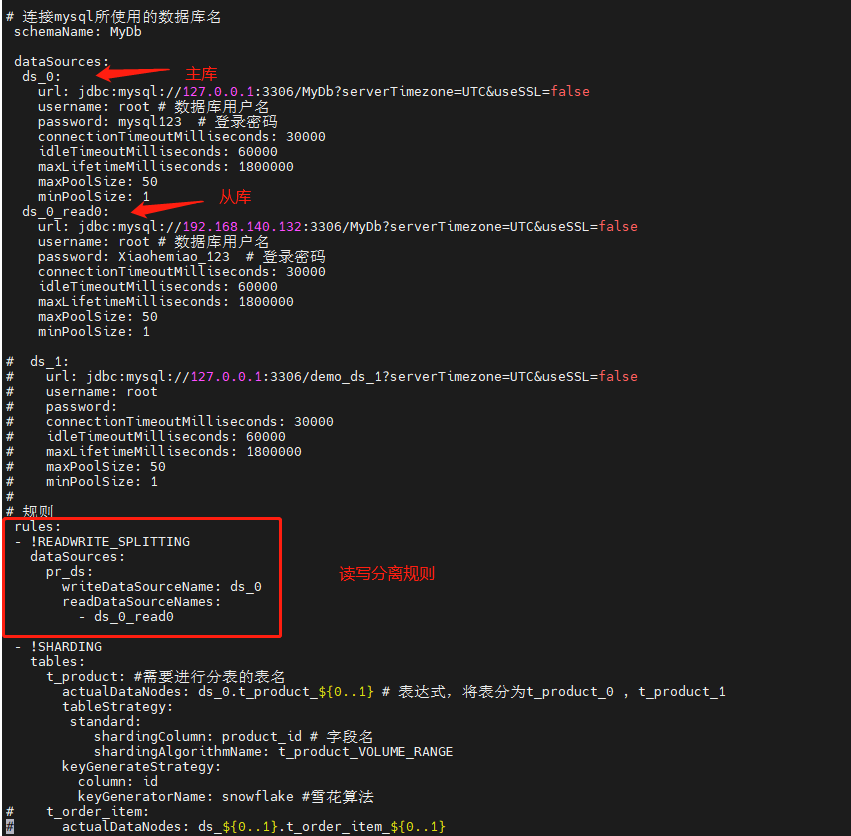
###################################################################################################### # 连接mysql所使用的数据库名
schemaName: MyDb dataSources:
ds_0: # 主库
url: jdbc:mysql://127.0.0.1:3306/MyDb?serverTimezone=UTC&useSSL=false
username: root # 数据库用户名
password: mysql123 # 登录密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_0_read0: # 从库
url: jdbc:mysql://192.168.140.132:3306/MyDb?serverTimezone=UTC&useSSL=false
username: root # 数据库用户名
password: Xiaohemiao_123 # 登录密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1 # ds_1:
# url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
# username: root
# password:
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# minPoolSize: 1
#
# 规则
rules:
- !READWRITE_SPLITTING #读写分离规则
dataSources:
pr_ds:
writeDataSourceName: ds_0
readDataSourceNames:
- ds_0_read0 - !SHARDING
tables:
t_product: #需要进行分表的表名
actualDataNodes: ds_0.t_product_${0..1} # 表达式,将表分为t_product_0 , t_product_1
tableStrategy:
standard:
shardingColumn: product_id # 字段名
shardingAlgorithmName: t_product_VOLUME_RANGE
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake #雪花算法
# t_order_item:
# actualDataNodes: ds_${0..1}.t_order_item_${0..1}
# tableStrategy:
# standard:
# shardingColumn: order_id
# shardingAlgorithmName: t_order_item_inline
# keyGenerateStrategy:
# column: order_item_id
# keyGeneratorName: snowflake
# bindingTables:
# - t_order,t_order_item
# defaultDatabaseStrategy:
# standard:
# shardingColumn: user_id
# shardingAlgorithmName: database_inline
# defaultTableStrategy:
# none:
#
shardingAlgorithms:
t_product_VOLUME_RANGE: # 取模名称,可自定义
type: VOLUME_RANGE # 取模算法
props:
range-lower: '5' # 最小容量为5条数据,仅方便测试
range-upper: '10' #最大容量为10条数据,仅方便测试
sharding-volume: '5' #分片的区间的数据的间隔
# t_order_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_${order_id % 2}
# t_order_item_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_item_${order_id % 2}
#
keyGenerators:
snowflake: # 雪花算法名称,自定义名称
type: SNOWFLAKE
props:
worker-id: 123
上述配置是同时有做容量范围分片
二、数据准备
在中间件中ShardingSphere中创建MyDb数据库,并创建相关表和插入数据
-- 创建表
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0; -- ----------------------------
-- Table structure for t_product
-- ----------------------------
DROP TABLE IF EXISTS `t_product`;
CREATE TABLE `t_product` (
`id` varchar(225) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`product_id` int(11) NOT NULL,
`product_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
PRIMARY KEY (`id`, `product_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1; -- 插入表数据
INSERT INTO t_product(product_id,product_name) VALUES(1,'one');
INSERT INTO t_product(product_id,product_name) VALUES(2,'two');
INSERT INTO t_product(product_id,product_name) VALUES(3,'three');
INSERT INTO t_product(product_id,product_name) VALUES(4,'four');
INSERT INTO t_product(product_id,product_name) VALUES(5,'five');
INSERT INTO t_product(product_id,product_name) VALUES(6,'six');
INSERT INTO t_product(product_id,product_name) VALUES(7,'seven');
三、查看数据

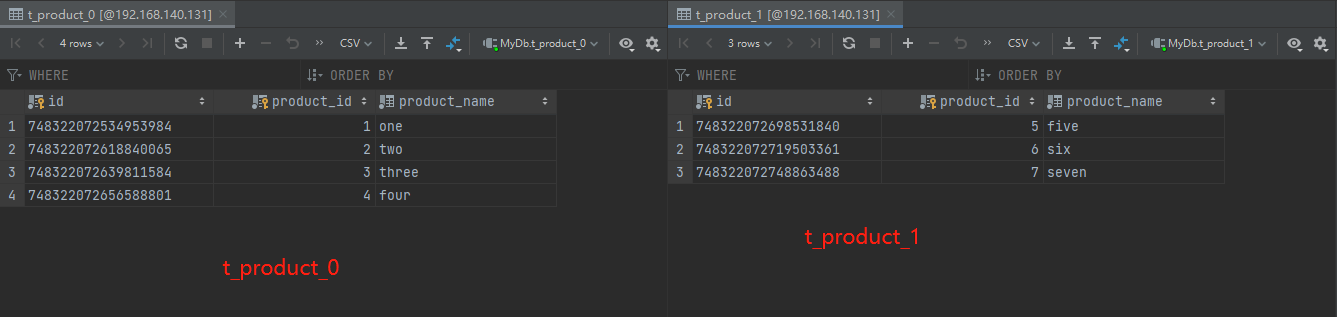
1、查看shardingsphere中间件t_product表数据

2、主库192.168.140.131数据
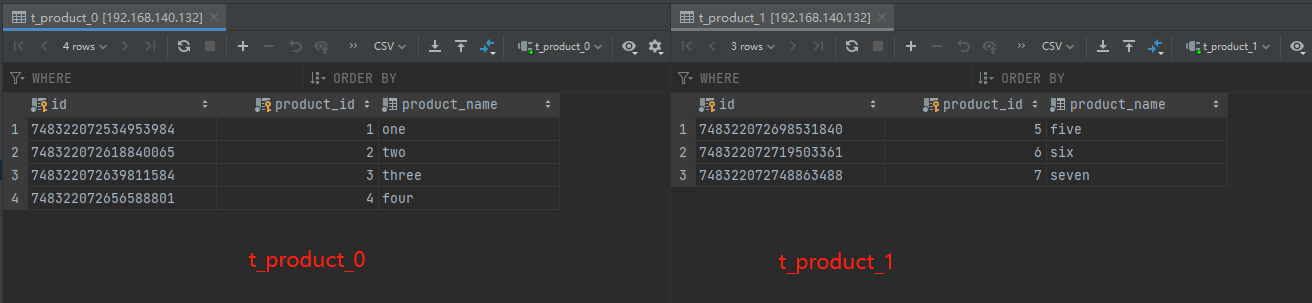
3、主库192.168.140.132数据
ShardingSphere-proxy-5.0.0建立mysql读写分离的连接(六)的更多相关文章
- Mysql读写分离-Amoeba Proxy
参考:http://www.linuxidc.com/Linux/2015-10/124115.htm 一个完整的MySQL读写分离环境包括以下几个部分: 应用程序client database pr ...
- MySQL读写分离技术
1.简介 当今MySQL使用相当广泛,随着用户的增多以及数据量的增大,高并发随之而来.然而我们有很多办法可以缓解数据库的压力.分布式数据库.负载均衡.读写分离.增加缓存服务器等等.这里我们将采用读写分 ...
- Mysql-Proxy实现mysql读写分离、负载均衡 (转)
在mysql中实现读写分离.负载均衡,用Mysql-Proxy是很容易的事,不过大型处理对于性能方面还有待提高,主要配置步骤如下: 1.1. mysql-proxy安装 MySQL Proxy就是这么 ...
- Database基础(六):实现MySQL读写分离、MySQL性能调优
一.实现MySQL读写分离 目标: 本案例要求配置2台MySQL服务器+1台代理服务器,实现MySQL代理的读写分离: 用户只需要访问MySQL代理服务器,而实际的SQL查询.写入操作交给后台的2台M ...
- [mysql]linux mysql 读写分离
[mysql]linux mysql 读写分离 作者:flymaster qq:908601287 blog:http://www.cnblogs.com/flymaster500/ 1.简介 当今M ...
- amoeba实现MySQL读写分离
amoeba实现MySQL读写分离 准备环境:主机A和主机B作主从配置,IP地址为192.168.131.129和192.168.131.130,主机C作为中间件,也就是作为代理服务器,IP地址为19 ...
- php实现MySQL读写分离
MySQL读写分离有好几种方式 MySQL中间件 MySQL驱动层 代码控制 关于 中间件 和 驱动层的方式这里不做深究 暂且简单介绍下 如何通过PHP代码来控制MySQL读写分离 我们都知道 &q ...
- mysql读写分离——中间件ProxySQL的简介与配置
mysql实现读写分离的方式 mysql 实现读写分离的方式有以下几种: 程序修改mysql操作,直接和数据库通信,简单快捷的读写分离和随机的方式实现的负载均衡,权限独立分配,需要开发人员协助. am ...
- ProxySQL实现Mysql读写分离 - 部署手册
ProxySQL是一个高性能的MySQL中间件,拥有强大的规则引擎.ProxySQL是用C++语言开发的,也是percona推的一款中间件,虽然也是一个轻量级产品,但性能很好(据测试,能处理千亿级的数 ...
随机推荐
- SpringMVC小小注意点——/*和/的区别
/*会去匹配所有的数据,包括jsp /只匹配请求,不匹配jsp页面
- QGIS 3.14插件开发——Win10系统PyCharm开发环境搭建四步走
前言:最近实习要求做一个QGIS插件,网上关于QGIS 3.14插件开发环境搭建的文档不多,而且也不算太全面.正好实习的时候写了一个文档,在这里给大家分享一下. 因为是Word转的Markdown,可 ...
- Exception in thread "main" java.awt.AWTError: Assistive Technology not found: org.GNOME.Accessibilit
系统环境 Ubuntu 20.04 focal 问题分析 该异常出现的原因,从谷歌上可以得到答案 one of the more common causes of this exception is ...
- HCNP Routing&Switching之代理ARP
前文我们了解了端口隔离相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16186451.html:今天我们来聊一聊ARP代理相关话题: 端口隔离之破解之 ...
- python学习-Day16
目录 今日内容详细 内置函数补充 常见内置函数 help() id() int() isinstance() pow() round() sum() 求和 迭代器 可迭代对象 什么是可迭代对象? 哪些 ...
- 【学习笔记】CDQ分治(等待填坑)
因为我对CDQ分治理解不深,所以这篇博客只是我现在的浅显理解有任何不对的,希望大佬指出. 首先就是CDQ分治适用的题型: (1)带修改,但修改互相独立 (2)必须允许离线 (3)解决数据结构的题,能把 ...
- Bugku练习题---MISC---蜜雪冰城~
Bugku练习题---MISC---蜜雪冰城~ flag:flag{1251_521_m1xueb1n9chen9ti@nm1mi} 解题步骤: 1.观察题目,下载附件 2.拿到手以后发现有好几个文件 ...
- [论文] FRCRN:利用频率递归提升特征表征的单通道语音增强
本文介绍了ICASSP2022 DNS Challenge第二名阿里和新加坡南阳理工大学的技术方案,该方案针对卷积循环网络对频率特征的提取高度受限于卷积编解码器(Convolutional Encod ...
- C++ 栈内存与堆内存小探究
实验方式:尝试以不同方式创建超大号二维数组 测试代码: #include <iostream> using namespace std; const int maxn=1000000; c ...
- fedora使用root超级用户
sudo -i可以使当前用户变成root帐号. 这样就不用一遍一遍的输sudo 了! 原来用sudo su也可以.