RNN,LSTM,BERT
RNN
RNN 按照时间步展开
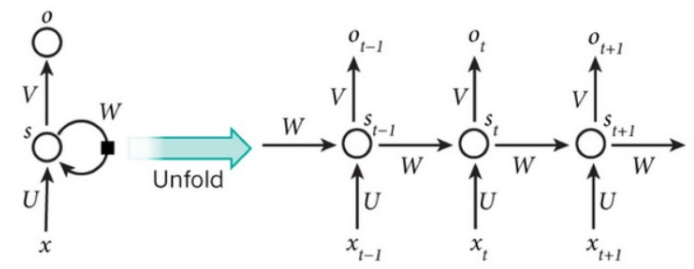
Bi-RNN
向前和向后的隐含层之间没有信息流。
LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失问题。
LSTM 对内部结构进行精心的设计,加入了输入门,遗忘门,输出门,和一个内部记忆单元\(c_t\)。输入门控制当前计算新状态以多大程度更新到记忆单元;遗忘门控制前一步记忆单元中的信息有多大程度被遗忘;输出门控制当前输出有多大程度上取决于当前的记忆单元。
和普通RNN相比,主要的输入输出区别如下
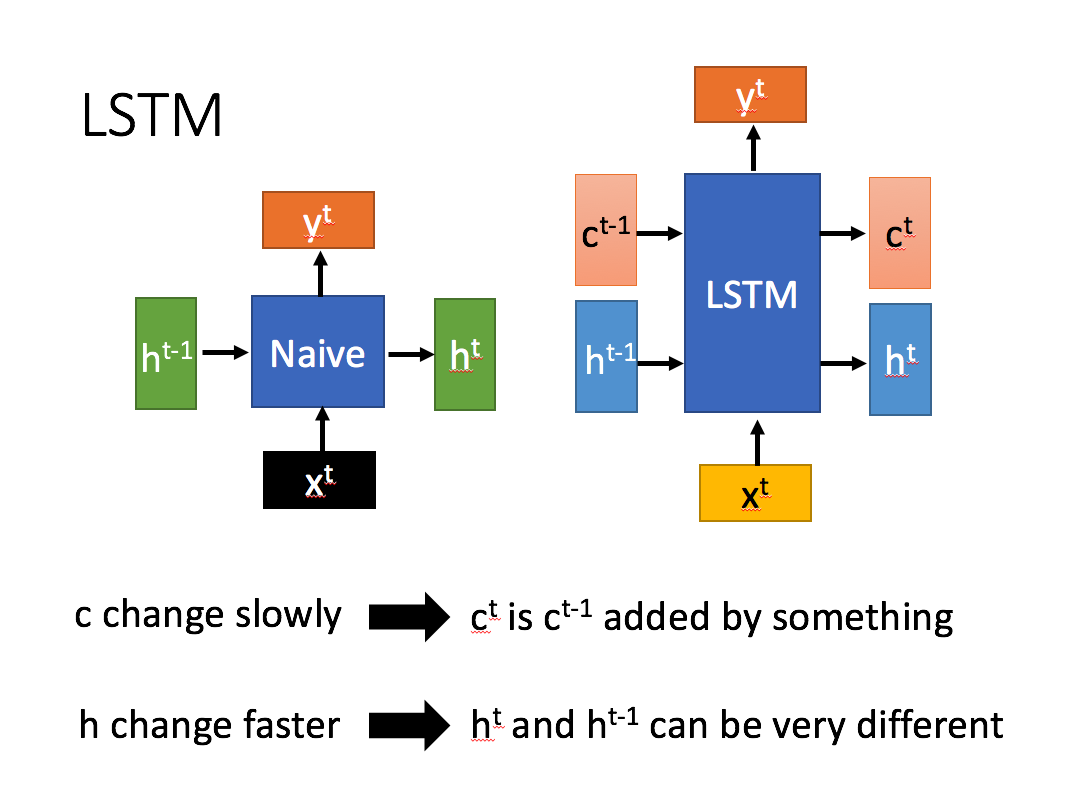
相比RNN只有一个传递状态\(h^t\),LSTM有两个传输状态,\(c^t\) (cell state)和 \(h^t\)(hidden state)。
计算公式
i_t = \sigma(W_i*[x_t, h_{t-1}]+b_i) \\
o_t = \sigma(W_o*[x_t, h_{t-1}]+b_o) \\
\tilde{C_t} = tanh(W_c*[h_t-1,x_t]+b_c) \\
C_t = f_t\odot C_{t-1}+i_t\odot \tilde{C_t} \\
h_t = o_t\odot tanh(C_t)
\]
参数量计算
\((hidden size * (hidden size + x_dim ) + hidden size) *4\)
self-attention
核心思想:用文本中的其他词来增强目标词的语义表示,从而更好地利用上下文信息。
计算步骤:
- 相似度计算
- softmax
- 加权平均
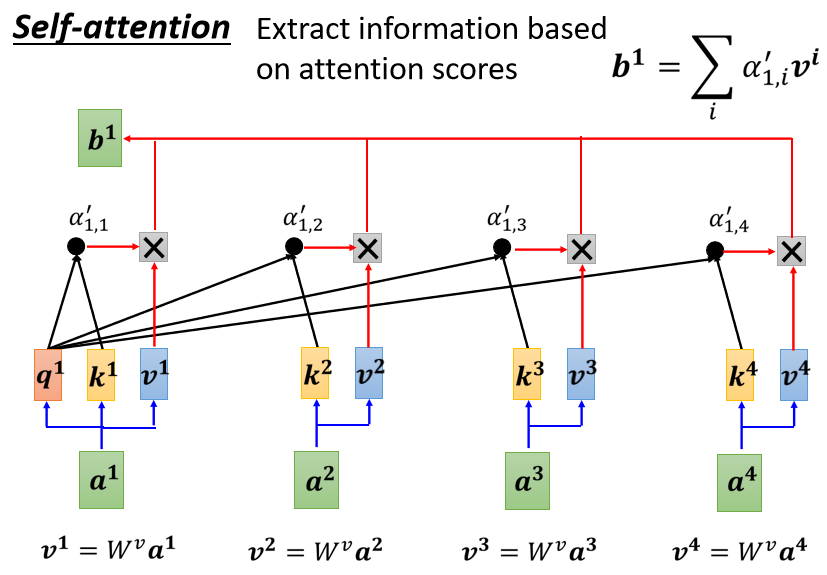
问题:常规的attention中,一般k=v, 那么self-attention中可以这样吗。
bert
推荐看原文哦: 超细节的BERT/Transformer知识点
史上最细节的自然语言处理NLP/Transformer/BERT/Attention面试问题与答案
上一个链接里问题的答案
论文
- Transformer: Attention Is All You Need
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
源码
问题
问题:为什么选择使用[cls]的输出代表整句话的语义表示?
或者说为什么不选择token1的输出
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。
为什么选它呢,
- 因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
- 从上面self-attention图片中可以看出把cls位置当做q,类似于站在全局的角度去观察整个句子文本。
问题:为什么是双线性点积模型(经过线性变换Q != K)?
- 双线性点积模型,引入非对称性,更具健壮性(Attention mask对角元素值不一定是最大的,也就是说当前位置对自身的注意力得分不一定最高)
展开解释:
- self-attention中,sequence中的每个词都会和sequence中的每个词做点积去计算相似度,也包括这个词本身。
- 对于 self-attention,一般会说它的 q=k=v,这里的相等实际上是指它们来自同一个基础向量,而在实际计算时,它们是不一样的,因为这三者都是乘了QKV参数矩阵的。那如果不乘,每个词对应的q,k,v就是完全一样的。
- 在相同量级的情况下,\(q_i\) 与 \(k_i\) 点积的值会是最大的(可以从“两数和相同的情况下,两数相等对应的积最大”类比过来)。
- 那在softmax后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法有效利用上下文信息来增强当前词的语义表示。
- 而乘以QKV参数矩阵,会使得每个词的q,k,v都不一样,能很大程度上减轻上述的影响。
问题:self-attention的时间复杂度
- 时间复杂复杂度为:\(O(n^2d)\)
- 相似度计算可以看成矩阵(n×d)×(d×n),这一步的时间复杂度为O(n×d×n)
- softmax的时间复杂度O(n^2)
- 加权平均可以看成矩阵(n×n)×(n×d), 时间复杂度为O(n×n×d)
多头注意力机制的时间复杂度:
hidden_size (d) = num_attention_heads (m) * attention_head_size (a),也即 d=m*a- 并将 num_attention_heads 维度transpose到前面,使得Q和K的维度都是(m,n,a),这里不考虑batch维度。
- 这样点积可以看作大小为(m,n,a)和(m,a,n)的两个张量相乘,得到一个(m,n,n)的矩阵,其实就相当于(n,a)和(a,n)的两个矩阵相乘,做了m次,时间复杂度是\(O(n^2×a×m) = O(n^2d)\)
问题:BERT 怎么处理长文本?
问题:BERT 比ELMO 效果好的原因
从网络结构以及最后的实验效果来看,BERT 比 ELMo 效果好主要集中在以下几点原因:
- LSTM 抽取特征的能力远弱于 Transformer
- 拼接方式双向融合的特征融合能力偏弱(没有具体实验验证,只是推测)
- 其实还有一点,BERT 的训练数据以及模型参数均多余 ELMo,这也是比较重要的一点
知乎:transformer中multi-head attention中每个head为什么要进行降维?
link
简洁的说:在不增加时间复杂度的情况下,同时,借鉴CNN多核的思想,在更低的维度,在多个独立的特征空间,更容易学习到更丰富的特征信息。
问题:BERT中的mask
- 预训练的时候在句子编码的时候将部分词mask,这个主要作用是用被mask词前后的词来去猜测mask掉的词是什么,因为是人为mask掉的,所以计算机是知道mask词的正确值,所以也可以判断模型猜的词是否准确。
- Transformer模型的decoder层存在mask,这个mask的作用是在翻译预测的时候,如“我爱你”,翻译成“I love you”,模型在预测love的时候是不知道you的信息,所以需r要把后面“you”的信息mask掉。但是bert只有encoder层,所以这个算是transformer模型的特征。
- 每个attention模块都有一个可选择的mask操作,这个主要是输入的句子可能存在填0的操作,attention模块不需要把填0的无意义的信息算进来,所以使用mask操作。
问题:bert中进行ner为什么没有使用crf;使用DL进行序列标注问题的时候CRF是必备嘛(todo: in action)
进行序列标注时CRF是必须的吗?
如果你已经将问题本身确定为序列标注了,并且正确的标注结果是唯一的,那么用CRF理论上是有正的收益的,但如果主体是BERT等预训练模型,那么可能要调一下CRF层的学习率,参考CRF层的学习率可能不够大进行NER时必须转为序列标注吗?
就原始问题而言,不论是NER、词性标注还是阅读理解等,都不一定要转化为序列标注问题,既然不转化为序列标注问题,自然也就用不着CRF了。不转化为序列标注的做法也有很多,比如笔者提的GlobalPointer
问题:BERT的初始标准差为什么是0.02?
Retrieved from https://kexue.fm/archives/8747
cnn vs rnn vs self-attention
语义特征提取能力
- 目前实验支持如下结论:Transformer在这方便的能力非常显著超过RNN和CNN,RNN和CNN两者能力差不多。
长距离特征捕捉能力
实验支持如下结论:- 原生CNN特征抽取器在这方面显著弱于RNN和Transformer
- Transformer微弱优于RNN模型(距离小于13的时)
- 在比较远的距离上RNN微弱优于Transformer
任务综合特征抽取能力(机器翻译)
Transformer > 原生CNN == 原生RNN
并行计算能力及运行效率
Transformer和CNN差不多,都强于RNN
RNN,LSTM,BERT的更多相关文章
- 从rnn到lstm,再到seq2seq(一)
rnn的的公式很简单: 对于每个时刻,输入上一个时刻的隐层s和这个时刻的文本x,然后输出这个时刻的隐层s.对于输出的隐层s 做个ws+b就是这个时刻的输出y. tf.scan(fn, elems, i ...
- pytorch --Rnn语言模型(LSTM,BiLSTM) -- 《Recurrent neural network based language model》
论文通过实现RNN来完成了文本分类. 论文地址:88888888 模型结构图: 原理自行参考论文,code and comment: # -*- coding: utf-8 -*- # @time : ...
- RNN,LSTM,GRU简单图解:
一篇经典的讲解RNN的,大部分网络图都来源于此:http://colah.github.io/posts/2015-08-Understanding-LSTMs/ 每一层每一时刻的输入输出:https ...
- 从rnn到lstm,再到seq2seq(二)
从图上可以看出来,decode的过程其实都是从encode的最后一个隐层开始的,如果encode输入过长的话,会丢失很多信息,所以设计了attation机制. attation机制的decode的过程 ...
- RNN,LSTM中如何使用TimeDistributed包装层,代码示例
本文介绍了LSTM网络中的TimeDistributed包装层,代码演示了具有TimeDistributed层的LSTM网络配置方法. 演示了一对一,多对一,多对多,三种不同的预测方法如何配置. 在对 ...
- tensorflow 笔记8:RNN、Lstm源码,训练代码输入输出,维度分析
tensorflow 官网信息:https://www.tensorflow.org/api_docs/python/tf/contrib/rnn/BasicLSTMCell tensorflow 版 ...
- 深度学习--RNN,LSTM
一.RNN 1.定义 递归神经网络(RNN)是两种人工神经网络的总称.一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neur ...
- 太深了,梯度传不下去,于是有了highway。 干脆连highway的参数都不要,直接变残差,于是有了ResNet。 强行稳定参数的均值和方差,于是有了BatchNorm。RNN梯度不稳定,于是加几个通路和门控,于是有了LSTM。 LSTM简化一下,有了GRU。
请简述神经网络的发展史sigmoid会饱和,造成梯度消失.于是有了ReLU.ReLU负半轴是死区,造成梯度变0.于是有了LeakyReLU,PReLU.强调梯度和权值分布的稳定性,由此有了ELU,以及 ...
- RNN,LSTM
RNN: Vanilla Neural Network :对单一固定的输入给出单一固定输出 Recurrent Neural Network:对单一固定的输入给出一系列输出(如:可边长序列),例:图片 ...
- RNN,GRU,LSTM
2019-08-29 17:17:15 问题描述:比较RNN,GRU,LSTM. 问题求解: 循环神经网络 RNN 传统的RNN是维护了一个隐变量 ht 用来保存序列信息,ht 基于 xt 和 ht- ...
随机推荐
- Python-网络编程和多进程多线程开发
网络编程 osi7层模型 以通过访问网站发送请求数据为例,每一层会做如下的事情 应用层:规定数据的格式. "GET /s?wd=你好 HTTP/1.1\r\nHost:www.baidu.c ...
- python requests库从接口get数据报错Max retries exceeded with url解决方式记录
问题: session = HTMLSession() r: requests_html.HTMLResponse r = session.get(url=req["url"], ...
- u盘重装系统后怎么恢复成普通u盘使用,U盘启动盘还原的方法
1.先将u盘插入到电脑,然后在电脑上按下win+r快捷键打开运行菜单,输入"cmd"回车确定打开命令提示符页面. 2. 然后在命令提示符输入"diskpart&quo ...
- 072_关于Dataloader导入Record的创建时间及修改时间并允许owner是Inactive
1.在User interface 中 启用 Enable "Set Audit Fields upon Record Creation" and "Update Rec ...
- NRF52832中文资料+蓝牙芯片
[产品应用] Nordic Semiconductor发布采用微型封装尺寸的高性能单芯片低功耗蓝牙SoC器件,瞄准新一代可穿戴产品和空间受限的loT应用.[产品说明]nRF52832晶圆级芯片尺寸封装 ...
- certutil工具使用和bypass学习
乌鸦安全的技术文章仅供参考,此文所提供的信息只为网络安全人员对自己所负责的网站.服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作.利用此文所提供 ...
- ESXI虚拟机 硬盘扩容/目录(添加新硬盘)
背景: 线上服务器,磁盘Linux的虚拟机根分区已经使用90%,触发了磁盘告警,再一顿操作删除后,勉勉强强回到了82%,现在需要对根目录进行扩容. 进入到EXSI管理平台,看到原来的sda磁盘只有30 ...
- BLP(Bell–LaPadula模型)(MAC)
Bell-LaPadula模型侧重于数据的保密性和对机密信息的受控访问 基于状态机,该状态机在一个计算机系统中具有一组允许的状态,并且从一个状态到另一种状态的转换由状态转移函数定义. 该模型定义了一个 ...
- 配置VS Code链接外部gsl库文件
配置VS code在C语言中调用gsl库文件 gsl安装 sudo apt-get install libgsl0-dev 先确认gsl库,gcc都已正确安装,命令行 gcc -L/usr/local ...
- @Async 注解的使用
1.@Async介绍 在Spring中,基于@Async标注的方法,称之为异步方法:这些方法将在执行的时候,将会在独立的线程中被执行,调用者无需等待它的完成,即可继续其他的操作 例如, 在某个调用中, ...