从零搭建hadoop集群之hadoop集群安装
1.集群规划
| HDSF | YARN | |
| hadoop01 | NanemNode(主机点),DataNode | NodeManager |
| hadoop02 | DataNode, SecondaryNamenode | NodeManager |
| hadoop03 | DataNode | NodeManager, ResourceManager(主节点) |
2. 再hadoop01的/home/hadoop目录下创建module 文件
3.下载2.7.6安装包 https://archive.apache.org/dist/hadoop/common/
4.上传hadoop安装包
通过xftp传送给到hadoop01机器的/home/hadoop/software目录下
[hadoop@hadoop01 software]$ tar -zxvf hadoop-2.7.6.tar.gz -C ../module/
5. 修改配置文件
cd /home/hadoop/module/hadoop-2.7.6/etc/hadoop
修改 hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_73
修改 core-site.xml
<configuration>
<!-- 指定 hdfs 的 nameservice 为 myha01 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myha01/</value>
</property>
<!-- 指定 hadoop 工作目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata/</value>
</property>
<!-- 指定 zookeeper 集群访问地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
修改 hdfs-site.xml
<configuration>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定 hdfs 的 nameservice 为 myha01,需要和 core-site.xml 中保持一致-->
<property>
<name>dfs.nameservices</name>
<value>myha01</value>
</property>
<!-- myha01 下面有两个 NameNode,分别是 nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.myha01</name>
<value>nn1,nn2</value>
</property>
<!-- nn1 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn1</name>
<value>hadoop01:9000</value>
</property>
<!-- nn1 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.myha01.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn2</name>
<value>hadoop02:9000</value>
</property>
<!-- nn2 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.myha01.nn2</name>
<value>hadoop02:50070</value>
</property>
<!-- 指定 NameNode 的 edits 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/myha01</value>
</property>
<!-- 指定 JournalNode 在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journaldata</value>
</property>
<!-- 开启 NameNode 失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<!-- 此处配置在安装的时候切记检查不要换行-->
<property>
<name>dfs.client.failover.proxy.provider.myha01</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用 sshfence 隔离机制时需要 ssh 免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置 sshfence 隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
修改 mapred-site.xml
<configuration>
<!-- 指定 mr 框架为 yarn 方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 设置 mapreduce 的历史服务器地址和端口号 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- mapreduce 历史服务器的 web 访问地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
修改 yarn-site.xml
<configuration>
<!-- 开启 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定 RM 的 cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定 RM 的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定 RM 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop04</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop05</value>
</property>
<!-- 指定 zk 集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop02:2181,hadoop03:2181,hadoop04:2181</value>
</property>
<!-- 要运行 MapReduce 程序必须配置的附属服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启 YARN 集群的日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- YARN 集群的聚合日志最长保留时长 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定 resourcemanager 的状态信息存储在 zookeeper 集群上-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
修改 slaves
添加 datanode 的节点地址:
hadoop01
hadoop02
hadoop03
6. 分发安装包到其他机器
scp -r hadoop-2.7.6 hadoop@hadoop02:$PWD
scp -r hadoop-2.7.6 hadoop@hadoop03:$PWD
7、 并分别配置环境变量
vim ~/.bashrc
添加两行:
export HADOOP_HOME=/home/hadoop/module/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
8. 集群初始化操作(记住:严格按照以下步骤执行)
先启动 zookeeper 集群
启动:zkServer.sh start
检查启动是否正常:zkServer.sh status
分别在每个 zookeeper(也就是规划的三个 journalnode 节点,不一定跟 zookeeper 节点一样)节点上启动 journalnode 进程
hadoop-daemon.sh start journalnode
然后用 jps 命令查看是否各个 datanode 节点上都启动了 journalnode 进程 如果报错,根据错误提示改进
在第一个 namenode 上执行格式化操作
hadoop namenode -format
然后会在 core-site.xml 中配置的临时目录中生成一些集群的信息 把他拷贝的第二个 namenode 的相同目录下
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata/</value>
这个目录下
[hadoop@hadoop01 ~]$ scp -r ~/data/hadoopdata/ hadoop02:~/data
或者也可以在另一个 namenode 上执行:hadoop namenode -bootstrapStandby

格式化 ZKFC
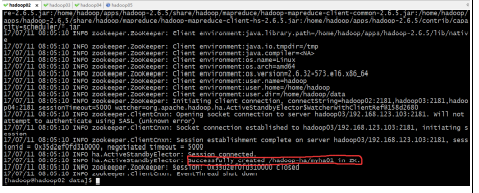
hdfs zkfc -formatZK
在第一台机器上即可
启动 HDFS
start-dfs.sh
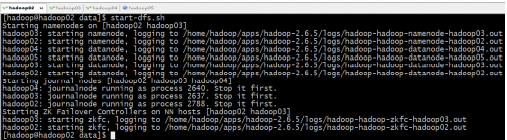
查看各节点进程是否启动正常:jps
访问 web 页面 http://hadoop01:50070
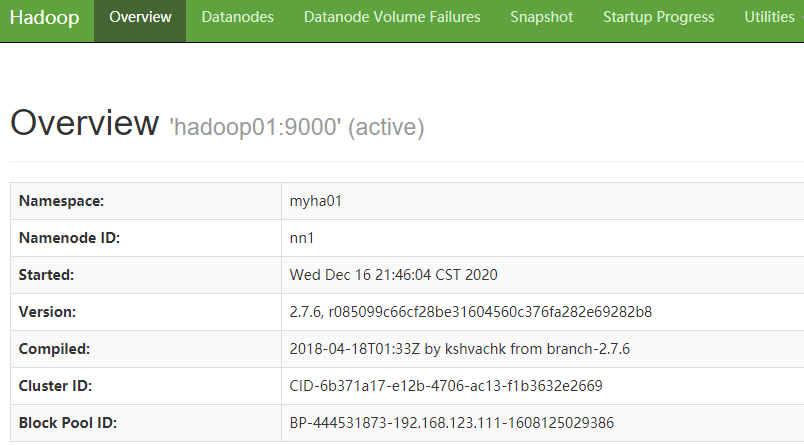
启动 YARN
start-yarn.sh
在主备 resourcemanager 中随便选择一台进行启动,正常启动之后,检查各节点的进程:jps
若备用节点的 resourcemanager 没有启动起来,则手动启动起来
yarn-daemon.sh start resourcemanager
之后打开浏览器访问页面:http://hadoop03:8088
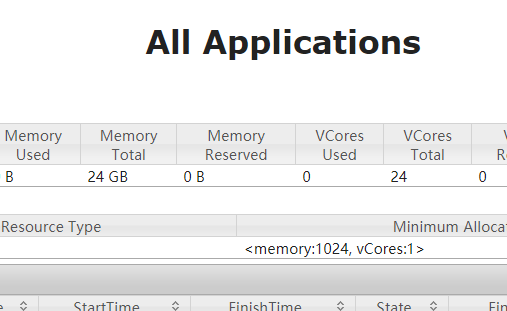
查看各主节点的状态
HDFS:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
YARN:
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
启动 mapreduce 任务历史服务器
mr-jobhistory-daemon.sh start historyserver
按照配置文件配置的历史服务器的 web 访问地址去访问: http://hadoop01:1988
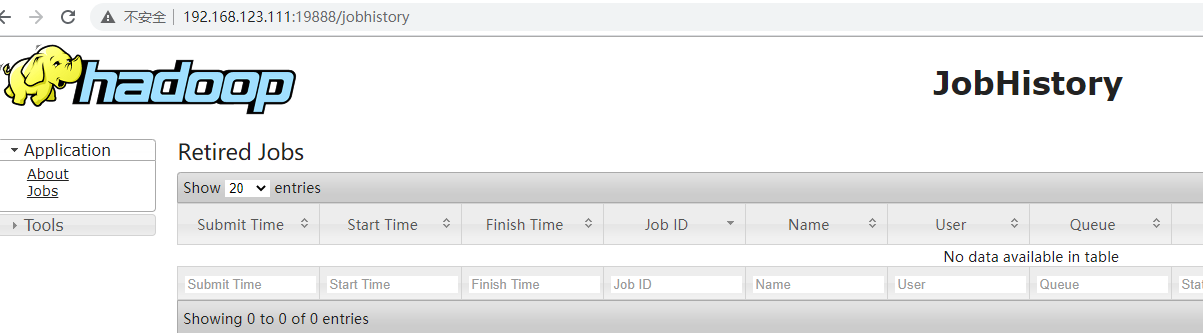
从零搭建hadoop集群之hadoop集群安装的更多相关文章
- Hadoop(五)搭建Hadoop与Java访问HDFS集群
前言 上一篇详细介绍了HDFS集群,还有操作HDFS集群的一些命令,常用的命令: hdfs dfs -ls xxx hdfs dfs -mkdir -p /xxx/xxx hdfs dfs -cat ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- Hadoop(二) HADOOP集群搭建
一.HADOOP集群搭建 1.集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 Na ...
- Hadoop(二)CentOS7.5搭建Hadoop2.7.6完全分布式集群
一 完全分布式集群(单点) Hadoop官方地址:http://hadoop.apache.org/ 1 准备3台客户机 1.1防火墙,静态IP,主机名 关闭防火墙,设置静态IP,主机名此处略,参考 ...
- (六)hadoop系列之__hadoop分布式集群环境搭建
配置hadoop(master,slave1,slave2) 说明: NameNode: master DataNode: slave1,slave2 ------------------------ ...
- Hadoop 3.0完全分布式集群搭建方法(CentOS 7+Hadoop 3.2.0)
本文详细介绍搭建4个节点的完全分布式Hadoop集群的方法,Linux系统版本是CentOS 7,Hadoop版本是3.2.0,JDK版本是1.8. 一.准备环境 1. 在VMware worksta ...
- Hadoop 2.0完全分布式集群搭建方法(CentOS7+Hadoop 2.7.7)
本文详细介绍搭建4个节点的完全分布式Hadoop集群的方法,Linux系统版本是CentOS 7,Hadoop版本是2.7.7,JDK版本是1.8. 一.准备环境 1. 在VMware worksta ...
- hadoop核心组件概述及hadoop集群的搭建
什么是hadoop? Hadoop 是 Apache 旗下的一个用 java 语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台.允许使用简单的编程模型在大量计算机集群上对大型数据集进行分 ...
- Hadoop详解(02)Hadoop集群运行环境搭建
Hadoop详解(02)Hadoop集群运行环境搭建 虚拟机环境准备 虚拟机节点数:3台 操作系统版本:CentOS-7.6-x86-1810 虚拟机 内存4G,硬盘99G IP地址分配 192.16 ...
随机推荐
- 使用Shapefile C Library读取shp文件并使用OpenGL绘制
1. 概述 坐标数据是空间数据文件的核心,空间数据的数据量往往是很大的.数据可视化是GIS的一个核心应用,绘制海量的坐标数据始终是一个考验设备性能的难题,使用GPU进行绘制可有效减少CPU的负载,提升 ...
- LeetCode算法训练-贪心算法 455.分发饼干 376. 摆动序列 53. 最大子序和
欢迎关注个人公众号:爱喝可可牛奶 LeetCode算法训练-贪心算法 455.分发饼干 376. 摆动序列 53. 最大子序和 前置知识 贪心算法核心是找局部最优解,通过局部最优推导出全局最优 Lee ...
- Corundum:100G NIC学习(二)——仿真
前情提要:搭建corundum仿真环境(一)https://www.cnblogs.com/shroud404/articles/15364812.html 三.Running test 接上文,梳理 ...
- 【FPGA学习】MATLAB和FPGA实现FFT
本博客记录一下在matlab设计和在FPGA平台实现FFT的方法,平台是Xilinx的ZYNQ 参考: COE文件制作与使用 Vivado使用技巧(9):COE文件使用方法 .coe文件生成 在某些I ...
- $forceUpdate和this.$set('userInfo',name,'小红');
在Vue官方文档中指出,$forceUpdate具有强制刷新的作用. 那在vue框架中,如果data中有一个变量:age,修改他,页面会自动更新. 但如果data中的变量为数组或对象,我们直接去给某个 ...
- combox下拉框控件
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- N63050 第十二周运维作业 ansible常用模块介绍未完成
就业和全程班本周学习内容: 二十三.Mysql数据库四 1.MySQL主从复制实现和故障排错(50分钟) 2.MySQL级联复制和主主复制架构实现(51分钟) 3.MySQL的半同步复制和复制过滤器( ...
- Unity ARCore动态增加识别图
项目需要,有两点要求说明一下 1.如果你的图片是下载生成的,那没什么问题 2.如果你的识别图是存储在APK包里的话需要调整图片属性: 代码如下: using QFramework; using Sys ...
- JavaSE——this关键字
this修饰的变量用于指代成员变量,其主要作用是(区分局部变量和成员变量的重名问题) 方法的形参如果与成员变量同名,不带this修饰的变量指的是形参,而不是成员变量 方法的形参没有与成员变量同名,不带 ...
- 一个小demo---递归计算子类下的某个值的总和
public function demo($frames) { foreach ($frames as $k => $frame) { $frames[$k]['allCount'] = $fr ...