使用python爬虫爬取链家潍坊市二手房项目
使用python爬虫爬取链家潍坊市二手房项目
需求分析
需要将潍坊市各县市区页面所展示的二手房信息按要求爬取下来,同时保存到本地。
流程设计
- 明确目标网站URL( https://wf.lianjia.com/ )
- 确定爬取二手房哪些具体信息(字段名)
- python爬虫关键实现:requests库和lxml库
- 将爬取的数据存储到CSV或数据库中
实现过程
项目目录

1、在数据库中创建数据表
我电脑上使用的是MySQL8.0,图形化工具用的是Navicat.
数据库字段对应
id-编号、title-标题、total_price-房屋总价、unit_price-房屋单价、
square-面积、size-户型、floor-楼层、direction-朝向、type-楼型、
district-地区、nearby-附近区域、community-小区、elevator-电梯有无、
elevatorNum-梯户比例、ownership-房屋性质
该图显示的是字段名、数据类型、长度等信息。

2、自定义数据存储函数
这部分代码放到Spider_wf.py文件中
通过write_csv函数将数据存入CSV文件,通过write_db函数将数据存入数据库
点击查看代码
import csv
import pymysql
#写入CSV
def write_csv(example_1):
csvfile = open('二手房数据.csv', mode='a', encoding='utf-8', newline='')
fieldnames = ['title', 'total_price', 'unit_price', 'square', 'size', 'floor','direction','type',
'BuildTime','district','nearby', 'community', 'decoration', 'elevator','elevatorNum','ownership']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writerow(example_1)
#写入数据库
def write_db(example_2):
conn = pymysql.connect(host='127.0.0.1',port= 3306,user='changziru',
password='ru123321',database='secondhouse_wf',charset='utf8mb4'
)
cursor =conn.cursor()
title = example_2.get('title', '')
total_price = example_2.get('total_price', '0')
unit_price = example_2.get('unit_price', '')
square = example_2.get('square', '')
size = example_2.get('size', '')
floor = example_2.get('floor', '')
direction = example_2.get('direction', '')
type = example_2.get('type', '')
BuildTime = example_2.get('BuildTime','')
district = example_2.get('district', '')
nearby = example_2.get('nearby', '')
community = example_2.get('community', '')
decoration = example_2.get('decoration', '')
elevator = example_2.get('elevator', '')
elevatorNum = example_2.get('elevatorNum', '')
ownership = example_2.get('ownership', '')
cursor.execute('insert into wf (title, total_price, unit_price, square, size, floor,direction,type,BuildTime,district,nearby, community, decoration, elevator,elevatorNum,ownership)'
'values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)',
[title, total_price, unit_price, square, size, floor,direction,type,
BuildTime,district,nearby, community, decoration, elevator,elevatorNum,ownership])
conn.commit()#传入数据库
conn.close()#关闭数据库
3、爬虫程序实现
这部分代码放到lianjia_house.py文件,调用项目Spider_wf.py文件中的write_csv和write_db函数
点击查看代码
#爬取链家二手房详情页信息
import time
from random import randint
import requests
from lxml import etree
from secondhouse_spider.Spider_wf import write_csv,write_db
#模拟浏览器操作
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
#随机USER_AGENTS
random_agent = USER_AGENTS[randint(0, len(USER_AGENTS) - 1)]
headers = {'User-Agent': random_agent,}
class SpiderFunc:
def __init__(self):
self.count = 0
def spider(self ,list):
for sh in list:
response = requests.get(url=sh, params={'param':'1'},headers={'Connection':'close'}).text
tree = etree.HTML(response)
li_list = tree.xpath('//ul[@class="sellListContent"]/li[@class="clear LOGVIEWDATA LOGCLICKDATA"]')
for li in li_list:
# 获取每套房子详情页的URL
detail_url = li.xpath('.//div[@class="title"]/a/@href')[0]
try:
# 向每个详情页发送请求
detail_response = requests.get(url=detail_url, headers={'Connection': 'close'}).text
except Exception as e:
sleeptime = randint(15,30)
time.sleep(sleeptime)#随机时间延迟
print(repr(e))#打印异常信息
continue
else:
detail_tree = etree.HTML(detail_response)
item = {}
title_list = detail_tree.xpath('//div[@class="title"]/h1/text()')
item['title'] = title_list[0] if title_list else None # 1简介
total_price_list = detail_tree.xpath('//span[@class="total"]/text()')
item['total_price'] = total_price_list[0] if total_price_list else None # 2总价
unit_price_list = detail_tree.xpath('//span[@class="unitPriceValue"]/text()')
item['unit_price'] = unit_price_list[0] if unit_price_list else None # 3单价
square_list = detail_tree.xpath('//div[@class="area"]/div[@class="mainInfo"]/text()')
item['square'] = square_list[0] if square_list else None # 4面积
size_list = detail_tree.xpath('//div[@class="base"]/div[@class="content"]/ul/li[1]/text()')
item['size'] = size_list[0] if size_list else None # 5户型
floor_list = detail_tree.xpath('//div[@class="base"]/div[@class="content"]/ul/li[2]/text()')
item['floor'] = floor_list[0] if floor_list else None#6楼层
direction_list = detail_tree.xpath('//div[@class="type"]/div[@class="mainInfo"]/text()')
item['direction'] = direction_list[0] if direction_list else None # 7朝向
type_list = detail_tree.xpath('//div[@class="area"]/div[@class="subInfo"]/text()')
item['type'] = type_list[0] if type_list else None # 8楼型
BuildTime_list = detail_tree.xpath('//div[@class="transaction"]/div[@class="content"]/ul/li[5]/span[2]/text()')
item['BuildTime'] = BuildTime_list[0] if BuildTime_list else None # 9房屋年限
district_list = detail_tree.xpath('//div[@class="areaName"]/span[@class="info"]/a[1]/text()')
item['district'] = district_list[0] if district_list else None # 10地区
nearby_list = detail_tree.xpath('//div[@class="areaName"]/span[@class="info"]/a[2]/text()')
item['nearby'] = nearby_list[0] if nearby_list else None # 11区域
community_list = detail_tree.xpath('//div[@class="communityName"]/a[1]/text()')
item['community'] = community_list[0] if community_list else None # 12小区
decoration_list = detail_tree.xpath('//div[@class="base"]/div[@class="content"]/ul/li[9]/text()')
item['decoration'] = decoration_list[0] if decoration_list else None # 13装修
elevator_list = detail_tree.xpath('//div[@class="base"]/div[@class="content"]/ul/li[11]/text()')
item['elevator'] = elevator_list[0] if elevator_list else None # 14电梯
elevatorNum_list = detail_tree.xpath('//div[@class="base"]/div[@class="content"]/ul/li[10]/text()')
item['elevatorNum'] = elevatorNum_list[0] if elevatorNum_list else None # 15梯户比例
ownership_list = detail_tree.xpath('//div[@class="transaction"]/div[@class="content"]/ul/li[2]/span[2]/text()')
item['ownership'] = ownership_list[0] if ownership_list else None # 16交易权属
self.count += 1
print(self.count,title_list)
# 将爬取到的数据存入CSV文件
write_csv(item)
# 将爬取到的数据存取到MySQL数据库中
write_db(item)
#循环目标网站
count =0
for page in range(1,101):
if page <=40:
url_qingzhoushi = 'https://wf.lianjia.com/ershoufang/qingzhoushi/pg' + str(page) # 青州市40
url_hantingqu = 'https://wf.lianjia.com/ershoufang/hantingqu/pg' + str(page) # 寒亭区 76
url_fangzi = 'https://wf.lianjia.com/ershoufang/fangziqu/pg' + str(page) # 坊子区
url_kuiwenqu = 'https://wf.lianjia.com/ershoufang/kuiwenqu/pg' + str(page) # 奎文区
url_gaoxin = 'https://wf.lianjia.com/ershoufang/gaoxinjishuchanyekaifaqu/pg' + str(page) # 高新区
url_jingji = 'https://wf.lianjia.com/ershoufang/jingjijishukaifaqu2/pg' + str(page) # 经济技术85
url_shouguangshi = 'https://wf.lianjia.com/ershoufang/shouguangshi/pg' + str(page) # 寿光市 95
url_weichengqu = 'https://wf.lianjia.com/ershoufang/weichengqu/pg' + str(page) # 潍城区
list_wf = [url_qingzhoushi, url_hantingqu,url_jingji, url_shouguangshi, url_weichengqu, url_fangzi, url_kuiwenqu, url_gaoxin]
SpiderFunc().spider(list_wf)
elif page <=76:
url_hantingqu = 'https://wf.lianjia.com/ershoufang/hantingqu/pg' + str(page) # 寒亭区 76
url_fangzi = 'https://wf.lianjia.com/ershoufang/fangziqu/pg' + str(page) # 坊子区
url_kuiwenqu = 'https://wf.lianjia.com/ershoufang/kuiwenqu/pg' + str(page) # 奎文区
url_gaoxin = 'https://wf.lianjia.com/ershoufang/gaoxinjishuchanyekaifaqu/pg' + str(page) # 高新区
url_jingji = 'https://wf.lianjia.com/ershoufang/jingjijishukaifaqu2/pg' + str(page) # 经济技术85
url_shouguangshi = 'https://wf.lianjia.com/ershoufang/shouguangshi/pg' + str(page) # 寿光市 95
url_weichengqu = 'https://wf.lianjia.com/ershoufang/weichengqu/pg' + str(page) # 潍城区
list_wf = [url_hantingqu,url_jingji, url_shouguangshi, url_weichengqu, url_fangzi, url_kuiwenqu, url_gaoxin]
SpiderFunc().spider(list_wf)
elif page<=85:
url_fangzi = 'https://wf.lianjia.com/ershoufang/fangziqu/pg' + str(page) # 坊子区
url_kuiwenqu = 'https://wf.lianjia.com/ershoufang/kuiwenqu/pg' + str(page) # 奎文区
url_gaoxin = 'https://wf.lianjia.com/ershoufang/gaoxinjishuchanyekaifaqu/pg' + str(page) # 高新区
url_jingji = 'https://wf.lianjia.com/ershoufang/jingjijishukaifaqu2/pg' + str(page) # 经济技术85
url_shouguangshi = 'https://wf.lianjia.com/ershoufang/shouguangshi/pg' + str(page) # 寿光市 95
url_weichengqu = 'https://wf.lianjia.com/ershoufang/weichengqu/pg' + str(page) # 潍城区
list_wf = [url_jingji, url_shouguangshi, url_weichengqu, url_fangzi, url_kuiwenqu, url_gaoxin]
SpiderFunc().spider(list_wf)
elif page <=95:
url_shouguangshi = 'https://wf.lianjia.com/ershoufang/shouguangshi/pg' + str(page) # 寿光市 95
url_weichengqu = 'https://wf.lianjia.com/ershoufang/weichengqu/pg' + str(page) # 潍城区
url_fangzi = 'https://wf.lianjia.com/ershoufang/fangziqu/pg' + str(page) # 坊子区
url_kuiwenqu = 'https://wf.lianjia.com/ershoufang/kuiwenqu/pg' + str(page) # 奎文区
url_gaoxin = 'https://wf.lianjia.com/ershoufang/gaoxinjishuchanyekaifaqu/pg' + str(page) # 高新区
list_wf = [url_shouguangshi, url_weichengqu, url_fangzi, url_kuiwenqu, url_gaoxin]
SpiderFunc().spider(list_wf)
else:
url_weichengqu = 'https://wf.lianjia.com/ershoufang/weichengqu/pg' + str(page) # 潍城区
url_fangzi = 'https://wf.lianjia.com/ershoufang/fangziqu/pg' + str(page) # 坊子区
url_kuiwenqu = 'https://wf.lianjia.com/ershoufang/kuiwenqu/pg' + str(page) # 奎文区
url_gaoxin = 'https://wf.lianjia.com/ershoufang/gaoxinjishuchanyekaifaqu/pg' + str(page) # 高新区
list_wf = [url_weichengqu, url_fangzi,url_kuiwenqu, url_gaoxin]
SpiderFunc().spider(list_wf)
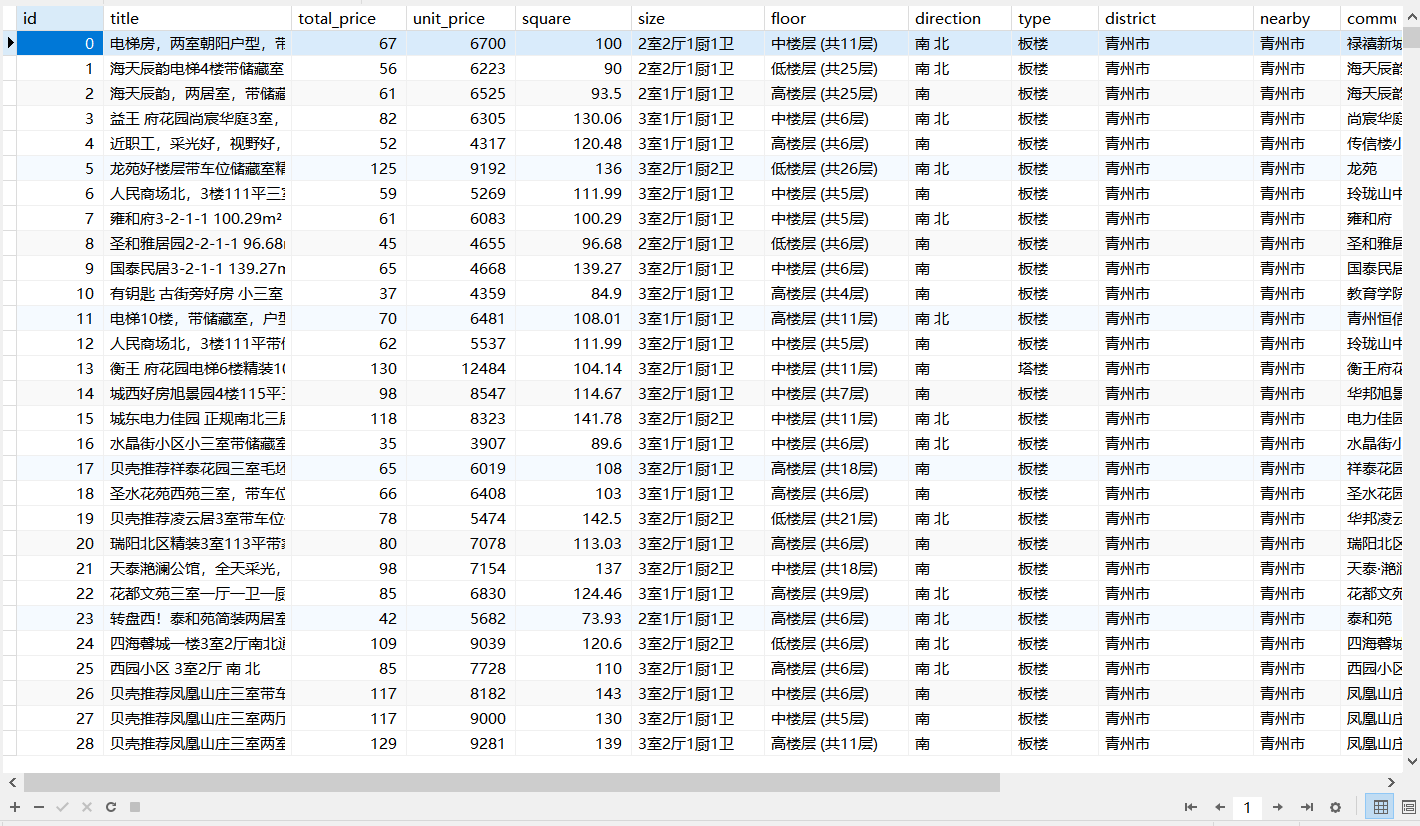
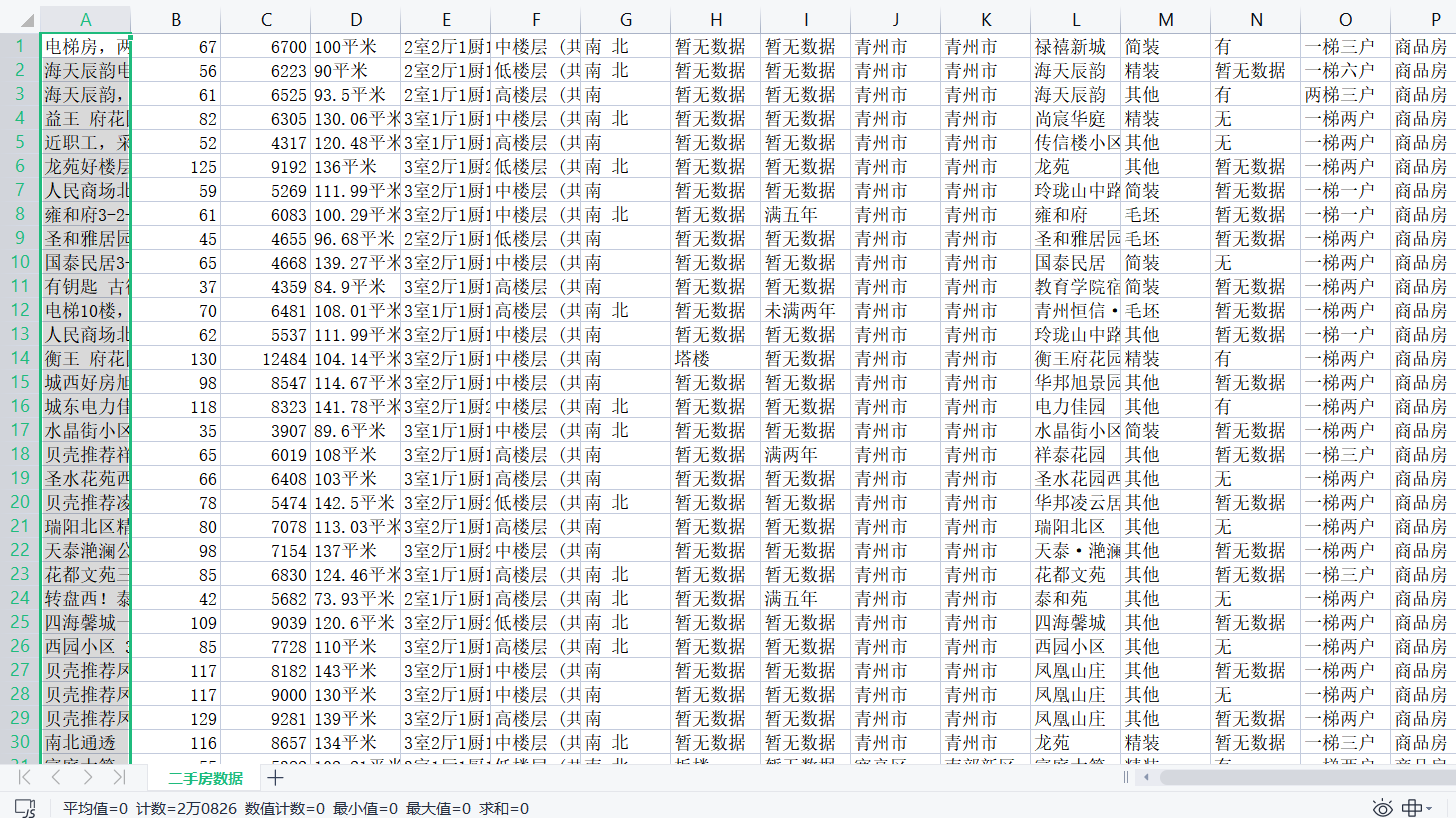
4、效果展示
总共获取到20826条数据,
我数据库因为要做数据分析,因而作了预处理,获得18031条
使用python爬虫爬取链家潍坊市二手房项目的更多相关文章
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- Python——Scrapy爬取链家网站所有房源信息
用scrapy爬取链家全国以上房源分类的信息: 路径: items.py # -*- coding: utf-8 -*- # Define here the models for your scrap ...
- 43.scrapy爬取链家网站二手房信息-1
首先分析:目的:采集链家网站二手房数据1.先分析一下二手房主界面信息,显示情况如下: url = https://gz.lianjia.com/ershoufang/pg1/显示总数据量为27589套 ...
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
- 44.scrapy爬取链家网站二手房信息-2
全面采集二手房数据: 网站二手房总数据量为27650条,但有的参数字段会出现一些问题,因为只给返回100页数据,具体查看就需要去细分请求url参数去请求网站数据.我这里大概的获取了一下筛选条件参数,一 ...
- Python爬虫项目--爬取链家热门城市新房
本次实战是利用爬虫爬取链家的新房(声明: 内容仅用于学习交流, 请勿用作商业用途) 环境 win8, python 3.7, pycharm 正文 1. 目标网站分析 通过分析, 找出相关url, 确 ...
- Python爬取链家二手房源信息
爬取链家网站二手房房源信息,第一次做,仅供参考,要用scrapy. import scrapy,pypinyin,requests import bs4 from ..items import L ...
- python爬虫:爬取链家深圳全部二手房的详细信息
1.问题描述: 爬取链家深圳全部二手房的详细信息,并将爬取的数据存储到CSV文件中 2.思路分析: (1)目标网址:https://sz.lianjia.com/ershoufang/ (2)代码结构 ...
- python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码
前言 作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始. 一.分析观察爬取网站结构 这里以广州链家二手房为例:http:/ ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
随机推荐
- Java-Maven实现简单的文件上传下载(菜鸟一枚、仅供参考)
1.JSP页面代码实现 <%@ page language="java" contentType="text/html; charset=UTF-8" p ...
- 高级纹理以及复杂而真实的应用——ShaderCp10
--20.9.7 这章主要分成三个部分 立方体纹理(cubemap) 渲染纹理(RenderTexture,rt) 和程序纹理 一.立方体纹理 立方体纹理顾名思义是一种三维的纹理形状类似于立方体,由六 ...
- 2020-2021第一学期2024"DCDD"小组第十二周讨论
2020-2021第一学期"DCDD"第十二周讨论 这次不同的是,先来一个密文吧: 53fd95b7c2bd8c1383cdcbf5b04e3880 求解! 小组名称:DCDD 小 ...
- pycharm 2021.3版本无法安装unittest
不用安装unittest包,直接在类后面的括号里黏贴:unittest.TestCase,报错后点击导入unittest包即可.
- 在Unity3D中开发的Hologram Shader
SwordMaster Hologram Shader 特点 此全息投影风格的Shader是顶点片元Shader,由本人手动编写完成 此全息投影风格的Shader已经在移动设备真机上进行过测试,可以直 ...
- LCP 34. 二叉树染色
class Solution: def maxValue(self, root: TreeNode, k: int) -> int: def dfs(root): # 空节点价值全为0 res ...
- Python 删除文件及文件夹
2种方式: [不删除给定的目录] path1 = "D:\\dev\\workspace\\python\\pytestDemo\\222" def del_filedir(pat ...
- kubectl使用方法及常用命令小结
Kubectl 是一个命令行接口,用于对 Kubernetes 集群运行命令.kubectl 在 $HOME/.kube 目录中寻找一个名为 config 的文件. kubectl安装方法详见:htt ...
- Windows+svn +Jenkins+发布NetCore/VUE项目
1. NetCore环境下载,注意是下载SDK,不是Runtime:https://dotnet.microsoft.com/download/dotnet-core?utm_source=getdo ...
- java初学者-向一个长度为5的整型数组中随机生成5个1-10的随机整数 ,要求生成的数字中没有重复数
public static void main(String[]args){ //定义一个数组 长度为5:角标为4 int []arr=new int[5]; for(int i=0;i<5;i ...