迁移学习(ADDA)《Adversarial Discriminative Domain Adaptation》
论文信息
论文标题:Adversarial Discriminative Domain Adaptation
论文作者:Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell
论文来源:CVPR 2017
论文地址:download
论文代码:download
引用次数:3257
1 简介
本文主要探讨的是:源域和目标域特征提取器共享参数的必要性。
源域和目标域特征提取器共享参数的代表——DANN。
2 对抗域适应
标准监督损失训练源数据:
$\underset{M_{s}, C}{\text{min}} \quad \mathcal{L}_{\mathrm{cls}}\left(\mathbf{X}_{s}, Y_{t}\right)= \mathbb{E}_{\left(\mathbf{x}_{s}, y_{s}\right) \sim\left(\mathbf{X}_{s}, Y_{t}\right)}-\sum\limits _{k=1}^{K} \mathbb{1}_{\left[k=y_{s}\right]} \log C\left(M_{s}\left(\mathbf{x}_{s}\right)\right)\quad\quad(1)$
域对抗:首先使得域鉴别器分类准确,即最小化交叉熵损失 $\mathcal{L}_{\operatorname{adv}_{D}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, M_{s}, M_{t}\right)$:
$\begin{array}{l}\mathcal{L}_{\text {adv }_{D}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, M_{s}, M_{t}\right)= -\mathbb{E}_{\mathbf{x}_{s} \sim \mathbf{X}_{s}}\left[\log D\left(M_{s}\left(\mathbf{x}_{s}\right)\right)\right] -\mathbb{E}_{\mathbf{x}_{t} \sim \mathbf{X}_{t}}\left[\log \left(1-D\left(M_{t}\left(\mathbf{x}_{t}\right)\right)\right)\right]\end{array} \quad\quad(2)$
其次,源映射和目标映射根据一个受约束的对抗性目标进行优化(使得域鉴别器损失最大)。
域对抗技术的通用公式如下:
$\begin{array}{l}\underset{D}{\text{min}} & \mathcal{L}_{\mathrm{adv}_{D}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, M_{s}, M_{t}\right) \\\underset{M_{s}, M_{t}}{\text{min}} & \mathcal{L}_{\mathrm{adv}_{M}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, D\right) \\\text { s.t. } & \psi\left(M_{s}, M_{t}\right)\end{array}\quad\quad(3)$
2.1 源域和目标域映射
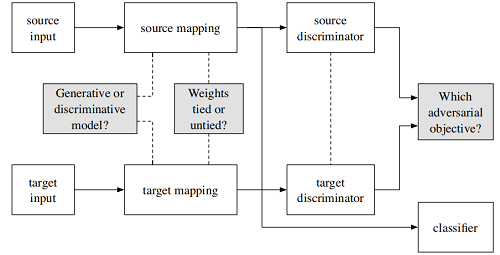
归结为三个问题:
- 选择生成式模型还是判别式模型?
- 针对源域与目标域的映射是否共享参数?
- 损失函数如何定义?
2.2 Adversarial losses
回顾DANN 的训练方式:DANN 的梯度反转层优化映射,使鉴别器损失最大化
$\mathcal{L}_{\text {adv }_{M}}=-\mathcal{L}_{\mathrm{adv}_{D}}\quad\quad(6)$
当训练 GANs 时,而不是直接使用 minimax,通常是用带有倒置标签[10]的标准损失函数来训
回顾 GAN :GAN将优化分为两个独立的目标,一个用于生成器,另一个用于鉴别器。训练生成器的时候,其中 $\mathcal{L}_{\mathrm{adv}_{D}}$ 保持不变,但 $\mathcal{L}_{\mathrm{adv}_{M}}$ 变成:
Note:$\mathbf{x}_{t}$ 代表噪声数据,这里是使得噪声数据尽可能迷惑鉴别器。


adversarial_loss = torch.nn.BCELoss() # 损失函数(二分类交叉熵损失)
generator = Generator() #生成器
discriminator = Discriminator() #鉴别器 optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) # 生成器优化器
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) # 鉴别器优化器 for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False) #torch.Size([64, 1])
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False) #torch.Size([64, 1])
real_imgs = Variable(imgs.type(Tensor)) #torch.Size([64, 1, 28, 28]) 真实数据 # ----------------------> 训练生成器 [生成器使用噪声数据,使得其尽可能为真,迷惑鉴别器]
optimizer_G.zero_grad()
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))) #torch.Size([64, 100])
gen_imgs = generator(z) #torch.Size([64, 1, 28, 28])
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step() # ----------------------> 训练鉴别器 [ 尽可能将真实数据和噪声数据区分开]
optimizer_D.zero_grad()
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
GAN code
本文采用的方法类似于 GAN 。
3 对抗性域适应
与之前方法不同:

本文方法:
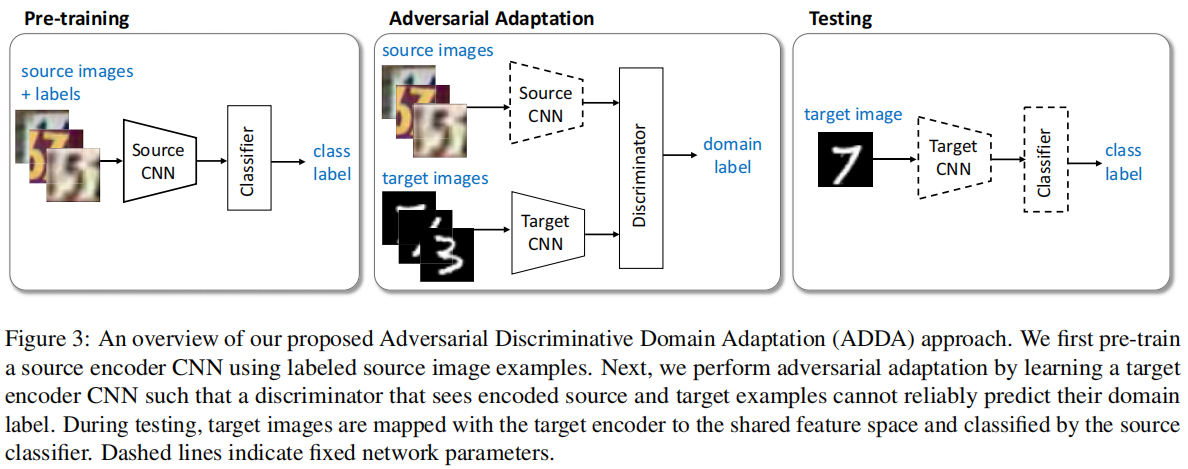
首先:Pretrain ,使用源域训练一个分类器;[ 公式 9 第一个子公式]
其次:Adversarial Adaption
- :使用源域和目标域数据,训练一个域鉴别器 Discriminator ,是的鉴别器尽可能区分源域和目标域数据 ;[ 公式 9 第二个子公式]
- :使用目标域数据,训练目标域特征提取器,尽可能使得域鉴别器区分不出目标域样本;[ 公式 9 第三个子公式]
最后:Testing,在目标域上做 Eval;
ADDA对应于以下无约束优化:
$\begin{array}{l}\underset{M_{s}, C}{\text{min}} \quad \mathcal{L}_{\mathrm{cls}}\left(\mathbf{X}_{s}, Y_{s}\right) &=&-\mathbb{E}_{\left(\mathbf{x}_{s}, y_{s}\right) \sim\left(\mathbf{X}_{s}, Y_{s}\right)} \sum_{k=1}^{K} \mathbb{1}_{\left[k=y_{s}\right]} \log C\left(M_{s}\left(\mathbf{x}_{s}\right)\right) \\\underset{D}{\text{min}} \quad\mathcal{L}_{\text {adv }_{D}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, M_{s}, M_{t}\right)&=& -\mathbb{E}_{\mathbf{x}_{s} \sim \mathbf{X}_{s}}\left[\log D\left(M_{s}\left(\mathbf{x}_{s}\right)\right)\right] \text { - } \mathbb{E}_{\mathbf{x}_{t} \sim \mathbf{X}_{t}}\left[\log \left(1-D\left(M_{t}\left(\mathbf{x}_{t}\right)\right)\right)\right] \\\underset{M_{t}}{\text{min}} \quad \mathcal{L}_{\operatorname{adv}_{M}}\left(\mathbf{X}_{s}, \mathbf{X}_{t}, D\right)&=& -\mathbb{E}_{\mathbf{x}_{t} \sim \mathbf{X}_{t}}\left[\log D\left(M_{t}\left(\mathbf{x}_{t}\right)\right)\right] \\\end{array} \quad\quad(9)$
tgt_encoder.train()
discriminator.train() # setup criterion and optimizer
criterion = nn.CrossEntropyLoss()
optimizer_tgt = optim.Adam(tgt_encoder.parameters(),lr=params.c_learning_rate,betas=(params.beta1, params.beta2))
optimizer_discriminator = optim.Adam(discriminator.parameters(),lr=params.d_learning_rate,betas=(params.beta1, params.beta2))
len_data_loader = min(len(src_data_loader), len(tgt_data_loader)) #149 for epoch in range(params.num_epochs):
# zip source and target data pair
data_zip = enumerate(zip(src_data_loader, tgt_data_loader))
for step, ((images_src, _), (images_tgt, _)) in data_zip:
# 2.1 训练域鉴别器,使得域鉴别器尽可能的准确
images_src = make_variable(images_src)
images_tgt = make_variable(images_tgt)
discriminator.zero_grad()
feat_src,feat_tgt = src_encoder(images_src) ,tgt_encoder(images_tgt) # 源域特征提取 # 目标域特征提取
feat_concat = torch.cat((feat_src, feat_tgt), 0)
pred_concat = discriminator(feat_concat.detach()) # 域分类结果 label_src = make_variable(torch.ones(feat_src.size(0)).long()) #假设源域的标签为 1
label_tgt = make_variable(torch.zeros(feat_tgt.size(0)).long()) #假设目标域域的标签为 0
label_concat = torch.cat((label_src, label_tgt), 0) loss_critic = criterion(pred_concat, label_concat)
loss_critic.backward()
optimizer_discriminator.step() # 域鉴别器优化 pred_cls = torch.squeeze(pred_concat.max(1)[1])
acc = (pred_cls == label_concat).float().mean() # 2.2 train target encoder # 使得目标域特征生成器,尽可能使得域鉴别器区分不出源域和目标域样本
optimizer_discriminator.zero_grad()
optimizer_tgt.zero_grad()
feat_tgt = tgt_encoder(images_tgt)
pred_tgt = discriminator(feat_tgt)
label_tgt = make_variable(torch.ones(feat_tgt.size(0)).long()) #假设目标域域的标签为 1(错误标签),使得域鉴别器鉴别错误
loss_tgt = criterion(pred_tgt, label_tgt)
loss_tgt.backward()
optimizer_tgt.step() # 目标域 encoder 优化
ADDA Code
迁移学习(ADDA)《Adversarial Discriminative Domain Adaptation》的更多相关文章
- 【深度学习系列】迁移学习Transfer Learning
在前面的文章中,我们通常是拿到一个任务,譬如图像分类.识别等,搜集好数据后就开始直接用模型进行训练,但是现实情况中,由于设备的局限性.时间的紧迫性等导致我们无法从头开始训练,迭代一两百万次来收敛模型, ...
- Domain adaptation:连接机器学习(Machine Learning)与迁移学习(Transfer Learning)
domain adaptation(域适配)是一个连接机器学习(machine learning)与迁移学习(transfer learning)的新领域.这一问题的提出在于从原始问题(对应一个 so ...
- 迁移学习(Transformer),面试看这些就够了!(附代码)
1. 什么是迁移学习 迁移学习(Transformer Learning)是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中.迁移学习是通过从已学习的相 ...
- 中文NER的那些事儿2. 多任务,对抗迁移学习详解&代码实现
第一章我们简单了解了NER任务和基线模型Bert-Bilstm-CRF基线模型详解&代码实现,这一章按解决问题的方法来划分,我们聊聊多任务学习,和对抗迁移学习是如何优化实体识别中边界模糊,垂直 ...
- 论文阅读 | A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes
paper链接:https://arxiv.org/pdf/1812.09953.pdf code链接:https://github.com/YangZhang4065/AdaptationSeg 摘 ...
- 【论文笔记】Domain Adaptation via Transfer Component Analysis
论文题目:<Domain Adaptation via Transfer Component Analysis> 论文作者:Sinno Jialin Pan, Ivor W. Tsang, ...
- 域适应(Domain adaptation)
定义 在迁移学习中, 当源域和目标的数据分布不同 ,但两个任务相同时,这种 特殊 的迁移学习 叫做域适应 (Domain Adaptation). Domain adaptation有哪些实现手段呢? ...
- Deep Transfer Network: Unsupervised Domain Adaptation
转自:http://blog.csdn.net/mao_xiao_feng/article/details/54426101 一.Domain adaptation 在开始介绍之前,首先我们需要知道D ...
- Domain Adaptation论文笔记
领域自适应问题一般有两个域,一个是源域,一个是目标域,领域自适应可利用来自源域的带标签的数据(源域中有大量带标签的数据)来帮助学习目标域中的网络参数(目标域中很少甚至没有带标签的数据).领域自适应如今 ...
- 【迁移学习】2010-A Survey on Transfer Learning
资源:http://www.cse.ust.hk/TL/ 简介: 一个例子: 关于照片的情感分析. 源:比如你之前已经搜集了大量N种类型物品的图片进行了大量的人工标记(label),耗费了巨大的人力物 ...
随机推荐
- golang中的锁竞争问题
索引:https://www.waterflow.link/articles/1666884810643 当我们打印错误的时候使用锁可能会带来意想不到的结果. 我们看下面的例子: package ma ...
- 浅谈API和SDK的区别
首先了解一下他们的定义 API:application program interface 应用程序接口 通常表示一些事先定义好的函数,为了向外部提供一组功能的实现,实现和其他软件的交互 SDK:so ...
- C#中进行数值的比较
Equals的使用 str1.Equals(str2,StringComparison.OrdinalIgnoreCase); ----比较str1和str2 StringComp ...
- 并发编程之 ThreadLocal
前言 了解过 SimpleDateFormat 时间工具类的朋友都知道,该工具类非常好用,可以利用该类可以将日期转换成文本,或者将文本转换成日期,时间戳同样也可以. 以下代码,我们采用通用的 Simp ...
- 看了同事这10个IDEA神级插件,我也悄悄安装了
昨天,有读者私信发我一篇文章,说里面提到的 Intellij IDEA 插件真心不错,基本上可以一站式开发了,希望能分享给更多的小伙伴,我在本地装了体验了一下,觉得确实值得推荐,希望小伙伴们有时间也可 ...
- JS常见问题总结
1. 什么是 JavaScript ? JavaScript 是一种具有面向对象的.解释型的.基于对象和事件驱动的.跨平台的.弱类型的程序设计语言 2. JavaScript 与 ECMAScript ...
- 幂次方表达:p1010
1 题目ID: P1010 [NOIP1998 普及组] 幂次方 2 题目描述: 任何一个正整数都可以用 22 的幂次方表示.例如 137=2^7+2^3+2^0137=27+23+20. 同时约定方 ...
- 聊聊FASTER和进程内混合缓存
最近有一个朋友问我这样一个问题: 我的业务依赖一些数据,因为数据库访问慢,我把它放在Redis里面,不过还是太慢了,有什么其它的方案吗? 其实这个问题比较简单的是吧?Redis其实属于网络存储,我对照 ...
- C ++:树
C++:树 树的概念: 所谓"树"是输就结构的一种,树大概可以分为两大类: 有根树 和 无根树 有根树使有一个确定的根节点,反之为无根树 · 子节点:从树根开始,通过树边向下扩展的 ...
- 关于mysql数据库user表没有password字段
解决 这个是因为mysql的版本问题,是mysql 5.7版本出现的,具体是mysql 5.7.x 开始变化的我不知道 新的字段变更为authentication_string 修改密码的方式还是和原 ...