记一次线上FGC问题排查
引言
本文记录一次线上 GC 问题的排查过程与思路,希望对各位读者有所帮助。过程中也走了一些弯路,现在有时间沉淀下来思考并总结出来分享给大家,希望对大家今后排查线上 GC 问题有帮助。
背景
服务新功能发版一周后下午,突然收到 CMS GC 告警,导致单台节点被拉出,随后集群内每个节点先后都发生了一次 CMS GC,拉出后的节点垃圾回收后接入流量恢复正常(事后排查发现被重启了)。
告警信息如下(已脱敏):
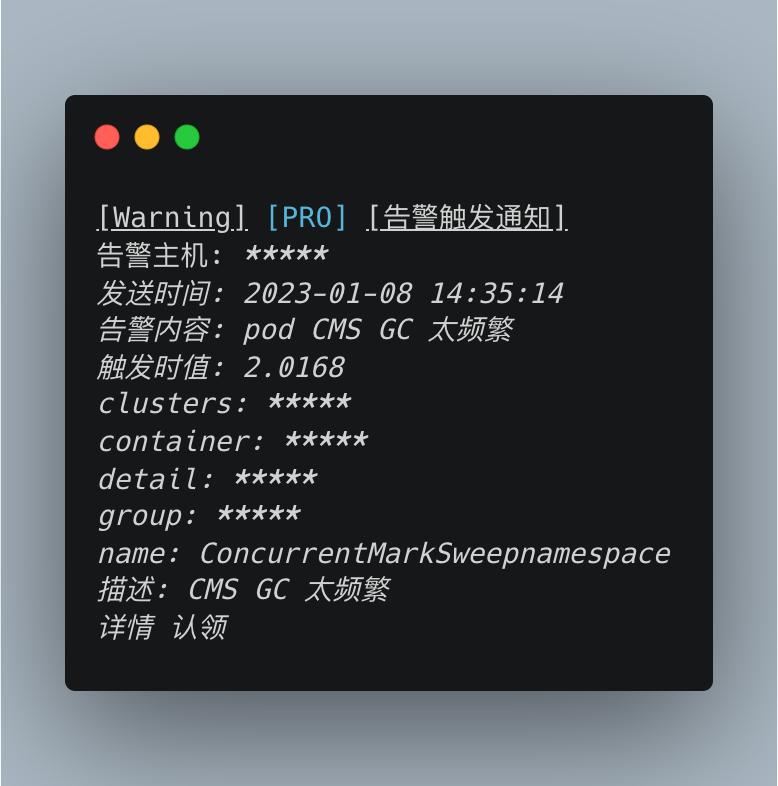
多个节点几乎同时发生 GC 问题,且排查自然流量监控后发现并未有明显增高,基本可以确定是有 GC 问题的,需要解决。
排查过程
GC 日志排查
GC 问题首先排查的应该是 GC 日志,日志能能够清晰的判定发生 GC 的那一刻是什么导致的 GC,通过分析 GC 日志,能够清晰的得出 GC 哪一部分在出问题,如下是 GC 日志示例:
0.514: [GC (Allocation Failure) [PSYoungGen: 4445K->1386K(28672K)] 168285K->165234K(200704K), 0.0036830 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.518: [Full GC (Ergonomics) [PSYoungGen: 1386K->0K(28672K)] [ParOldGen: 163848K->165101K(172032K)] 165234K->165101K(200704K), [Metaspace: 3509K->3509K(1056768K)], 0.0103061 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
0.528: [GC (Allocation Failure) [PSYoungGen: 0K->0K(28672K)] 165101K->165101K(200704K), 0.0019968 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.530: [Full GC (Allocation Failure) [PSYoungGen: 0K->0K(28672K)] [ParOldGen: 165101K->165082K(172032K)] 165101K->165082K(200704K), [Metaspace: 3509K->3509K(1056768K)], 0.0108352 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
如上 GC 日志能很明显发现导致 Full GC 的问题是:Full GC 之后,新生代内存没有变化,老年代内存使用从 165101K 降低到 165082K (几乎没有变化)。这个程序最后内存溢出了,因为没有可用的堆内存创建 70m 的大对象。
但是,生产环境总是有奇奇怪怪的问题,由于服务部署在 K8s 容器,且运维有对服务心跳检测,当程序触发 Full GC 时,整个系统 Stop World,连续多次心跳检测失败,则判定为当前节点可能出故障(硬件、网络、BUG 等等问题),则直接拉出当前节点,并立即重建,此时之前打印的 GC 日志都是在当前容器卷内,一旦重建,所有日志全部丢失,也就无法通过 GC 日志排查问题了。
JVM 监控埋点排查
上述 GC 日志丢失问题基本无解,发生 GC 则立即重建,除非人为干预,否则很难拿到当时的 GC 日志,且很难预知下次发生 GC 问题时间(如果能上报 GC 日子就不会有这样的问题,事后发现有,但是我没找到。。)。
此时,另一种办法就是通过 JVM 埋点监控来排查问题。企业应用都会配备完备的 JVM 监控看板,就是为了能清晰明了的看到“事故现场”,通过监控,可以清楚的看到 JVM 内部在时间线上是如何分配内存及回收内存的。
JVM 监控用于监控重要的 JVM 指标,包括堆内存、非堆内存、直接缓冲区、内存映射缓冲区、GC 累计信息、线程数等。
主要关注的核心指标如下:
- GC(垃圾收集)瞬时和累计详情
- FullGC 次数
- YoungGC 次数
- FullGC 耗时
- YoungGC 耗时
- 堆内存详情
- 堆内存总和
- 堆内存老年代字节数
- 堆内存年轻代 Survivor 区字节数
- 堆内存年轻代 Eden 区字节数
- 已提交内存字节数
- 元空间元空间字节数
- 非堆内存
- 非堆内存提交字节数
- 非堆内存初始字节数
- 非堆内存最大字节数
- 直接缓冲区
- DirectBuffer 总大小(字节)
- DirectBuffer 使用大小(字节)
- JVM 线程数
- 线程总数量
- 死锁线程数量
- 新建线程数量
- 阻塞线程数量
- 可运行线程数量
- 终结线程数量
- 限时等待线程数量
- 等待中线程数量
发生 GC 问题,重点关注的就是这几个指标,大致就能圈定 GC 问题了。
堆内存排查
首先查看堆内存,确认是否有内存溢出(指无法申请足够的内存导致),对内监控如下:
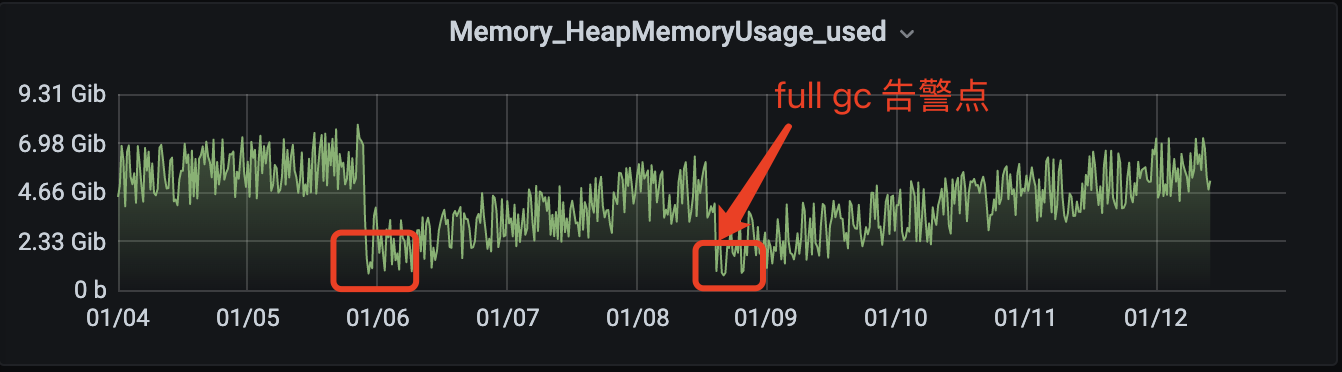
可以看到发生 Full GC 后,堆内存明显降低了很多,但是在未发生大量 Full GC 后也有内存回收到和全量 GC 同等位置,所以可以断定堆内存是可以正常回收的,不是导致大量 Full GC 的元凶。
非堆内存排查
非堆内存指 Metaspace 区域,监控埋点如下:
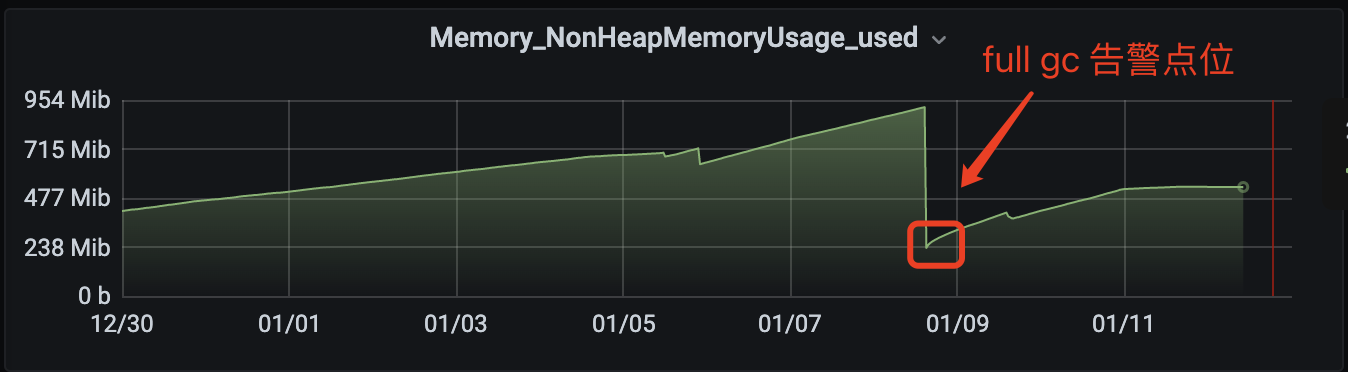
可以看到发生告警后,非堆内存瞬间回收很多(因为服务器被健康检查判定失效后重建,相当于重新启动,JVM 重新初始化),此处如果有 GC 排查经验的人一定能立即笃定,metaspace 是有问题的。
Metaspace 是用来干嘛的?JDK8 的到来,JVM 不再有 PermGen(永久代),但类的元数据信息(metadata)还在,只不过不再是存储在连续的堆空间上,而是移动到叫做 “Metaspace” 的本地内存(Native memory)中。
那么何时会加载类信息呢?
- 程序运行时:当运行 Java 程序时,该程序所需的类和方法。
- 类被引用时:当程序首次引用某个类时,加载该类。
- 反射:当使用反射 API 访问某个类时,加载该类。
- 动态代理:当使用动态代理创建代理对象时,加载该对象所需的类。
由上得出结论,如果一个服务内没有大量的反射或者动态代理等类加载需求时,讲道理,程序启动后,类的加载数量应该是波动很小的(不排除一些异常堆栈反射时也会加载类导致增加),但是如上监控显示,GC 后,metaspace 的内存使用量一直缓步增长,即程序内不停地制造“类”。
查看 JVM 加载类监控如下:
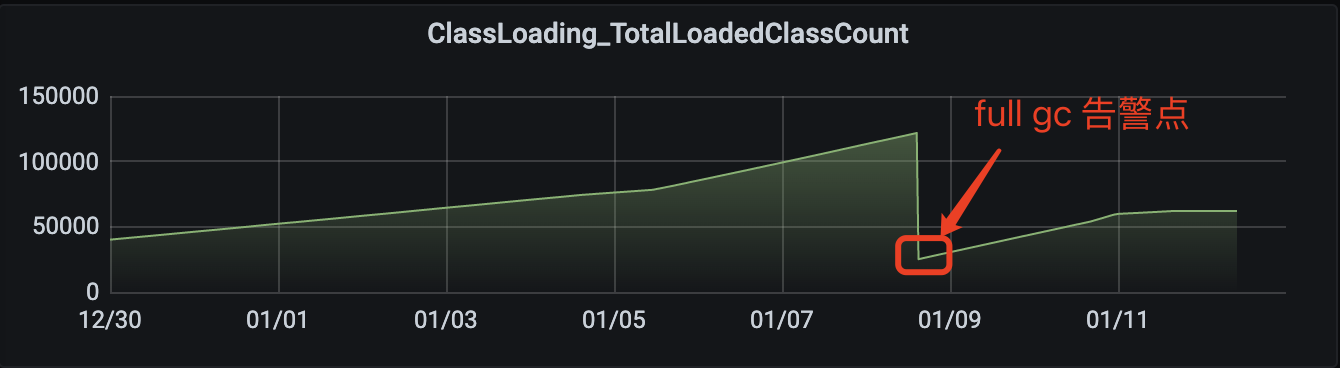
由上监控,确实是加载了大量的类,数量趋势和非堆使用量趋势吻合。
查看当前 JVM 设置的非堆内存大小如下:
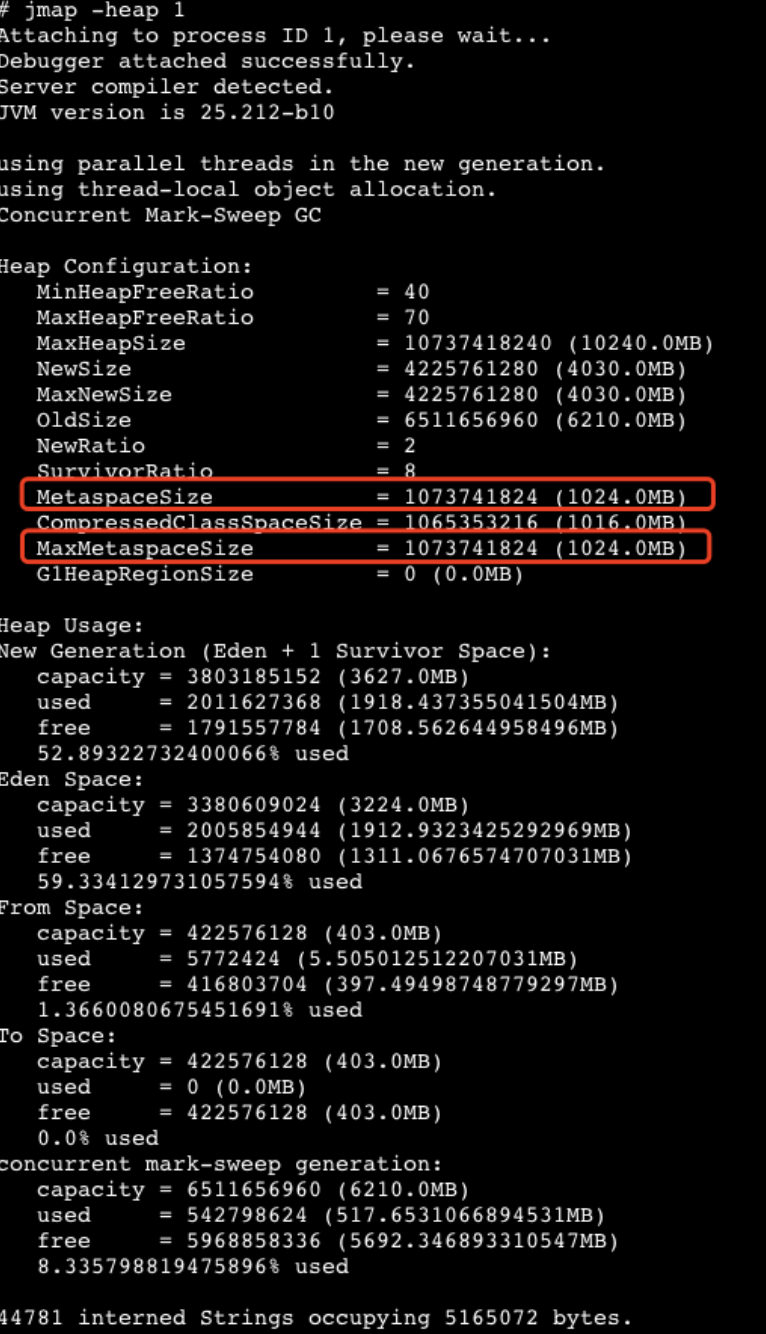
MetaspaceSize & MaxMetaspaceSize = 1024 M,由上面非堆内存使用监控得出,使用量已接近 1000 M,无法在分配足够的内存来加载类,最终导致发生 Full GC 问题。
程序代码排查
由上面排查得出的结论:程序内在大量的创建类导致非堆内存被打爆。结合当前服务内存在大量使用 Groovy 动态脚本功能,大概率应该是创建脚本出了问题,脚本创建动态类代码如下:
public static GroovyObject buildGroovyObject(String script) {
GroovyClassLoader classLoader = new GroovyClassLoader();
try {
Class<?> groovyClass = classLoader.parseClass(script);
GroovyObject groovyObject = (GroovyObject) groovyClass.newInstance();
classLoader.clearCache();
log.info("groovy buildScript success: {}", groovyObject);
return groovyObject;
} catch (Exception e) {
throw new RuntimeException("buildScript error", e);
} finally {
try {
classLoader.close();
} catch (IOException e) {
log.error("close GroovyClassLoader error", e);
}
}
}
线上打开日志,确实证明了在不停的创建类。
脚本创建类导致堆内存被打爆,之间也是踩过坑的,针对同一个脚本(MD5 值相同),则会直接拿缓存,不会重复创建类,缓存 check 逻辑如下:
public static GroovyObject buildScript(String scriptId, String script) {
Validate.notEmpty(scriptId, "scriptId is empty");
Validate.notEmpty(scriptId, "script is empty");
// 尝试缓存获取
String currScriptMD5 = DigestUtils.md5DigestAsHex(script.getBytes());
if (GROOVY_OBJECT_CACHE_MAP.containsKey(scriptId)
&& currScriptMD5.equals(GROOVY_OBJECT_CACHE_MAP.get(scriptId).getScriptMD5())) {
log.info("groovyObjectCache hit, scriptId: {}", scriptId);
return GROOVY_OBJECT_CACHE_MAP.get(scriptId).getGroovyObject();
}
// 创建
try {
GroovyObject groovyObject = buildGroovyObject(script);
// 塞入缓存
GROOVY_OBJECT_CACHE_MAP.put(scriptId, GroovyCacheData.builder()
.scriptMD5(currScriptMD5)
.groovyObject(groovyObject)
.build());
} catch (Exception e) {
throw new RuntimeException(String.format("scriptId: %s buildGroovyObject error", scriptId), e);
}
return GROOVY_OBJECT_CACHE_MAP.get(scriptId).getGroovyObject();
}
此处代码逻辑在之前的测试中都是反复验证过的,不会存在问题,即只有缓存 Key 出问题导致了类的重复加载。结合最近修改上线的逻辑,排查后发现,scriptId 存在重复的可能,导致不同脚本,相同 scriptId 不停重复加载(加载的频次 10 分钟更新一次,所以非堆使用缓慢上升)。
此处埋了一个小坑:加载的类使用 Map 存储的,即同一个 cacheKey 调用 Map.put() 方法,重复加载的类会被后面加载的类给替换掉,即之前加载的类已经不在被 Map 所“持有”,会被垃圾回收器回收掉,按理来说 Metaspace 不应该一直增长下去!?
提示:类加载与 Groovy 类加载、Metaspace 何时会被回收。
由于篇幅原因,本文就不在此处细究原因了,感兴趣的朋友自行 Google 或者关注一下我,后续我再专门开一章详解下原因。
总结
知其然知其所以然。
想要系统性地掌握 GC 问题处理方法,还是得了解 GC 的基础:基础概念、内存划分、分配对象、收集对象、收集器等。掌握常用的分析 GC 问题的工具,如 gceasy.io 在线 GC 日志分析工具,此处笔者参照了美团技术团队文章 Java 中 9 种常见的 CMS GC 问题分析与解决 收益匪浅,推荐大家阅读。
往期精彩
欢迎关注公众号:咕咕鸡技术专栏
个人技术博客:https://jifuwei.github.io/ >

记一次线上FGC问题排查的更多相关文章
- 记一次线上bug排查-quartz线程调度相关
记一次线上bug排查,与各位共同探讨. 概述:使用quartz做的定时任务,正式生产环境有个任务延迟了1小时之久才触发.在这一小时里各种排查找不出问题,直到延迟时间结束了,该任务才珊珊触发.原因主要就 ...
- 解Bug之路-记一次线上请求偶尔变慢的排查
解Bug之路-记一次线上请求偶尔变慢的排查 前言 最近解决了个比较棘手的问题,由于排查过程挺有意思,于是就以此为素材写出了本篇文章. Bug现场 这是一个偶发的性能问题.在每天几百万比交易请求中,平均 ...
- Java线上应用故障排查之二:高内存占用
搞Java开发的,经常会碰到下面两种异常: 1.java.lang.OutOfMemoryError: PermGen space 2.java.lang.OutOfMemoryError: Java ...
- 一次线上OOM故障排查经过
转贴:http://my.oschina.net/flashsword/blog/205266 本文是一次线上OOM故障排查的经过,内容比较基础但是真实,主要是记录一下,没有OOM排查经验的同学也可以 ...
- java线上应用故障排查之二:高内存占用【转】
前一篇介绍了线上应用故障排查之一:高CPU占用,这篇主要分析高内存占用故障的排查. 搞Java开发的,经常会碰到下面两种异常: 1.java.lang.OutOfMemoryError: PermGe ...
- 【JVM】线上应用故障排查
高CPU占用 一个应用占用CPU很高,除了确实是计算密集型应用之外,通常原因都是出现了死循环. 根据top命令,发现PID为28555的Java进程占用CPU高达200%,出现故障. 通过ps aux ...
- 线上服务器CPU100%排查,Linux进程消耗查看
线上服务器CPU100%排查,Linux进程消耗查看 1.排查步骤 1.1Linux下排查 1.1.1查消耗cpu最高的进程PID 1.1.2根据PID查出消耗cpu最高的线程号 1.1.3根据线程号 ...
- 记一次线上dubbo服务超时和线程池满问题排查
线上某dubbo服务A调用dubbo服务B的接口X方法,调用端A日志中出现了很多超时的情况,提供端B该接口X超时时间设置为60s: 查看提供端B的日志,报了很多线程池满的异常: Caused by: ...
- 记一次线上事故的JVM内存学习
今天线上的hadoop集群崩溃了,现象是namenode一直在GC,长时间无法正常服务.最后运维大神各种倒腾内存,GC稳定后,服务正常.虽说全程在打酱油,但是也跟着学习不少的东西. 第一个问题:为什么 ...
- 记一次线上coredump事故
1.事故背景 上周三凌晨,我负责的某个模块在多台机器上连续发生coredump,幸好发生在业务低峰期,而且该模块提供的功能也不是核心流程功能,所以对线上业务影响比较小.发生coredump后,运维收到 ...
随机推荐
- jquery的toggle()函数,显示/隐藏交替
<!DOCTYPE html> <html lang="en"> <head> <script src="jquery.js&q ...
- 二、redis介绍
二.redis介绍 2.1.定义 Redis(Remote Dictionary Server ,远程字典服务) 是一个使用ANSI C编写的开源.支持网络.基于内存.可选持久性的键值对存储数据库,是 ...
- 编译安装PHP7.4
1.下载PHP源码包 wget https://www.php.net/distributions/php-7.4.30.tar.gz 2.解压缩 tar xf php-7.4.30.tar.gz - ...
- python tcp select 多路复用
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 # 文件名:tcpserver.py 4 5 import socket 6 import time 7 ...
- 2流高手速成记(之八):基于Sentinel实现微服务体系下的限流与熔断
我们接上回 上一篇中,我们进行了简要的微服务实现,也体会到了SpringCloudAlibaba的强大和神奇之处 我们仅改动了两个注释,其他全篇代码不变,原来的独立服务就被我们分为了provider和 ...
- OpenHarmony移植案例: build lite源码分析之hb命令__entry__.py
摘要:本文介绍了build lite 轻量级编译构建系统hb命令的源码,主要分析了_\entry__.py文件. 本文分享自华为云社区<移植案例与原理 - build lite源码分析 之 hb ...
- spring源码解析(一) 环境搭建(各种坑的解决办法)
上次搭建spring源码的环境还是两年前,依稀记得那时候也是一顿折腾,奈何当时没有记录,导致两年后的今天把坑重踩了一遍,还遇到了新的坑,真是欲哭无泪;为了以后类似的事情不再发生,这次写下这篇博文来必坑 ...
- luoguP1505旅游(处理边权的树剖)
/* luogu1505 非常简单的处理边权的树剖题. 在树上将一条边定向,把这条边的权值赋给这条边的出点 树剖的时候不计算lca权值即可 */ #include<bits/stdc++.h&g ...
- C#winform使用NOPI读取Excel读取图片
需求:在Winform使用NOPI做导入时候,需要导入数据的同时导入图片. 虽然代码方面不适用(我好像也没仔细看过代码),但是感谢大佬给了灵感http://www.wjhsh.net/IT-Ramon ...
- HashMap为何线程不安全?HashMap,HashTable,ConcurrentHashMap对比
这两天写爬虫帮组里收集网上数据做训练,需要进一步对收集到的json数据做数据清洗,结果就用到了多线程下的哈希表数据结构,猛地回想起自己看<Java并发编程的艺术>框架篇的时候,在Concu ...