MySQL数据存储
MySQL体系架构
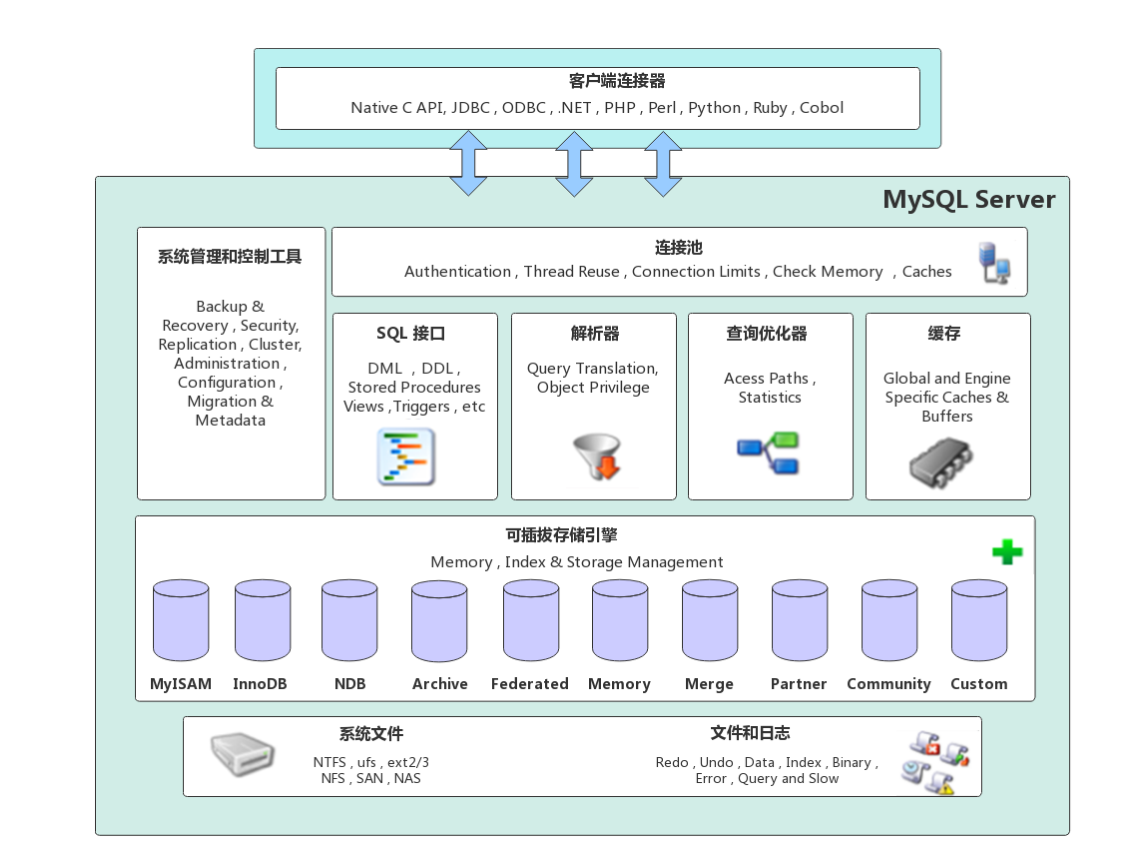
- 客户端连接器
提供与MySQL服务器建立的支持。目前几乎支持所有主流的服务端编程技术,例如常见的 Java、C、Python、.NET等,它们通过各自API技术与MySQL建立连接
- 连接池
负责存储和管理客户端与数据库的连接,一个线程负责管理一个连接。
- 系统管理和控制工具
例如备份恢复、安全管理、集群管理等
- SQL接口
用于接受客户端发送的各种SQL命令,并返回用户需要查询的结果。比如DML、DDL、存储过程、视图、触发器等。
- 解析器
负责将请求的SQL解析生成一个“解析树”。然后根据一些MySQL规则进一步检查解析树是否合法。
- 查询优化器
当“解析树”通过解析器语法检查后,将交由优化器将其转为执行计划,然后与存储引擎交互
- 缓存
缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,权限缓存,引擎缓存等。如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据
- 存储引擎
存储引擎负责MySQL中数据的存储和提取,与底层系统文件进行交互。MySQL存储引擎是插件式的,服务器中的查询执行引擎通过接口与存储引擎进行通信,接口屏蔽了不同存储引擎之间的差异。现在有很多存储引擎,各有各的特点,最常见的是MyISAM和InnoDB。
- 系统文件
该层负责将数据库的数据和日志存储在文件系统之上,并完成与存储引擎的交互,是文件的物理存储层。主要包含日志文件、数据文件、配置文件、pid文件、socket文件等。
MySQL运行机制
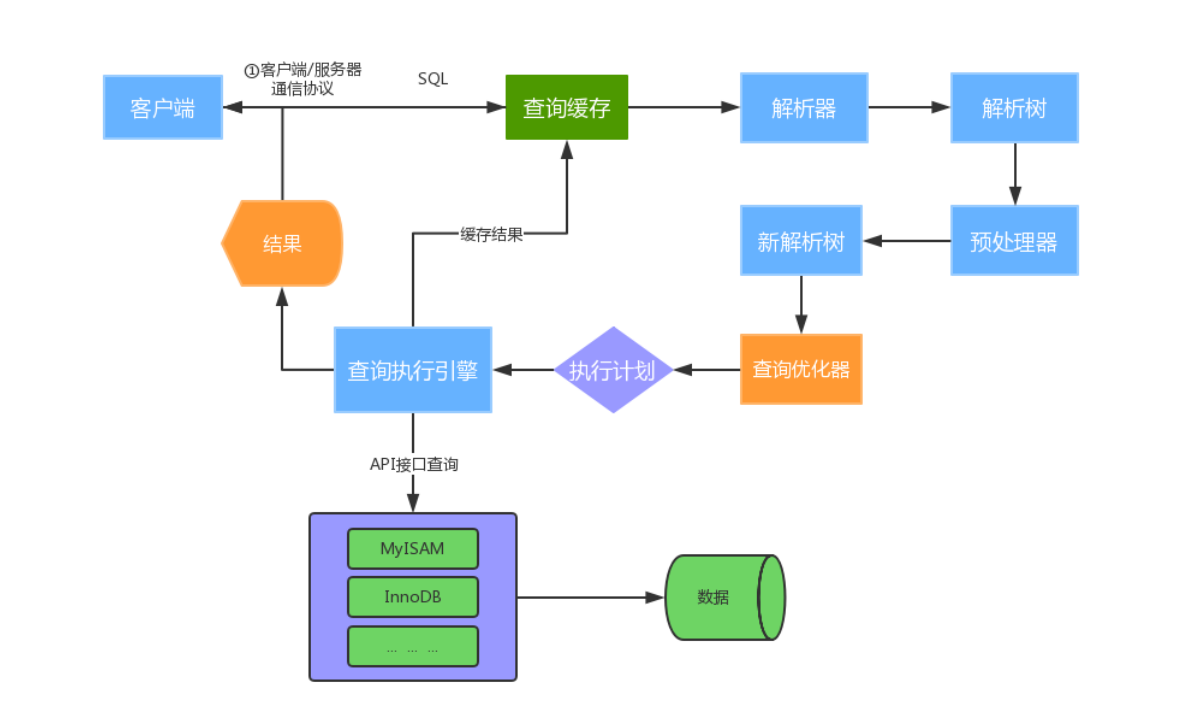
- 建立连接,MySQL客户端与服务端的通信方式是半双工。
全双工:能够同时发送和接收数据。例如平时打电话
半双工:指的某一时刻,要么发送数据,要么接收数据,不能同时。例如早期对讲机
单工:只能发送数据或只能接收数据。例如单行道
查询缓存,如果开启了查询缓存并且在查询缓存过程中查询到完全相同的SQL语句,则将查询结果直接返回客户端
解析器,解析器将客户端发送的SQL进行语法解析,生成“解析树”。预处理器根据一些MySQL规则进一步检查“解析树”是否合法,例如这里将检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义,最后生成新的“解析树”。
查询优化器,根据“解析树”生成最优的执行计划。MySQL试用很多优化策略生成最优的执行计划,可以分为两类:静态优化(编译时优化)、动态优化(运行时优化)
- 等级变换策略
- a < b and a = 5 改为 b>5 and a=5
- 基于联合索引,调整条件位置等
- 优化count、max、min等函数
- innoDB引擎min函数只需要找索引最左边,max找索引最右边。
- MyISAM引擎count(*)不需要计算,直接返回
- 提前终止查询,使用了limit查询,获取到所需的数据就返回
- in的优化,MySQL对in的查询,会先进行排序,再采用二分法查找数据
- 查询引擎,查询引擎负责执行SQL语句,此时查询执行引擎会根据 SQL 语句中表的存储引擎类型,以及对应的API接口与底层存储引擎缓存或者物理文件的交互,得到查询结果并返回给客户端。若开启用查询缓存,这时会将SQL语句和结果完整地保存到查询缓存(Cache&Buffer)中,以后若有相同的 SQL语句执行则直接返回结果。
- 如果开启了查询缓存,先将查询结果做缓存操作
- 返回结果过多,采用增量模式返回
MySQL存储引擎
存储引擎负责MySQL中的数据的存储和提取,是与文件打交道的子系统,它是根据MySQL提供的文件访问层抽象接口定制的一种文件访问机制,这种机制叫做存储引擎。
通过SHOW ENGINES命令,可以查看当前数据库支持的引擎信息。
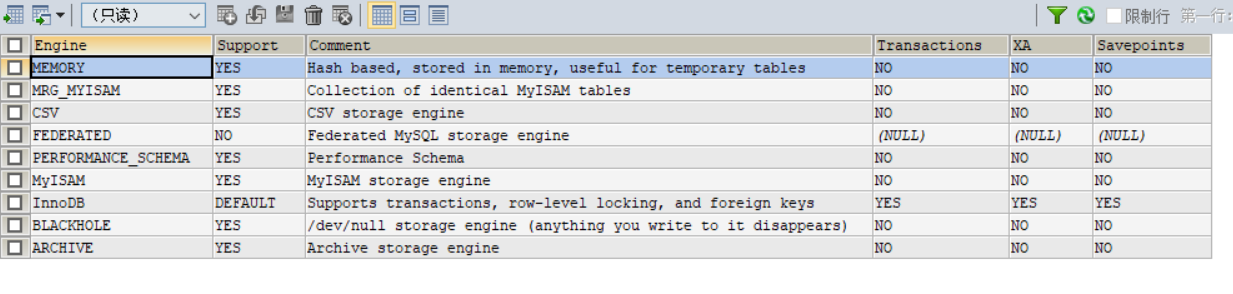
在5.5版本之前默认采用MyISAM存储引擎,从5.5开始采用InnoDB存储引擎。
- InnoDB:支持事务,具有提交,回滚和崩溃恢复能力,事务安全
- MyISAM:不支持事务和外键,访问速度快
- Memory:利用内存创建表,访问速度非常快,因为数据在内存,而且默认使用Hash索引,但是一旦关闭,数据就会丢失
- Archive:归档类型引擎,仅能支持insert和select语句
- Csv:以CSV文件进行数据存储,由于文件限制,所有列必须强制指定not null,另外CSV引擎也不支持索引和分区,适合做数据交换的中间表
- BlackHole: 黑洞,只进不出,进来消失,所有插入数据都不会保存
- Federated:可以访问远端MySQL数据库中的表。一个本地表,不保存数据,访问远程表内容。
- MRG_MyISAM:一组MyISAM表的组合,这些MyISAM表必须结构相同,Merge表本身没有数据,对Merge操作可以对一组MyISAM表进行操作。
InnoDB和MyISAM对比
- 事务和外键
InnoDB支持事务和外键,具有安全性和完整性,适合大量insert或update操作
MyISAM不支持事务和外键,它提供高速存储和检索,适合大量的select查询操作
- 锁机制
InnoDB支持行级锁,锁定指定记录。基于索引来加锁实现
MyISAM支持表级锁,锁定整张表
- 索引结构
InnoDB主键使用了聚集索引,索引和记录在一起存储,既缓存索引,也缓存记录。
MyISAM使用非聚集索引,索引和记录分开,有单独的数据文件
- 并发处理能力
MyISAM使用表锁,写操作并发低
InnoDB读写阻塞可以与隔离级别有关,可以采用MVCC(多版本并发控制)来支持高并发
- 存储文件
InnoDB表对应两个文件,一个.frm表结构文件,一个.ibd数据文件。InnoDB最大支持64TB;
MyISAM表对应三个文件,一个.frm表结构文件,一个MYD表数据文件,一个.MYI索引文件。从MySQL5.0开始默认限制是256TB
InnoDB存储结构
下面是InnoDB引擎架构图,主要分为++内存结构++和++磁盘结构++两大部分。
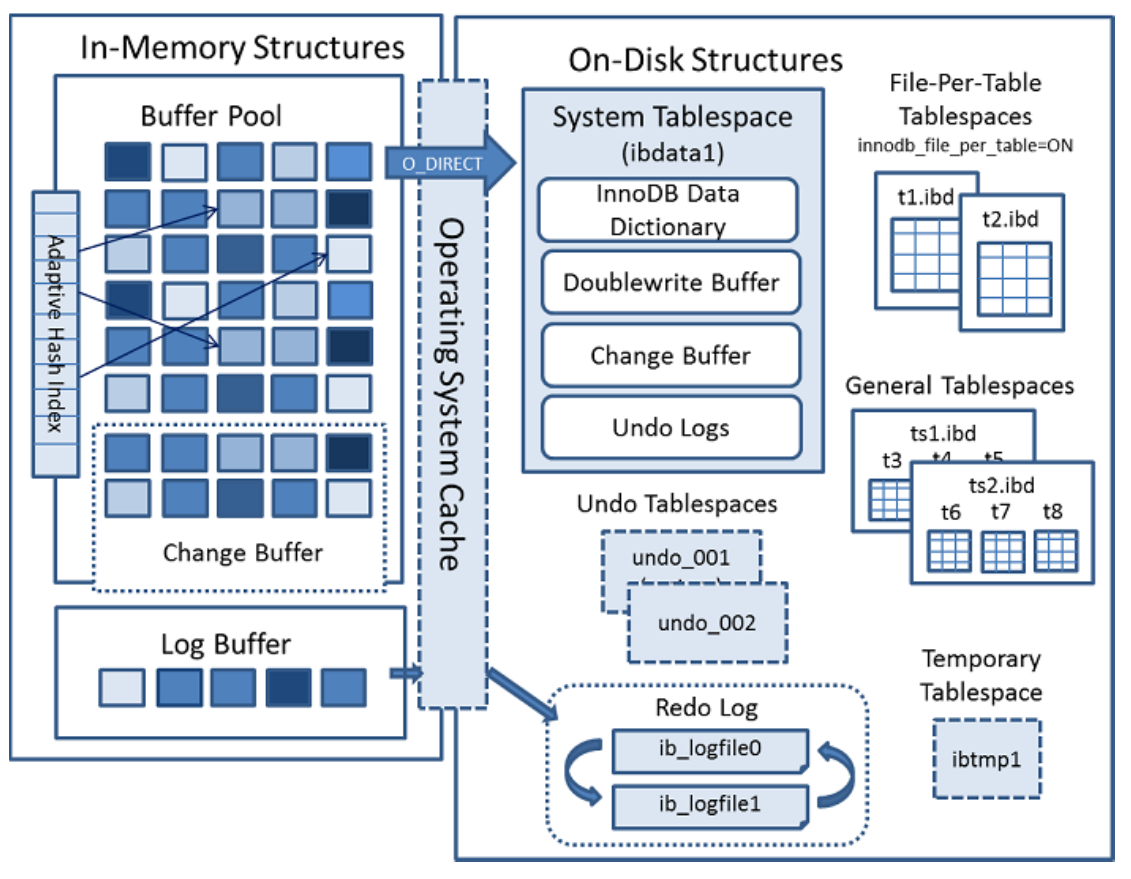
内存结构
内存结构主要包括Buffer Pool、Change Buffer、Adaptive Hash Index和Log Buffer四大组件。
- Buffer Pool:缓冲池,简称BP。BP以Page页为单位,默认大小16K,BP的底层采用链表数据结构管理Page。在InnoDB访问表记录和索引时会在Page页中缓存,以后使用可以减少磁盘IO操作,提升效率。
Page管理机制,Page根据状态可以分为三种类型:
free page :空闲page,未被使用
clean page:被使用page,数据没有被修改过
dirty page:脏页,被使用page,数据被修改过,页中数据和磁盘的数据产生了不一致
针对上述三种page类型,InnoDB通过三种链表结构来维护和管理
free list :表示空闲缓冲区,管理free page
flush list:表示需要刷新到磁盘的缓冲区,管理dirty page,内部page按修改时间排序。脏页既存在于flush链表,也在LRU链表中,但是两种互不影响,LRU链表负责管理page的可用性和释放,而flush链表负责管理脏页的刷盘操作。
lru list:表示正在使用的缓冲区,管理clean page和dirty page,缓冲区以midpoint为基点,前面链表称为new列表区,存放经常访问的数据,占63%;后面的链表称为old列表区,存放使用较少数据,占37%。
改进型LRU算法维护
普通LRU:末尾淘汰法,新数据从链表头部加入,释放空间时从末尾淘汰
改性LRU:链表分为new和old两个部分,加入元素时并不是从表头插入,而是从中间midpoint位置插入,如果数据很快被访问,那么page就会向new列表头部移动,如果数据没有被访问,会逐步向old尾部移动,等待淘汰。每当有新的page数据读取到buffer pool时,InnoDb引擎会判断是否有空闲页,是否足够,如果有就将free page从free list列表删除,放入到LRU列表中。没有空闲页,就会根据LRU算法淘汰LRU链表默认的页,将内存空间释放分配给新的页。Buffer Pool配置参数
show variables like '%innodb_page_size%'; //查看page页大小
show variables like '%innodb_old%'; //查看lru list中old列表参数
show variables like '%innodb_buffer%'; //查看buffer pool参数
建议:将innodb_buffer_pool_size设置为总内存大小的60%-80%,
innodb_buffer_pool_instances可以设置为多个,这样可以避免缓存争夺。
- Change Buffer:写缓冲区,简称CB。在进行DML操作时,如果BP没有其相应的Page数据,并不会立刻将磁盘页加载到缓冲池,而是在CB记录缓冲变更,等未来数据被读取时,再将数据合并恢复到BP中。
ChangeBuffer占用BufferPool空间,默认占25%,最大允许占50%,可以根据读写业务量来进行调整。参数innodb_change_buffer_max_size;
3. Adaptive Hash Index:自适应哈希索引,用于优化对BP数据的查询。InnoDB存储引擎会监控对表索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应。InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。
4. Log Buffer:日志缓冲区,用来保存要写入磁盘上log文件(Redo/Undo)的数据,日志缓冲区的内容定期刷新到磁盘log文件中。日志缓冲区满时会自动将其刷新到磁盘,当遇到BLOB或多行更新的大事务操作时,增加日志缓冲区可以节省磁盘I/O。
LogBuffer主要是用于记录InnoDB引擎日志,在DML操作时会产生Redo和Undo日志。
磁盘结构
InnoDB磁盘主要包含Tablespaces,InnoDB Data Dictionary,Doublewrite Buffer、Redo Log和Undo Logs
表空间(Tablespaces):用于存储表结构和数据。表空间又分为系统表空间、独立表空间、通用表空间、临时表空间、Undo表空间等多种类型;
数据字典(InnoDB Data Dictionary)
InnoDB数据字典由内部系统表组成,这些表包含用于查找表、索引和表字段等对象的元数据。元数据物理上位于InnoDB系统表空间中。由于历史原因,数据字典元数据在一定程度上与InnoDB表元数据文件(.frm文件)中存储的信息重叠
- 双写缓冲区(Doublewrite Buffer)
位于系统表空间,是一个存储区域。在BufferPage的page页刷新到磁盘真正的位置前,会先将数据存在Doublewrite缓冲区。如果在page页写入过程中出现操作系统、存储子系统或mysqld进程崩溃,InnoDB可以在崩溃恢复期间从Doublewrite 缓冲区中找到页面的一个好备份。在大多数情况下,默认情况下启用双写缓冲区,要禁用Doublewrite缓冲区,可以将innodb_doublewrite设置为0。使用Doublewrite缓冲区时建议将innodb_flush_method设置为O_DIRECT
MySQL的innodb_flush_method这个参数控制着innodb数据文件及redo log的打开、刷写模式。有三个值:fdatasync(默认),O_DSYNC,O_DIRECT。设置O_DIRECT表示数据文件写入操作会通知操作系统不要缓存数据,也不要用预读,直接从Innodb Buffer写到磁盘文件。
- 重做日志(Redo Log)
重做日志是一种基于磁盘的数据结构,用于在崩溃恢复期间更正不完整事务写入的数据。
MySQL以循环方式写入重做日志文件,记录InnoDB中所有对Buffer Pool修改的日志。当出现实例故障(像断电),导致数据未能更新到数据文件,则数据库重启时根据Redo Log重新把数据更新到数据文件。读写事务在执行的过程中,都会不断的产生redo log。默认情况下,重做日志在磁盘上由两个名为ib_logfile0和ib_logfile1的文件物理表示
- 撤销日志(Undo Log)
撤消日志是在事务开始之前保存的被修改数据的备份,用于例外情况时回滚事务。撤消日志属于逻辑日志,根据每行记录进行记录。撤消日志存在于系统表空间、撤消表空间和临时表空间中。
InnoDB线程模型
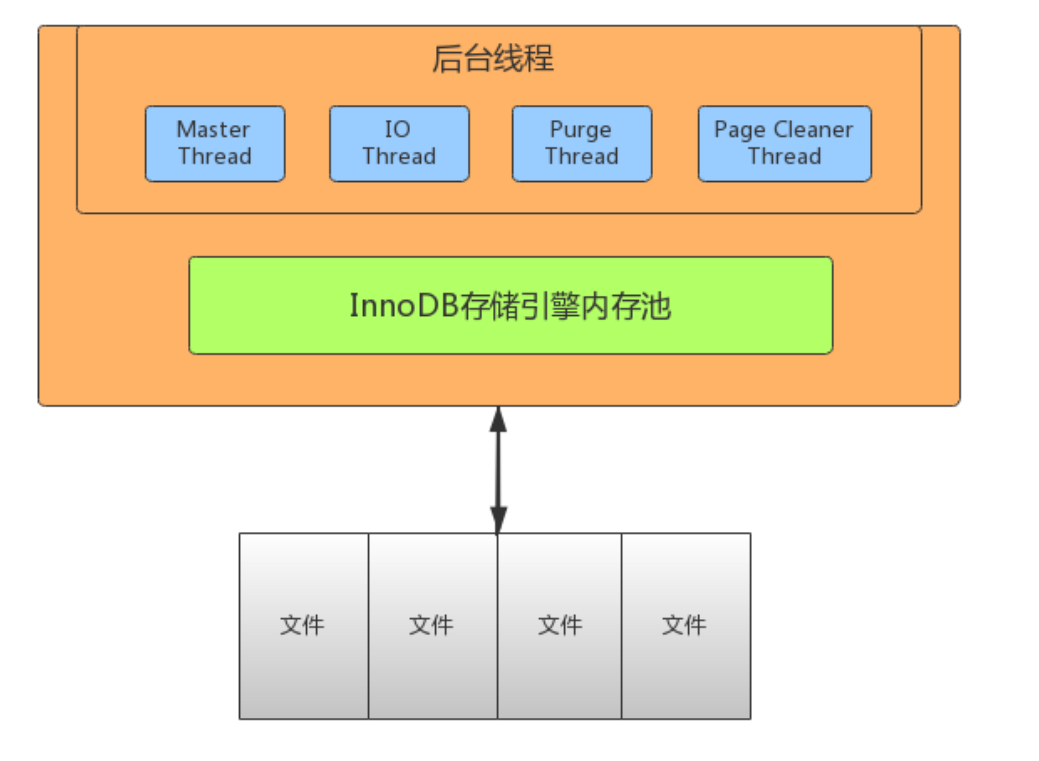
- Master Thread
Master Thread是InnoDB的主线程,负责调度其他线程,优先级最高。作用是将缓冲池中的数据异步刷新到磁盘,保证数据的一致性。包含:脏页的刷新(page cleaner thread)、undo页回收(purge thread)、redo日志刷新(log thread)、合并写缓冲等。
- IO Thread
在InnoDB中使用了大量的AIO来做读写处理,这样可以极大提高数据库的性能。一共10个线程。
- read thread : 负责读取操作,将数据从磁盘加载到缓存page页。4个
- write thread:负责写操作,将缓存脏页刷新到磁盘。4个
- log thread:负责将日志缓冲区内容刷新到磁盘。1个
- insert buffer thread :负责将写缓冲内容刷新到磁盘。1个
- Purge Thread
事务提交之后,其使用的undo日志将不再需要,因此需要Purge Thread回收已经分配的undo页。
- Page Cleaner Thread
作用是将脏数据刷新到磁盘,脏数据刷盘后相应的redo log也就可以覆盖,即可以同步数据,又能达到redo log循环使用的目的。会调用write thread线程处理。
InnoDB数据文件
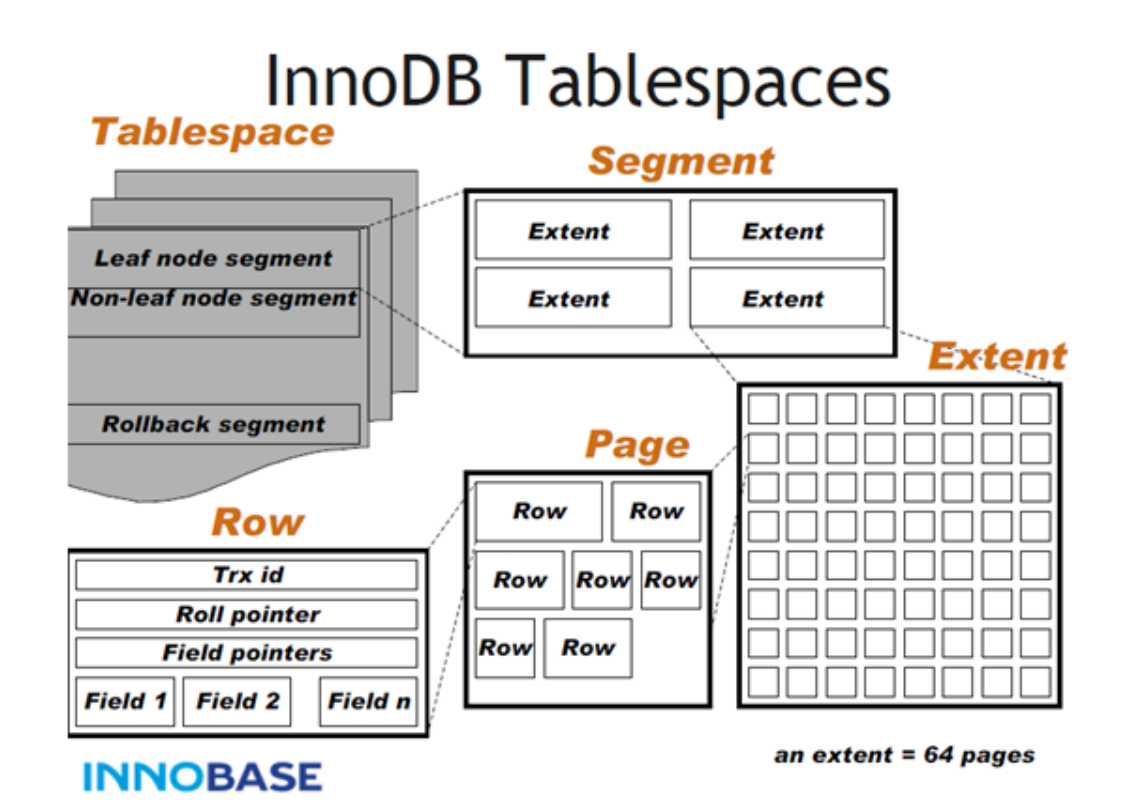
InnoDB数据文件存储结构分为一个ibd数据文件-->Segment(段)-->Extent(区)-->Page(页)-->Row(行)
- Tablesapce
表空间,用于存储多个ibd数据文件,用于存储表的记录和索引。一个文件包含多个段。
- Segment
段,用于管理多个Extent,分为数据段、索引段、回滚段。一个表至少有两个segment,一个管理索引,一个管理数据。
- Extent
区,一个区固定包含64个连续的页,大小为1M。当表空间不足,需要分配新的页资源,不会一页页的分,直接分配一个区
- Page
页,用于存储多个Row行记录,大小为16K。包含很多种页类型,比如数据页、undo页、系统页、事务数据页、大的BLOB对象页。
- Row
行,包含了记录的字段值、事务ID、回滚指针、字段指针等信息。
Undo Log、Redo Log和Binlog
- Undo Log(撤销日志)
数据库事务开始前,会将要修改的记录放到Undo日志里,当事务要回滚或数据库崩溃时,撤销对未提交的事务对数据库产生的影响。
Undo Log产生和销毁:Undo Log在事务开始前产生;事务在提交时,并不会立刻删除Undo log,innodb会将该事务对应的Undo log放入到删除列表中,后面会通过后台线程purge thread进行回收处理。Undo Log属于逻辑日志,记录一个变化过程。例如执行一个delete,undolog会记录一个insert;执行一个update,undolog会记录一个相反的update。
show variables like '%innodb_undo%';
Undo Log的作用:
- 实现事务的原子性。事务处理中,如果出现了错误或用户执行了Roll Back语句,MySQL可以利用Undo Log中的备份将数据恢复到事务开始前的状态
- 实现多版本并发控制(MVCC)
- Redo Log(重做日志)
事务中修改的任何数据,将最新的数据备份存储到Redo Log里。Redo Log 是为了实现事务的持久性而出现的产物。防止在发生故障的时间点,尚有脏页未写入表的IBD文件中,在重启MySQL服务的时候,根据 Redo Log进行重做,将未入磁盘数据进行持久化。
Redo Log 的生成和释放:随着事务操作的执行,就会生成Redo Log,在事务提交时会将产生Redo Log写入Log Buffer,并不是随着事务的提交就立刻写入磁盘文件。等事务操作的脏页写入到磁盘之后,Redo Log 的使命也就完成了,Redo Log占用的空间就可以重用(被覆盖写入)
Redo Buffer 持久化到 Redo Log 的策略,可通过Innodb_flush_log_at_trx_commit 设置:
- 0:每秒提交 Redo buffer ->OS cache -> flush cache to disk,可能丢失一秒内的事务数据。由后台Master线程每隔1秒执行一次操作。
- 1(默认值):每次事务提交执行 Redo Buffer -> OS cache -> flush cache to disk,最安全,性能最差的方式。
- 2:每次事务提交执行 Redo Buffer -> OS cache,然后由后台Master线程再每隔1秒执行OS cache -> flush cache to disk的操作。
一般建议选择取值2,因为 MySQL挂了数据没有损失,整个服务器挂了才会损失1秒的事务提交数据。
3. Binlog(Binary log(二进制日志))
BinLog和上面的两种日志不同,他说属于Mysql Server的日志,不是InnoDb引擎特有的。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志。不会记录select这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。开启Binlog日志有以下两个最重要的使用场景。
- 主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
- 数据恢复:通过mysqlbinlog工具来恢复数据。
Binlog文件名默认为“主机名_binlog-序列号”格式,例如oak_binlog-000001,也可以在配置文件中指定名称。文件记录模式有STATEMENT、ROW和MIXED三种,具体含义如下:
- ROW(row-based replication,RBR):日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
- 优点:能清楚记录每一个数据的修改细节,实现主从完全的同步和数据恢复
- 批量的操作会产生大量日志,如:alter table
- STATMENT(statement-based replication,SBR):每一条被修改数据的SQL都会记录到master的Binlog中,slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL再次执行。简称SQL语句复制
- 优点:日志量少,减少磁盘IO
- 缺点:在某些情况下会导致主从数据不一致,如last_insert_id()、now()等函数的执行。
- MIXED(mixed-based replication,MBR):以上两种模式的混合使用,一般会使用STATEMENT模式保存Binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存Binlog,MySQL会根据执行的SQL语句选择写入模式。
Binlog文件操作命令
- Binlog状态查看
SHOW VARIABLES LIKE 'log_bin';
- 开启Binlog
需要修改my.cnf或my.ini配置文件,在[mysqld]下面增加log_bin=mysql_bin_log,重启MySQL服务。
- 使用show binlog events命令
show binary logs; //等价于show master logs;
show master status;
show binlog events;
show binlog events in 'mysqlbinlog.000001';
- mysqlbinlog命令
mysqlbinlog "文件名"
mysqlbinlog "文件名" > "test.sql"
- binlog数据恢复
mysqldump:定期全部备份数据库数据。mysqlbinlog可以做增量备份和恢复操作。
//按指定时间恢复
mysqlbinlog --start-datetime="2020-04-25 18:00:00" --stop-
datetime="2020-04-26 00:00:00" mysqlbinlog.000002 | mysql -uroot -p1234
//按事件位置号恢复
mysqlbinlog --start-position=154 --stop-position=957 mysqlbinlog.000002
| mysql -uroot -p1234
- 删除binlog文件
purge binary logs to 'mysqlbinlog.000001'; //删除指定文件
purge binary logs before '2020-04-28 00:00:00'; //删除指定时间之前的文件
reset master; //清除所有文件
可以通过设置expire_logs_days参数来启动自动清理功能。默认值为0表示没启用。设置为1表示超出1天binlog文件会自动删除掉。
Redo Log和Binlog的区别
- Redo Log是属于InnoDB引擎的;Binlog属于MySQL Server自带的功能
- Redo Log属于物理日志,记录的是“在某个数据页上做了什么修改”;Binlog是记录的这个语句的原始逻辑,比如“给某个行的某字段+1”
- Redo Log是日志循环写,日志空间大小是固定的;Binlog是追加写入,不会覆盖使用
- Redo Log作为服务器异常宕机后事务数据自动恢复使用;Binlog可以作为主从复制和数据恢复使用。
MySQL数据存储的更多相关文章
- Web自动化框架之五一套完整demo的点点滴滴(excel功能案例参数化+业务功能分层设计+mysql数据存储封装+截图+日志+测试报告+对接缺陷管理系统+自动编译部署环境+自动验证false、error案例)
标题很大,想说的很多,不知道从那开始~~直接步入正题吧 个人也是由于公司的人员的现状和项目的特殊情况,今年年中后开始折腾web自动化这块:整这个原因很简单,就是想能让自己偷点懒.也让减轻一点同事的苦力 ...
- 修改mysql数据存储的地址
修改mysql数据存储的地址 修改步骤如下 1,修改前为默认路径/var/lib/mysql/,计划修改为/data/mysql/data mysql> show variables like ...
- 修改mysql数据存储位置
停止mysql服务. 在mysql安装目录下找到mysql配置文件my.ini. 在my.ini中找到mysql数据存储位置配置datadir选项,比如我电脑上的配置如下: # Path to the ...
- 使用logstash拉取MySQL数据存储到es中的再次操作
使用情况说明: 已经使用logstash拉取MySQL数据存储到es中,es中也创建了相应的索引,也存储了数据.假若把这个索引给删除了,再次进行同步操作的话要咋做,从最开始的数据进行同步,而不是新增的 ...
- 冰河,能不能讲讲如何实现MySQL数据存储的无限扩容?
写在前面 随着互联网的高速发展,企业中沉淀的数据也越来越多,这就对数据存储层的扩展性要求越来越高.当今互联网企业中,大部分企业使用的是MySQL来存储关系型数据.如何实现MySQL数据存储层的高度可扩 ...
- centos mysql 数据存储目录安装位置
rpm -ql mysql查看安装位置 MYSQL默认的数据文件存储目录为/var/lib/mysql.假如要把目录移到/home/data下需要进行下面几步: 1.home目录下建立data目录 c ...
- 更改mysql数据存储路径
1.检查mysql数据库存放目录 mysql -u root -prootadmin show variables like '%dir%'; quit; (查看datadir 那一行所指的路径) 2 ...
- mysql 数据存储引擎区别
一,存储类型 二 , MyISAM默认存储引擎 MyISAM 管理非事务表.是ISAM 的扩展格式.除了提供ISAM里所没有的索引的字段管理等的大量功能.MyISAM 还使用一种表格锁定的机制.来优化 ...
- linux 更改mysql 数据存储目录
https://www.cnblogs.com/hellangels333/p/8376177.html 参考位博主的文章,稍做改动 1.检查mysql数据库存放目录 mysql -u root - ...
随机推荐
- STL基本用法的一些记录
迭代器 (set类型)::iterator 就是迭代器 迭代器可以看成stl容器内元素的指针 set 默认从小到大排序 begin() set中最小的元素的迭代器 end() set中最大的元素的迭代 ...
- 有限差分法(Finite Difference Method)解方程:边界和内部结点的控制方程
FDM解常微分方程 问题描述 \[\frac{d^2\phi}{dx^2}=S_{\phi} \tag{1} \] 这是二阶常微分方程(second-order Ordinary Differenti ...
- 面向对象编程(C++篇4)——RAII
目录 1. 概述 2. 详论 2.1. 堆.栈.静态区 2.2. 手动管理资源的弊端 2.3. 间接使用 2.4. 自下而上的抽象 3. 总结 4. 参考 1. 概述 在前面两篇文章<面向对象编 ...
- 【VNCTF2022】Reverse wp
babymaze 反编译源码 pyc文件,uncompy6撸不出来,看字节码 import marshal, dis fp = open(r"BabyMaze.pyc", 'rb' ...
- 【flareon6】 overlong-通过动调改内存修改程序
程序分析 无壳,32位程序 运行后结果 程序比较简单一共三个函数 根据题目和运行结果可以看出来是a3太小了,没法完全解密密钥 解决该问题可以通过写脚本或动调解决 方法一:动调改内存 定位到a3入栈的位 ...
- idea如何打包项目,部署到linux后台运行
服务器安装tomcat 上传好tomcat包 scp -r tomcat liwwww@111116.11222.101121.12111111:/opt/ linux下启动tomcat服务的命令 ...
- 转载:平衡二叉树(AVL Tree)
平衡二叉树(AVL Tree) 转载至:https://www.cnblogs.com/jielongAI/p/9565776.html 在学习算法的过程中,二叉平衡树是一定会碰到的,这篇博文尽可能简 ...
- Redis 常见性能问题和解决方案?
1.Master 最好不要写内存快照,如果 Master 写内存快照,save 命令调度 rdbSave 函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性 暂停服务 2.如果数据 ...
- Java 面试问题列表包含的主题?
多线程,并发及线程基础 数据类型转换的基本原则 垃圾回收(GC) Java 集合框架 数组 字符串 GOF 设计模式 SOLID 抽象类与接口 Java 基础,如 equals 和 hashcode ...
- c的free 为什么不需要知道大小
malloc malloc函数在运行时分配内存.它需要以字节为单位的大小并在内存中分配那么多空间.这意味着malloc(50)将在内存中分配50个字节.它返回一个void指针 calloc 与mall ...