Apache Hudi 如何加速传统的批处理模式?
1. 现状说明
1.1 数据湖摄取和计算过程 - 处理更新
在我们的用例中1-10% 是对历史记录的更新。当记录更新时,我们需要从之前的 updated_date 分区中删除之前的条目,并将条目添加到最新的分区中,在没有删除和更新功能的情况下,我们必须重新读取整个历史表分区 -> 去重数据 -> 用新的去重数据覆盖整个表分区
1.2 当前批处理过程中的挑战
这个过程有效,但也有其自身的缺陷:
- 时间和成本——每天都需要覆盖整个历史表
- 数据版本控制——没有开箱即用的数据和清单版本控制(回滚、并发读取和写入、时间点查询、时间旅行以及相关功能不存在)
- 写入放大——日常历史数据覆盖场景中的外部(或自我管理)数据版本控制增加了写入放大,从而占用更多的 S3 存储
借助Apache Hudi,我们希望在将数据摄取到数据湖中的同时,找到更好的重复数据删除和数据版本控制优化解决方案。
2. Hudi 数据湖 — 查询模式
当我们开始在我们的数据湖上实现 Apache Hudi 的旅程时,我们根据表的主要用户的查询模式将表分为 2 类。
- 面向ETL :这是指我们从各种生产系统摄取到数据湖中的大多数原始/基本快照表。 如果这些表被 ETL 作业广泛使用,那么我们将每日数据分区保持在 updated_date,这样下游作业可以简单地读取最新的 updated_at 分区并(重新)处理数据。
- 面向分析师:通常包括维度表和业务分析师查询的大部分计算 OLAP,分析师通常需要查看基于事务(或事件)created_date 的数据,而不太关心 updated_date。
这是一个示例电子商务订单数据流,从摄取到数据湖到创建 OLAP,最后到业务分析师查询它
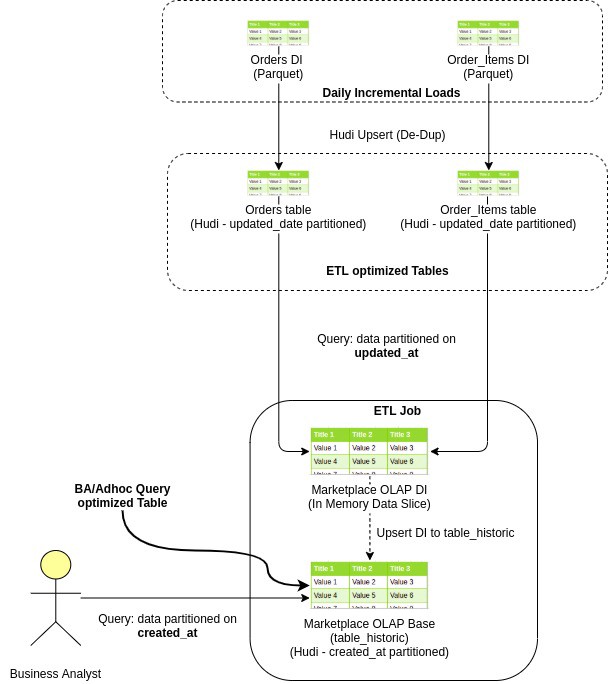
由于两种类型的表的日期分区列不同,我们采用不同的策略来解决这两个用例。
2.1 面向分析师的表/OLAP(按 created_date 分区)
在 Hudi 中,我们需要指定分区列和主键列,以便 Hudi 可以为我们处理更新和删除。
以下是我们如何处理面向分析师的表中的更新和删除的逻辑:
- 读取上游数据的 D-n 个 updated_date 分区。
- 应用数据转换。 现在这个数据将只有新的插入和很少的更新记录。
- 发出 hudi upsert 操作,将处理后的数据 upsert 到目标 Hudi 表。
由于主键和 created_date 对于退出和传入记录保持相同,Hudi 通过使用来自传入记录 created_date 和 primary_key 列的此信息获取现有记录的分区和分区文件路径。
2.2 面向ETL(按更新日期分区)
当我们开始使用 Hudi 时,在阅读了许多博客和文档之后,在 created_date 上对面向 ETL 的表进行分区似乎是合乎逻辑的。
此外 Hudi 提供增量消费功能,允许我们在 created_date 上对表进行分区,并仅获取在 D-1 或 D-n 上插入(插入或更新)的那些记录。
1. “created_date”分区的挑战
这种方法在理论上效果很好,但在改造传统的日常批处理过程中的增量消费时,它带来了其他一系列挑战:
Hudi 维护了在不同时刻在表上执行的所有操作的时间表,这些提交包含有关作为 upsert 的一部分插入或重写的部分文件的信息,我们将此 Hudi 表称为 Commit Timeline。
这里要注意的重要信息是增量查询基于提交时间线,而不依赖于数据记录中存在的实际更新/创建日期信息。
- 冷启动:当我们将现有的上游表迁移到 Hudi 时,D-1 Hudi 增量查询将获取完整的表,而不仅仅是 D-1 更新。发生这种情况是因为在开始时,整个表是通过在 D-1 提交时间线内发生的单个初始提交或多个提交创建的,并且缺少真正的增量提交信息。
- 历史数据重新摄取:在每个常规增量 D-1 拉取中,我们期望仅在 D-1 上更新的记录作为输出。但是在重新摄取历史数据的情况下,会再次出现类似于前面描述的冷启动问题的问题,并且下游作业也会出现 OOM。
作为面向 ETL 的作业的解决方法,我们尝试将数据分区保持在 updated_date 本身,然而这种方法也有其自身的挑战。
2. “updated_date”分区的挑战
我们知道 Hudi 表的本地索引,Hudi 依靠索引来获取存储在数据分区本地目录中的 Row-to-Part_file 映射。因此,如果我们的表在 updated_date 进行分区,Hudi 无法跨分区自动删除重复记录。
Hudi 的全局索引策略要求我们保留一个内部或外部索引来维护跨分区的数据去重。对于大数据量,每天大约 2 亿条记录,这种方法要么运行缓慢,要么因 OOM 而失败。
因此,为了解决更新日期分区的数据重复挑战,我们提出了一种全新的重复数据删除策略,该策略也具有很高的性能。
3. “新”重复数据删除策略
- 查找更新 - 从每日增量负载中,仅过滤掉更新(1-10% 的 DI 数据)(其中 updated_date> created_date)(快速,仅映射操作)
- 找到过时更新 - 将这些“更新”与下游 Hudi 基表广播连接。 由于我们只获取更新的记录(仅占每日增量的 1-10%),因此可以实现高性能的广播连接。 这为我们提供了与更新记录相对应的基础 Hudi 表中的所有现有记录
- 删除过时更新——在基本 Hudi 表路径上的这些“过时更新”上发出 Hudi 删除命令
- 插入 - 在基本 hudi 表路径上的完整每日增量负载上发出 hudi insert 命令
进一步优化用 true 填充陈旧更新中的 _hoodie_is_deleted 列,并将其与每日增量负载结合。 通过基本 hudi 表路径发出此数据的 upsert 命令。 它将在单个操作(和单个提交)中执行插入和删除。
4. Apache Hudi 的优势
- 时间和成本——Hudi 在重复数据删除时不会覆盖整个表。 它只是重写接收更新的部分文件。 因此较小的 upsert 工作
- 数据版本控制——Hudi 保留表版本(提交历史),因此提供实时查询(时间旅行)和表版本回滚功能。
- 写入放大——由于只有部分文件被更改并保留用于数据清单版本控制,我们不需要保留完整数据的版本。 因此整体写入放大是最小的。
作为数据版本控制的另一个好处,它解决了并发读取和写入问题,因为数据版本控制使并发读取器可以读取数据文件的版本控制副本,并且当并发写入器用新数据覆盖同一分区时不会抛出 FileNotFoundException 文件。
Apache Hudi 如何加速传统的批处理模式?的更多相关文章
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- Apache Hudi助力nClouds加速数据交付
1. 概述 在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案.但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一 ...
- 详解 Apache Hudi Schema Evolution(模式演进)
Schema Evolution(模式演进)允许用户轻松更改 Hudi 表的当前模式,以适应随时间变化的数据. 从 0.11.0 版本开始,支持 Spark SQL(spark3.1.x 和 spar ...
- 官宣!ASF官方正式宣布Apache Hudi成为顶级项目
马萨诸塞州韦克菲尔德(Wakefield,MA)- 2020年6月 - Apache软件基金会(ASF).350多个开源项目和全职开发人员.管理人员和孵化器宣布:Apache Hudi正式成为Apac ...
- 通过Apache Hudi和Alluxio建设高性能数据湖
T3出行的杨华和张永旭描述了他们数据湖架构的发展.该架构使用了众多开源技术,包括Apache Hudi和Alluxio.在本文中,您将看到我们如何使用Hudi和Alluxio将数据摄取时间缩短一半.此 ...
- Apache Hudi 设计与架构最强解读
感谢 Apache Hudi contributor:王祥虎 翻译&供稿. 欢迎关注微信公众号:ApacheHudi 本文将介绍Apache Hudi的基本概念.设计以及总体基础架构. 1.简 ...
- Apache Hudi 0.6.0版本重磅发布
1. 下载信息 源码:Apache Hudi 0.6.0 Source Release (asc, sha512) 二进制Jar包:nexus 2. 迁移指南 如果您从0.5.3以前的版本迁移至0.6 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 超级重磅!Apache Hudi多模索引对查询优化高达30倍
与许多其他事务数据系统一样,索引一直是 Apache Hudi 不可或缺的一部分,并且与普通表格式抽象不同. 在这篇博客中,我们讨论了我们如何重新构想索引并在 Apache Hudi 0.11.0 版 ...
随机推荐
- manjaro下使用scrcpy安卓设备投屏
scrcpy 安卓版本要大于等于 5.0 安装scrcpy及安卓工具包 yay -S scrcpy-git android-tools 打开手机 开发者模式->USB调试,将手机通过数据线连接电 ...
- UNIX网络编程--学习日记
今天在学习accept函数的时候,在执行服务器程序的时候,碰到了如下的出错信息: bind error: Address already in use 其原因在于服务器程序使用了13号的端口; 然而在 ...
- 整理分布式锁:业务场景&分布式锁家族&实现原理
1.引入业务场景 业务场景一出现: 因为小T刚接手项目,正在吭哧吭哧对熟悉着代码.部署架构.在看代码过程中发现,下单这块代码可能会出现问题,这可是分布式部署的,如果多个用户同时购买同一个商品,就可能导 ...
- spring-注解驱动模式
spring web装配原理: /** * WebApplicationInitializer Spring MVC 提供接口. * * Spring中的web自动配置,也是可以, */ /** * ...
- docker安装部署、fastDFS文件服务器搭建与springboot项目接口
一.docker安装部署 1.更新yum包:sudo yum update 2.安装需要的软件包,yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动 ...
- Error 和 Exception 有什么区别?
Error 表示系统级的错误和程序不必处理的异常,是恢复不是不可能但很困难的情 况下的一种严重问题:比如内存溢出,不可能指望程序能处理这样的情况: Exception 表示需要捕捉或者需要程序进行处理 ...
- hdu 1175 连连看 DFS_字节跳动笔试原题
转载至:https://www.cnblogs.com/LQBZ/p/4253962.html Problem Description "连连看"相信很多人都玩过.没玩过也没关系, ...
- synchronized使用及原理解析
修饰静态方法.实例方法.代码块 Synchronized修饰静态方法,对类对象进行加锁,是类锁. Synchronized修饰实例方法,对方法所属对象进行加锁,是对象锁. Synchronized修饰 ...
- Windows 10 安装 wordpress
如何在Windows上安装wordpress. 安装前准备: 安装并配置好Apache httpd及PHP,见<Windows10安装PHP7+Apache 2.4>. 安装好MySQL, ...
- Flask-Script使用教程
Flask使用第三方脚本 一个干净的项目准备: 一个干净的Flask项目连接地址: https://pan.baidu.com/s/123TyVXOFvh5P7V8MbyMfDg 话不多说,上菜: 1 ...