[STL] deque 双端队列
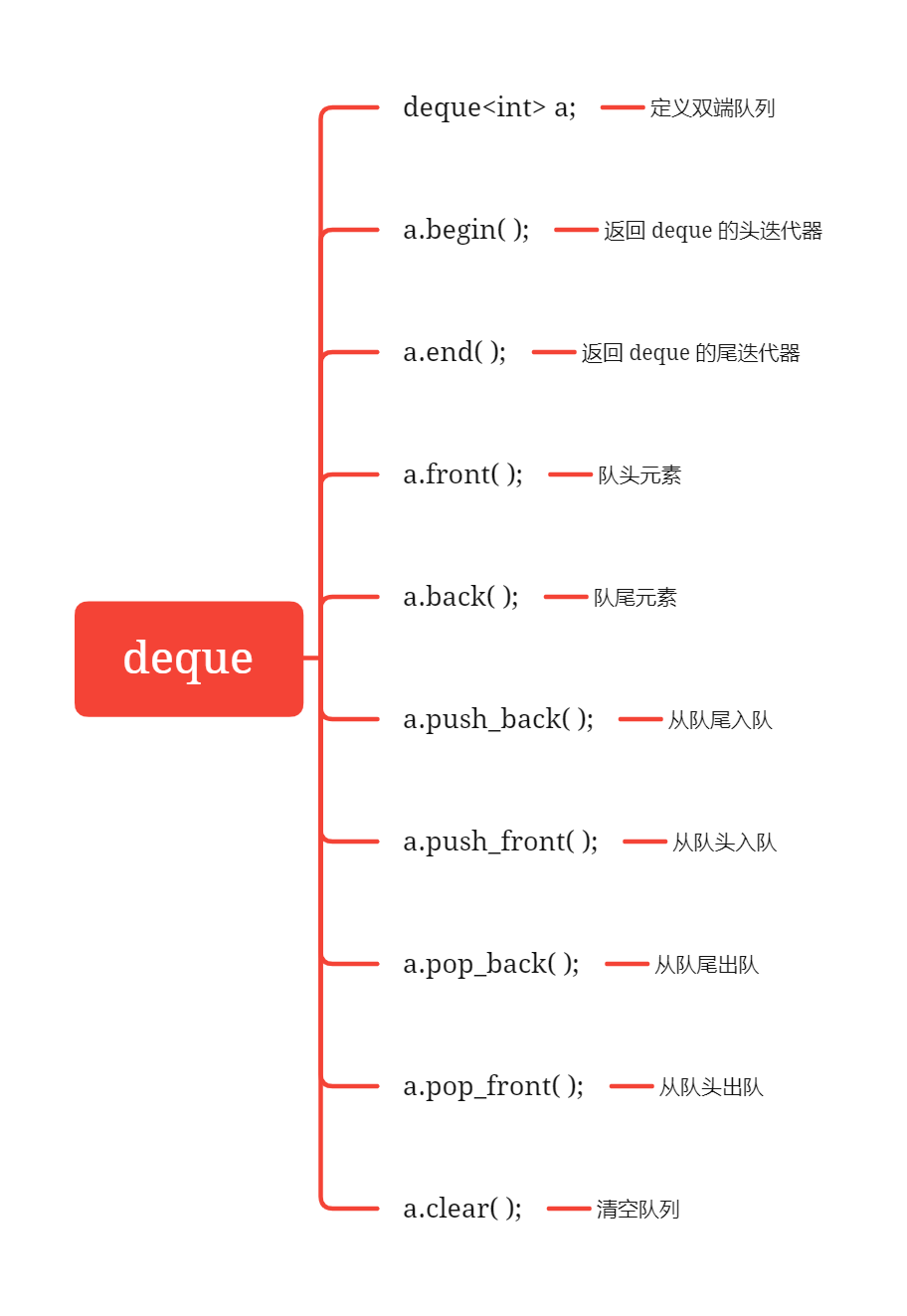
[STL] deque 双端队列的更多相关文章
- C++STL之双端队列容器
C++STL之双端队列容器 deque双端队列容器与vector很类似,采用线性表顺序存储结构.但与vector区别,deque采用分块的线性存储结构来存储数据,每块的大小一般为512B,将之称为de ...
- deque双端队列容器
//deque双端队列容器 //deque双端队列容器与vector一样,采用线性表顺序存储结构,但与vector不同的是, //deque采用的分块线性存储结构来存储数据,每块的大小一般为512字节 ...
- deque双端队列笔记
clear()clear()clear():清空队列 pushpushpush_back()back()back():从尾部插入一个元素. pushpushpush_front()front()fro ...
- stl之deque双端队列容器
deque与vector很相似,不仅能够在尾部插入和删除元素,还能够在头部插入和删除. 只是当考虑到容器元素的内存分配策略和操作性能时.deque相对vector较为有优势. 头文件 #include ...
- STL容器:deque双端队列学习
所谓deque,是"double-ended queue"的缩写; 它是一种动态数组形式,可以向两端发展,在尾部和头部插入元素非常迅速; 在中间插入元素比较费时,因为需要移动其它元 ...
- Java 集合深入理解(10):Deque 双端队列
点击查看 Java 集合框架深入理解 系列, - ( ゜- ゜)つロ 乾杯~ 什么是 Deque Deque 是 Double ended queue (双端队列) 的缩写,读音和 deck 一样,蛋 ...
- c++ deque 双端队列
双端队列: 函数 描述 c.assign(beg,end)c.assign(n,elem) 将[beg; end)区间中的数据赋值给c.将n个elem的拷贝赋值给c. c.at(idx) 传回索引 ...
- 算法-deque双端队列
Python的deque模块,它是collections库的一部分.deque实现了双端队列,意味着你可以从队列的两端加入和删除元素 1.基本介绍 # 实例化一个deque对象d = deque()d ...
- STL标准库-容器-deque 双端队列
头文件: #include<deque> 常用操作: https://www.cnblogs.com/LearningTheLoad/p/7450948.html
随机推荐
- Spring Boot 多模块项目创建与配置 (转)
转载:https://www.cnblogs.com/MaxElephant/p/8205234.html 最近在负责的是一个比较复杂项目,模块很多,代码中的二级模块就有9个,部分二级模块下面还分了多 ...
- myisamchk 是用来做什么的?
它用来压缩 MyISAM 表,这减少了磁盘或内存使用. MyISAM Static 和 MyISAM Dynamic 有什么区别? 在 MyISAM Static 上的所有字段有固定宽度.动态 MyI ...
- final, finally, finalize的区别?
final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承.内部类要访问局部变量,局部变量必须定义成final类型.finally是异常处理语句结构的一部分,表示总是执行.fin ...
- 什么是 ThreadLocal 变量?
ThreadLocal 是 Java 里一种特殊的变量.每个线程都有一个 ThreadLocal 就是每 个线程都拥有了自己独立的一个变量,竞争条件被彻底消除了.它是为创建代价 高昂的对象获取线程安全 ...
- 并发包下常见的同步工具类(CountDownLatch,CyclicBarrier,Semaphore)
在实际开发中,碰上CPU密集且执行时间非常耗时的任务,通常我们会选择将该任务进行分割,以多线程方式同时执行若干个子任务,等这些子任务都执行完后再将所得的结果进行合并.这正是著名的map-reduce思 ...
- 在多线程环境下,SimpleDateFormat 是线程安全的吗?
不是,非常不幸,DateFormat 的所有实现,包括 SimpleDateFormat 都不是 线程安全的,因此你不应该在多线程序中使用,除非是在对外线程安全的环境中 使用,如 将 SimpleDa ...
- 爬虫-数据解析-xpath
xpath 解析 模块安装 : pip install lxml xpath的解析原理 实例化一个etree类型的对象,且将页面源码数据加载到该对象中 需要调用该对象的xpath方法结合着不同形式的x ...
- 实验配置cisco单臂路由
第一步 搭建实验拓扑图 第二步 对路由器做基本配置 为路由器创建名称: 设置进入特权模式 口令:控制台登录密码:vty登录密码 禁用DNS查找: 加密明文密码: 创建一个向访问设备者发出警告的标语&q ...
- 自动驾驶运动规划-Reeds Shepp曲线
自动驾驶运动规划-Reeds Shepp曲线 相比于Dubins Car只允许车辆向前运动,Reeds Shepp Car既允许车辆向前运动,也允许车辆向后运动. Reeds Shepp Car运动规 ...
- 结合Vue.js的前端压缩图片方案
这是一个很简单的方案.嗯,是真的. 为什么要这么做? 在移动Web蓬勃发展的今天,有太多太多的应用需要让用户在移动Web上传图片文件了,正因如此,我们有些困难必须去攻克: 低网速下上传进度缓慢,用户体 ...