wordcloud + jieba 生成词云
利用jieba库和wordcloud生成中文词云。
jieba库:中文分词第三方库
分词原理:
利用中文词库,确定汉字之间的关联概率,关联概率大的生成词组
三种分词模式:
1、精确模式:把文本精确的切分开,不存在冗余单词
2、全模式:把文本中所有可能的词语都扫描出来,有冗余
3、搜索引擎模式:在精确模式基础上,对长词再次切分
常用函数:
jieba.lcut(s) #精确模式,返回列表类型的分词结果
jieba.lcut(s,cut_all=True) #全模式,返回列表类型的分词结果
jieba.lcut_for_search(s,cut_all=True) # 搜索引擎模式(精确模式后对过长的词再精确分词),返回列表类型的分词结果
jieba.add_word(w) #在参考的中文词库中添加自定义的词,如:jieba.add_word(“产生式系统”),无返回
jieba.del_word(w) #在参考的中文词库中删除词
jieba.analyse.extract_tags(sentence,topK=10) #关键词提取,返回权重最大的10个词语,返回列表类型的提取结果,注意:import jieba.analyse
wordcloud库:词云生成库
生成词云的三个步骤:
import wordcloud
#1、生成wordcloud对象,设置字体路径和其他基本属性
#除了font_path外的一些常用属性:
#词云使用的字体:font_path
#生成图片的大小:width=120,height=120
#生成词云的形状:mask(结合下面的实例解释)
#词云的背景颜色:background_color="white"
w = wordcloud.WordCloud(font_path="C:/Users/ASUS/Desktop/aaa.ttf") #2、产生词云
w.generate("春天 春天 在哪里 这里") #3、把词云输出到已创建的png、jpg文件里,可打开查看结果
w.to_file("outfile.png")
产生的词云:

安装与运行时可能遇到的问题:
1、安装:直接用命令行 pip install wordcloud 安装会产生错误 Microsoft Visual C++ 14.0 is required.
解决方法:1)点击进入pythonlib页面:https://www.lfd.uci.edu/~gohlke/pythonlibs/
2)下拉找到wordcloud包:
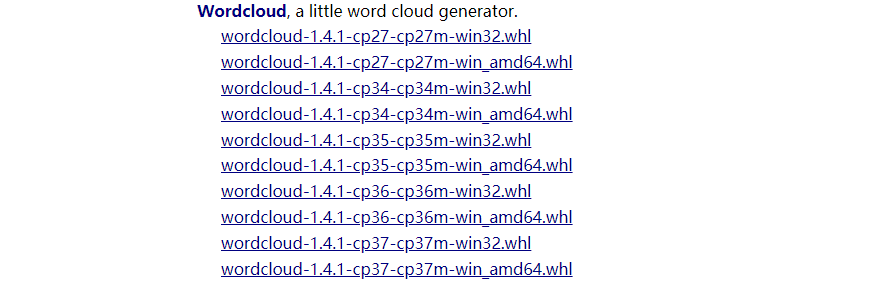
3)下载对应版本的wordcloud,存放到文件夹下
其中cp表示python版本,如36对应3.6 win为操作系统位数,32位或6位
4)再执行命令行:
pip install C:\data\wordcloud-1.4.1-cp36-cp36m-win_amd64.whl
5)安装成功
2、编译时显示 OSError: cannot open resource
解决方法:库中自带的字体文件不是中文,可以自己下载一个ttf字体文件放到对应文件夹下,
一个ttf字体文件链接: https://pan.baidu.com/s/1xJVPe1YIXN9Wl_z3fkVpFg 密码: 7iux
在生成词云时使用 wordcloud.WordCloud( font_path="C:/Users/ASUS/Desktop/returnline/aaa.ttf" )
利用jieba+wordcloud生成词云
import wordcloud
import jieba
from scipy.misc import imread #生成遮罩mask(词云的形状)
import jieba.analyse #top30关键词提取 mk=imread("0.jpg") #获得作为遮罩的图片,我的是一只蜗牛
txt = open("1.txt").read() #获得要生成词云的文本,并将内容转换为字符串
#生成词云对象,大小为120*120,遮罩是0.jpg,背景颜色是白色
w = wordcloud.WordCloud(font_path="C:/Users/ASUS/Desktop/returnline/aaa.ttf",width=120,height=120,mask=mk,background_color="white")
#jieba统计并提取权值top30的词语,返回list
ls=jieba.analyse.extract_tags(txt,topK=30)
#将list转换为元素间空格分隔的字符串,创建词云
w.generate(" ".join(ls))
#将词云导出到outfile.png
w.to_file("outfile.png")
遮罩图:

词云图:

wordcloud + jieba 生成词云的更多相关文章
- Python3+pdfminer+jieba+wordcloud+matplotlib生成词云(以深圳十三五规划纲要为例)
一.各库功能说明 pdfminer----用于读取pdf文件的内容,python3安装pdfminer3k jieba----用于中文分词 wordcloud----用于生成词云 matplotlib ...
- python爬取豆瓣流浪地球影评,生成词云
代码很简单,一看就懂. (没有模拟点击,所以都是未展开的) 地址: https://movie.douban.com/subject/26266893/reviews?rating=&star ...
- 爬虫之使用requests爬取某条标签并生成词云
一.爬虫前准备 1.工具:pychram(python3.7) 2.库:random,requests,fake-useragent,json,re,bs4,matplotlib,worldcloud ...
- python 基于 wordcloud + jieba + matplotlib 生成词云
词云 词云是啥?词云突出一个数据可视化,酷炫.以前以为很复杂,不想python已经有成熟的工具来做词云.而我们要做的就是准备关键词数据,挑一款字体,挑一张模板图片,非常非常无脑.准备好了吗,快跟我一起 ...
- 已知词频生成词云图(数据库到生成词云)--generate_from_frequencies(WordCloud)
词云图是根据词出现的频率生成词云,词的字体大小表现了其频率大小. 写在前面: 用wc.generate(text)直接生成词频的方法使用很多,所以不再赘述. 但是对于根据generate_from_f ...
- 作业练习P194,jieba应用,读取,分词,存储,生成词云,排序,保存
import jieba #第一题 txt='Python是最有意思的编程语言' words=jieba.lcut(txt) #精确分词 words_all=jieba.lcut(txt,cut_al ...
- 根据词频生成词云(Python wordcloud实现)
网上大多数词云的代码都是基于原始文本生成,这里写一个根据词频生成词云的小例子,都是基于现成的函数. 另外有个在线制作词云的网站也很不错,推荐使用:WordArt 安装词云与画图包 pip3 insta ...
- Python统计excel表格中文本的词频,生成词云图片
import xlrd import jieba import pymysql import matplotlib.pylab as plt from wordcloud import WordClo ...
- 【python3】爬取简书评论生成词云
一.起因: 昨天在简书上看到这么一篇文章<中国的父母,大都有毛病>,看完之后个人是比较认同作者的观点. 不过,翻了下评论,发现评论区争议颇大,基本两极化.好奇,想看看整体的评论是个什么样, ...
随机推荐
- swift 类型系统 Self self Type
namedClass:静态类型:与类型实现直接关联:可以用于初始化.类型检查等. namedClass.self:@thick,脱敏(脱关)类型:动态类型:可以作为元类型的实例:可以作为类型参量进行传 ...
- Linux 之WinSCP连接FTP
1.安装vsftpd 2.ftp命令 /sbin/service vsftpd start /sbin/service vsftpd restart /sbin/service vsftpd stop ...
- ADB 常用命令学习
参考文档:https://www.cnblogs.com/bravesnail/articles/5850335.html非常感谢作者的分享,以下是我学习的记录.Android 常用adb 命令汇总- ...
- 类的定义与实例化、构造函数和初始化表(day04)
十三 类的定义与实例化 类的一般形式 class/struct 类名:继承表{ 访问控制限定符: 类名(形参表):初始化表{}//构造函数 ~类名(void){}//析构函数 返回类型 函数名(形参表 ...
- UVA1339 - Ancient Cipher 【字符串+排序】【紫书例题4.1】
题意:给定两个字符串,你可以替换或者置换,替换是指可以将相同的字母替换为任意一个字母,而置换是指将字母替换为下一个,如A替换B,B替换为C,,,Z替换为A.你需要判断是否可以通过一系列操作使两个字符串 ...
- python的多版本安装以及常见错误(长期更新)
(此文长期更新)Python安装常见错误汇总 注:本教程以python3.6为基准 既然是总结安装过程中遇到的错误,就顺便记录一下我的安装过程好了. 先来列举一下安装python3.6过程中可能需要的 ...
- 批量重命名B站下载文件
将B站下载的文件统一修改文件名 事情来由 事情是这样的,我在B站上发现一个教程,看了一下,非常不错,于是想下载下来(免得B站和谐). 问题就是这样来了,我手机没多少内存,下载后下发现文件在手机中都是以 ...
- Travel Card
Travel Card time limit per test 2 seconds memory limit per test 256 megabytes input standard input o ...
- 【ACM】poj_1363_Rails_201308081502
Rails Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 21528 Accepted: 8597 Descriptio ...
- Linux去重命令uniq(转)
注意:需要先排序sort才能使用去重. Linux uniq命令用于检查及删除文本文件中重复出现的行列. uniq可检查文本文件中重复出现的行列. 语法 uniq [-cdu][-f<栏位> ...