Linear Decoders
Sparse Autoencoder Recap
In the sparse autoencoder, we had 3 layers of neurons: an input layer, a hidden layer and an output layer. In our previous description of autoencoders (and of neural networks), every neuron in the neural network used the same activation function. In these notes, we describe a modified version of the autoencoder in which some of the neurons use a different activation function. This will result in a model that is sometimes simpler to apply, and can also be more robust to variations in the parameters.
Recall that each neuron (in the output layer) computed the following:
where a(3) is the output. In the autoencoder, a(3) is our approximate reconstruction of the input x = a(1).
Because we used a sigmoid activation function for f(z(3)), we needed to constrain or scale the inputs to be in the range[0,1], since the sigmoid function outputs numbers in the range [0,1].
引入 —— 相同的activation function ,非线性映射会导致输入和输出不等
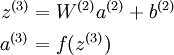
Linear Decoder
One easy fix for this problem is to set a(3) = z(3). Formally, this is achieved by having the output nodes use an activation function that's the identity function f(z) = z, so that a(3) = f(z(3)) = z(3). 输出结点不适用sigmoid 函数
This particular activation function
is called the linear activation function。Note however that in the hidden layer of the network, we still use a sigmoid (or tanh) activation function, so that the hidden unit activations are given by (say)
, where
is the sigmoid function, x is the input, and W(1) andb(1) are the weight and bias terms for the hidden units. It is only in the output layer that we use the linear activation function.
An autoencoder in this configuration--with a sigmoid (or tanh) hidden layer and a linear output layer--is called a linear decoder.
In this model, we have
. Because the output
is a now linear function of the hidden unit activations, by varying W(2), each output unit a(3) can be made to produce values greater than 1 or less than 0 as well. This allows us to train the sparse autoencoder real-valued inputs without needing to pre-scale every example to a specific range.
Since we have changed the activation function of the output units, the gradients of the output units also change. Recall that for each output unit, we had set set the error terms as follows:
where y = x is the desired output,
output结点
Of course, when using backpropagation to compute the error terms for the hidden layer:
hidden结点
Because the hidden layer is using a sigmoid (or tanh) activation f, in the equation above
should still be the derivative of the sigmoid (or tanh) function.
Linear Decoders的更多相关文章
- (六)6.16 Neurons Networks linear decoders and its implements
Sparse AutoEncoder是一个三层结构的网络,分别为输入输出与隐层,前边自编码器的描述可知,神经网络中的神经元都采用相同的激励函数,Linear Decoders 修改了自编码器的定义,对 ...
- CS229 6.16 Neurons Networks linear decoders and its implements
Sparse AutoEncoder是一个三层结构的网络,分别为输入输出与隐层,前边自编码器的描述可知,神经网络中的神经元都采用相同的激励函数,Linear Decoders 修改了自编码器的定义,对 ...
- Unsupervised Feature Learning and Deep Learning(UFLDL) Exercise 总结
7.27 暑假开始后,稍有时间,“搞完”金融项目,便开始跑跑 Deep Learning的程序 Hinton 在Nature上文章的代码 跑了3天 也没跑完 后来Debug 把batch 从200改到 ...
- Deep learning:三十八(Stacked CNN简单介绍)
http://www.cnblogs.com/tornadomeet/archive/2013/05/05/3061457.html 前言: 本节主要是来简单介绍下stacked CNN(深度卷积网络 ...
- [UFLDL] Basic Concept
博客内容取材于:http://www.cnblogs.com/tornadomeet/archive/2012/06/24/2560261.html 参考资料: UFLDL wiki UFLDL St ...
- [UFLDL] Dimensionality Reduction
博客内容取材于:http://www.cnblogs.com/tornadomeet/archive/2012/06/24/2560261.html Deep learning:三十五(用NN实现数据 ...
- Deep Learning 教程翻译
Deep Learning 教程翻译 非常激动地宣告,Stanford 教授 Andrew Ng 的 Deep Learning 教程,于今日,2013年4月8日,全部翻译成中文.这是中国屌丝军团,从 ...
- ICLR 2013 International Conference on Learning Representations深度学习论文papers
ICLR 2013 International Conference on Learning Representations May 02 - 04, 2013, Scottsdale, Arizon ...
- Deep Learning基础--线性解码器、卷积、池化
本文主要是学习下Linear Decoder已经在大图片中经常采用的技术convolution和pooling,分别参考网页http://deeplearning.stanford.edu/wiki/ ...
随机推荐
- hiho1515 - 数据结构 并查集
题目链接 小Hi的学校总共有N名学生,编号1-N.学校刚刚进行了一场全校的古诗文水平测验. 学校没有公布测验的成绩,所以小Hi只能得到一些小道消息,例如X号同学的分数比Y号同学的分数高S分. 小Hi想 ...
- sql笔试题-1
在oracle下sql:比较巧妙地是group by 部分 E from (select a.team,b.y from nba a,nba b ) c group by (c.y-rownum) o ...
- bzoj1457: 棋盘游戏 SG函数 Nim
Code: #include<cstdio> #include<cstring> using namespace std; #define maxn 1003 #define ...
- easyui-combobox实现取值范围的联动
需求:需要用两个combobox来输入一个年月的范围,下拉框的内容从服务器获取.需要实现选中前者后,后者的下拉框中不能显示比前者数值小的:选中后者后,前者的下拉框内容不能显示比后者数值大的 有两个co ...
- 20180929 北京大学 人工智能实践:Tensorflow笔记02
https://www.bilibili.com/video/av22530538/?p=16 https://www.bilibili.com/video/av22530538/?p=14 (完)
- ZJU 1346 Comparing Your Heroes 状态压缩DP 拓扑排序的计数
做多校的时候遇见一个求拓扑排序数量的题,就顺便来写了一下. 题意: 你有个朋友是KOF的狂热粉丝,他有一个对其中英雄的强弱比较,让你根据这些比较关系来给这些英雄排名.问一共有多少种排名方式. 思路: ...
- 百度API调用实例
今天依据需求要从百度API中取出一些数据.这些操作包含:将坐标转换成百度坐标.依据转换的百度坐标进行特定的查询. 有需求的收藏下,免得下次手写浪费时间. 涉及到的操作有:JSON格式的字符解析.HTT ...
- C++windows内核编程笔记day11 win32静态库和动态库的使用
windows库程序: 静态库: 源码被链接到调用的程序或动态库,被调用时,代码最少有1份,文件后缀.LIB 动态库: 函数被程序或其它动态库调用,被调用时,代码仅仅有1份,文件后缀.DLL 静态库( ...
- Android插件实例——360 DroidPlugin具体解释
在中国找到钱不难,但你的一个点子不意味着是一个创业.你谈一个再好的想法,比方我今天谈一个创意说,新浪为什么不收购GOOGLE呢?这个创意非常好.新浪一收购GOOGLE.是不是新浪就变成老大了?你从哪儿 ...
- Android4.42-Settings源代码分析之蓝牙模块Bluetooth(上)
继上一篇Android系统源代码剖析(一)---Settings 接着来介绍一下设置中某个模块的源代码.本文依然是基于Android4.42源代码进行分析,分析一下蓝牙模块的实现.建议大致看一下关于S ...