Scala——面向对象和函数式编程语言
Scala
Scala是一门运行时基于JVM的编程语言,具备函数式编程和面向对象特点。
基本知识 basics
任意词均可作为符号名,对于关键词,以反引号包裹,避免使用下划线,避免带美元符的名字。
声明类型为Type的符号x的方式是先给出符号后通过冒号指定类型,x:Type,不同于java/c++等语言的Type x形式。
变量声明 variable/constant declaration
关键字 val, var, lazy val, final val
val x= 0 //自动推断出类型Int
val x:Long=0 // 显示指定类型
var x:Type = _ // 初始化对应类型等价0形式
final val field=0 //声明字段或局部变量
val a,b=5 // val a=5; val b=5
val (a,b)=(4,5) // val a=4; val b=5
val (a:TypeA, b:TypeB)=(,)
val a,b = (4,5) // val a=(4,5); b=(4,5)
val CaseClass(a,b) = caseClassInstance // a, b分别是case class的对应字段数据;常用用法是提取出返回case class的函数的返回值
case class CaseClass(x:Int, y:Int)
def f():CaseClass = {CaseClass(7,9)}
val CaseClass(a,b) = f() // a=7, b=9
val SomeObject(a,b) = ... // SomeObject.unapply .unapplySeq
val someInstance(a,b) = ... // someInstance.unapply .unapplySeq
如何根据其他class/trait中字段类型声明一个同类型的变量?类似var x: typeof(SomeClass.someField)。 <=== 不能
scala中局部变量名允许深层作用域遮蔽上层同名变量的情况(shading、hiding),类似C++。
操作符
括号:形式"<符号x>(...)" 相当于调用apply()方法。形式"<符号x>(...) = ..."相当于调用update()方法。 具体地,符号x是数组对象时,表示下标访问,此时类似java中下标访问符[];符号x为函数/方法名时,表示函数调用;符号为其他类型对象,是对其apply方法的调用;如果该形式出现在赋值操作符左侧时即x(...) = ...则表示调用对象x的update方法。
括号()是左结合的,优先级比点号.高。例如代码list.sorted(1)表示对list排序,排序时将数字1作为sorted函的参数,而不是将list排序后取索引为1的元素。当然,因为sorted接受的是Ordering类型的实参,1不是该类型的值,故代码有编译错误。
前置操作符与unary_函数
中置操作符
后置操作符
优先级
结合性:操作符都是左结合的,除了以冒号:结尾的操作符具有右结合性。
字符串 String
string interpolation
可以在字符串中嵌入表达式,然后解释出字符串的现象叫做stirng interpolation。解释这个字符串的方法叫做string interpolator。解释字符串中的变量(string interpolation),像perl、php、ruby那样,在字符串前引号前加s即可让编译器对字符串做string interpolation。(val name="Jack"; println(s"Hello $name"))。不仅是变量,还可以是表达式"... ${name.length>3}"。
这里的前置s(prepending s)事实上是一个方法。
除了s (standard) string interpolator,还有f string interpolator,f interpolator允许类似printf样式格式化字符串。
还有raw interpolator。
package & import
package xx.xx {
class xxx
object xxx
package xxx {
}
}
import java.io._ // import all in java.io
import java.io.{File, InputStream} // java.io.File java.io.InputStream
import java.io.{File => JFile} // *rename*(not alias) java.io.File -> JFile(将java.io.File重命名为JFile,不同于取别名,重命名将导致JFile可用,File不可用)
import java.io.{File=>_, _} #import any except..., any in java.io except java.io.File
程序控制 control structure
if() {} else {}
for(x <- 0 to 10)
for(x <- 0 to 10; if x%2 == 0)
for(i <- 1 to 3; z=4-i; j <- z to 3) //有变量定义的for
for(x<-0 to 10) yield x*2
for(x<-0 to 10; y<- 0 to 5)
for( (k,v) <- map ) // for遍历Map
集合上的for循环被“转译”时遵循以下规则:
- 简单for,转译为集合上的foreach方法调用
- for-guard(for if),利用withFilter,然后调用foreach
- for-yield,利用.map
- for-guard-yield,先.withFilter然后.map
expression, statement, block都有值,block由最后一句statement/expression决定。赋值表达式返回Unit。单独的()表示Unit。非yeild的for返回Unit, while返回Unit。
集合 collection
集合分可变(mutalbe)、不可变(immutable)两种类型。
immutalbe类层次结构图
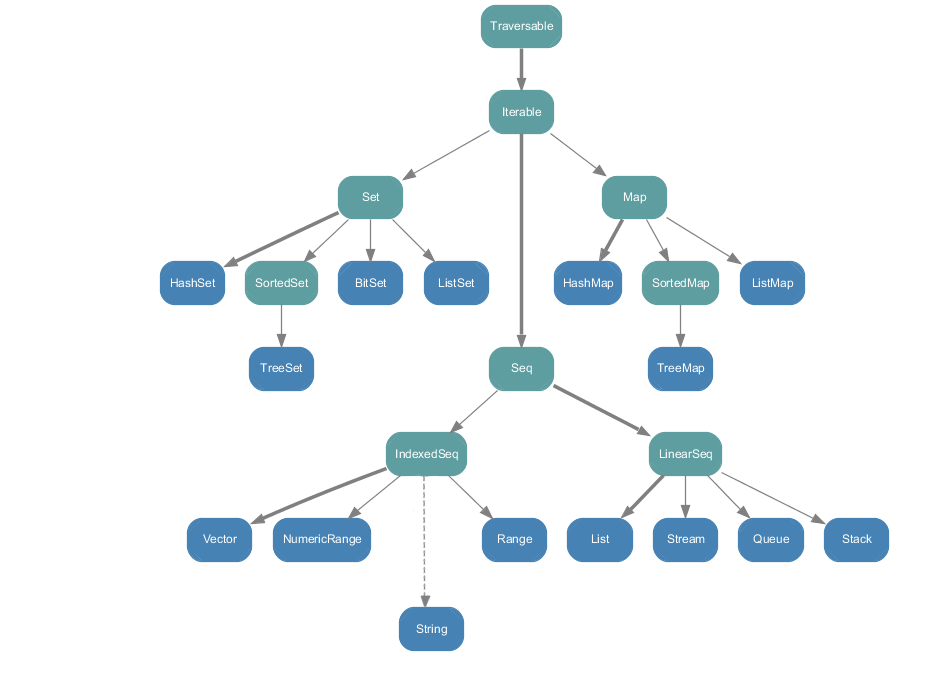{kind=link}
sort: .sorted是自然序(升序),sortBy()定义元素的序,如果实参是元组,则是定义分组排序。
sliding(size, step=1): 滑动切分集合,每组不超过size个元素,每组起始元素是上一组起始元素的下step个元素(返回$\left\lceil \frac{coll.length}{step}\right\rceil$组)。
grouped(size): 把集合拆分为每组不超过size个元素的$\left\lceil\frac{coll.length}{size}\right\rceil$组,效果等同于.sliding(size, size)。
java集合转Scala集合:import scala.collection.convert.ImplicitConversionsToScala._
有限集合zip一个常量,利用Stream.continually由一个常量生成一个无限集。xs.zip(Stream.continually(constant)),不可通过由常量生成的无限集zip有限集合,.zip(xs)
:_* 将集合展开,作为函数可变参数的实参
mutable.ListMap(2.12.0)(慎用) 声称是保存了插入顺序的map,然而保存的顺序和插入顺序相反(ListMap实现将其插到表头),而且,和immutable.ListMap(kv1, ....)在插入顺序行为上表现相反(也就说后者表现是预期的顺序)。两点不合理:1.表现顺序不合理;2.mutable和immutable行为表现不一致。这个类在不同的版本上行为表现都不尽相同,保存的插入顺序乱七八糟。
Set.intersect(Set)求出两set的交集
List.intersect(List)?
.distinct和.toSet都能生成不重复元素,二者开销差不多,前者能保留元素顺序(order preservation)。
.par并行集
.collect({case x if ... => x.yy}):当满足条件时返回映射结果,相当于联合filter().map(),找出满足条件的元素,同时进行映射
.toMap(implicit ev: A<:<(T,U))
其中<:<是
.withFilter是专为.map, .flatMap, .foreach 设计,不同于.filter,前者不会产生新集合,从而提高效率。
.partition(p:A=>Boolean)将集合内元素按谓词分为两部分,返回二元组的前者为满足谓词的元素集,后者为不满足的。
.span(p:A=>Boolean)相当于(c takeWhile p, c dropWhile p),不同于.partition。
mutable.OpenHashMap(open hash, 链址法) vs. HashMap(HashTable实现)
参数类型推断部分情况有bug,如<Array[String]>.toSet.map(_.trim),其中的下划线不能被推断出类型,造成编译不通过。
view
对有序列表进行数据操作,如果该数据操作中达到某种条件,则返回某种转换数据,并停止对列表中后续元素的匹配以避免计算浪费,有点类似.map().collectFirst,但这种组合操作不能避免后续元素的map操作。一种方式是对列表直接调用.collectFirst,传入的偏函数实参定义成显式的偏函数(同时定义 definedAt,apply)将数据操作中间状态放在字段中,在definedAt返回偏函数应用条件,在apply中对中间状态进行转换,返回想要的类型。另一种更流畅的调用方式是通过.view来实现,.view返回一个延迟计算的集合,在需要时才计算,也就说在遍历元素过程中遇到满足条件的元素前不会提前计算后续元素。.view.find()或 .view.filter().head
.view产生的是一个延迟计算集合(或可遍历对象),和stream有区别,如调用filter时前者不一定会对每个元素进行。
区别例子如下,对stream或collection:
// scala REPL
scala> (1 to 1000000000).filter(_ % 2 == 0).take(10).toList
java.lang.OutOfMemoryError: GC overhead limit exceeded
对view:
// scala REPL
scala> (1 to 1000000000).view.filter(_ % 2 == 0).take(10).toList
res2: List[Int] = List(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
元组 tuple
java代码中使用scala元组(TupleN)实例时尽量通过方法调用(._1())访问元素,避免字段访问元素(._1),因为在元组类型参数全是基本类型(实质是Tuple2类声明时定义的特例化@specialized类型)时,通过字段访问到的值是null,通过方法能正确获取值。另外,scala声明的类型参数为AnyVal(非java class/interface类型,几乎对应java基本数据类型)的泛型在java代码看来其类型参数是Object(比如scala中参为Int的泛型在java看来不是java.lang.Integer,而是Object)。
/* scala
class STest {
def int_long(): (Int, Long) = (1, 2L)
def int_string: (Int, String) = (1, "abc")
}
*/
public class AppMain {
public static void main(String[] args) throws Exception {
// Tuple2<Object,Object> intLong = int_long();
// can NOT: Tuple<Integer,Long> intLong = int_long();
Tuple2<?, ?> intLong = new STest().int_long();
System.out.println("intLong._1 = " + intLong._1);
System.out.println("intLong._1() = " + intLong._1());
System.out.println("intLong._2 = " + intLong._2);
System.out.println("intLong._2() = " + intLong._2());
System.out.println();
// Tuple2<Object, String> intStr;
Tuple2<?, ?> intStr = new STest().int_string();
System.out.println("intStr._1 = " + intStr._1);
System.out.println("intStr._1() = " + intStr._1());
System.out.println("intStr._2 = " + intStr._2);
System.out.println("intStr._2() = " + intStr._2());
}
}
/* output
intLong._1 = null
intLong._1() = 1
intLong._2 = null
intLong._2() = 2
intStr._1 = 1
intStr._1() = 1
intStr._2 = abc
intStr._2() = abc
*/
互转java类型
seq -> java list
// in java, for scala 2.12.x
scala.collection.JavaConverters.seqAsJavaList(seq)
// in scala, scala 2.12.x
import scala.collection.JavaConverters._ // [.asJava] explicitly convert
import scala.collection.ImplicitConversionsToJava._ // as java implicits
import scala.collection.convert.ImplicitConversionsToScala._ // as scala implicits
import scala.collection.convert.ImplicitConversions._ // as java/scala implicits
// in scala 2.11.x
import scala.collection.JavaConversions._ // asScala implicits
scala.Int <--> java.lang.Integer
java调用时,本是scala.Int的对象(事实上java代码中看到的已经不是scala.Int而是int)自动成为java.lang.Integer;
scala调用时, scala.Int -> java.lang.Integer: Predef.int2integer(.); java.lang.Integer -> scala.Int: Predef.integer2int(.)。
java.util.Map转scala immutable.Map:
// scala 2.10
JavaConverters.mapAsScalaMapConverter(map).asScala().toMap(scala.Predef\(.MODULE\).<scala.Tuple2<K, V>>conforms())
java stream -> scala stream
借助库org.scala-lang.modules:scala-java8-compat_2.12(“2.12”部分需对应scala版本),在定义compat依赖时,如果习惯通过引用pom property来定义版本,则不能定义该库版本的property名为"scala.compat.version",因为该property会被scala编译器用来检查多版本scala sdk兼容性。
import scala.compat.java8.StreamConverters._
val scalaStream = javaStream.toScala[scala.Stream]
<!--pom.xml-->
<properties>
<!--do NOT try to define a property with such name for scala-java8-compat library-->
<!--property with the name will be used by scala compiler plugin-->
<!--<scala.compat.version>0.9</scala.compat.version>-->
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang.modules</groupId>
<artifactId>scala-java8-compat_2.12</artifactId>
<!--NO-->
<!--<version>${scala.compat.version}</version>-->
</dependency>
</dependencies>
class & object
声明类的基本语法形式
[private] [final|sealed] [abstract] class ClassName [private] ([private] val|var] name1:Type1...) [extends SuperClassOrTrait[(superClassConstructorArg1,...)] [with trait1,...]] {}
相对于java,scala class声明没有public(事实上public也不关键字),类默认公有,一个.scala文件中可以声明多个类(但一般仍建议文件对应类)。
abstract class定义抽象类,final class定义不可被继承类,sealed class定义的类不允许在同文件外地方被继承。
类字段和方法 fields & methods
无参函数(方法)可定义为带括号和不带括号两种形式,一般将不会改变实例状态、无副作用的方法(immutator)定义为无括号形式,会改变实例状态、有副作用的(mutator)定义为带括号形式。无括号函数调用时必须不带括号调用,带括号函数调用时可带括号也可不带,但一般地,不带括号调用会隐含方法不会改变实例状态、无副作用之意义。
class Counter{
private var i = 0
def current = i
def get() = i
def increment() = i+=1
// def incre2 = i+=2 // NOT recommended, mutable method should NOT be parenthesis-less
}
object app extends App{
val n = new Counter
n.increment() // OK
//n.increment // compilation ERROR
n.current // OK, better than .current()
n.current() // OK
}
scala class成员默认是公有的(事实上scala偏向默认公有设计,同时没有public关键字),可以声明私有private或保护型protected。
字段定义时,val声明只读字段,var声明可读写字段。读方法"getter"(类似java中getXxx)方法名同字段名,写方法"setter"(类似java中setXxx)方法名为<字段名>_=(在jvm中不能有等号故为 _$eq)。即声明的公有字段时除了类内保存数据的私有字段,对于公有val字段蕴含"getter"(同方法名),对于公有var字段蕴含"getter"和"setter"(方法名<字段名>_=)。声明私有变量通过加private实现;对本实例外私有通过private[this]语法实现(类的其他实例也无法访问);声明对嵌套类可访问,private[<类名>];也可声明对某个包内可访问(包外不可访问)私有型,通过private[<包名>]实现。
如果需要覆盖默认的getter、setter,应将字段设为private,字段名一般为getter/setter名(即对外形式的字段名)前加下划线_,类中定义getter方法def ={},和setter方法def _=(s:Type){}。
通过注解@BeanProperty标注字段(或主构造器中的val/var参数)可(额外)生成java bean 风格的getter/setter(对val字段则只有getter)。
(类定义体中的)字段定义时不提供初始值则被认为是抽象字段(要求类是抽象类),对val/var字段皆如此,初始值可由代码块产生的返回值提供。
class P(val name:String, var age:Int) {
}
// $javap -private P.class
/* output ==>
public class P {
private String name;
public String name(){...}
private int age;
public int age(){...}
public int age_$eq(int){...}
public P(){...}
}
*/
object app extends App {
val p=new P("Jack Ma", 54)
println(p.name)
p.age = 50 // in java, p.age_$eq(60)
println(p.age)
}
package com.exmaple.access
class FieldAccessorExample( val age:Int /* public */){
private var a = 0
private[this] var b = 0 // this instance accessible
private[access] var c = 0 // accessible in this ‘access’ package
private[exmaples] var d = 0 // NOT be: private[com.exmaple]
private[com] var d1 = 0
// private[another] var dx = 0 // may NOT be other packages, neither subpackages
}
// private[this|<Class>]
class Girl{
private[this] var age:Int
//! def isOlder(that:Person) :Boolean= this.age > that.age // compilation ERROR, NOT accessible in other instances
}
class Girl{
private[Girl] var age:Int
def isOlder(that:Person) :Boolean= this.age > that.age // OK
}
class JavaBeanExmaple (@BeanProperty var age:Int) {
@BeanProperty var name:String = _
// yield 4 methods: String name(); void name_$eq(String); String getName(); void setName(String);
}
// getter/setter customizing
class Person {
private var _name: String = _
private var _age: Int = _
def name= _name
def name_= (newName:String){
if(newName=="Lady Gaga")throw Illegal("NOT allowed: her tracks are noisy")
_name = newName
}
}
// field declaration & initialization
class SomeClass{
val text={
var lines=""
try{
io.Source.fromFile("a.txt").getLines.mkString()
}catch{
case e:Exception=> lines="ERROR"
}
lines
}
}
构造函数 constructor
scala class构造函数(构造器)分为两种,主构函数(primary constructor)和辅构函数(auxiliary constructor)。主构函数有且仅有一个,参数列表在类名后的括号中(省略括号时即为无参构造函数),类定义体中的执行代码为主构器的代码。辅构函数可定义多个,在类定义体中定义,像类方法一样,只是方法名是特殊的this,辅构函数将会调用其他构造函数(主构函数或辅构函数),其函数体内首先应该是对其他构造函数的调用,然后是其他代码。主构函数的可访范围默认公有,如需私有,在主构函数的括号前声明可访范围修饰符,如private,private[this];辅构函数的可访范围设置同类方法的。
主构函数的参数形式为“([[private] val|var] <参数名>:<参数类型>,...)”,如果有val或var,则同时蕴含类字段声明,如果仅是“<参数名>:<参数类型>”则该参数和普通函数参数一样,不蕴含类字段声明。类定义体(类名后的花括号代码块)中定义的字段名不允许与主构函数中的参数名一样,即使主构函数中的参数未蕴含字段声明。
无var、val没有getter、setter。case class是例外,其为functional programming设计,无var/val时相当于带val。无var、val可用在继承时子类的primary constructor参数中传输父类构造器参数,如class Student(name:String,age:Int,val id:String) extends Person(name,age){}
字段可见性默认public,private的val、var不会自动被自动生成getter、setter。private字段对类的所有实例可见,private[this]的仅对本实例可见,private[thisPackage|someAncientPacke|enclosingClass]对某个package或嵌套类可见,package名指本名,不是带点号的限定名。
val字段可以通过block或expression赋值,例:
class Person {}
class Person(val name:String, var age:Int) { // primary constructor
private profile: String = ""
def this(name:String) = this(name, age)
def this() = {
this("no one", 0)
this.profile = "faceless"
}
}
class Person private {} // private parameterless primary constructor
class Person private (name: String){} // private one-parameter primary constructor
class Person (name:String){
...
println(s"name: $name") // executed when constructing
... // members
}
val字段值可以是lazy计算的,通过lazy关键字实现,其中的值计算要推迟到第一次访问,而非类实例化时就计算。lazy val text=io.Source.fromFile("read.large.size.file").getLines.mkString
constructor分两种,primary constructor和auxiliary constructor,后者通过在类中定义名为this的函数实现。定义private的primary constructor通过在类名和参数括号之间加private关键字实现class ClassName private (...)。
实例化class使用new ClassName(....)语法。
内嵌类 nested class
类中可定义别的类,但其类型绑定于类实例(而非类),也就说对于两个外部类的实例,其关联的内部类(内嵌类)的类型是不一样的。但是这仅限于scala编译器角度,由于编译为jvm字节码时等同于java(非静态)内嵌类,故运行时的类型实际一样,而且对于java视角而言其类型等同于类的嵌套类。如果定义为外部类的内嵌类,又想表达与外部类实例无关(所有外部类实例)的类型语义,可通过#操作符实现,形式为<外部类>#<内部类>。对于仅想将类名作为名字空间使用而定义类情况,通过在伴生对象中定义内部类实现,相当于java中的静态内部类。
new内嵌类实例语法形式为new <外部类实例>.<内嵌类名>,而java中为<外部类实例>.new <内嵌类名>。
class P{
class PNested
}
object P {
class PInner
}
object app extends App {
val p=new P
val p2=new P
val list1:ListBuffer[p.PNested] = ListBuffer()
list1 += new p.PNested // OK
// list1 += new p2.PNested // compilation ERROR
val list2:ListBuffer[P#PNested] = ListBuffer()
list2 += new p.PNested // OK
list2 += new p2.PNested // OK
println(new p.PNested().getClass eq new p2.PNested().getClass) // but this gets true
val z = new P.PInner
}
class Outer{
class Inner{
def conn(n:Inner){}
}
def newInn:Inner=new Inner
}
val outer1=new Outer; val o1n1=new outer1.Inner;val o1n2=outer1.newInn;
val outer2=new Outer; val o2n1=outer2.newInn
o1n1.conn(o1n2); // OK,o1n1, o1n2类型均为o1.Inner
//! o1n2.conn(o2n1); // ERROR o1n1类型为o1.Inner,其conn方法期待的类型是o1.Inner,而o2n1类型为o2.Inner
class ... {
class Inner {
def conn(n: Outer#Inner){}
}
}
class中可定义内嵌class或object,object的归属性质同class。
TODO 内嵌类访问外部类引用
object
scala没有静态函数、变量概念,可通过object实现相关功能,同时object还是一种单例。
对象的特征几乎相同于类的——对象甚至可继承其他类或特质——但是对象不可有(其他)构造函数,即一个无参主构函数。
一个继承了超类或特质(class or trait)的scala object也被认为是一个子类型单例对象。
在类定义的源文件中可定义与类名同名的scala object,称为类的伴生对象,类称为该对象的伴生类。
伴生对(伴生类及其对应伴生对象)可访问对方私有成员,伴生对需置于同一源代码文件。
枚举 enum ?
无枚举类型,但可通过扩展object Enumeration实现相同功能。如下:
object Color extends Enumeration {
val R, G, B = Value
}
其中,Value是内部类,val R,G,B=Value语句调用了三次Value无参构造器(数值ID默认从0自增1,名字默认为字段名字)。注意,R,G,B的类型是Color.Value,不是Color,后者是持有R,G,B的单例对象(object)。为了将Color理解为R,G,B的类型,可以增加一个类型别名定义语句,如下:
object Color extends Enumeration {
type Color = Value
val R, G, B = Value
}
case class
case class是一种特殊的class,因为类定义很简单,无法直接定义auxiliary constructor,只有primary constructor。实例化case class直接用ClassName(....),可不用加new关键字。要想定义其他参数形式的实例创建方法,可以通过定义其伴生对象的apply方法实现。
case class主构造器的参数默认带val(不同于普通class)。
如
case class Person(var name:String, var age:Int)
object Person {
def apply()=new Per("default-name",default-age)
def apply(name:String)=new Per(name,default-age)
}
case class Point(x:Int,y:Int) // 等同 case class(val x:Int,y:Int)
val p=Person("Gu Tianle", 28)
方法/函数 method/function
我们讲“方法”时一般指类的方法(相当于java中的类实例方法,与对象实例关联);讲“函数”时根据上下文有两种理解,一是指定义了输入输出的行为过程,类似C函数,另一种理解把范围缩小至仅指与对象实例无关的函数(类似java中类的静态方法),此时与“方法”相对。
函数参数可以有默认值。def connect(host:String, timeout=3000){}
如果有默认值的参数都放在参数列表的后面,那么调用方法时可以从参数尾依序不提供参数。connect("localhost")
也把具有默认值的参数可以放在参数列表任何位置,这时要使用参数默认值,则要通过命名参数传递方式实现。def connect(timeout=3000,host:String); connect(host="localhost")
支持不定长参数,不定长参数需放到参数列表尾,定义语法为在参数类型后加*,例:def f(args:String*){...}。
可以把一个集合展开,作为变长参数函数的实参,通过 :_* 操作符实现,使用如下:val xs=List("aa","bb"); f(xs:_*)
定义可能会抛出异常的方法,通过在方法上添加多个注解@throws(classOf[SomeException])或@throws[SomeException]("cause")实现。
@throws(classOf[IOException])
@throws[FileNotFoundException]("missing file")
def read(file:String){}
class定义中this.type表示实例的类型。支持连续调用的方法返回类型一般是this.type,返回this。
函数参数可声明为形式(x: => Type),和供值函数(无参函数) x: ()=>Type相似(类似类的无参方法不带括号和带括号两种形式),但前者只需传入一个返回类型为Type的表达式(一个值或者值计算表达式)即可,而后者需传入一个函数(函数对象或lambda)。
无参函数类型与无括号函数类型:
def f(y: ()=> Int) ={ println(y())} // 无参函数作为参数,使用y时必须带括号表示调用函数,否则作为函数对象实例使用
def g(z: => Int) ={} // 无括号函数作为参数,使用z时必须不带括号
g(5) // OK
g(Random.nextInt) // OK
g(Random.nextInt()) // OK
//! h(5) // ERROR
h(Random.nextInt) // OK
//! h(Random.nextInt()) // ERROR
h( ()=> 5 ) // OK
无括号函数类型作为参数时,传的实参可以是值,或者返回该类型的供值函数(provider)。
scala可定义无括号函数与无参函数,一般地,无括号函数表示该函数无副作用(side-effect),而无参(带括号)函数表示无副作用。scala中调用java无参方法时可带括号调用也可不带。
def getXXX = {}
def clean() = {}
def x() ={
val javaBean=xxx
javaBean.getName // OK
javaBean.getName() // OK
}
结合scala中对于参数类型为无括号函数的函数,传入实参时,如果给的是类似javaBean.getName不带括号的形式,那scala理解为瞬时值还是动态值呢(捕获了传入时的调用值还是捕获了方法引用)?
答案是,始终是动态值,不论加括号与否,捕获的都是方法。
class A(z: =>String) {
def print()= println(z)
}
object app extends App {
val javaBean = xxx
javaBean.setName("name 1")
val a=new A(javaBean.getName)
a.print() // "1"
javaBean.setName("name 2")
a.print() // "2"
val b=new A(javaBean.getName())
b.print() // "2"
javaBean.setName("name 3")
b.print() // "3" <-- careful
}
特殊方法 apply/unapply/unapplySeq/update
形式x(...)相当于调用apply()方法;用于赋值等号左侧时,形如x(...)=y,相当于调用update(..., y)。
伴生对象的apply方法多用于提供伴生类实例,省去new操作符。
unapply有逆apply之语义,但更广泛,是一种抽取行为(extract),定义了如何从一个量中抽取出若干个量。
unapply方法可定义在scala object或class中,捕获抽取出的量的形式为ObjectName(varName1,...)或classInstance(varName1,...),unapply需返回Option,Option[Type]的类型参数Type即是捕获变量的类型,返回元组时允许捕获多个变量(和元组元素个数相同,编译期固定),unapplySeq返回Option[Seq[Type]]允许返回序列,允许动态(运行时)捕获多个量。
对于scala object定义unapply/unapplySeq情形主要提醒的一点是,并不要求该object有伴生class,捕获变量时当然也没有任何构造函数被调用。
class XYPoint(x:Int, y:Int){
}
object XYPoint{
def unapply(p:XYPoint)= /*if ... None else */ Some((p.x, p.y))
}
object Point { // no companion class, not to mention the constructor Point(Int,Int)
def unapply(s:String)=Try(s.split(",")).filter(_.length==2).map(x=>(x(0),x(1))).toOption
}
objects Names{ // no companion class
def unapplySeq(s:String)=Some(s.split(","))
}
object app extends App {
val p=new XYPoint(1,2) // or XYPoint(1,2) if apply defined in companion object
val (x,y)=p // yield variables x = p.x, y = p.y
val Point(a,b)="50,100" // a=50, b=100, Note: no class Point, not to mention the constructor Point(Int,Int)
val s=scala.io.StdIn.readLine
s match {
case Names(n1) => ... // a name, no ','
case Nmaes(n1, n2) => ... // two names separated by ','
case Names(n1,n2,n3)=>....
}
}
对于抽取器用于变量声明时,如果返回None会导致运行时抛出Error,如果用于match,表示匹配不上该case。
case class自动具备apply、unapply。
偏函数 partial function
PartialFunction定义了对是否在对象上采取措施(将是否施用函数)的isDefinedAt(_),和定义将施用的函数apply(_),可用case语法定义偏函数:
{
case Type(x) => // if match Type(x) do block
case x if x.xxx => // if satisfy condition
case _: VirtualMachineError | _: ThreadDeath => // if instance of XxxError or Xxx
}
函数对象:
val f = scala.math.ceil _ // 需要下划线指明需要的是函数对象,而非忘了传参,在没有歧义的上下文中不用带下划线
val f2: (Double)=>Double = ceil
val g = (_:String).charAt(_:Int) // yeild type of g is (String,Int)=>Char
val g2:(String,Int)=>Char = _.charAt(_)
高阶函数:以函数作为输入或者输出函数的函数。……
闭包:……
-=-=-=-
对于java接口中的funtional interface类型的参数,scala调用时只可当场传入scala函数字面量(lambda),不能直接传入函数对象实例引用。
柯里化 Currying:将接受多个参数调用变成挨个接受单一参数函数后连续调用的技术。
val f = (y:Int) => ((x:Int)=> x*y)
f(5)(6)
def g(x:Int)(y:Int) = x*y
g(5)(6)
继承 inheritance
特质(trait)是定义行为、状态的抽象,类似java中的interface,但语义、功能更丰富。
尽管特质比java interface语义丰富很多,但暂且把使得一个类具备一个特质的行为称为一个类++实现++了一个特质。
类型只能继承一个class,不存在多继承,但类似java,可实现任意个特质(trait)。(class xx extends X with T1 with T2 ...)
类型继承类、实现特质的语法形式并非是extends关键字用于继承class、with关键字用于trait,类声明如果有继承/实现,则首先是extends关键字接其他类或特质,而后是多个"with TraitXx",不能只有with而没有extends(如果有覆盖早定义则extends接的是覆盖内容而with接的是类)。
final修饰class表示类不可被继承,sealed修饰class表示类不可在类定义源文件外被继承。final可修饰字段,表示字段不可被重写(不同于java中的final字段指不可被重新赋值)。
无函数实现体的方法即为抽象方法,有抽象方法的类必须声明为abstract class。抽象的val/var“字段”会生成抽象的getter/setter类方法(var同时包括getter&setter),不会生成类字段。
覆盖父类非抽象方法必须添加override关键字,实现父类抽象方法或特质中的方法则无需override关键字。
子类中使用super关键字引用父类。
scala中不能像java中那样调用super(...)。
一个override def只能覆盖父类的def;一个override val可覆盖父类的val和def;一个override var只能覆盖父类abstract var(或者一对getter/setter的def)。
匿名子类:
class P(val name:String)
object app extends App {
val x= new P("Lei Jun") {
def greeting = "are you ok"
}
// anonymous subclass as parameter
def hello(p:P{def greeting:String})= println(s"${p.name}: ${p.greeting}")
}
类继承层次结构 inheritance hierarchy
顶层Any,后分值类AnyVal和引用类AnyRef。值类不可赋null,引用类可赋null。值类包括基本数据类型和Unit类(不像java,scala中没有基本类型包装类),允许自定义值类。(需要注意仅单个参数且类型为Any的方法在调用时可传入的实参)
Unit语义基本等同java中的void,Unit有唯一的一个值()。(需要注意Unit类型参数方法调用时可传入的实参)
Null是所有引用类的子类,Nothing是所有类的子类。Nothing和Null仅存在于scala编译器视角(所以运行时并没有多继承)。
.isInstanceOf[ClassName]检查实例是否为某类的实例,null变量检查返回false。
.asInstanceOf[ClassName]进行类型强转,对null变量进行类型转换得到null,非null变量转换时若类型不对应则抛出异常。
值类 value class
值类的设计目的是使得隐式转换高效进行。
特点:
- 继承自AnyVal
- 主构函数中包含且仅包含一个val字段
- 没有其他字段或构造函数
- 自动提供equals、hashCode函数,基于比较和散列包含的唯一字段
早定义 early definition
覆盖早定义,为了解决父类初始化中能正确获取被子类覆盖的字段/方法值问题。(语法很不优雅)
class Sup{
val n = 5
val p = n+1
}
// no using early-definition
class Sub{
override val n = 10
}
// new Sub().p : 1 // Unexpected value <= not 11 ( neither 6)
// 实例构造过程:
/*
1. new Sub() => 开辟内存空间(置字段值为等价0),准备构造自己前构造父类
2. 设置父类字段n为5
3. 设置字段p的值(通过调用字段n的getter然后加1),由于n的getter被覆盖,调用子类覆盖方法,因子类在等待父类初始化完成而未开始对自身字段赋值,子类字段getter返回等价0,导致父类初始化时p为0+1即1
3. 子类的父类初始化完成后开始构造自身,置字段n为10.
*/
// early-definition
class Sub extends {override val n=10} with Sup
// new Sub().p : 11 // OK
equality 相等性
一般用==比较,如值、集合(位置及对应元素)。
比较引用是否指向同一地址(是否为同一个实例对象)时使用方法eq
new String("a") == new String("a") // true
new String("a") eq new String("a") // false
List(1,2,3) == Vector(1,2,3) // true
要自定义相等性,需覆盖方法equals(Object)即override def equals(o:Any),需要注意的是,参数类型是Any,而不是自身类型(否则成了重载),也不是覆盖方法==,即不是override def ==(o:Any)或参数类型为自身类型的==方法。
TODO
canEqual, equals
特质 trait
- 类可以实现任意多特质
- 特质可要求实现类具备特定字段、方法、或超类
- 特质可提供方法实现和字段(状态)
- 类实现的多个特质间有层结构,特质顺序决定行为
trait A {
def hello(msg:String):Unit // abstract
def hi(m:String)=println(m) // concrete
val n:Int // abstract field
val m = 5 // concrete field
}
trait B extends traitC with D1 ...
// a trait can event extend a class
trait extend ClassX with ...
// self types
trait C {
this: Type => // this trait can be only mixed into subclasses of Type
def f()... // can access memebers in Type
}
模式匹配 pattern matching
关键字match有多路选择匹配之语义,类似java中的swith,但不会像java中匹配上的case会自动包含后续case除非加break(fall-through现象)。
x match {
case 5 =>
case 7 | 9 => // use a pipe '|' to indicate OR conditions
case "some" =>
case y:SomeClass => // isInstanceOf & asInstanceOf, cast as variable y
case _:AnotherClass =>
case _ if .... =>
case Array(0) =>
case Array(0, _*) => // 0 then followed by any
case Array(0, y @ _*) // 0, and bind the rest elements to variable y
case CaseClass(a,b) =>
case CaseClass("100", a) =>
case CaseClass(a, InnerClass(b,_),_*) =>
case CaseClass(_, y @ InnerClass(b,_), z @ _*) =>
case SomeObject(...) => // unapply/unapplySeq
case someInstance(...) => // unapply/unapplySeq,例如正则匹配,捕获的若干变量是正则式中的组
case 0::Nil => // only "0"
case a::b::Nil => // only two elements and bind orderly to a(the first), b(the second)
case 0::t => // 0, ... bind ... to t
case (0, _) =>
case (1,_) | (_,1) =>
//! case (2,y) | (y,2) => // ERROR, cannot bind with alternative conditions
case (a,b,c)=>
//! case (a, _*)=> //ERROR no such _*
case _ => // locate as the last one case, for otherwise condition
}
正则表达式 regular expression
……
不能像java那样在表达式中定义命名组,需通过.r('name1'...)后的参数定义命名组。
泛型 generics
类型约束
T =:= U T是否为U
T <:< U T是否为U子类
T => U T是否可转换为U
三个“符号”为object(有伴生类),=:=和<:<定义在Predef中,继承关系 =:=继承自<:<继承自=>。
协变
……
逆变
……
implicit
implicit可以进行隐式类型转换,或者用于自动传参。
implicit的搜索过程
import scala.collection.convert.ImplicitConver
val x = new jva.util.ArrayList[String]
val y:Iterable[String] = x (ArrayList被隐式转换为Iterable)
ArrayList[java.lang.Inteter]能隐式转到Iterable[Integer],Integer能隐式转到Int,但不能从ArrayList[Integer]隐式转到Iterable[Int]。尽管如此,可以定义一个implicit方法convert,通过显示调用转换。(val x=new ArrayList[Integer] (); val y:Iterable[Int]=x)
implicit canBuildFrom与collection.breakOut
val obj:A
// obj.additionalMethod(); compilation ERR reporting before implicit class
// 扩展类A的方法
implicit class RichA(a:A) {
def additionalMethod() ={}
}
obj.additionalMethod() // it's ok now
// 隐式类型转换
implicit def double2Int(d:Double): Int = d.toInt
val x:Int = 0.0 // it's ok after we have an implicit type converter from double to int
类型参数T、泛型M,T : M是绑定T到一种上下文的行为语法,该上下文具有类型M[T]的一个implict值。
Predef.implicitly[T](.)该函数返回上下文中类型T的implicit值。
异常 exception
package & import
package内可定义package, class, triat, object。包名的解析按相对层级和绝对层级两种方式(而java中只按绝对层级,即始终从顶层包开始)。包内成员对父层包内成员可访问。
_root_包表示顶级包(最顶级包无名,多以表示绝对层级解析后面的包名)。
package com {
class A
package ex {
object U {
new A // A is accessible
_root_.scala.collection.List()
}
}
}
package com.a.b {
class B {
// members of com and com.a are NOT accessible
}
}
package a {
package b {
package c {
"可访问b,a中的成员"
}}}
package a.b.c {
"不可访问b, a中的成员"
}
不带花括号体的package的作用域覆盖文件后续内容。
package com.a
package b
// package com.a.b
package可以一个package object,其中可定义方法和变量。一般将package object放到包对应层级目录下的package.scala源文件中。
// com/a/b/package.scala
package com.a.b {
package object {
def ...
}
}
导入时隐藏成员,仅在导入全部用作排除。
import java.util.{HashMap=>_, _} // can NOT only import java.util.{HashMap=>_}
注解 annotation
标注类主构函数:
class定义前的annotation默认annotate class,要annotate primary constructor,需要将annotation置于constructor的开括号前,constructor的无参annotation不能省略括号:
@Component // for class
class A @Autowired() /* for constructor */ (param:Type){}
// class A @Autowired (para:Type) //ERROR, you can NOT do this
primary constructor中有getter/setter的参数(参数变量同时蕴含字段、getter、setter,甚至bean-getter如果加了@BeanProperty注解)的注解默认标注???
标注类属性:
非private的val, var蕴含了字段、getter(var/val)、setter(var)三种定义,如果仅需标注字段需要借助注解scala.annotation.meta.*,在@后使用括号,先加注解名,然后加标注目标(target)@field/@getter/@setter/@beanGetter/@beanSetter等(@(Annot @)),注解的参数在@()后(@(Annot @)(annot-args))。
import scala.annotation.meta.field
class A( @(Field @field) val id:String)
type AnnoField = Field @field
class A(@AnnoField("tid") val id:String)
class A(@(Field @field)("tid") val id:String)
动态性 dynamic
scala.Dynamic(实现此trait获得动态调用能力)
applyDynamic()
applyDynamicNamed()
updateDynamic()
selectDynamic()
Actor
Using an actor to perform blocking I/O is asking for trouble.
Any system that have the need for high-throughput and low latency is a good
candidate for using Akka
由于typesafe akka库比Scala.actor更优秀,自scala 2.11版本后,scala actor库被废弃。
va system=ActorSystem("name"); val actor=system.actorOf(Props(new SomeActor(""),name="actor-name"); actor ! "msg1"; actor ! "msg2";
自调用.actorOf后,actor即被自动启动,开始处理消息,没有类似start的手动启动方法。
给A actor发送停工消息(stop)后,手动给下游actor发送停工消息,最后一个actor需通知actorsystem停工,这种需求应该在重写的postStop方法中完成:
class A extends Actor {
val bActorRef
override def receive = {
case StopMsg=>
context.stop(self)
}
override def postStop()={
bActorRef ! StopMsg
}
}
class LastActor extendsActor {
override def receive={
case StopMsg=>
context.stop(self)
}
override def postStop()={
context.system.terminate()
}
}
Scala知识点(杂)
Int赋值语句的返回值是Unit,因此不能连续赋值,如:x=y=1。
块语句的返回值是块内最后一条语句的返回值。
breakable是通过抛出/捕获异常的机制实现的,有性能代价。
函数的返回值仅当函数是递归函数才必须指定。在面向对象语言中,递归函数的返回类型并不总能推断出。
函数无指定有效返回值时返回Unit,返回Unit的函数一般被称为过程(procedure),对其定义时可以省略等号,像这样:def proc(x:Int){...},而一般的函数定义是像这样的:def sum(x:Int,y:Int):Int={x+y}。
可以在传参时混用无名参和命名参,但无名参需放在前面,依次对应于函数的形参列表。
变长形参的类型是Seq,三字符操作符“:_*”告诉编译器将变量展开为函数的变长形参的实参。
val, lazy val, def
如果if-else结构的某一支的类型为Nothing,那么此if-else的类型由另一支决定。
try{}catch{case xx:}finally{}
for(i <- 0 until x.length if ...)
for(i <- (0 until x.length).reverse if ...)
ArrayBuffer:变长数组 toArray => Array定长数组 toBuffer => ArrayBuffer
类:
val字段默认有getter,var字段默认有getter和setter,其可访问性和字段保持一致。通过定义函数def foo = ...; def foo_= (arg:Type) = ...;分别实现自定义getter和setter。
字段的@BeanProperty注解,生成4个方法,scala风格的getter(def foo)和setter(def foo_=)和java bean风格的getter( getFoo())和setter(setFoo(...))。
private[this]字段没有编译器自动生成的方法。
构造器有两种:主构造器和辅助构造器。主构造器只有一个,其参数在类名后定义,如class Foo(val x:Type1, var y:Type2) {...},类中所有的语句会被主构造器执行;辅助构造器在类中通过def this(...)定义,其实现过程中可调用其他构造器(主、辅助构造器)。
无静态方法或字段一说。通过object定义一个单例对象,若其名字和类一致,则成为类的伴生对象。可通过伴生对象实现静态方法和字段的功能。
所有class实现一个标记接口ScalaObject(与版本有关?)。
Any类是所有类的根类,AnyVal是值类型的标记接口,AnyRef是引用类型的超类。Nothing是所有类型的子类,无实例。
Null是所有引用类型的子类,只有一个实例,为null。
Unit是值类型,有唯一实例()。
scala和java混合的maven工程pom配置:
<dependencies>
<!--scala-lang library-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.6</version>
</dependency>
</dependencies>
<build><plugins>
<!-- plugin declaration for scala compiler plugin goes before the one for java compiler-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<!--<version>3.2.0</version>-->
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
</plugin>
</plugins></build>
jetbrain idea IDE在maven项目引入org.scala-lang:scala-library和编译插件net.alchim31.maven:scala-maven-plugin依赖后认为项目依赖scala语言,同时将src/main/scala标记为sources目录,仅添加任一单个组件时不会被认为是scala工程。
Scala——面向对象和函数式编程语言的更多相关文章
- swift是面向对象、面向协议、高阶类型、灵活扩展、函数式编程语言
swift是面向对象.面向协议.高阶类型.灵活扩展.函数式编程语言
- 测试和恢复性的争论:面向对象vs.函数式编程
Michael Feathers最近的博文在博客社区引发了一场异常激烈的论战.Feathers发表言论说一些面向对象编程语言的内嵌特性有助于测试的进行,并且使用面向对象编程语言编写的代码更容易恢复. ...
- Scala 中的函数式编程基础(一)
主要来自 Scala 语言发明人 Martin Odersky 教授的 Coursera 课程 <Functional Programming Principles in Scala>. ...
- Scala函数与函数式编程
函数是scala的重要组成部分, 本文将探讨scala中函数的应用. scala作为支持函数式编程的语言, scala可以将函数作为对象即所谓"函数是一等公民". 函数定义 sca ...
- 函数式编程语言(functional language)
内容根据百度词条整理! 转载请声明来源:https://baike.baidu.com/item/%E5%87%BD%E6%95%B0%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8 ...
- 函数式编程语言(Fuction Program Language)
一.什么是函数式编程语言 函数式编程语言(functional progarm language)一类程序设计语言,是一种非冯·诺伊曼式的程序设计语言.函数式语言主要成分是原始函数.定义函数和函数型. ...
- 函数式编程语言(Functional Program Language)
(一) 什么是函数编程语言 简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论. 是一种编程典范, ...
- (数据科学学习手札48)Scala中的函数式编程
一.简介 Scala作为一门函数式编程与面向对象完美结合的语言,函数式编程部分也有其独到之处,本文就将针对Scala中关于函数式编程的一些常用基本内容进行介绍: 二.在Scala中定义函数 2.1 定 ...
- 【AMAD】coconut -- 简单,优雅,pythonic的函数式编程语言
动机 简介 个人评分 动机 作者的话: 我喜欢函数式编程,我认为函数式编程提供了一个更自然的方式来思考问题,并且代码也更加优雅,易读.不过如果你看过前20个最受欢迎的编程语言,你会发现没有一个式函数式 ...
随机推荐
- Thinkphp5跨域问题
关于代码分离可能会遇到json传输接收不到的问题(可能00) 起初我百度到解决此问题可以用jsonp来发送并接受,可是这只是一时之计 以后也会不方便所以我发现了一下方法 在app顶层创建文件commo ...
- WEB 移动端 CSS3动画性能 优化
很多时候,我们在开发移动端的时候要使自己的网页兼容不同的机型,很多时候会采用CSS3动画,但是很多时候在安卓机下,动画明显会出现卡顿,很难看,那么这里我介绍几个CSS 属性进行硬件加速那么就会得到明显 ...
- seleniumd对象的操作方法,属性,keys
这是通过find方法找到的页面元素,此对象提供了多种方法,让我们可以与页面元素进行交互,例如点击.清空. 目录: 1. 方法 2. 属性 3. keys 方法 clear()清空 如果当前元素中有文本 ...
- 【Codeforces 474D】Flowers
[链接] 我是链接,点我呀:) [题意] 让你吃东西 B食物一次必须要吃连续k个 但是对A食物没有要求 问你有多少种吃n个食物的方法(吃的序列) [题解] 设f[i]表示长度为i的吃的序列且符合要求的 ...
- 洛谷 P1348 Couple number
题目描述 任何一个整数N都能表示成另外两个整数a和b的平方差吗?如果能,那么这个数N就叫做Couple number.你的工作就是判断一个数N是不是Couple number. 输入输出格式 输入格式 ...
- 修改tomcat端口号的方法
8080是Tomcat服务器的默认的端口号.我们可以通过修改Tomcat服务器的conf目录下的主配置文件server.xml来更改.用记事本打开server.xml文件,找到如下部分: 以下为引用的 ...
- TASKLIST 显示计算机上的所有进程
Tasklist"是 winxp/win2003/vista/win7/win8下的命令,用来显示运行在本地或远程计算机上的所有进程,带有多个执行参数. 使用格式 tasklist [/s ...
- [poj3735] Training little cats_矩乘快速幂
Training little cats poj-3735 题目大意:给你n个数,k个操作,将所有操作重复m次. 注释:三种操作,将第i个盒子+1,交换两个盒子中的个数,将一个盒子清空.$1\le m ...
- [MongoDB]Python 操作 MongoDB
from pymongo import MongoClient mc = MongoClient('localhost',27017) db = mc.users db.users.save({'na ...
- 2本Hadoop技术内幕电子书百度网盘下载:深入理解MapReduce架构设计与实现原理、深入解析Hadoop Common和HDFS架构设计与实现原理
这是我收集的两本关于Hadoop的书,高清PDF版,在此和大家分享: 1.<Hadoop技术内幕:深入理解MapReduce架构设计与实现原理>董西成 著 机械工业出版社2013年5月出 ...