About CNN(convolutional neural network)
NO.1卷积神经网络基本概念
CNN是第一个被成功训练的多层深度神经网络结构,具有较强的容错、自学习及并行处理能力。最初是为识别二维图像而设计的多层感知器,局部连接和权值共享网络结构
类似于生物神经网络。
- 卷积神经网络的权值共享(weight sharing)的网络结构显著降低了模型的复杂度,减少了权值的数量。
- 神经网络NN的基本组成包括输入层,隐藏层和输出层。卷积神经网络的特点在于隐藏层分为卷积层和池化层(pooling layer,也叫下采样层)。
- 卷积层通过一块块的卷积核(conventional kernel)在原始图像上平移来提取特征,每一个特征就是一个特征映射;
- 而池化层通过汇聚特征后稀疏参数来减少要学习的参数,降低网络的复杂度。池化层最常见的包括最大值池化(max pooling)和平均值池化(average pooling).
- 卷积核在提取特征映射时的动作称为padding,有两种方式,即SAME和VALID.由于移动步长(Stride)不一定能整除整张图的像素宽度,我们把不越过边缘取样称为Valid Padding,取样的面积小于输入图像的像素宽度;越过边缘取样称为Same Padding,取样的面积和输入图像的像素宽度一致。
- 卷积神经网络有两种神器可以减少参数数目,第一种神器叫做局部感知域。每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在
更高层将局部信息综合起来就得到了全局的信息。用局部感知域参数仍然较多,于是启动第二种神器,称作权值共享。(图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。)
卷积神经网络的核心思想是将局部感受域、权值共享(或者权值复制)以及时间或空间亚采样这三种结构思想巧妙地结合起来获得了某种程度的位移、尺度、形变不变性。
- 权值共享,即一个卷积层只用来提取前一层网络中不同位置处的同一种特征,这种限制策略称为权值共享。
NO.2 卷积神经网络的训练
CNN训练算法与传统的BP算法差不多。主要包括4步,这4步被分为两个阶段:
第一阶段:向前传播阶段
a)从样本集中取一个样本(X,Yp),将X输入网络;
b)计算相应的输出Op,即输入与每层的权值矩阵相点乘,得到最后的输出结果:

第二阶段:向后传播阶段
a)计算实际输出Op与相应的理想输出Yp的差;
b)按照极小化误差方法反向传播调整权值矩阵。
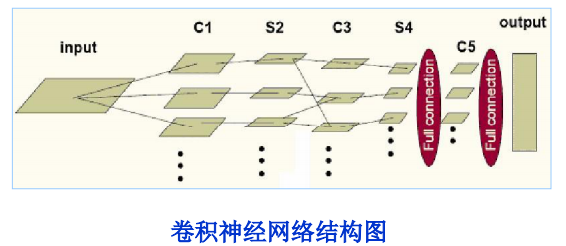
NO3.卷积神经网络的搭建
卷积神经网络一般由三种层搭建而成:卷积层,pooling层和全连接层。(详见:https://blog.csdn.net/han_xiaoyang/article/details/50542880)
最常见的组合方式是:用ReLU神经元的卷积层组一个神经网络,同时在卷积层和卷积层之间插入Pooling层,经过多次卷积层和池化层的叠加之后,
数据的总体量级就不大了,这个时候放一个全连接层,然后最后一层和output层之间是一个全连接层。
一个简单的CNN仅创建三层:卷积层(简称conv)、ReLU 层和最大池化层,涉及的主要步骤如下:
1. 读取输入图像;
2. 准备滤波器;
3. 卷积层:使用滤波器对输入图像执行卷积操作;
4. ReLU 层:将 ReLU 激活函数应用于特征图(卷积层的输出)(即,用于卷积层和池化层之间);
5. 最大池化层:在 ReLU 层的输出上应用池化操作;
6. 堆叠卷积层、ReLU 层和最大池化层。
补充概念0.图像卷积
图像卷积运算的几个主要参数分别是卷积核的大小(Filter Size)为(Fw,Fh),步长(Stride)为S,以及周围补零宽度(Padding)为P。
假设输入图像和输出特征图的宽和高分别为(Wi,Hi)和(W0,H0),则可以得到以下公式:
W0=(Wi-Fw+2P)/S+1
H0=(Hi-Fh+2P)/S+1
补充概念1.全连接层(参考:https://blog.csdn.net/GoodShot/article/details/79633313)
全连接的目的是什么呢?因为传统的网络我们的输出都是分类,也就是几个类别的概率甚至就是一个数--类别号,那么全连接层就是高度提纯的特征了,方便交给最后的分类器或者回归。但是全连接的参数实在是太多了,所以现在的趋势是尽量避免全连接,目前主流的一个方法是全局平均值。也就是最后那一层的feature map(最后一层卷积的输出结果),直接求平均值。有多少种分类就训练多少层,这十个数字就是对应的概率或者叫置信度。
每一层的神经元,其实只和上一层里某些小区域进行连接,而不是和上一层每个神经元全连接。
补充概念2.局部关联细节
刚才说到卷积层的局部关联问题,这个地方有一个receptive field,即『滑动数据窗口』。从输入的数据到输出数据,有三个超参数会决定输出数据的维度,
分别是深度/depth,步长/stride 和 填充值/zero-padding:
所谓深度/depth,简单说来指的就是卷积层中和上一层同一个输入区域连接的神经元个数。这部分神经元会在遇到输入中的不同feature时呈现activate状态,举个例子,如果这是第一个卷积层,那输入到它的数据实际上是像素值,不同的神经元可能对图像的边缘、轮廓或者颜色会敏感。
所谓步长/stride,是指的窗口从当前位置到下一个位置,『跳过』的中间数据个数。比如从图像数据层输入到卷积层的情况下,也许窗口初始位置在第1个像素,第二个位置在第5个像素,那么stride=5-1=4.
所谓zero-padding是在原始数据的周边补上0值的圈数
---------------------
补充概念3.ReLU层
MP神经元模型(https://www.baidu.com/linkurl=vznsux8UNC_uwOjfgtrhyu9zkW4TT6gkDRo3Oht4ult0fcYLyaLbpdBhcF9X9pOqETUtugWsDODoWi239qBybq&wd=&eqid=f61393520002d5d1000000055bc0202d)

为什么引入激活函数?(https://www.baidu.com/link?url=UU9rd_HoxOTBQREEXKjGwDYLyUxTtuxsq9voFfJHu_E6aeWAk3YhnROt1WuBIzT-GMWMLeVoiAbhpkWPo6oXmK&wd=&eqid=f61393520002d5d1000000055bc0202d)(https://www.baidu.com/link?url=siAdHpPWJIJwXvVmxRHKR2zfC6-31PFzguBxxhO4kBFYgPNWL2ZwN8uV4qLSQz47ISW_G6P-rFyjaCw_CGi5XCpABVQTDAIGsxmrL3ShT9e&wd=&eqid=f61393520002d5d1000000055bc0202d)
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。常见的激活函数有:tanh,sigmoid function,ReLU等。
为什么引入Relu呢?
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
ReLU(Recitified Linear Unit,ReLU),称为线性整流函数。常见的有斜坡函数f(x)=max{0,x}等。(参考:https://blog.csdn.net/u010105243/article/details/78548793)
当神经网络层数较多的时候,Sigmoid函数在反向传播中梯度值会逐渐减小,在经过多层的反向传递之后,梯度值在传递到神经网络的头几层的时候就会变得非常小,这样的话根据训练数据的反馈来更新神经网络的参数会变得异常缓慢,甚至起不到任何作用。这种情况我们一般称之为梯度弥散(Gtadient Vanishment),而ReLU函数的出现很大一部分程度上解决了梯度弥散的问题。(参考:https://www.jianshu.com/p/68d44a4295d1)
这种模式非常类似于人脑的阈值响应机制。信号在超过某一个阈值之后,神经元才会进入兴奋和激活的状态,平时则往往处于抑制状态。ReLU可以很好的传递梯度,经过多次的反向传播,梯度依旧不会大幅度的减小,适合适应训练很深的神经网络。
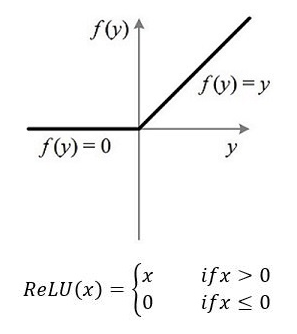
通过ReLU实现稀疏后的模型能够更好地挖掘相关特征,拟合训练数据。此外,相比于其它激活函数来说,ReLU有以下优势:对于线性函数而言,ReLU的表达能力更强,尤其体现在深度网络中;而对于非线性函数而言,ReLU由于非负区间的梯度为常数,因此不存在梯度消失问题(Vanishing Gradient Problem),使得模型的收敛速度维持在一个稳定状态
---------------------
https://blog.csdn.net/cherrylvlei/article/details/53149381?utm_source=copy
NO.3 卷积神经网络发展
卷积神经网络的演化过程主要有4个方向的演化:
- 网络加深 (如LeNet,AlexNet)
- 增强卷积层的功能,如VGGNet,卷积层从8到16一步步加深;GoogLeNet,将原来的线性卷积层变为多层感知卷积层,并且将全连接层改进为全局平均池化,其主要思想是加深深度,层数更深和增加宽度,增加了多种大小的卷积核
- 从分类任务到检测任务,这个演化方向经历了从R-CNN到Fast R-CNN,再到Faster R-CNN的演化。R-CNN可以看做是Region Proposal Networks(RPN)和CNN的力作,但是它的主要缺点是重复计算;Fast R-CNN是R-CNN的加速版本,将最后建议的区域映射到CNN的最后一个卷积层的特征映射上去,这样一张图片只需要提取一次特征,大大提高了速度,但是其瓶颈在R-CNN。Fast R-CNN支持多类物体的同时检测。Faster-R-CNN将RPN也交给CNN来做,可以达到实时。
- 增加新的功能模块,主要涉及FCN(反卷积),STNet,CNN与RNN/LSTM的混合架构。
NO4.数据增强与规范化
无论CNN还是普通的神经网络,都具有强大的函数拟合能力,但是这种能力潜在风险是容易出现过拟合,即网络的泛化能力变差,准确率在训练集以外的数据上严重下降。一个折中的办法就是在训练中使用数据增强技巧。其次,神经网络另一个难以训练的原因是反向传播时会出现梯度消失或者梯度爆炸的问题。规范化就是为了缓解此类梯度问题而提出的,用来规范神经网络的参数,加快网络的收敛。
数据增强(Data Augmentation):通过对图片的变换,创造出更多的训练样本。
批规范化(Batch Normalization,BN)就是在训练过程中对每个mini-batch的数据分布进行规范化。神经网络的实质是为了学习数据的分布。
在输入激活函数之前加入批规范化,可以保证网络层输入的分布是稳定的,从而能有效加速训练过程。
About CNN(convolutional neural network)的更多相关文章
- Deep Learning 学习随记(八)CNN(Convolutional neural network)理解
前面Andrew Ng的讲义基本看完了.Andrew讲的真是通俗易懂,只是不过瘾啊,讲的太少了.趁着看完那章convolution and pooling, 自己又去翻了翻CNN的相关东西. 当时看讲 ...
- 使用CNN(convolutional neural nets)关键的一点是检测到的面部教程(四):学习率,学习潜能,dropout
第七部分 让 学习率 和 学习潜能 随时间的变化 光训练就花了一个小时的时间.等结果并非一个令人心情愉快的事情.这一部分.我们将讨论将两个技巧结合让网络训练的更快! 直觉上的解决的方法是,開始训练时取 ...
- 卷积神经网络(Convolutional Neural Network,CNN)
全连接神经网络(Fully connected neural network)处理图像最大的问题在于全连接层的参数太多.参数增多除了导致计算速度减慢,还很容易导致过拟合问题.所以需要一个更合理的神经网 ...
- 【转载】 卷积神经网络(Convolutional Neural Network,CNN)
作者:wuliytTaotao 出处:https://www.cnblogs.com/wuliytTaotao/ 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可,欢迎 ...
- 4.5 RNN循环神经网络(recurrent neural network)
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: https://www.cnblogs.com/bclshuai/p/11380657.html 1.1 RNN循环神经网络 ...
- 小白也能弄懂的卷积神经网络(Convolutional Neural Networks )
本系列主要是讲解卷积神经网络 - Convolutional Neural Networks 的系列知识,本系列主要帮助大家入门,我相信这是所有入门深度学习的初学者都必须学习的知识,这里会用更加直接和 ...
- 深度学习:卷积神经网络(convolution neural network)
(一)卷积神经网络 卷积神经网络最早是由Lecun在1998年提出的. 卷积神经网络通畅使用的三个基本概念为: 1.局部视觉域: 2.权值共享: 3.池化操作. 在卷积神经网络中,局部接受域表明输入图 ...
- deeplearning.ai 序列模型 Week 1 RNN(Recurrent Neural Network)
1. Notations 循环序列模型的输入和输出都是时间序列.$x^{(i)<t>}$表示第$i$个输入样本的第$t$个元素,$T_x^{(i)}$表示输入的第$i$个样本的元素个数:$ ...
- RNN(Recurrent Neural Network)的几个难点
1. vanish of gradient RNN的error相对于某个时间点t的梯度为: \(\frac{\partial E_t}{\partial W}=\sum_{k=1}^{t}\frac{ ...
随机推荐
- onTouchEvent事件
@Override public boolean onTouchEvent(MotionEvent event) { if(event.getAction() == MotionEvent.ACTIO ...
- git + grunt 环境配置
1⃣️ssh key生成步骤 一.设置Git的user.name和user.email: $ git config --global user.name "xiongzuyan&qu ...
- hdu2614 Beat
题意: 有n个问题. 给出你解决完第i个问题之后解决j问题所花的时间,花的时间越多表示难度越大,每次只能解决难度大于或等于上个题难度的问题.问你最多能解决多少问题. 他妈的,第一次做想半天想不出来如何 ...
- luogu p1004
P1004 题意 类似一个比较小的方格(N<=9),有的点是0,有的点有数, A->B的路径经过的点加上该点代表的数,求两次A->B的最大解(最优解) 一个令人恼的问题是两条路径如果 ...
- Unity2D 小游戏之 RocketMouse
这个小游戏源自这里.这几天闲时捡了点 Unity(很久没有摸它了),顺手将这个小游戏移植到了 Unity5.5.0,除了 Parallax Scrolling 还有点小问题外,其它功能全部完整.部分代 ...
- IOS - autoresizingMask
提醒:当frame设定死,慎用autoresizingMask:否则该frame变形的难以想象.
- POJ 1883 排序 ( 水 + next_permutation )
链接:传送门 题意:略 思路:next_permutation(),水,但是要注意一点的是如果是最后一个排列next_permutation会返回第一个排列并结束,所以如果到了最后一个排列还不是第k个 ...
- SPOJ CIRU
SPOJ CIRU 题意 给出n个圆,求他们覆盖的面积. 解法 自适应Simpson,但需要将圆离散化一下,以保证我们查询的是一个连续的有圆的区间. 奇怪的是我没有离散化,样例都没有过,却把题给A了 ...
- ARM - Linux嵌入式C/C++各种资料分享【更新日期:2012/04/24】
http://blog.csdn.net/shuxiao9058/article/details/6786868 由于115网盘取消大众分享功能,因此不能继续分享下载链接.更新资料将在本人分享空间转存 ...
- springboot的几个缓存相关注解
@Cacheable:查询 几个属性: cacheNames/value:指定缓存组件的名字: key:缓存数据使用的key,可以用来指定.默认即使用方法参数的值 keyGenerator ...