Spark 介绍(基于内存计算的大数据并行计算框架)
Spark 介绍(基于内存计算的大数据并行计算框架)
Hadoop与Spark
行业广泛使用Hadoop来分析他们的数据集。原因是Hadoop框架基于一个简单的编程模型(MapReduce),它支持可扩展,灵活,容错和成本有效的计算解决方案。这里,主要关注的是在处理大型数据集时在查询之间的等待时间和运行程序的等待时间方面保持速度。
Spark由Apache Software Foundation引入,用于加速Hadoop计算软件过程。
对于一个普遍的信念,Spark不是Hadoop的修改版本,并不是真的依赖于Hadoop,因为它有自己的集群管理。 Hadoop只是实现Spark的方法之一。
Spark以两种方式使用Hadoop - 一个是存储,另一个是处理。由于Spark具有自己的集群管理计算,因此它仅使用Hadoop进行存储。
Apache Spark简介
Apache Spark是一种快速的集群计算技术,专为快速计算而设计。它基于Hadoop MapReduce,它扩展了MapReduce模型,以有效地将其用于更多类型的计算,包括交互式查询和流处理。 Spark的主要特性是它的内存中集群计算,提高了应用程序的处理速度。
Spark旨在涵盖各种工作负载,如批处理应用程序,迭代算法,交互式查询和流式处理。除了在相应系统中支持所有这些工作负载之外,它还减少了维护单独工具的管理负担。
Apache Spark的演变
Spark是Hadoop在2009年在加州大学伯克利分校的Matei Zaharia的AMPLab开发的子项目之一。它是在2010年根据BSD许可开放。它在2013年捐赠给Apache软件基金会,现在Apache Spark已经成为2014年2月的顶级Apache项目。
Apache Spark的特性
Apache Spark具有以下功能。
速度
Spark有助于在Hadoop集群中运行应用程序,在内存中速度提高100倍,在磁盘上运行时提高10倍。这可以通过减少对磁盘的读/写操作的数量来实现。它将中间处理数据存储在存储器中。
支持多种语言
Spark在Java,Scala或Python中提供了内置的API。因此,您可以使用不同的语言编写应用程序。 Spark提供了80个高级操作员进行交互式查询。
高级分析
Spark不仅支持“Map”和“reduce”。它还支持SQL查询,流数据,机器学习(ML)和图算法。
Spark基于Hadoop
下图显示了如何使用Hadoop组件构建Spark的三种方式。
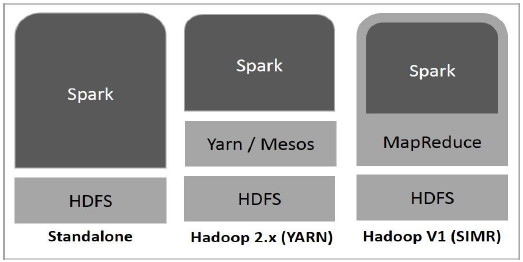
Spark部署有三种方式,如下所述。
Standalone- Spark独立部署意味着Spark占据HDFS(Hadoop分布式文件系统)顶部的位置,并明确为HDFS分配空间。 这里,Spark和MapReduce将并行运行以覆盖集群上的所有spark作业。
Hadoop Yarn- Hadoop Yarn部署意味着,spark只需运行在Yarn上,无需任何预安装或根访问。 它有助于将Spark集成到Hadoop生态系统或Hadoop堆栈中。 它允许其他组件在堆栈顶部运行。
Spark in MapReduce (SIMR) - MapReduce中的Spark用于在独立部署之外启动spark job。 使用SIMR,用户可以启动Spark并使用其shell而无需任何管理访问。
Spark的组件
下图说明了Spark的不同组件。
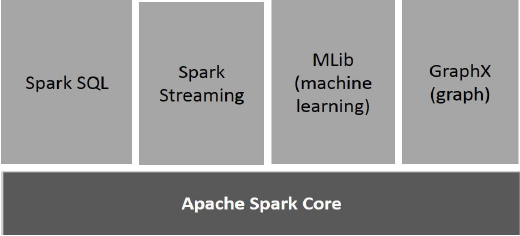
Apache Spark Core
Spark Core是spark平台的基础通用执行引擎,所有其他功能都是基于。它在外部存储系统中提供内存计算和引用数据集。
Spark SQL
Spark SQL是Spark Core之上的一个组件,它引入了一个称为SchemaRDD的新数据抽象,它为结构化和半结构化数据提供支持。
Spark Streaming
Spark Streaming利用Spark Core的快速调度功能来执行流式分析。它以小批量获取数据,并对这些小批量的数据执行RDD(弹性分布式数据集)转换。
MLlib (Machine Learning Library)
MLlib是Spark之上的分布式机器学习框架,因为基于分布式内存的Spark架构。根据基准,它是由MLlib开发人员针对交替最小二乘法(ALS)实现完成的。 Spark MLlib是基于Hadoop磁盘的Apache Mahout版本的9倍(在Mahout获得了Spark接口之前)。
GraphX
GraphX是Spark上的一个分布式图形处理框架。它提供了一个用于表达图形计算的API,可以通过使用Pregel抽象API为用户定义的图形建模。它还为此抽象提供了一个优化的运行时。
Spark 介绍(基于内存计算的大数据并行计算框架)的更多相关文章
- 大数据并行计算框架Spark
Spark2.1. http://dblab.xmu.edu.cn/blog/1689-2/ 0+入门:Spark的安装和使用(Python版) Spark2.1.0+入门:第一个Spark应用程序: ...
- 【转】Spark是基于内存的分布式计算引擎
Spark是基于内存的分布式计算引擎,以处理的高效和稳定著称.然而在实际的应用开发过程中,开发者还是会遇到种种问题,其中一大类就是和性能相关.在本文中,笔者将结合自身实践,谈谈如何尽可能地提高应用程序 ...
- 如何基于Go搭建一个大数据平台
如何基于Go搭建一个大数据平台 - Go中国 - CSDN博客 https://blog.csdn.net/ra681t58cjxsgckj31/article/details/78333775 01 ...
- 坐实大数据资源调度框架之王,Yarn为何这么牛
摘要:Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为大数据的代名词. 本文分享自华为云社区<Yarn为何能坐实资源调度框架之王?>,作者: Java ...
- 《SPARK/TACHYON:基于内存的分布式存储系统》-史鸣飞(英特尔亚太研发有限公司大数据软件部工程师)
史鸣飞:大家好,我是叫史鸣飞,来自英特尔公司,接下来我向大家介绍一下Tachyon.我事先想了解一下大家有没有听说过Tachyon,或者是对Tachyon有没有一些了解?对Spark呢? 首先做一个介 ...
- 基于InfluxDB+Grafana打造大数据监控利器--转
这是一个大数据爆发的时代.面对信息的激流.多元化数据的涌现,我们在获取.存储.传输.理解.分析.应用.维护大数据时,无疑需要一种便捷的信息交流通道,以便快速.有效.准确地理解和驾驭这个过程.本文将通过 ...
- 基于MaxCompute的媒体大数据开放平台建设
摘要:随着自媒体的发展,传统媒体面临着巨大的压力和挑战,新华智云运用大数据和人工智能技术,致力于为媒体行业赋能.通过媒体大数据开放平台,将媒体行业全网数据汇总起来,借助平台数据处理能力和算法能力,将有 ...
- 云计算OpenStack---云计算、大数据、人工智能(14)
一.互联网行业及云计算 在互联网时代,技术是推动社会发展的驱动,云计算则是一个包罗万象的技术栈集合,通过网络提供IAAS.PAAS.SAAS等资源,涵盖从数据中心底层的硬件设置到最上层客户的应用.给我 ...
- 三:基于Storm的实时处理大数据的平台架构设计
一:元数据管理器==>元数据管理器是系统平台的“大脑”,在任务调度中有着重要的作用[1]什么是元数据?--->中介数据,用于描述数据属性的数据.--->具体类型:描述数据结构,数据的 ...
随机推荐
- 配置IISserver
我们自己开发站点的时候 要在自己的电脑上写网页 然后我们怎么能像我们浏览互联网上的网页一样.而不是直接双击打开网页呢 这时候就要配置IISserver 让自己能够 预览自己站点的效果 以下是 ...
- ext: gridpanel中的点击事件的参数是什么意思?
listeners: { // 当用户单击列表项时激发该函数 itemclick: function(view, record, item, index, evt) //① ...
- go环境变量配置 (GOROOT和GOPATH)
GOROOT就是go的安装路径在~/.bash_profile中添加下面语句: GOROOT=/usr/local/go export GOROOT 当然, 要执行go命令和go工具, 就要配置go的 ...
- 3dmax,查看场景中所有材质
- Unity GPU Instancing的使用尝试
似乎是在Unity5.4中开始支持GPU Instacing,但如果要比较好的使用推荐用unity5.6版本,因为这几个版本一直在改. 这里测试也是使用unity5.6.2进行测试 在5.6的版本里, ...
- 牛腩学Kotlin做Android应用
牛腩学Kotlin做Android应用,蹭热度视频,边学边做, 01-kotlin插件安装及hello world 02-kotlin基础语法速览 哔哩哔哩观看地址:http://www.bilibi ...
- LeetCode——4Sum & 总结
LeetCode--4Sum & 总结 前言 有人对 Leetcode 上 2Sum,3Sum,4Sum,K Sum问题作了总结: http://blog.csdn.net/nanjunxia ...
- 隐藏和显示服务器端控件以及Html控件
隐藏和显示服务器端控件以及Html控件 /// <summary> /// 隐藏控件 /// </summary> /// <param name="contr ...
- 每日英语:How Your Knees Can Predict the Weather
The Wolff family of Paramus, N.J., was eyeing the gathering clouds and debating whether to cancel a ...
- iOS开发-图片浏览器(优化)
// // ViewController.m // 19-图片浏览器 // // Created by hongqiangli on 2017/7/31. // Copyright © 201 ...