基于TextRank提取关键词、关键短语、摘要
一、TextRank原理
TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要。因为TextRank是基于PageRank的,所以首先简要介绍下PageRank算法。
1. PageRank算法
PageRank设计之初是用于Google的网页排名的,以该公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。PageRank通过互联网中的超链接关系来确定一个网页的排名,其公式是通过一种投票的思想来设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道有哪些网页链接到网页A,也就是要首先得到网页A的入链,然后通过入链给网页A的投票来计算网页A的PR值。这样设计可以保证达到这样一个效果:当某些高质量的网页指向网页A的时候,那么网页A的PR值会因为这些高质量的投票而变大,而网页A被较少网页指向或被一些PR值较低的网页指向的时候,A的PR值也不会很大,这样可以合理地反映一个网页的质量水平。那么根据以上思想,佩奇设计了下面的公式:
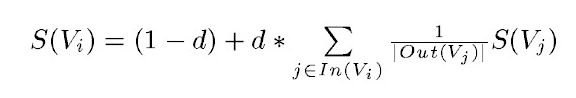
该公式中,Vi表示某个网页,Vj表示链接到Vi的网页(即Vi的入链),S(Vi)表示网页Vi的PR值,In(Vi)表示网页Vi的所有入链的集合,Out(Vj)表示网页,d表示阻尼系数,是用来克服这个公式中“d *”后面的部分的固有缺陷用的:如果仅仅有求和的部分,那么该公式将无法处理没有入链的网页的PR值,因为这时,根据该公式这些网页的PR值为0,但实际情况却不是这样,所有加入了一个阻尼系数来确保每个网页都有一个大于0的PR值,根据实验的结果,在0.85的阻尼系数下,大约100多次迭代PR值就能收敛到一个稳定的值,而当阻尼系数接近1时,需要的迭代次数会陡然增加很多,且排序不稳定。公式中S(Vj)前面的分数指的是Vj所有出链指向的网页应该平分Vj的PR值,这样才算是把自己的票分给了自己链接到的网页。
2. TextRank算法
2.1 TextRank算法提取关键词
TextRank是由PageRank改进而来,其公式有颇多相似之处,这里给出TextRank的公式:
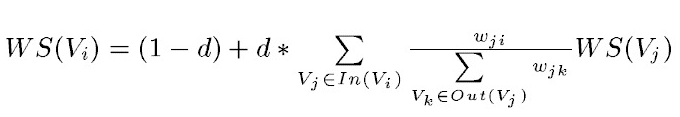
可以看出,该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度。TextRank用于关键词提取的算法如下:
1)把给定的文本T按照完整句子进行分割,即 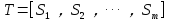
2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即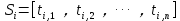 ,其中 ti,j 是保留后的候选关键词。
,其中 ti,j 是保留后的候选关键词。
3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
4)根据上面公式,迭代传播各节点的权重,直至收敛。
5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
6)由5得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
2.2 TextRank算法提取关键词短语
提取关键词短语的方法基于关键词提取,可以简单认为:如果提取出的若干关键词在文本中相邻,那么构成一个被提取的关键短语。
2.3 TextRank生成摘要
将文本中的每个句子分别看做一个节点,如果两个句子有相似性,那么认为这两个句子对应的节点之间存在一条无向有权边。考察句子相似度的方法是下面这个公式:
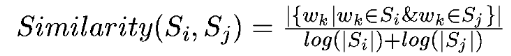
公式中,Si,Sj分别表示两个句子,Wk表示句子中的词,那么分子部分的意思是同时出现在两个句子中的同一个词的个数,分母是对句子中词的个数求对数之和。分母这样设计可以遏制较长的句子在相似度计算上的优势。
我们可以根据以上相似度公式循环计算任意两个节点之间的相似度,根据阈值去掉两个节点之间相似度较低的边连接,构建出节点连接图,然后计算TextRank值,最后对所有TextRank值排序,选出TextRank值最高的几个节点对应的句子作为摘要。
参考:
https://www.cnblogs.com/xueyinzhe/p/7101295.html
http://blog.csdn.net/u013041398/article/details/52473994
二、包安装
sudo pip install textrank4zh
三、提取关键词、关键短语、摘要
from textrank4zh import TextRank4Keyword, TextRank4Sentence text = "xxxxxx" # text = codecs.open(text_file, "r", "utf-8").read() tr4w = TextRank4Keyword()
tr4w.analyze(text=text, window=5, lower=True) print "关键词:"
for item in tr4w.get_keywords(num=20, word_min_len=1):
print item.word, item.weight print "关键短语:\n", ", ".join(tr4w.get_keyphrases(keywords_num=20, min_occur_num=2)) tr4s = TextRank4Sentence()
tr4s.analyze(text=text, lower=True, source="all_filters") print "摘要:"
for item in tr4s.get_key_sentences(num=3):
print item.index, item.weight, item.sentence # index是语句在文本中位置,weight是权重
查看源码,TextRank4Keyword的说明:
class TextRank4Keyword(object):
def __init__(self, stop_words_file = None,
allow_speech_tags = util.allow_speech_tags,
delimiters = util.sentence_delimiters):
"""
Keyword arguments:
stop_words_file -- str,指定停止词文件路径(一行一个停止词),若为其他类型,则使用默认停止词文件
delimiters -- 默认值是`?!;?!。;…\n`,用来将文本拆分为句子。 Object Var:
self.words_no_filter -- 对sentences中每个句子分词而得到的两级列表。
self.words_no_stop_words -- 去掉words_no_filter中的停止词而得到的两级列表。
self.words_all_filters -- 保留words_no_stop_words中指定词性的单词而得到的两级列表。
""" def analyze(self, text,
window = 2,
lower = False,
vertex_source = 'all_filters',
edge_source = 'no_stop_words',
pagerank_config = {'alpha': 0.85,}):
"""分析文本
Keyword arguments:
text -- 文本内容,字符串。
window -- 窗口大小,int,用来构造单词之间的边。默认值为2。
lower -- 是否将文本转换为小写。默认为False。
vertex_source -- 选择使用words_no_filter, words_no_stop_words, words_all_filters中的哪一个来构造pagerank对应的图中的节点。
默认值为`'all_filters'`,可选值为`'no_filter', 'no_stop_words', 'all_filters'`。关键词也来自`vertex_source`。
edge_source -- 选择使用words_no_filter, words_no_stop_words, words_all_filters中的哪一个来构造pagerank对应的图中的节点之间的边。
默认值为`'no_stop_words'`,可选值为`'no_filter', 'no_stop_words', 'all_filters'`。边的构造要结合`window`参数。
""" def get_keywords(self, num = 6, word_min_len = 1):
"""获取最重要的num个长度大于等于word_min_len的关键词。
Return:
关键词列表。
""" def get_keyphrases(self, keywords_num = 12, min_occur_num = 2):
"""获取关键短语。
获取 keywords_num 个关键词构造的可能出现的短语,要求这个短语在原文本中至少出现的次数为min_occur_num。
Return:
关键短语的列表。
"""
TextRank4Sentence的说明:
class TextRank4Sentence(object):
def __init__(self, stop_words_file = None,
allow_speech_tags = util.allow_speech_tags,
delimiters = util.sentence_delimiters):
"""
Keyword arguments:
stop_words_file -- str,停止词文件路径,若不是str则是使用默认停止词文件
delimiters -- 默认值是`?!;?!。;…\n`,用来将文本拆分为句子。 Object Var:
self.sentences -- 由句子组成的列表。
self.words_no_filter -- 对sentences中每个句子分词而得到的两级列表。
self.words_no_stop_words -- 去掉words_no_filter中的停止词而得到的两级列表。
self.words_all_filters -- 保留words_no_stop_words中指定词性的单词而得到的两级列表。
""" def analyze(self, text, lower = False,
source = 'no_stop_words',
sim_func = util.get_similarity,
pagerank_config = {'alpha': 0.85,}):
"""
Keyword arguments:
text -- 文本内容,字符串。
lower -- 是否将文本转换为小写。默认为False。
source -- 选择使用words_no_filter, words_no_stop_words, words_all_filters中的哪一个来生成句子之间的相似度。
默认值为`'all_filters'`,可选值为`'no_filter', 'no_stop_words', 'all_filters'`。
sim_func -- 指定计算句子相似度的函数。
""" def get_key_sentences(self, num = 6, sentence_min_len = 6):
"""获取最重要的num个长度大于等于sentence_min_len的句子用来生成摘要。
Return:
多个句子组成的列表。
"""
参考:
letiantian/TextRank4ZH: 从中文文本中自动提取关键词和摘要
基于TextRank提取关键词、关键短语、摘要的更多相关文章
- TextRank:关键词提取算法中的PageRank
很久以前,我用过TFIDF做过行业关键词提取.TFIDF仅仅从词的统计信息出发,而没有充分考虑词之间的语义信息.现在本文将介绍一种考虑了相邻词的语义关系.基于图排序的关键词提取算法TextRank [ ...
- TextRank算法提取关键词的Java实现
转载:码农场 » TextRank算法提取关键词的Java实现 谈起自动摘要算法,常见的并且最易实现的当属TF-IDF,但是感觉TF-IDF效果一般,不如TextRank好. TextRank是在 G ...
- TextRank算法及生产文本摘要方法介绍
TextRank 算法是一种用于文本的基于图的排序算法,其基本思想来源于谷歌的 PageRank算法,通过把文本分割成若干组成单元(句子),构建节点连接图,用句子之间的相似度作为边的权重,通过循环迭代 ...
- 文本自动摘要:基于TextRank的中文新闻摘要
TextRank算法源自于PageRank算法.PageRank算法最初是作为互联网网页排序的方法,经过轻微地改动,可以被应用于文本摘要领域. 本文分为两部分,第一部分介绍TextRank做文本自动摘 ...
- TF-IDF与余弦类似性的应用(一):自己主动提取关键词
作者: 阮一峰 日期: 2013年3月15日 原文链接:http://www.ruanyifeng.com/blog/2013/03/tf-idf.html 这个标题看上去好像非常复杂,事实上我要谈的 ...
- 基于TextRank算法的文本摘要
本文介绍TextRank算法及其在多篇单领域文本数据中抽取句子组成摘要中的应用. TextRank 算法是一种用于文本的基于图的排序算法,通过把文本分割成若干组成单元(句子),构建节点连接图,用句子之 ...
- 基于Webkit的浏览器关键渲染路径介绍
关键渲染路径概念 浏览器是如何将HTML.JS.CSS.image等资源渲染成可视化的页面的呢?本文简单介绍一下渲染过程中涉及到的关键步骤. 该过程分为四步:模型对象的构建.渲染树构建.布局.绘制. ...
- 【数据共享】基于Landsat提取的全球河网(河宽)GDWL数据库
GRWL数据库,全称Global River Widths from Landsat Database,是由Allen, George H & Pavelsky. Tamlin M等人基于La ...
- 巧用VBA实现:基于多个关键词模糊匹配Excel多行数据
在用Excel处理实际业务中,我们会碰到如下场景: 1.从一堆人名中找到包含某些关键字的名字: 2.从银行流水文件中根据[备注]字段找到包含某些关键字的,统一识别为[手续费业务]等. 这本质说的都是一 ...
随机推荐
- ubuntu16.04上安装maven
官网:http://maven.apache.org/download.cgi 创建manve目录:sudo mkdir /opt/maven 解压到/opt/maven目录下:sudo tar zx ...
- 【Golang】幽灵变量(变量覆盖)问题的一劳永逸解决方法
背景 在我们公司,测试定位问题的能力在考核中占了一定的比例,所以我们定位问题的主动性会比较高.因为很多开发同学都是刚开始使用golang,所以bug频出,其中又以短变量声明语法导致的错误最多.所以就专 ...
- JavaScript运算符与类型
1.运算符优先级 首先讲一下运算符的优先级,它决定了表达式中运算执行的先后顺序,优先级高的运算符最先被执行. 下面的表将所有运算符按照优先级的不同从高到低排列: 优先级 运算类型 关联性 运算符 19 ...
- spring boot:创建一个简单的web(maven web project)
1.新建一个maven web project; 2.在pom.xml文件中添加相应的依赖包: 3.新建一个HelloController请求控制类: 4.编写index.jsp页面: 5.编写启动类 ...
- 雷林鹏分享:C# 正则表达式
C# 正则表达式 正则表达式 是一种匹配输入文本的模式..Net 框架提供了允许这种匹配的正则表达式引擎.模式由一个或多个字符.运算符和结构组成. 定义正则表达式 下面列出了用于定义正则表达式的各种类 ...
- [.NET开发] C#编程调用Cards.dll实现图形化发牌功能示例
本文实例讲述了C#编程调用Cards.dll实现图形化发牌功能.分享给大家供大家参考,具体如下: using System; using System.Collections.Generic; usi ...
- English trip -- Review Unit2 At school 在学校
What do you need,Loki? I need an eraser What does he need? He needs a dictionary Where's my pencil? ...
- 20170324xlVBA最简单分类计数
Sub NextSeven_CodeFrame() Application.ScreenUpdating = False Application.DisplayAlerts = False Appli ...
- Vue.js Client-Side Storage;( Web Storage/localStorage)
原文:https://cn.vuejs.org/v2/cookbook/client-side-storage.html LocalStorage (api) my code pen :https:/ ...
- synchronized同步代码块锁释放
今天发现自己写的线上程序出现数据库不能同步的问题,查看日志已经停止记录,随后使用jstack查看线程的运行状况,发现有个同步线程锁住了. 以下是jstack -l 637 问题线程的内容. &quo ...