(第3篇)HDFS是什么?HDFS适合做什么?我们应该怎样操作HDFS系统?
摘要: 这篇文章会详细介绍HDFS是什么,HDFS的作用,适合和不适合的场景,我们该如何操作HDFS?
HDFS文件系统
Hadoop 附带了一个名为 HDFS(Hadoop分布式文件系统)的分布式文件系统,专门存储超大数据文件,为整个Hadoop生态圈提供了基础的存储服务。
本章内容:
1) HDFS文件系统的特点,以及不适用的场景
2) HDFS文件系统重点知识点:体系架构和数据读写流程
3) 关于操作HDFS文件系统的一些基本用户命令
1. HDFS特点:
HDFS专为解决大数据存储问题而产生的,其具备了以下特点:
1) HDFS文件系统可存储超大文件
每个磁盘都有默认的数据块大小,这是磁盘在对数据进行读和写时要求的最小单位,文件系统是要构建于磁盘上的,文件系统的也有块的逻辑概念,通常是磁盘块的整数倍,通常文件系统为几千个字节,而磁盘块一般为512个字节。
HDFS是一种文件系统,自身也有块(block)的概念,其文件块要比普通单一磁盘上文件系统大的多,默认是64MB。
HDFS上的块之所以设计的如此之大,其目的是为了最小化寻址开销。
HDFS文件的大小可以大于网络中任意一个磁盘的容量,文件的所有块并不需要存储在一个磁盘上,因此可以利用集群上任意一个磁盘进行存储,由于具备这种分布式存储的逻辑,所以可以存储超大的文件,通常G、T、P级别。
2) 一次写入,多次读取
一个文件经过创建、写入和关闭之后就不需要改变,这个假设简化了数据一致性的问题,同时提高数据访问的吞吐量。
3) 运行在普通廉价的机器上
Hadoop的设计对硬件要求低,无需昂贵的高可用性机器上,因为在HDFS设计中充分考虑到了数据的可靠性、安全性和高可用性。
2. 不适用于HDFS的场景:
1) 低延迟
HDFS不适用于实时查询这种对延迟要求高的场景,例如:股票实盘。往往应对低延迟数据访问场景需要通过数据库访问索引的方案来解决,Hadoop生态圈中的Hbase具有这种随机读、低延迟等特点。
2) 大量小文件
对于Hadoop系统,小文件通常定义为远小于HDFS的block size(默认64MB)的文件,由于每个文件都会产生各自的MetaData元数据,Hadoop通过Namenode来存储这些信息,若小文件过多,容易导致Namenode存储出现瓶颈。
3) 多用户更新
为了保证并发性,HDFS需要一次写入多次读取,目前不支持多用户写入,若要修改,也是通过追加的方式添加到文件的末尾处,出现太多文件需要更新的情况,Hadoop是不支持的。
针对有多人写入数据的场景,可以考虑采用Hbase的方案。
4) 结构化数据
HDFS适合存储半结构化和非结构化数据,若有严格的结构化数据存储场景,也可以考虑采用Hbase的方案。
5) 数据量并不大
通常Hadoop适用于TB、PB数据,若待处理的数据只有几十GB的话,不建议使用Hadoop,因为没有任何好处。
3. HDFS体系架构
HDFS是一个主/从(Master/Slave)体系架构,由于分布式存储的性质,集群拥有两类节点NameNode和DataNode。
NameNode(名字节点):系统中通常只有一个,中心服务器的角色,管理存储和检索多个DataNode的实际数据所需的所有元数据。
DataNode(数据节点):系统中通常有多个,是文件系统中真正存储数据的地方,在NameNode统一调度下进行数据块的创建、删除和复制。
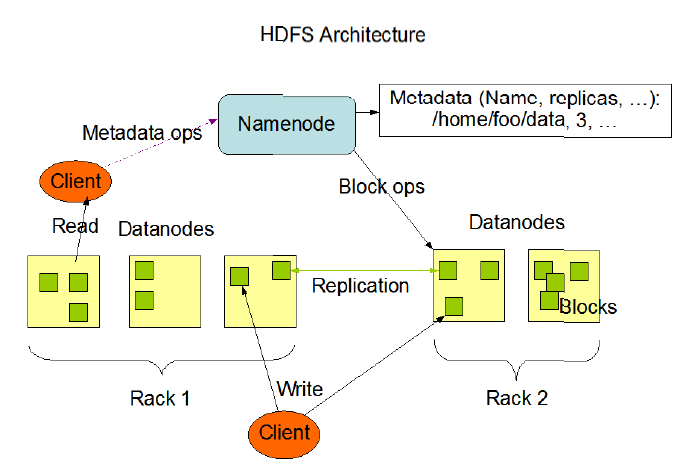
图中的Client是HDFS的客户端,是应用程序可通过该模块与NameNode和DataNode进行交互,进行文件的读写操作。
4. HDFS数据块复制
为了系统容错,文件系统会对所有数据块进行副本复制多份,Hadoop是默认3副本管理。
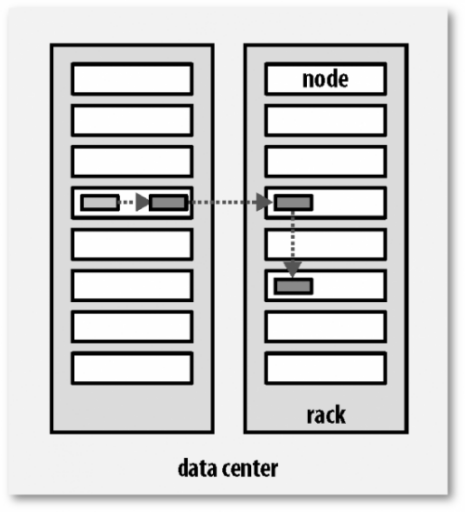
复本管理策略是运行客户端的节点上放一个复本(若客户端运行在集群之外,会随机选择一个节点),第二个复本会放在与第一个不同且随机另外选择的机架中节点上,第三个复本与第二个复本放在相同机架,切随机选择另一个节点。所存在其他复本,则放在集群中随机选择的节点上,不过系统会尽量避免在相同机架上放太多复本。
所有有关块复制的决策统一由NameNode负责,NameNode会周期性地接受集群中数据节点DataNode的心跳和块报告。一个心跳的到达表示这个数据节点是正常的。一个块报告包括该数据节点上所有块的列表。
5. HDFS读取和写入流程
1) 读文件的过程:
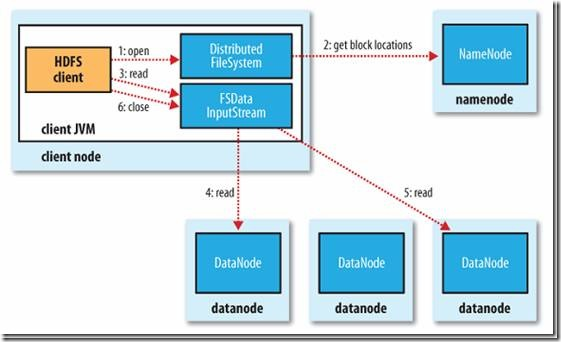
首先Client通过File System的Open函数打开文件,Distributed File System用RPC调用NameNode节点,得到文件的数据块信息。对于每一个数据块,NameNode节点返回保存数据块的数据节点的地址。Distributed File System返回FSDataInputStream给客户端,用来读取数据。客户端调用stream的read()函数开始读取数据。DFSInputStream连接保存此文件第一个数据块的最近的数据节点。DataNode从数据节点读到客户端(client),当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
2) 写文件的过程:
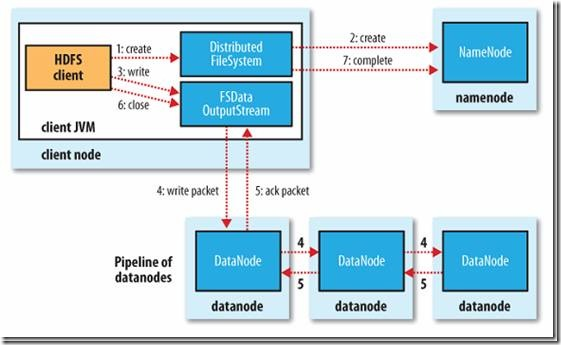
客户端调用create()来创建文件,Distributed File System用RPC调用NameNode节点,在文件系统的命名空间中创建一个新的文件。NameNode节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
Distributed File System返回DFSOutputStream,客户端用于写数据。客户端开始写入数据,DFSOutputStream将数据分成块,写入Data Queue。Data Queue由Data Streamer读取,并通知NameNode节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个Pipeline里。Data Streamer将数据块写入Pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
DFSOutputStream为发出去的数据块保存了Ack Queue,等待Pipeline中的数据节点告知数据已经写入成功。
6. 操作HDFS的基本命令
1) 打印文件列表(ls)
|
标准写法: hadoop fs -ls hdfs:/#hdfs: 明确说明是HDFS系统路径 简写: hadoop fs -ls /#默认是HDFS系统下的根目录 打印指定子目录: hadoop fs -ls /package/test/#HDFS系统下某个目录 |
2) 上传文件、目录(put、copyFromLocal)
put用法:
|
上传新文件: hdfs fs -put file:/root/test.txt hdfs:/ #上传本地test.txt文件到HDFS根目录,HDFS根目录须无同名文件,否则“File exists” hdfs fs -put test.txt /test2.txt #上传并重命名文件。 hdfs fs -put test1.txt test2.txt hdfs:/ #一次上传多个文件到HDFS路径。 上传文件夹: hdfs fs -put mypkg /newpkg #上传并重命名了文件夹。 覆盖上传: hdfs fs -put -f /root/test.txt / #如果HDFS目录中有同名文件会被覆盖 |
copyFromLocal用法:
|
上传文件并重命名: hadoop fs -copyFromLocal file:/test.txt hdfs:/test2.txt 覆盖上传: hadoop fs -copyFromLocal -f test.txt /test.txt |
3) 下载文件、目录(get、copyToLocal)
get用法:
|
拷贝文件到本地目录: hadoop fs -get hdfs:/test.txt file:/root/ 拷贝文件并重命名,可以简写: hadoop fs -get /test.txt /root/test.txt |
copyToLocal用法
|
拷贝文件到本地目录: hadoop fs -copyToLocal hdfs:/test.txt file:/root/ 拷贝文件并重命名,可以简写: hadoop fs -copyToLocal /test.txt /root/test.txt |
4) 拷贝文件、目录(cp)
|
从本地到HDFS,同put hadoop fs -cp file:/test.txt hdfs:/test2.txt 从HDFS到HDFS hadoop fs -cp hdfs:/test.txt hdfs:/test2.txt hadoop fs -cp /test.txt /test2.txt |
5) 移动文件(mv)
|
hadoop fs -mv hdfs:/test.txt hdfs:/dir/test.txt hadoop fs -mv /test.txt /dir/test.txt |
6) 删除文件、目录(rm)
|
删除指定文件 hadoop fs -rm /a.txt 删除全部txt文件 hadoop fs -rm /*.txt 递归删除全部文件和目录 hadoop fs -rm -R /dir/ |
7) 读取文件(cat、tail)
|
hadoop fs -cat /test.txt #以字节码的形式读取 hadoop fs -tail /test.txt |
8) 创建空文件(touchz)
|
hadoop fs - touchz /newfile.txt |
9) 创建文件夹(mkdir)
|
hadoop fs -mkdir /newdir /newdir2#可以同时创建多个 hadoop fs -mkdir -p /newpkg/newpkg2/newpkg3 #同时创建父级目录 |
10) 获取逻辑空间文件、目录大小(du)
|
hadoop fs - du / #显示HDFS根目录中各文件和文件夹大小 hadoop fs -du -h / #以最大单位显示HDFS根目录中各文件和文件夹大小 hadoop fs -du -s / #仅显示HDFS根目录大小。即各文件和文件夹大小之和 |
这时,你已经了解了HDFS和HDFS的操作命令,接下来我会继续介绍Mapreduce计算框架,Mapreduce在hadoop中又起到什么作用呢?
(第3篇)HDFS是什么?HDFS适合做什么?我们应该怎样操作HDFS系统?的更多相关文章
- 介绍一款非常适合做微网站并且免费的CMS系统
在微网站火热的今天,寻找一款具备 web app功能的CMS系统能够大大提高我们的工作效率,eBSite升级到3.0后,开始支持web app 皮肤,也就是创建一个站点,会同时绑定一个PC版皮肤与一个 ...
- 大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一.HDFS概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 ...
- java操作hdfs实例
环境:window7+eclipse+vmware虚拟机+搭建好的hadoop环境(master.slave01.slave02) 内容:主要是在windows环境下,利用eclipse如何来操作hd ...
- spark中操作hdfs
1 获取路径 val output = new Path("hdfs://master:9000/output/"); val hdfs = org.apache.hadoop.f ...
- eclipse下使用API操作HDFS
1)使用eclipse,在HDFS上创建新目录 import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Fil ...
- Hadoop操作hdfs的命令【转载】
本文系转载,原文地址被黑了,故无法贴出原始链接. Hadoop操作HDFS命令如下所示: hadoop fs 查看Hadoop HDFS支持的所有命令 hadoop fs –ls 列出目录及文件信息 ...
- 使用javaAPI操作hdfs
欢迎到https://github.com/huabingood/everyDayLanguagePractise查看源码. 一.构建环境 在hadoop的安装包中的share目录中有hadoop所有 ...
- 使用shell操作HDFS
前提是都已经配置好了,可以参考hadoop伪分布安装:http://blog.csdn.net/jerome_s/article/details/25788967 linux的文件系统与hdfs的关系 ...
- 关于操作HDFS的一个问题
近日写程序定时任务调Hadoop MR程序,然后生成报表,发送邮件,当时起了两个任务A和B,调MR程序之前,会操作hdfs(读写都有),任务A每天一点跑,任务B每十分钟跑一次,B任务不会调用MR程序, ...
随机推荐
- win8中的gridview和listview控件微软链接
快速入门:添加 ListView 和 GridView 控件 http://msdn.microsoft.com/zh-cn/library/windows/apps/hh780650.aspx XA ...
- mysql的骚操作:自增长的字段同时插入到另一个字段
如题 ' ); select * from information_schema.tables where table_schema ='mytest' and table_name='users'; ...
- Android——Fragment过度动画分析一(转)
Sliding Fragment 作者:小文字 出处:http://www.cnblogs.com/avenwu/ 介绍:该案例为传统的Fragment增加了个性化的补间动画,其效果是原有frag ...
- [开发笔记]-C#判断文件类型
判断文件真实的类型,不是通过扩展名来判断: /// <summary> /// 判断文件格式 /// http://www.cnblogs.com/babycool /// </su ...
- idea properties文件unicode码问题
在git hub上下载了个工程.但是properties文件一直显示不了中文: # \u662F\u5426\u4F7F\u7528\u8FDC\u7A0B\u914D\u7F6E\u6587\u4E ...
- 理解ThreadPoolExecutor源代码(二)execute函数的巧妙设计和阅读心得
ThreadPoolExecutor.execute()源代码提供了大量凝视来解释该方法的设计考虑.以下的源代码来自jdk1.6.0_37 public void execute(Runnable c ...
- MySql5.7配置文件my.cnf设置
# MySql5.7配置文件my.cnf设置[client]port = 3306socket = /tmp/mysql.sock [mysqld]########################## ...
- openvpn 客户端配置
clientdev tunproto tcpremote xx.xx.xx.xx 1194resolv-retry infinitenobindpersist-keypersist-tunca c ...
- 微信小程序——购物车数字加减
上一篇,我们有讲到如何造一个购物车弹层.今天来说一下,购物车数量的加减如何实现. 主要思路就是在data里面定义一个属性,属性值就是这个数量.点击+的时候就+1,点击-的时候就-1,再结合setDat ...
- 通过 Spark R 操作 Hive
作为数据工程师,我日常用的主力语言是R,HiveQL,Java与Scala.R是非常适合做数据清洗的脚本语言,并且有非常好用的服务端IDE——RStudio Server:而用户日志主要储存在hive ...