Lucene系列二:Lucene(Lucene介绍、Lucene架构、Lucene集成)
一、Lucene介绍
1. Lucene简介
最受欢迎的java开源全文搜索引擎开发工具包。提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索功能,或者是以此为基础建立起完整的全文检索引擎。是Apache的子项目,网址:http://lucene.apache.org/
2. Lucene用途
为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索功能,或者是以此为基础建立起完整的全文检索引擎。
3. Lucene适用场景
在应用中为数据库中的数据提供全文检索实现。
开发独立的搜索引擎服务、系统
4. Lucene的特性
1、稳定、索引性能高
每小时能够索引150GB以上的数据。
对内存的要求小——只需要1MB的堆内存
增量索引和批量索引一样快。
索引的大小约为索引文本大小的20%~30%。
2、高效、准确、高性能的搜索算法
良好的搜索排序。
强大的查询方式支持:短语查询、通配符查询、临近查询、范围查询等。
支持字段搜索(如标题、作者、内容)。
可根据任意字段排序
支持多个索引查询结果合并
支持更新操作和查询操作同时进行
支持高亮、join、分组结果功能
速度快
可扩展排序模块,内置包含向量空间模型、BM25模型可选
可配置存储引擎
3、跨平台
纯java编写。
作为Apache开源许可下的开源项目,你可在商业或开源项目中使用。
Lucene有多种语言实现版可选(如C、C++、Python等),不光是JAVA。
二、Lucene架构

1. 数据收集
2. 创建索引
3. 索引存储
4. 搜索(使用索引)
三、Lucene集成
1. 选用的Lucene版本
选用当前最新版 7.3.0 : https://lucene.apache.org/
2. 系统要求
JDK1.8 及以上版本
3. 集成:将lucene core的jar引入到你的应用中
方式一:官网下载 zip,解压后拷贝jar到你的工程
方式二:maven 引入依赖
4. Lucene 模块说明
core: Lucene core library 核心模块:分词、索引、查询
analyzers-*: 分词器
facet: Faceted indexing and search capabilities 提供分类索引、搜索能力
grouping: Collectors for grouping search results. 搜索结果分组支持
highlighter: Highlights search keywords in results 关键字高亮支持
join: Index-time and Query-time joins for normalized content 连接支持
queries: Filters and Queries that add to core Lucene 补充的查询、过滤方式实现
queryparser: Query parsers and parsing framework 查询表达式解析模块
spatial: Geospatial search 地理位置搜索支持 suggest: Auto-suggest and Spellchecking support 拼写检查、联想提示
5. 先引入lucene的核心模块
<!-- lucene 核心模块 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.3.0</version>
</dependency>
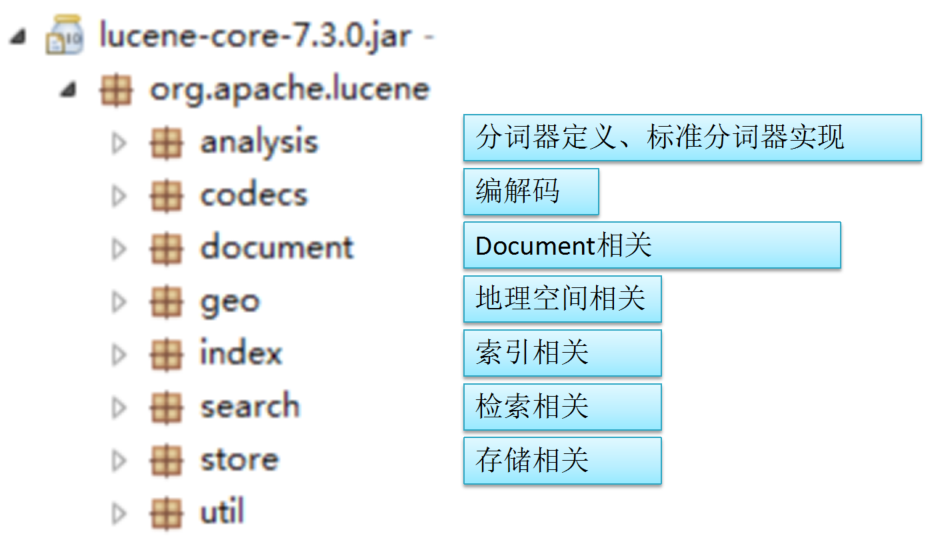
6. 了解核心模块的构成
Lucene系列二:Lucene(Lucene介绍、Lucene架构、Lucene集成)的更多相关文章
- paper 5:支持向量机系列二: Support Vector —— 介绍支持向量机目标函数的 dual 优化推导,并得出“支持向量”的概念。
paper 4中介绍了支持向量机,结果说到 Maximum Margin Classifier ,到最后都没有说“支持向量”到底是什么东西.不妨回忆一下上次最后一张图: 可以看到两个支撑着中间的 ga ...
- nova系列二:kvm介绍
一 什么是kvm KVM 全称 Kernel-Based Virtual Machine.也就是说 KVM 是基于 Linux 内核实现的,这就使得linux内核本身就相当于一个Hypervisor. ...
- Redis系列二:reids介绍
一.什么是redis.redis有哪些特性.redis有哪些应用场景.redis的版本 1. 什么是redis redis是一种基于键值对(key-value)数据库,其中value可以为string ...
- Redis系列二 Redis数据库介绍
1.SELECT命令 通过查看配置文件可以知道Redis默认有17个库,从0-16. 默认是在0号库.选择库使用SELECT <dbid>命令.例如选择0号库 SELECT 0 2.DB ...
- Lucene系列六:Lucene搜索详解(Lucene搜索流程详解、搜索核心API详解、基本查询详解、QueryParser详解)
一.搜索流程详解 1. 先看一下Lucene的架构图 由图可知搜索的过程如下: 用户输入搜索的关键字.对关键字进行分词.根据分词结果去索引库里面找到对应的文章id.根据文章id找到对应的文章 2. L ...
- Lucene系列-索引文件
本文介绍下lucene生成的索引有哪些文件组成,每个文件包含了什么信息.基于Lucene 4.10.0. 数据结构 索引(index)包含了存储的文档(document)正排.倒排信息,用于文本搜索. ...
- 【Lucene3.6.2入门系列】第03节_简述Lucene中常见的搜索功能
package com.jadyer.lucene; import java.io.File; import java.io.IOException; import java.text.SimpleD ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- [lucene系列笔记3]用socket把lucene做成一个web服务
上一篇介绍了用lucene建立索引和搜索,但是那些都只是在本机上运行的,如果希望在服务器上做成web服务该怎么办呢? 一个有效的方法就是用socket通信,这样可以实现后端与前端的独立,也就是不管前端 ...
随机推荐
- EF事务处理封装公用
/// <summary> /// EF事务封装 公用类 /// </summary> public class TransactionCommon { DbContextTr ...
- DIOCP开源项目-DIOCP3重写笔记-1
这几天在在重新DIOCP3,基本工作已经初步完成,进入测试阶段,今天加入排队投递,本认为是个很简单的工作,稍微不注意,留了两个坑,调了7,8个小时,刚刚总算找到问题,记录一下, 关于排队投递的流程 这 ...
- 远程mysql导入本地文件
远程mysql导入本地文件 登陆数据库 mysql --local-infile -h<IP> -u<USR> -p 选择数据库 USE xxx 导入文件 LOAD DATA ...
- LeetCode: Pascal's Triangle 解题报告
Pascal's Triangle Given numRows, generate the first numRows of Pascal's triangle. For example, given ...
- 【Deep Learning】Hinton. Reducing the Dimensionality of Data with Neural Networks Reading Note
2006年,机器学习泰斗.多伦多大学计算机系教授Geoffery Hinton在Science发表文章,提出基于深度信念网络(Deep Belief Networks, DBN)可使用非监督的逐层贪心 ...
- 移动web开发(三)——字体使用
参考: 移动web页面使用字体的思考.http://www.cnblogs.com/PeunZhang/p/3592096.html
- Oracle Database 11g Release 2 Standard Edition and Enterprise Edition Software Downloads
Oracle Database 11g Release 2 Standard Edition and Enterprise Edition Software DownloadsOracle 数据库 1 ...
- C语言 · 企业奖金发放
算法提高 企业奖金发放 时间限制:1.0s 内存限制:512.0MB 企业发放的奖金根据利润提成.利润低于或等于10万元时,奖金可提10%:利润高于10万元,低于20万元时,低于10 ...
- Java并发编程 LockSupport源码分析
这个类比较简单,是一个静态类,不需要实例化直接使用,底层是通过java未开源的Unsafe直接调用底层操作系统来完成对线程的阻塞. package java.util.concurrent.locks ...
- win7系统损坏无法进入系统(dsark.sys文件损坏)(未测试过)
原文:http://blog.csdn.net/foreverhuylee/article/details/37913837 电脑今天突然开不了机,出现一下画面 即提示d:\Windows\syste ...