第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
封装模块
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import urllib
from urllib import request
import json
import random
import re
import urllib.error
def hq_html(hq_url):
"""
hq_html()封装的爬虫函数,自动启用了用户代理和ip代理
接收一个参数url,要爬取页面的url,返回html源码
"""
def yh_dl(): #创建用户代理池
yhdl = [
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'User-Agent:Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10',
'Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13',
'Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)',
'UCWEB7.0.2.37/28/999',
'NOKIA5700/ UCWEB7.0.2.37/28/999',
'Openwave/ UCWEB7.0.2.37/28/999',
'Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999'
]
thisua = random.choice(yhdl) #随机获取代理信息
headers = ("User-Agent",thisua) #拼接报头信息
opener = urllib.request.build_opener() #创建请求对象
opener.addheaders=[headers] #添加报头到请求对象
urllib.request.install_opener(opener) #将报头信息设置为全局,urlopen()方法请求时也会自动添加报头 def dai_li_ip(hq_url): #创建ip代理池
url = "http://http-webapi.zhimaruanjian.com/getip?num=1&type=2&pro=&city=0&yys=0&port=11&time=1&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1"
if url:
data = urllib.request.urlopen(url).read().decode("utf-8")
data2 = json.loads(data) # 将字符串还原它本来的数据类型
# print(data2['data'][0])
ip = str(data2['data'][0]['ip'])
dkou = str(data2['data'][0]['port'])
zh_ip = ip + ':' + dkou
pat = "(\w*):\w*"
rst = re.compile(pat).findall(hq_url) #正则匹配获取是http协议还是https协议
rst2 = rst[0]
proxy = urllib.request.ProxyHandler({rst2: zh_ip}) # 格式化IP,注意,第一个参数,请求目标可能是http或者https,对应设置
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler) # 初始化IP
urllib.request.install_opener(opener) # 将代理IP设置成全局,当使用urlopen()请求时自动使用代理IP
else:
pass #请求
try:
dai_li_ip(hq_url) #执行代理IP函数
yh_dl() #执行用户代理池函数 data = urllib.request.urlopen(hq_url).read().decode("utf-8")
return data
except urllib.error.URLError as e: # 如果出现错误
if hasattr(e, "code"): # 如果有错误代码
# print(e.code) # 打印错误代码
pass
if hasattr(e, "reason"): # 如果有错误信息
# print(e.reason) # 打印错误信息
pass # a = hq_html('http://www.baid.com/')
# print(a)
实战爬取搜狗微信公众号
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import urllib.request
import fzhpach
import re
#抓取搜狗微信公众号
#http://weixin.sogou.com/weixin?type=1&query=php&page=1
#type=1表示显示公众号
#type=2表示抓取文章
#query=关键词
#page=页码 gjc = '火锅'
gjc = urllib.request.quote(gjc) #将关键词转码成浏览器认识的字符,默认网站不能是中文
url = 'http://weixin.sogou.com/weixin?type=1&query=%s&page=1' %(gjc)
html = fzhpach.hq_html(url) #使用我们封装的爬虫模块
pat = '微信号:<label name="em_weixinhao">(\w*)</label>'
rst = re.compile(pat).findall(html) #正则获取公众号
print(rst) #返回
#['cqhuoguo1', 'qkmjscj888', 'cdsbcdhs', 'zk4538111', 'lamanannv', 'ctm2813333', 'cslhg2016', 'gh_978a858b478f', 'CCLWL0431', 'yuhehaixian']
抓包教程
首先安装Fiddler4
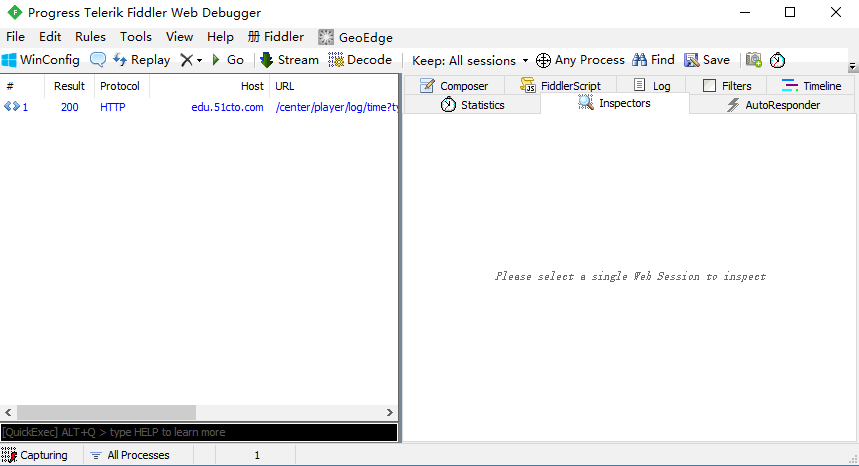
软件界面说明
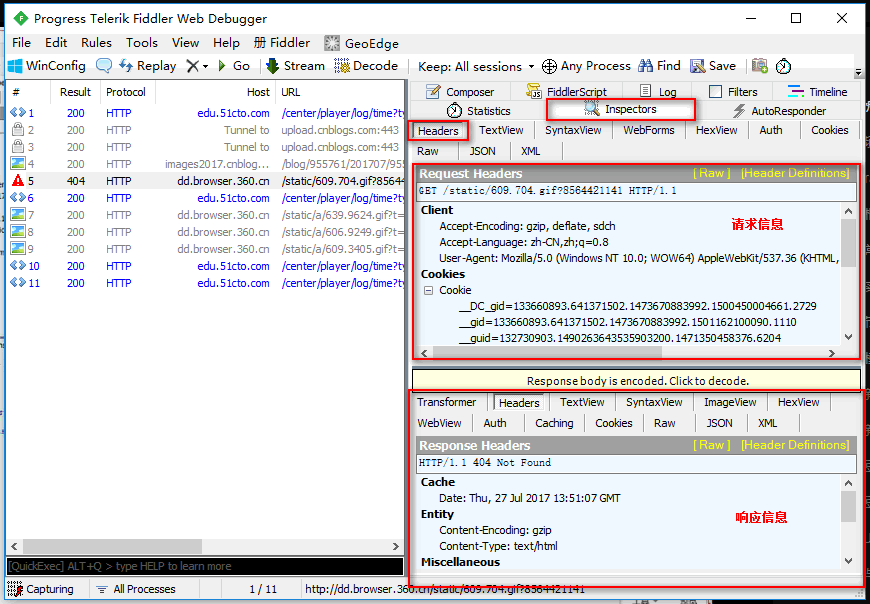
清除请求
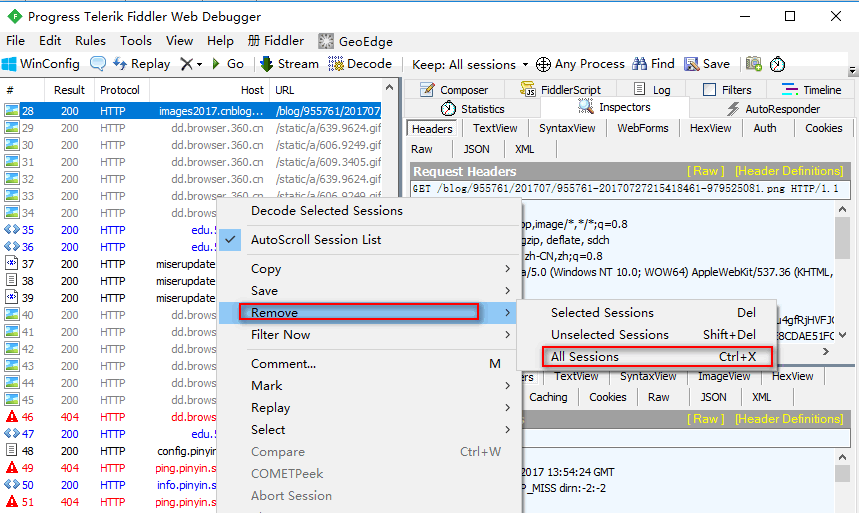
设置抓包浏览器
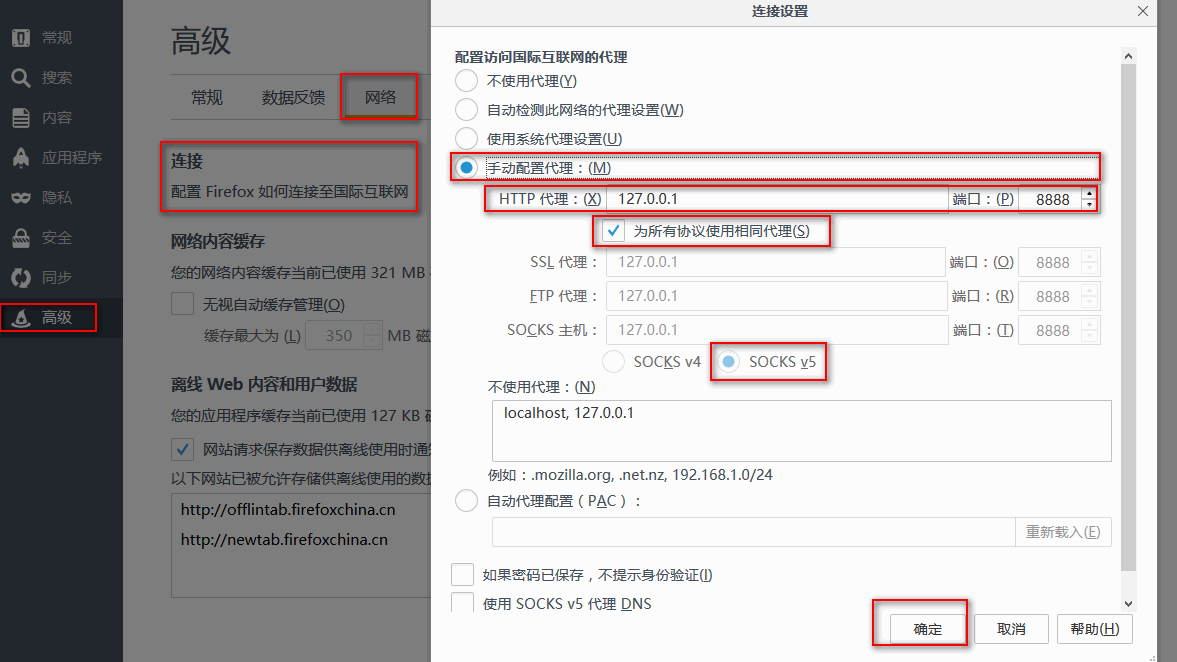
这样设置好后,这个浏览器访问的网址就会在抓包软件里看到信息了
设置抓取https协议的网站
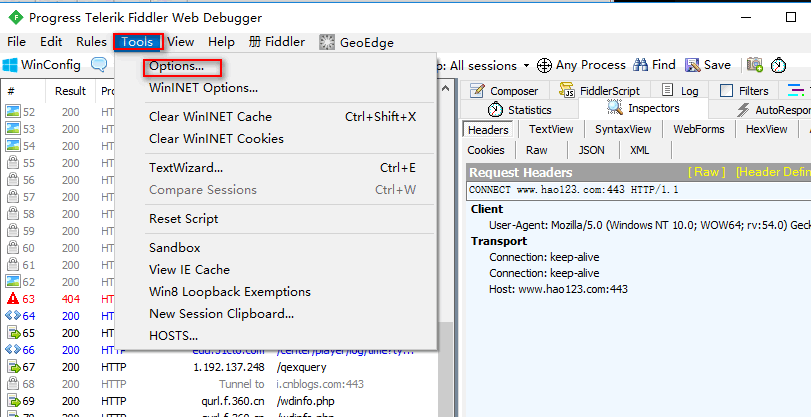
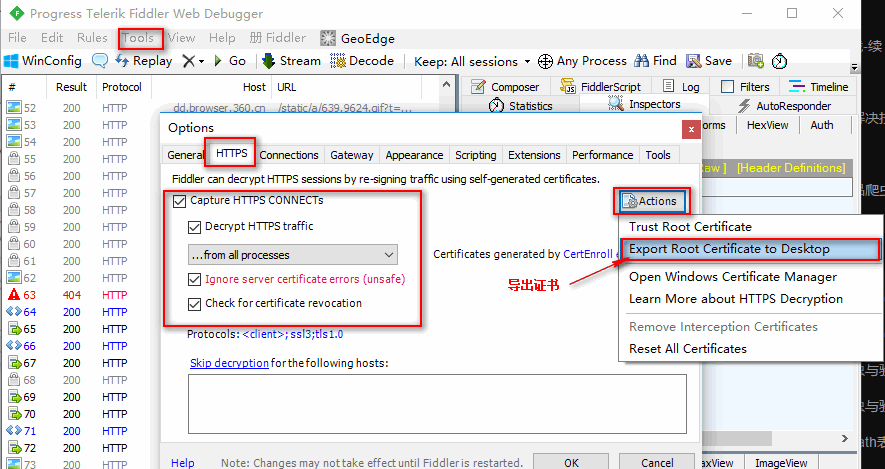
导出证书到桌面

将证书安装到浏览器

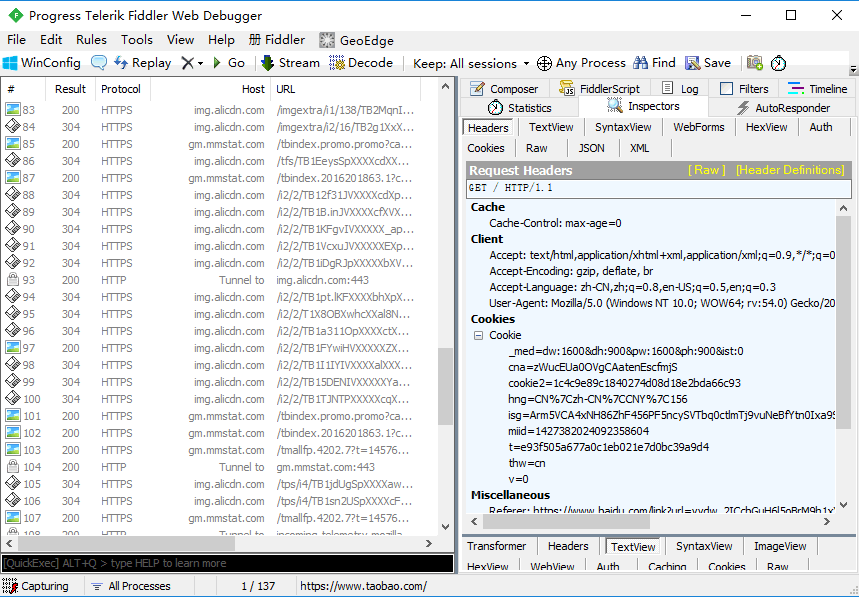
可以看到软件已经获取到https网站了
疑难问题解决:
有些可能已经按照流程在feiddler中设置好了https抓包,但死活抓不了
(1)首先,看看火狐浏览器的配置,是不是下方“为所有协议使用相同代理”的地方没有勾选上,如果是,请勾选上。
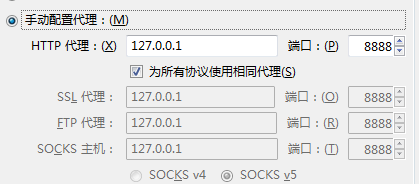
有一部分做到这一步应该能解决无法抓https的问题。如果还不行,请继续往下看。
一般这个时候,还不行,应该就是你的证书问题了,有些可能会问,我是按照正常流程导出并安装的证书,也会有问题?
对的,就是这么奇怪。
(2)接下来,请在下面这个地方输入certmgr.msc并回车,打开证书管理。
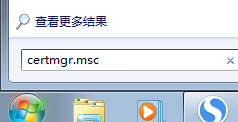
打开后如下所示:
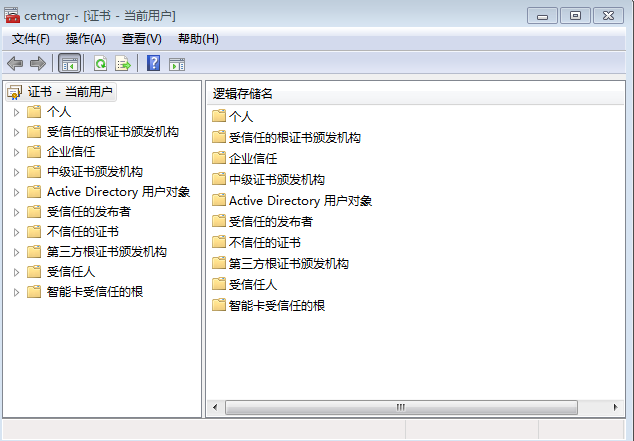
请点击操作–查找证书,如下所示:
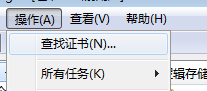
然后输入fiddler查找所有相关证书,如下所示:

可以看到,我们找到一个,您可能会找到多个,不要紧,有多少个删多少个,分别右键–删除这些证书,如下所示:
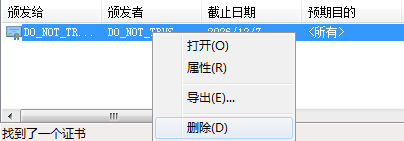
全删之后,这一步完成。
(3)再接下来,打开火狐浏览器,进入选项-高级-证书-查看证书,然后找以DO_NOT开头的关于Fiddler的证书,以字母排序的,所以你可以很快找到。如下所示,我们找到两个,不用多说,右键,然后全部依次删除。你可能找到一个或多个,反正找到多少个删多少个就行,另外,特别注意,请如图中【个人、服务器、证书机构、其他】等标签依次查找,以免遗漏,切记切记!
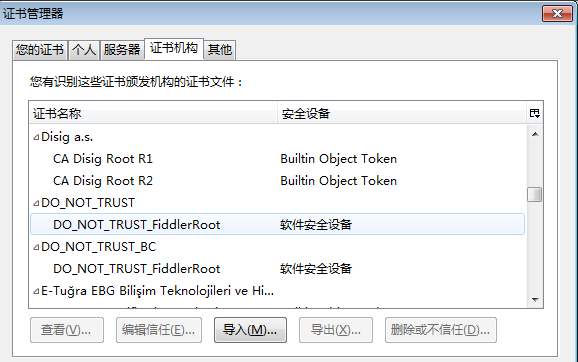
这些全删之后,这一步完成,现在证书已经全部清理了,进入下一步。
(4)下载 FiddlerCertMaker.exe,可以去官网找,如不想麻烦,直接下载我提供的,链接如下:
链接: https://pan.baidu.com/s/1bQBhxG 密码: cu85
下载了这个之后,直接打开,不管出现什么错误,直接忽略,直到出现如下界面为止:
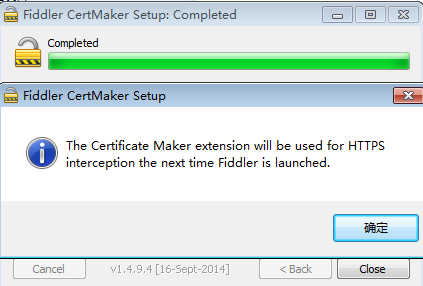
然后点击确定,关掉它。
(5)有了证书之后,请重启Fiddler(关掉再开),重启之后,访问https的网站,比如淘宝首页,有可能成功了,但你也有可能会发现如下错误:
“你的连接并不安全” 等类似提示
见到这里,你应该开心,离成功近了。
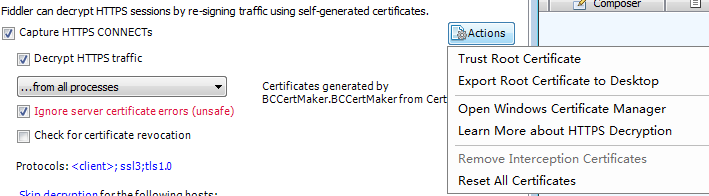
(6)果断的,打开fiddler,“Tools–Fiddler Options–HTTPS”,然后把下图中同样的地方勾上(注意一致),然后点击actions,然后先点击Trust Root…,然后,再点击Export Root…,此时,导出成功的话,在桌面就有你的证书了。务必注意:这一步成功的话,把第(7)步跳过,不要做了,直接进入第(8)步,如失败,请继续第(7步)。
(7)务必注意:上一步成功的话,把这一步跳过,不要做了。如果,你在导出的时候出现:creation of the root certificate was not located等错误,不要慌。接下来在cmd命令行中进入Fiddler安装目录,比如我的是C盘,所以进入如下图所示Fiddler2目录,然后直接复制下方make那一行代码,然后直接cmd中运行,出现如下所示succeeded提示,出现这一步提示之后,再按步骤(6)的方法导出证书,就能成功了:
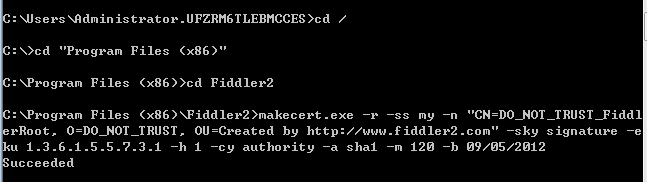
makecert.exe -r -ss my -n “CN=DO_NOT_TRUST_FiddlerRoot, O=DO_NOT_TRUST, OU=Created by http://www.fiddler2.com” -sky signature -eku 1.3.6.1.5.5.7.3.1 -h 1 -cy authority -a sha1 -m 120 -b 09/05/2012
(8)好,证书导入到桌面后,请打开火狐浏览器,然后进入选项-高级-证书-查看证书-导入-选择刚导出的桌面的证书-确定。
(9)随后,为了保险,Fiddler重启,火狐浏览器也重启一下,然后开始抓HTTPS的包,此时你会发现“你的连接并不安全” 等类似提示已经消失,并且已经能够抓包了。
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解的更多相关文章
- 九 web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
封装模块 #!/usr/bin/env python # -*- coding: utf-8 -*- import urllib from urllib import request import j ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求 selenium模块 selenium模块为 ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- 第三百八十节,Django+Xadmin打造上线标准的在线教育平台—将所有app下的models数据库表注册到xadmin后台管理
第三百八十节,Django+Xadmin打造上线标准的在线教育平台—将所有app下的models数据库表注册到xadmin后台管理 将一个app下的models数据库表注册到xadmin后台管理 重点 ...
- 第三百二十节,Django框架,生成二维码
第三百二十节,Django框架,生成二维码 用Python来生成二维码,需要qrcode模块,qrcode模块依赖Image 模块,所以首先安装这两个模块 生成二维码保存图片在本地 import qr ...
随机推荐
- lua -- table.nums
table.nums 计算表格包含的字段数量. 格式: count = table.nums(表格对象) Lua 的“#”操作可以取得表格的长度,但仅限从 开始连续数字为索引的表格.table.num ...
- 从tableview中拖动某个精灵
virtual void registerWithTouchDispatcher(void); virtual bool ccTouchBegan(CCTouch *pTouch,CCEvent *p ...
- flink Job提交过程
https://www.jianshu.com/p/0cdfa2a05ebd http://vinoyang.com/2017/04/02/flink-runtime-client-submit-jo ...
- sql server2000导出表结构说明
SELECT 表名 then d.name else '' end, 表说明 then isnull(f.value,'') else '' end, 字段序号=a.colorder, 字段名=a.n ...
- [Windows Azure] How to Scale an Application
How to Scale an Application To use this feature and other new Windows Azure capabilities, sign up fo ...
- 在IIS服务器上屏蔽IP的访问
今天就跟大家分享一下在IIS服务器上如何屏蔽特定IP的访问,希望对大家有所帮助. 第一种方法:通过iis中的ip地址和域名限制. 此方法简单有效,建议使用 点击网站--右键属性--目录安全性--IP地 ...
- SQL 迭代查询语句
SQL迭代查询 PL/SQL with ORG_Tree(ObjectId,parentID) as ( select a.ObjectId,a.parentID from Ot_Organizati ...
- liunx Swap 分区的作用
1.1 SWAP 概述 当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用.那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存 ...
- tf.square
tf.square square( x, name=None ) 功能说明: 计算张量对应元素平方 参数列表: 参数名 必选 类型 说明 x 是 张量 是 half, float32, float64 ...
- postgresql 修改字段名称
ALTER TABLE auth_user RENAME email TO aemail;