分析 HTML 代码并提取数据
在前面的内容中,我们已经学习了 HTML、CSS 和 XPath 的基础知识。从真实世界的
网页中获取数据,关键在于如何编写合适的 CSS 或者 XPath 选择器。本节介绍一些确定选
择器的简单方法。
假设从https://cran.rstudio.com/web/packages/available_packages_by_name.html 这个网页
上获取所有可用的 R 程序包。网页看起来很简单。想知道选择器的表达式,在页面上右击,
选择菜单中的审查元素选项(检查大部分现代浏览器中都有),然后就会出现检查面板,如
图 14-6 所示。
图 14-6
我们便可以看到网页底层的 HTML 代码。在火狐浏览器和谷歌浏览器中,选择的节点
是高亮的,更容易定位,如图 14-7 所示。
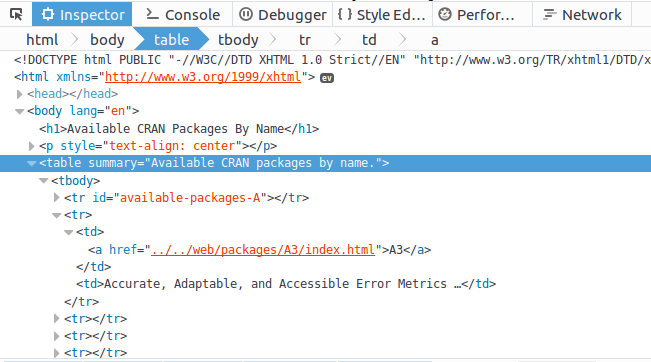
图 14-7
HTML 包含唯一的 <table>,因此可以直接将 CSS 选择器设为 table,再用 html_
table( ) 提取表格并返回一个数据框:
page <-
read_ _html("https://cran.rstudio.com/web/packages/available_packages_by_name
.html")
pkg_table <- page %>%
html_ _node("table") %>%
html_ _table(fill = TRUE)
head(pkg_table, 5)
## X1
## 1
## 2 A3
## 3 abbyyR
## 4 abc
## 5 ABCanalysis
## X2
## 1 <NA>
## 2 Accurate, Adaptable, and Accessible Error Metrics for Predictive\nModels
## 3 Access to Abbyy Optical Character Recognition (OCR) API
## 4 Tools for Approximate Bayesian Computation (ABC)
## 5 Computed ABC Analysis
注意,原始表没有表头。而结果数据框使用了默认表头,并且第一行是空的。下面的
代码解决了这些问题:
pkg_table <- pkg_table[complete.cases(pkg_table), ]
colnames(pkg_table) <- c("name", "title")
head(pkg_table, 3)
## name
## 2 A3
## 3 abbyyR
## 4 abc
##
title
## 2 Accurate, Adaptable, and Accessible Error Metrics for Predictive\nModels
## 3 Access to Abbyy Optical Character Recognition (OCR) API
## 4 Tools for Approximate Bayesian Computation (ABC)
在下一个例子中,我们想要提取微软最新的股票价格 http://finance.yahoo.com/quote/
MSFT。使用元素查看器,发现价格包含在 <span> 中,其中通过程序生成的 class 属性
值特别长,如图 14-8 所示。
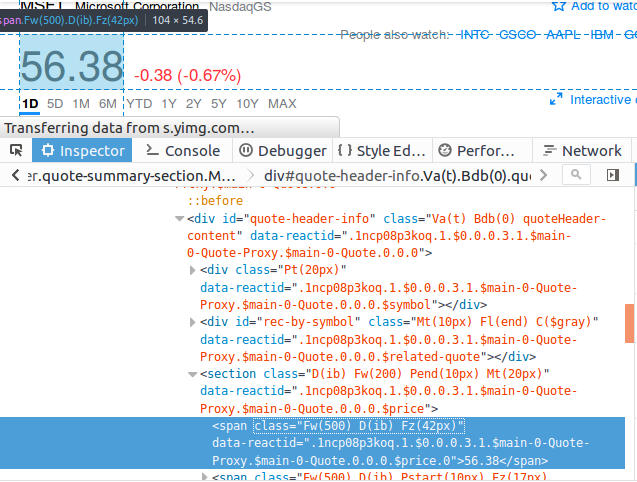
图 14-8
查看几个层级后,我们找到一条路径 div#quote-header-info > section >
span,就是它导向这个价格节点。因此,可以使用这个 CSS 选择器寻找并提取股票价格:
page <- read_ _html("https://finance.yahoo.com/quote/MSFT")
page %>%
html_ _node("div#quote-header-info > section > span") %>%
html_ _text() %>%
as.numeric()
## [1] 56.68
在网页的右侧,有一张包含企业关键数据的统计表格,如图 14-9 所示。
取出表格之前,我们可以通过查看器找到它所属的节点和能够定位到这个表格的选择器。
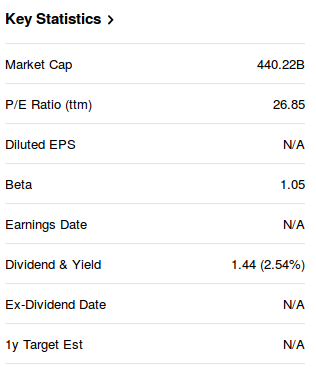
图 14-9
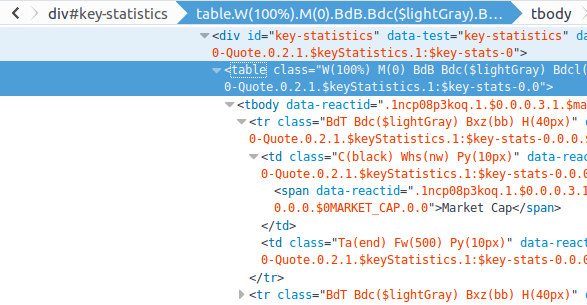
图 14-10
显然,我们感兴趣的 <table> 节点是 <div id = ”key-statustics”> 的子节点。因此,
我们可以直接使用 #key-statistics table 匹配这个表格节点,并将它转换为一个数据框:
page %>%
html_ _node("#key-statistics table") %>%
html_ _table()
## X1 X2
## 1 Market Cap 442.56B
## 2 P/E Ratio (ttm) 26.99
## 3 Diluted EPS N/A
## 4 Beta 1.05
## 5 Earnings Date N/A
## 6 Dividend & Yield 1.44 (2.56%)
## 7 Ex-Dividend Date N/A
## 8 1y Target Est N/A
使用类似的方法,我们也能创建一个函数,给定一个股票代码(例如 MSFT)就可以
返回公司名称和股票价格:
get_price <- function(symbol) {
page <- read_ _html(sprintf("https://finance.yahoo.com/quote/%s", symbol))
list(symbol = symbol,
company = page %>%
html_ _node("div#quote-header-info > div:nth-child(1) > h6") %>%
html_ _text(),
price = page %>%
html_ _node("div#quote-header-info > section > span:nth-child(1)") %>%
html_ _text() %>%
as.numeric())
}
CSS 选择器充分的限制条件能够保证定位到正确的 HTML 节点。我们运行以下代码来
测试这个函数:
get_ _price("AAPL")
## $symbol
## [1] "AAPL"
##
## $company
## [1] "Apple Inc."
##
## $price
## [1] 104.19
另一个例子是获取 http://stackoverflow.com/questions/tagged/r?sort=votes 上关于 R 的投
票数最多的问题,如图 14-11 所示。
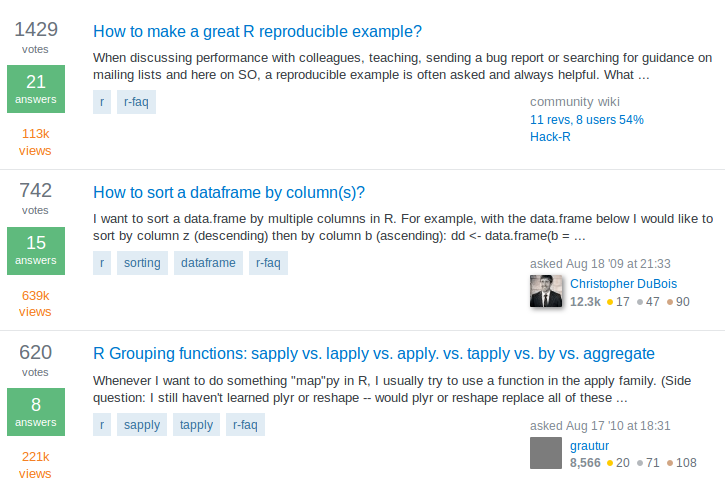
图 14-11
使用类似的方法,很容易就能找到问题列表包含在一个 id 是 questions 的集合中。
因此,我们载入页面并用#questions 选择和存储问题集合:
page <-
read_ _html("https://stackoverflow.com/questions/tagged/r?sort = votes&pageSize
= 5")
questions <- page %>%
html_ _node("#questions")
为了提取问题标题,我们仔细查看第 1 个问题的 HTML 结构,如图 14-12 所示。
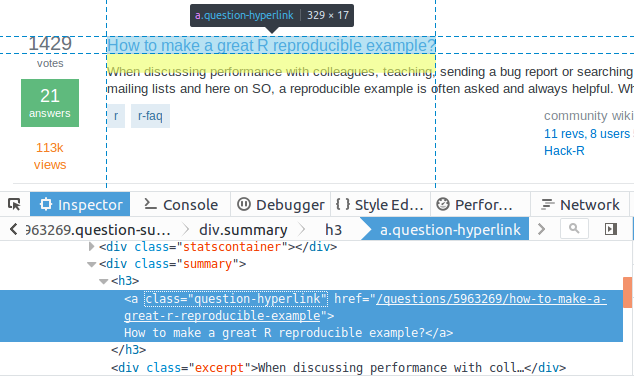
图 14-12
很容易便发现每个问题的标题都包含在 <div class = "summary"><h3> 中:
questions %>%
html_ _nodes(".summary h3") %>%
html_ _text()
## [1] "How to make a great R reproducible example?"
## [2] "How to sort a dataframe by column(s)?"
## [3] "R Grouping functions: sapply vs. lapply vs. apply. vs. tapply vs.
by vs. aggregate"
## [4] "How to join (merge) data frames (inner, outer, left, right)?"
## [5] "How can we make xkcd style graphs?"
要注意的是, <a class = "question-hyperlink"> 还提供了一个更简单的 CSS
选择器,能够返回相同的结果:
questions %>%
html_ _nodes(".question-hyperlink") %>%
html_ _text()
如果对每个问题的票数也感兴趣,可以返回去检查投票情况,并查看它们是如何
用 CSS 选择器描述的,如图 14-13 所示。
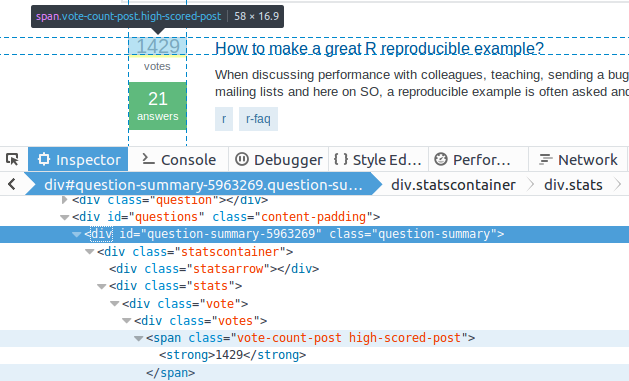
图 14-13
幸运的是,所有的投票面板共享同一个结构,并且非常容易找到它们的模式。每个问
题 被 包 含 在 一 个 question-summary 类 的 <div> 节 点 中 , 其 中 , 票 数 位
于 .vote-count-post 类的 <span> 节点中:
questions %>%
html_ _nodes(".question-summary .vote-count-post") %>%
html_ _text() %>%
as.integer()
## [1] 1429 746 622 533 471
类似地,下面这段代码用于提取回答数量:
questions %>%
html_ _nodes(".question-summary .status strong") %>%
html_ _text() %>%
as.integer()
## [1] 21 15 8 11 7
但是,若想继续提取每个问题的标签,就比较棘手了,因为不同问题的标签数量可能不同。
在下面的代码中,我们先选择所有问题的标签集合,再通过迭代提取每个集合中的标签:
questions %>%
html_ _nodes(".question-summary .tags") %>%
lapply(function(node) {
node %>%
html_ _nodes(".post-tag") %>%
html_ _text()
}) %>%
str
## List of 5
## $ : chr [1:2] "r" "r-faq"
## $ : chr [1:4] "r" "sorting" "dataframe" "r-faq"
## $ : chr [1:4] "r" "sapply" "tapply" "r-faq"
## $ : chr [1:5] "r" "join" "merge" "dataframe" ...
## $ : chr [1:2] "r" "ggplot2"
上面所有的数据抓取过程都是在同一个网页上进行的。试想一下,如果需要从多个网页收
集数据,应该怎样做呢?假设我们访问该页面中的每个问题(例如 http://stackoverflow.com/
q/5963269/2906900)。注意到,右上角有一个“信息盒”(信息框),我
们以列表形式提取每个问题的“信息盒”,如图 14-14 所示。
通过检查,我们发现 #qinfo 正是每个问题页面“信息盒”的
“钥匙”(键)。然后,选择所有问题的超链接,提取每个问题的 URL
并进行迭代,读取每个问题页面,再使用 #qinfo 从中提取信息框:
questions %>%
html_ _nodes(".question-hyperlink") %>%
html_ _attr("href") %>%
lapply(function(link) {
paste0("https://stackoverflow.com", link) %>%
read_ _html() %>%
html_ _node("#qinfo") %>%
html_ _table() %>%
setNames(c("item", "value"))
})
## [[1]]
## item value
## 1 asked 5 years ago
## 2 viewed 113698 times
## 3 active 7 days ago
##

图 14-14
## [[2]]
## item value
## 1 asked 6 years ago
## 2 viewed 640899 times
## 3 active 2 months ago
##
## [[3]]
## item value
## 1 asked 5 years ago
## 2 viewed 221964 times
## 3 active 1 month ago
##
## [[4]]
## item value
## 1 asked 6 years ago
## 2 viewed 311376 times
## 3 active 15 days ago
##
## [[5]]
## item value
## 1 asked 3 years ago
## 2 viewed 53232 times
## 3 active 4 months ago
除了这些,rvest 扩展包还支持创建 HTTP 会话来模拟导航过程。想了解更多内容,请
阅读 rvest 扩展包的帮助文档。对于多个爬虫任务,可以使用 http://selectorgadget.com/ 提供
的工具简化选择器的寻找过程。
还有很多更高级的网页爬虫技术,例如使用 JavaScript 处理 AJAX 和动态网页,但是
它们超出了本章的范围。想学习更多关于 rvest 的用法,请阅读 rvest 扩展包的帮助文档。
值得一提的是,在网页爬虫方面,rvest 在很大程度上是受到 Python 的 Robobrowser
和 BeautifulSoup 的启发。这些包更强大,甚至某些方面要比 rvest 更流行。如果源代
码很复杂并且规模很大的话,可能最好还是要学习使用 Python 的扩展包。读者可以访
问 https://www. crummy.com/software/BeautifulSoup/ 获取更多信息。
分析 HTML 代码并提取数据的更多相关文章
- 如何使用Hive&R从Hadoop集群中提取数据进行分析
一个简单的例子! 环境:CentOS6.5 Hadoop集群.Hive.R.RHive,具体安装及调试方法见博客内文档. 1.分析题目 --有一个用户数据样本(表名huserinfo)10万数据左右: ...
- [数据科学] 从csv, xls文件中提取数据
在python语言中,用丰富的函数库来从文件中提取数据,这篇博客讲解怎么从csv, xls文件中得到想要的数据. 点击下载数据文件http://seanlahman.com/files/databas ...
- 代码中函数、变量、常量 / bss段、data段、text段 /sct文件、.map文件的关系[实例分析arm代码(mdk)]
函数代码://demo.c #include<stdio.h> #include<stdlib.h> , global2 = , global3 = ; void functi ...
- 洛谷 P2194 HXY烧情侣【Tarjan缩点】 分析+题解代码
洛谷 P2194 HXY烧情侣[Tarjan缩点] 分析+题解代码 题目描述: 众所周知,HXY已经加入了FFF团.现在她要开始喜(sang)闻(xin)乐(bing)见(kuang)地烧情侣了.这里 ...
- 洛谷P1783 海滩防御 分析+题解代码
洛谷P1783 海滩防御 分析+题解代码 题目描述: WLP同学最近迷上了一款网络联机对战游戏(终于知道为毛JOHNKRAM每天刷洛谷效率那么低了),但是他却为了这个游戏很苦恼,因为他在海边的造船厂和 ...
- 002 requests的使用方法以及xpath和beautifulsoup4提取数据
1.直接使用url,没用headers的请求 import requests url = 'http://www.baidu.com' # requests请求用get方法 response = re ...
- synchronized关键字的详细分析和代码实例
在Java中,一般都是通过同步机制来解决线程安全问题的,在JDK 5.0之后又新增了Lock的方式来实现线程安全.所以说实现线程安全方式一共有三种方法 方式一: synchronized(同步监视器) ...
- Java NIO原理 图文分析及代码实现
Java NIO原理图文分析及代码实现 前言: 最近在分析hadoop的RPC(Remote Procedure Call Protocol ,远程过程调用协议,它是一种通过网络从远程计算机程序上请 ...
- 使用 CSS 选择器从网页中提取数据
在 R 中,关于网络爬虫最简单易用的扩展包是 rvest.运行以下代码从 CRAN 上安装:install.packages("rvest")首先,加载包并用 read_html( ...
随机推荐
- c#实现图片二值化例子(黑白效果)
C#将图片2值化示例代码,原图及二值化后的图片如下: 原图: 二值化后的图像: 实现代码: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 2 ...
- win10 + cuda(v9.0) 安装TensorFlow-gpu版
之前在实习公司的电脑上装过TensorFlow-gpu,那时候很快就装好了.但在自己的笔记本上装时,却搞了很久... 一部分原因是因为用校园网下载cuda toolkit 和cudnn ,总是在最后时 ...
- numpy中的广播(Broadcasting)
Numpy的Universal functions 中要求输入的数组shape是一致的,当数组的shape不相等的时候,则会使用广播机制,调整数组使得shape一样,满足规则,则可以运算,否则就出错 ...
- 剑指offer4
中序遍历(LDR)是二叉树遍历的一种,也叫做中根遍历.中序周游.在二叉树中,先左后根再右.巧记:左根右. 现在有一个问题,已知二叉树的前序遍历和中序遍历:PreOrder: GDAFE ...
- JavaScript DOM2
1.Window.history:window.open打开网页的方式必须是_self window.history.back()后退 Window.history.forward()前进 <b ...
- 开发人员必备的几款bug管理工具
Bug是软件开发过程中的“副产品”,也是开发人员最不想见到的状况.如果没有跟踪和梳理各种bug和问题并及时解决,项目就会花费非常多的时间,导致整个项目的重心偏移.如果在产品开发过程中,使用一个合适的B ...
- VS2010/MFC编程入门之四十七(字体和文本输出:CFont字体类)
上一节中鸡啄米讲了MFC异常处理,本节的主要内容是字体CFont类. 字体简介 GDI(Graphics Device Interface),图形设备接口,是Windows提供的一些函数和结构,用于在 ...
- POJ 1836
刚开始二分写错了 wa了很久 这个二分 的好好想想 #include <iostream> #include<cstdio> #include<string.h> ...
- 公司里面用的iTextSharp(教程)---简介
一.需求: 公司这次要做一个生成PDF的功能,需要设计,刚刚进入公司,组长把任务分配给了我,为了完成这个任务,苦学了许久的iTextSharp.现在记录下实现过程中了了解的一些东东,一起分享哈~~ 二 ...
- 微信公众号为什么要加粉?流量,广告,KPI,吸粉,增粉
微信公众号为什么要加粉?流量,广告,KPI,吸粉,增粉 1.曾有人这样比喻:当你的粉丝超过100人时,你就像是一本内刊:超过1000人,你就像个布告栏:超过1万人,你就好比一本杂志:超过10万人,你就 ...