一篇文章,读懂Netty的高性能架构之道
一篇文章,读懂Netty的高性能架构之道
Netty是由JBOSS提供的一个java开源框架,是一个高性能、异步事件驱动的NIO框架,它提供了对TCP、UDP和文件传输的支持,作为一个异步NIO框架,Netty的所有IO操作都是异步非阻塞的,通过Future-Listener机制,用户可以方便的主动获取或者通过通知机制获得IO操作结果。
作为当前最流行的NIO框架,Netty在互联网领域、大数据分布式计算领域、游戏行业、通信行业等获得了广泛的应用,一些业界著名的开源组件也基于Netty的NIO框架构建。
为什么选择Netty
Netty是业界最流行的NIO框架之一,它的健壮性、功能、性能、可定制性和可扩展性在同类框架中都是首屈一指的,它已经得到成百上千的商用项目验证,例如Hadoop的RPC框架avro使用Netty作为底层通信框架;很多其他业界主流的RPC框架,也使用Netty来构建高性能的异步通信能力。
Netty的特点
高并发
Netty是一款基于NIO(Nonblocking I/O,非阻塞IO)开发的网络通信框架,对比于BIO(Blocking I/O,阻塞IO),他的并发性能得到了很大提高 。
传输快
Netty的传输快其实也是依赖了NIO的一个特性——零拷贝。
封装好
Netty封装了NIO操作的很多细节,提供易于使用的API。
为什么选择Netty
JDK 原生也有一套网络应用程序 API,但是存在一系列问题,主要如下:
1)NIO 的类库和 API 繁杂,使用麻烦:你需要熟练掌握 Selector、ServerSocketChannel、SocketChannel、ByteBuffer 等。
2)需要具备其他的额外技能做铺垫:例如熟悉 Java 多线程编程,因为 NIO 编程涉及到 Reactor 模式,你必须对多线程和网路编程非常熟悉,才能编写出高质量的 NIO 程序。
3)可靠性能力补齐,开发工作量和难度都非常大:例如客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流的处理等等。NIO 编程的特点是功能开发相对容易,但是可靠性能力补齐工作量和难度都非常大。
4)JDK NIO 的 Bug:例如臭名昭著的 Epoll Bug,它会导致 Selector 空轮询,最终导致 CPU 100%。官方声称在 JDK 1.6 版本的 update 18 修复了该问题,但是直到 JDK 1.7 版本该问题仍旧存在,只不过该 Bug 发生概率降低了一些而已,它并没有被根本解决。
Netty框架的优势
API使用简单,开发门槛低;
功能强大,预置了多种编解码功能,支持多种主流协议;
定制能力强,可以通过ChannelHandler对通信框架进行灵活地扩展;
性能高,通过与其他业界主流的NIO框架对比,Netty的综合性能最优;
成熟、稳定,Netty修复了已经发现的所有JDK NIO BUG,业务开发人员不需要再为NIO的BUG而烦恼;
社区活跃,版本迭代周期短,发现的BUG可以被及时修复,同时,更多的新功能会加入;
经历了大规模的商业应用考验,质量得到验证。在互联网、大数据、网络游戏、企业应用、电信软件等众多行业得到成功商用,证明了它已经完全能够满足不同行业的商业应用了。
Netty的核心组件
Netty应用中必不可少的组件:
Bootstrap or ServerBootstrap
EventLoop
EventLoopGroup
ChannelPipeline
Channel
Future or ChannelFuture
ChannelInitializer
ChannelHandler
1.Bootstrap
一个Netty应用通常由一个Bootstrap开始,它主要作用是配置整个Netty程序,串联起各个组件。
Handler,为了支持各种协议和处理数据的方式,便诞生了Handler组件。Handler主要用来处理各种事件,这里的事件很广泛,比如可以是连接、数据接收、异常、数据转换等。
2.ChannelInboundHandler
一个最常用的Handler。这个Handler的作用就是处理接收到数据时的事件,也就是说,我们的业务逻辑一般就是写在这个Handler里面的,ChannelInboundHandler就是用来处理我们的核心业务逻辑。
3.ChannelInitializer
当一个链接建立时,我们需要知道怎么进行接收或者发送数据,当然,我们有各种各样的Handler实现来处理它,那么ChannelInitializer便是用来配置这些Handler,它会提供一个ChannelPipeline,并把Handler加入到ChannelPipeline。
4.ChannelPipeline
一个Netty应用基于ChannelPipeline机制,这种机制需要依赖于EventLoop和EventLoopGroup,因为它们三个都和事件或者事件处理相关。
EventLoops的目的是为Channel处理IO操作,一个EventLoop可以为多个Channel服务。
EventLoopGroup会包含多个EventLoop。
5.Channel
代表了一个Socket链接,或者其它和IO操作相关的组件,它和EventLoop一起用来参与IO处理。
6.Future
在Netty中所有的IO操作都是异步的,因此,你不能立刻得知消息是否被正确处理,但是我们可以过一会等它执行完成或者直接注册一个监听,具体的实现就是通过Future和ChannelFutures,他们可以注册一个监听,当操作执行成功或失败时监听会自动触发。
总之,所有的操作都会返回一个ChannelFuture。
Netty的应用场景
1.互联网行业
在分布式系统中,各个节点之间需要远程服务调用,高性能的RPC框架必不可少,Netty作为异步高新能的通信框架,往往作为基础通信组件被这些RPC框架使用。
典型的应用有:阿里分布式服务框架Dubbo的RPC框架使用Dubbo协议进行节点间通信,Dubbo协议默认使用Netty作为基础通信组件,用于实现各进程节点之间的内部通信。
除了 Dubbo 之外,淘宝的消息中间件 RocketMQ 的消息生产者和消息消费者之间,也采用 Netty 进行高性能、异步通信。
2.游戏行业
无论是手游服务端还是大型的网络游戏,Java语言得到了越来越广泛的应用。Netty作为高性能的基础通信组件,它本身提供了TCP/UDP和HTTP协议栈。
非常方便定制和开发私有协议栈,账号登录服务器,地图服务器之间可以方便的通过Netty进行高性能的通信
3.大数据领域
经典的Hadoop的高性能通信和序列化组件Avro的RPC框架,默认采用Netty进行跨界点通信,它的Netty Service基于Netty框架二次封装实现。
Netty架构分析
Netty 采用了比较典型的三层网络架构进行设计,逻辑架构图如下所示:
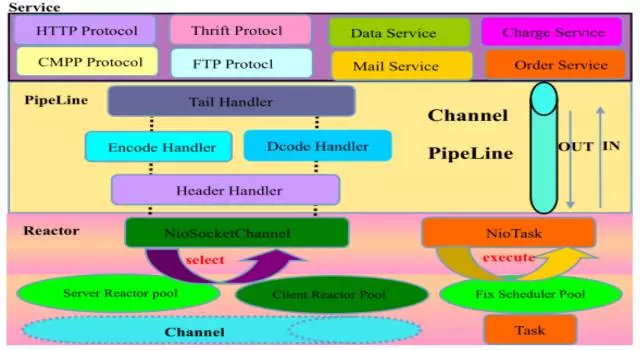
#第一层,Reactor 通信调度层,它由一系列辅助类完成,包括 NioEventLoop 以及其父类、NioSocketChannel/NioServerSocketChannel 以及其父 类、ByteBuffer 以及由其衍生出来的各种 Buffer、Unsafe 以及其衍生出的各种内部类等。该层的主要职责就是监听网络的读写和连接操作,负责将网络层的数据读取到内存缓冲区中,然后触发各种网络事件,例如连接创建、连接激活、读事 件、写事件等等,将这些事件触发到 PipeLine 中,由 PipeLine 充当的职责链来进行后续的处理。
#第二层,职责链 PipeLine,它负责事件在职责链中的有序传播,同时负责动态的编排职责链,职责链可以选择监听和处理自己关心的事件,它可以拦截处理和向后/向前传播事件,不同的应用的 Handler 节点的功能也不同,通常情况下,往往会开发编解码 Handler 用于消息的编解码,它可以将外部的协议消息转换成内部的 POJO 对象,这样上层业务侧只需要关心处理业务逻辑即可,不需要感知底层的协议差异和线程模型差异,实现了架构层面的分层隔离。
#第三层,业务逻辑处理层。可以分为两类:纯粹的业务逻辑处理,例如订单处理;应用层协议管理,例如 HTTP 协议、FTP 协议等。
I/O模型
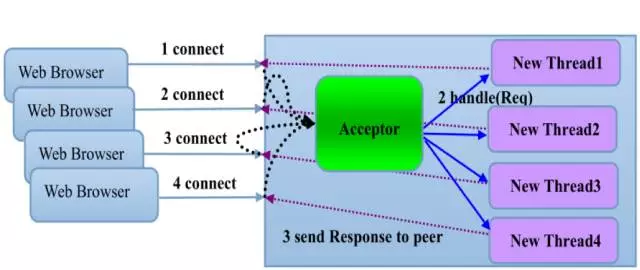
传统同步阻塞I/O模式如下图所示:
几种I/O模型的功能和特性对比:
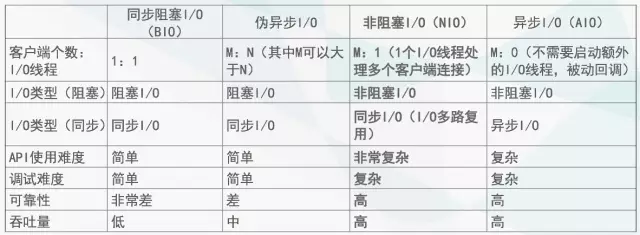
Netty的I/O模型基于非阻塞I/O实现,底层依赖的是JDK NIO框架的Selector。Selector提供选择已经就绪的任务的能力。简单来讲,Selector会不断地轮询注册在其上的Channel,如果某个Channel上面有新的TCP连接接入、读和写事件,这个Channel就处于就绪状态,会被Selector轮询出来,然后通过SelectionKey可以获取就绪Channel的集合,从而进行后续的I/O操作。
一个多路复用器Selector可以同时轮询多个Channel,由于JDK1.5_update10版本(+)使用了epoll()代替传统的select实现,所以它并没有最大连接句柄1024/2048的限制。这也就意味着只需要一个线程负责Selector的轮询,就可以接入成千上万的客户端,这确实是个非常巨大的技术进步。使用非阻塞I/O模型之后,Netty解决了传统同步阻塞I/O带来的性能、吞吐量和可靠性问题。
线程调度模型
常用的Reactor线程模型有三种,分别如下:
#Reactor单线程模型:Reactor单线程模型,指的是所有的I/O操作都在同一个NIO线程上面完成。对于一些小容量应用场景,可以使用单线程模型。
#Reactor多线程模型:Rector多线程模型与单线程模型最大的区别就是由一组NIO线程处理I/O操作。主要用于高并发、大业务量场景。
#主从Reactor多线程模型:主从Reactor线程模型的特点是服务端用于接收客户端连接的不再是个1个单独的NIO线程,而是一个独立的NIO线程池。利用主从NIO线程模型,可以解决1个服务端监听线程无法有效处理所有客户端连接的性能不足问题。
Netty的线程模型
说完了Reactor的三种模型,那么Netty是哪一种呢?其实Netty的线程模型是Reactor模型的变种,那就是去掉线程池的第三种形式的变种,这也是Netty NIO的默认模式。
事实上,Netty的线程模型并非固定不变,通过在启动辅助类中创建不同的EventLoopGroup实例并通过适当的参数配置,就可以支持上述三种Reactor线程模型.
在大多数场景下,并行多线程处理可以提升系统的并发性能。但是,如果对于共享资源的并发访问处理不当,会带来严重的锁竞争,这最终会导致性能的下降。为了尽可能的避免锁竞争带来的性能损耗,可以通过串行化设计,即消息的处理尽可能在同一个线程内完成,期间不进行线程切换,这样就避免了多线程竞争和同步锁。
为了尽可能提升性能,Netty采用了串行无锁化设计,在I/O线程内部进行串行操作,避免多线程竞争导致的性能下降。表面上看,串行化设计似乎CPU利用率不高,并发程度不够。但是,通过调整NIO线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部无锁化的串行线程设计相比一个队列-多个工作线程模型性能更优。
Reactor模型
Java NIO非堵塞技术实际是采取反应器模式,或者说是观察者(observer)模式为我们监察I/O端口,如果有内容进来,会自动通知我们,这样,我们就不必开启多个线程死等,从外界看,实现了流畅的I/O读写,不堵塞了。
NIO 有一个主要的类Selector,这个类似一个观察者,只要我们把需要探知的socketchannel告诉Selector,我们接着做别的事情,当有事件发生时,他会通知我们,传回一组SelectionKey,我们读取这些Key,就会获得我们刚刚注册过的socketchannel,然后,我们从这个Channel中读取数据,接着我们可以处理这些数据。
反应器模式与观察者模式在某些方面极为相似:当一个主体发生改变时,所有依属体都得到通知。不过,观察者模式与单个事件源关联,而反应器模式则与多个事件源关联 。
一般模型
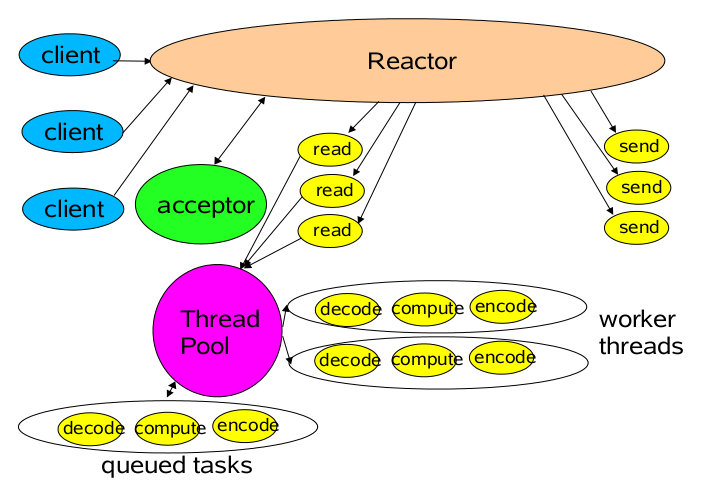
EventLoopGroup:对应于Reactor模式中的定时器的角色,不断地检索是否有事件可用(I/O线程-BOSS),然后交给分离者将事件分发给对应的事件绑定的handler(WORK线程)。
经验分享:在客户端编程中经常容易出现在EVENTLOOP上做定时任务的,如果定时任务耗时很长或者存在阻塞,那么可能会将I/O操作挂起(因为要等到定时任务做完才能做别的操作)。解决方法:用独立的EventLoopGroup
序列化方式
影响序列化性能的关键因素总结如下:
- 序列化后的码流大小(网络带宽占用)
- 序列化&反序列化的性能(CPU资源占用)
- 并发调用的性能表现:稳定性、线性增长、偶现的时延毛刺等
对Java序列化和二进制编码分别进行性能测试,编码100万次,测试结果表明:Java序列化的性能只有二进制编码的6.17%左右。
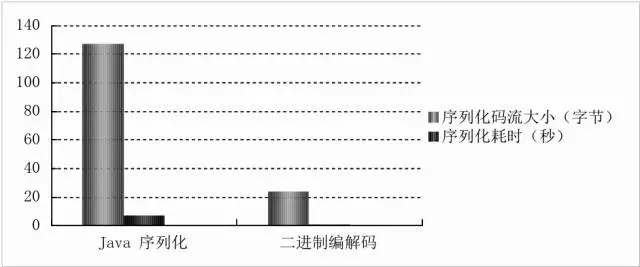
Netty默认提供了对Google Protobuf的支持,通过扩展Netty的编解码接口,用户可以实现其它的高性能序列化框架,例如Thrift的压缩二进制编解码框架。
不同的应用场景对序列化框架的需求也不同,对于高性能应用场景Netty默认提供了Google的Protobuf二进制序列化框架,如果用户对其它二进制序列化框架有需求,也可以基于Netty提供的编解码框架扩展实现。
Netty架构剖析之可靠性
Netty面临的可靠性挑战:
\1. 作为RPC框架的基础网络通信框架,一旦故障将导致无法进行远程服务(接口)调用。
\2. 作为应用层协议的基础通信框架,一旦故障将导致应用协议栈无法正常工作。
\3. 网络环境复杂(例如推送服务的GSM/3G/WIFI网络),故障不可避免,业务却不能中断。
从应用场景看,Netty是基础的通信框架,一旦出现Bug,轻则需要重启应用,重则可能导致整个业务中断。它的可靠性会影响整个业务集群的数据通信和交换,在当今以分布式为主的软件架构体系中,通信中断就意味着整个业务中断,分布式架构下对通信的可靠性要求非常高。
从运行环境看,Netty会面临恶劣的网络环境,这就要求它自身的可靠性要足够好,平台能够解决的可靠性问题需要由Netty自身来解决,否则会导致上层用户关注过多的底层故障,这将降低Netty的易用性,同时增加用户的开发和运维成本。
Netty的可靠性是如此重要,它的任何故障都可能会导致业务中断,蒙受巨大的经济损失。因此,Netty在版本的迭代中不断加入新的可靠性特性来满足用户日益增长的高可靠和健壮性需求。
链路有效性检测
Netty提供的心跳检测机制分为三种:
- 读空闲,链路持续时间t没有读取到任何消息
- 写空闲,链路持续时间t没有发送任何消息
- 读写空闲,链路持续时间t没有接收或者发送任何消息
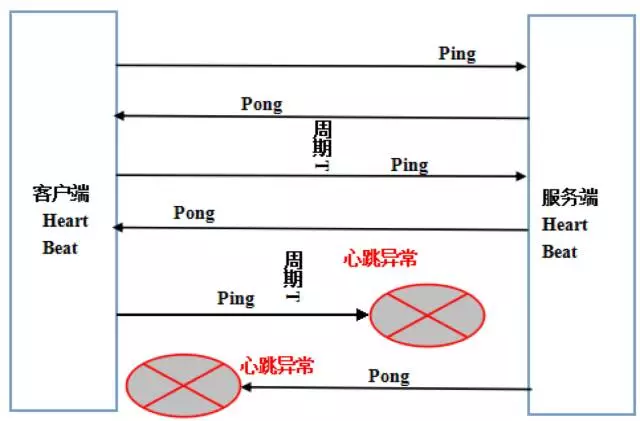
当网络发生单通、连接被防火墙拦截住、长时间GC或者通信线程发生非预期异常时,会导致链路不可用且不易被及时发现。特别是异常发生在凌晨业务低谷期间,当早晨业务高峰期到来时,由于链路不可用会导致瞬间的大批量业务失败或者超时,这将对系统的可靠性产生重大的威胁。
从技术层面看,要解决链路的可靠性问题,必须周期性的对链路进行有效性检测。目前最流行和通用的做法就是心跳检测。
心跳检测机制分为三个层面:
\1. TCP层面的心跳检测,即TCP的Keep-Alive机制,它的作用域是整个TCP协议栈;
\2. 协议层的心跳检测,主要存在于长连接协议中。例如SMPP协议;
\3. 应用层的心跳检测,它主要由各业务产品通过约定方式定时给对方发送心跳消息实现。
Keep-Alive仅仅是TCP协议层会发送连通性检测包,但并不代表设置了Keep-Alive就是长连接了。
心跳检测的目的就是确认当前链路可用,对方活着并且能够正常接收和发送消息。
做为高可靠的NIO框架,Netty也提供了基于链路空闲的心跳检测机制:
- 读空闲,链路持续时间t没有读取到任何消息
- 写空闲,链路持续时间t没有发送任何消息
- 读写空闲,链路持续时间t没有接收或者发送任何消息(netty自带心跳处理Handler IdleStateHandler)
客户端和服务端之间连接断开机制
TCP连接的建立需要三个分节(三次握手),终止则需要四个分节。
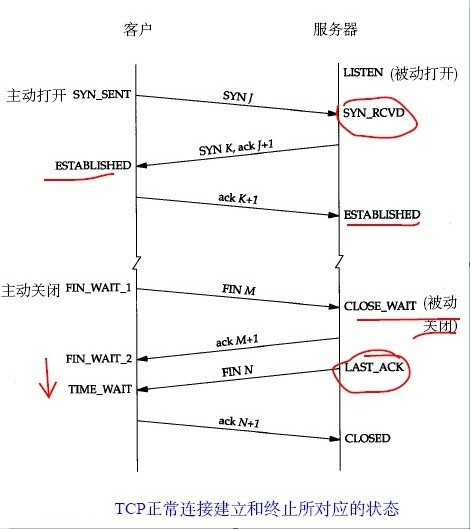
对于大量短连接的情况下,经常出现卡在FIN_WAIT2和TIMEWAIT状态的连接,等待系统回收,但是操作系统底层回收的时间频率很长,导致SOCKET被耗尽。
TCP状态图
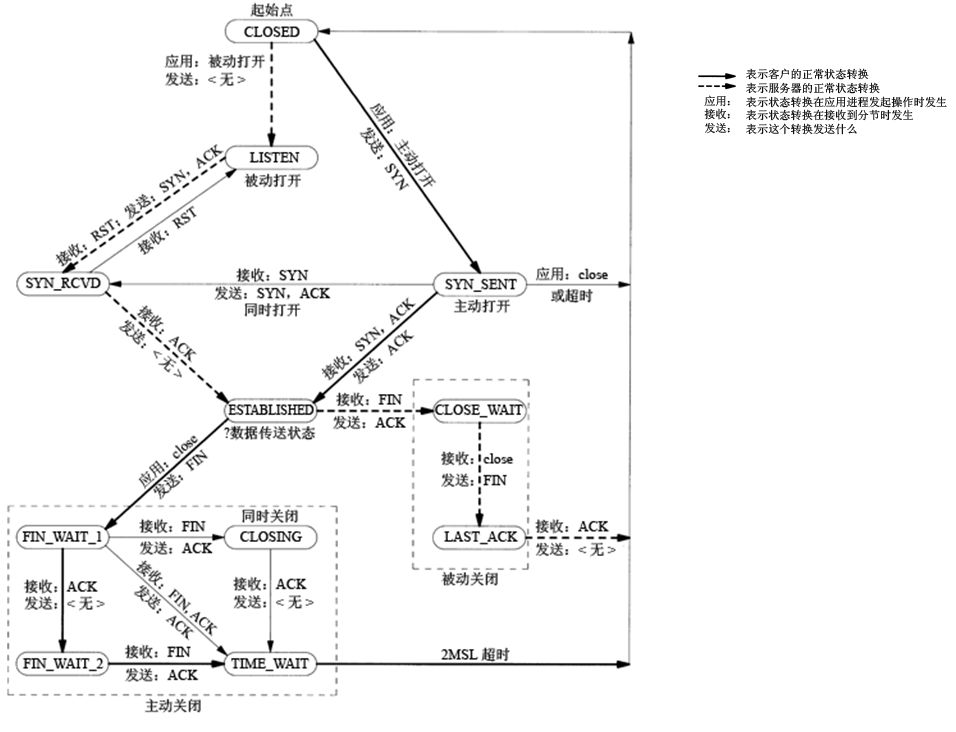
TCP/IP半关闭
从上述讲的TCP关闭的四个分节可以看出,被动关闭执行方,发送FIN分节的前提是TCP套接字对应应用程序调用close产生的。如果服务端有数据发送给客户端那么可能存在服务端在接受到FIN之后,需要将数据发送到客户端才能发送FIN字节。这种处于业务考虑的情形通常称为半关闭。
半关闭可能导致大量socket处于CLOSE_WAIT状态
谁负责关闭连接合理
连接关闭触发的条件通常分为如下几种:
\1. 数据发送完成(发送到对端并且收到响应),关闭连接
\2. 通信过程中产生异常
\3. 特殊指令强制要求关闭连接
对于第一种,通常关闭时机是,数据发送完成方发起(客户端触发居多); 对于第二种,异常产生方触发(例如残包、错误数据等)发起。但是此种情况可能也导致压根无法发送FIN。对于第三种,通常是用于运维等。由命令发起方产生。
流量整形
流量整形(Traffic Shaping)是一种主动调整流量输出速率的措施。
Netty的流量整形有两个作用:
\1. 防止由于上下游网元性能不均衡导致下游网元被压垮,业务流程中断
\2. 防止由于通信模块接收消息过快,后端业务线程处理不及时导致的"撑死"问题
流量整形的原理示意图如下:
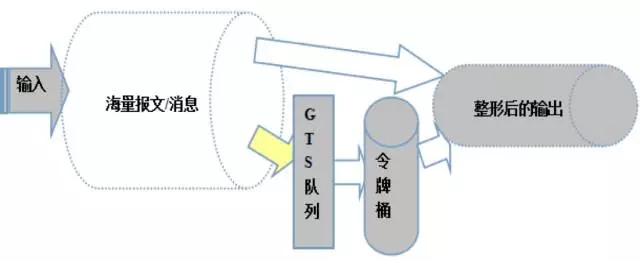
流量整形(Traffic Shaping)是一种主动调整流量输出速率的措施。一个典型应用是基于下游网络结点的TP指标来控制本地流量的输出。
流量监管TP(Traffic Policing)就是对流量进行控制,通过监督进入网络的流量速率,对超出部分的流量进行“惩罚”,使进入的流量被限制在一个合理的范围之内,从而保护网络资源和用户的利益。
流量整形与流量监管的主要区别在于,流量整形对流量监管中需要丢弃的报文进行缓存——通常是将它们放入缓冲区或队列内,也称流量整形(Traffic Shaping,简称TS)。当令牌桶有足够的令牌时,再均匀的向外发送这些被缓存的报文。流量整形与流量监管的另一区别是,整形可能会增加延迟,而监管几乎不引入额外的延迟。
#全局流量整形:全局流量整形的作用范围是进程级的,无论你创建了多少个Channel,它的作用域针对所有的Channel。用户可以通过参数设置:报文的接收速率、报文的发送速率、整形周期。[GlobalChannelTrafficShapingHandler]
#链路级流量整形:单链路流量整形与全局流量整形的最大区别就是它以单个链路为作用域,可以对不同的链路设置不同的整形策略。[ChannelTrafficShapingHandler针对于每个channel]
优雅停机
Netty的优雅停机三部曲: 1. 不再接收新消息 2. 退出前的预处理操作 3. 资源的释放操作
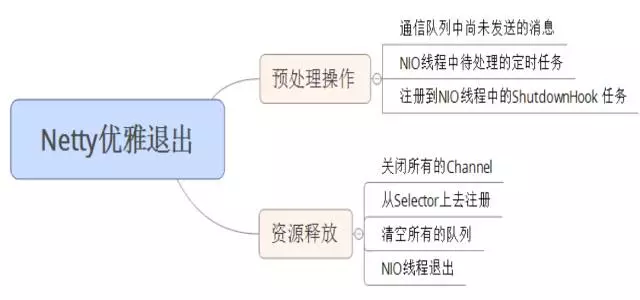
Java的优雅停机通常通过注册JDK的ShutdownHook来实现,当系统接收到退出指令后,首先标记系统处于退出状态,不再接收新的消息,然后将积压的消息处理完,最后调用资源回收接口将资源销毁,最后各线程退出执行。
通常优雅退出需要有超时控制机制,例如30S,如果到达超时时间仍然没有完成退出前的资源回收等操作,则由停机脚本直接调用kill -9 pid,强制退出。
在实际项目中,Netty作为高性能的异步NIO通信框架,往往用作基础通信框架负责各种协议的接入、解析和调度等,例如在RPC和分布式服务框架中,往往会使用Netty作为内部私有协议的基础通信框架。 当应用进程优雅退出时,作为通信框架的Netty也需要优雅退出,主要原因如下:
\1. 尽快的释放NIO线程、句柄等资源
\2. 如果使用flush做批量消息发送,需要将积攒在发送队列中的待发送消息发送完成
\3. 正在write或者read的消息,需要继续处理
\4. 设置在NioEventLoop线程调度器中的定时任务,需要执行或者清理
Netty架构剖析之安全性
Netty面临的安全挑战:
- 对第三方开放
- 作为应用层协议的基础通信框架
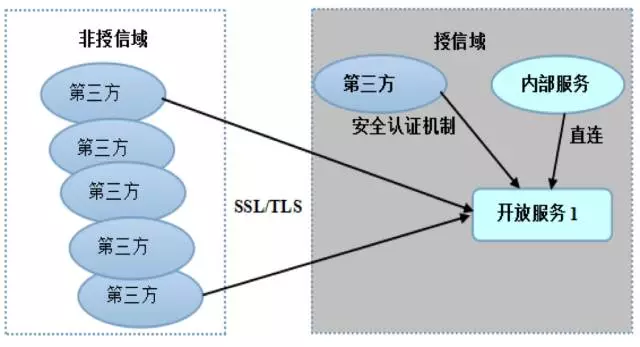
安全威胁场景分析:
#对第三方开放的通信框架:如果使用Netty做RPC框架或者私有协议栈,RPC框架面向非授信的第三方开放,例如将内部的一些能力通过服务对外开放出去,此时就需要进行安全认证,如果开放的是公网IP,对于安全性要求非常高的一些服务,例如在线支付、订购等,需要通过SSL/TLS进行通信。
#应用层协议的安全性:作为高性能、异步事件驱动的NIO框架,Netty非常适合构建上层的应用层协议。由于绝大多数应用层协议都是公有的,这意味着底层的Netty需要向上层提供通信层的安全传输功能。
SSL/TLS
Netty安全传输特性:
- 支持SSL V2和V3
- 支持TLS
- 支持SSL单向认证、双向认证和第三方CA认证。
SSL单向认证流程图如下:
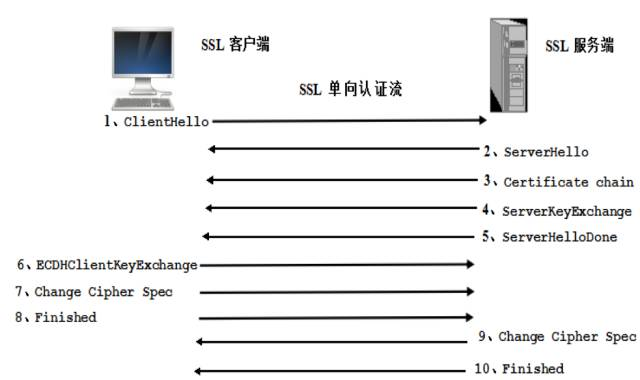
Netty通过SslHandler提供了对SSL的支持,它支持的SSL协议类型包括:SSL V2、SSL V3和TLS。
#单向认证:单向认证,即客户端只验证服务端的合法性,服务端不验证客户端。
#双向认证:与单向认证不同的是服务端也需要对客户端进行安全认证。这就意味着客户端的自签名证书也需要导入到服务端的数字证书仓库中。
#CA认证:基于自签名的SSL双向认证,只要客户端或者服务端修改了密钥和证书,就需要重新进行签名和证书交换,这种调试和维护工作量是非常大的。因此,在实际的商用系统中往往会使用第三方CA证书颁发机构进行签名和验证。我们的浏览器就保存了几个常用的CA_ROOT。每次连接到网站时只要这个网站的证书是经过这些CA_ROOT签名过的。就可以通过验证了。
可扩展的安全特性
通过Netty的扩展特性,可以自定义安全策略:
- IP地址黑名单机制
- 接入认证
- 敏感信息加密或者过滤机制
IP地址黑名单是比较常用的弱安全保护策略,它的特点就是服务端在与客户端通信的过程中,对客户端的IP地址进行校验,如果发现对方IP在黑名单列表中,则拒绝与其通信,关闭链路。
接入认证策略非常多,通常是较强的安全认证策略,例如基于用户名+密码的认证,认证内容往往采用加密的方式,例如Base64+AES等。
Netty架构剖析之扩展性
通过Netty的扩展特性,可以自定义安全策略:
- 线程模型可扩展
- 序列化方式可扩展
- 上层协议栈可扩展
- 提供大量的网络事件切面,方便用户功能扩展
Netty的架构可扩展性设计理念如下:
\1. 判断扩展点,事先预留相关扩展接口,给用户二次定制和扩展使用
\2. 主要功能点都基于接口编程,方便用户定制和扩展。
粘连包解决方案
TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。
出现粘包现象的原因是多方面的,它既可能由发送方造成,也可能由接收方造成。发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一包数据。若连续几次发送的数据都很少,通常TCP会根据优化算法把这些数据合成一包后一次发送出去,这样接收方就收到了粘包数据。接收方引起的粘包是由于接收方用户进程不及时接收数据,从而导致粘包现象。这是因为接收方先把收到的数据放在系统接收缓冲区,用户进程从该缓冲区取数据,若下一包数据到达时前一包数据尚未被用户进程取走,则下一包数据放到系统接收缓冲区时就接到前一包数据之后,而用户进程根据预先设定的缓冲区大小从系统接收缓冲区取数据,这样就一次取到了多包数据。
粘包情况有两种:
\1. 粘在一起的包都是完整的数据包
\2. 粘在一起的包有不完整的包
解决粘连包的方法大致分为如下三种:
\1. 发送方开启TCP_NODELAY
\2. 接收方简化或者优化流程尽可能快的接收数据
\3. 认为强制分包每次只读一个完整的包
对于以上三种方式,第一种会加重网络负担,第二种治标不治本,第三种算比较合理的。
第三种又可以分两种方式:
\1. 每次都只读取一个完整的包,如果不足一个完整的包,就等下次再接收,如果缓冲区有N个包要接受,那么需要分N次才能接收完成
\2. 有多少接收多少,将接収的数据缓存在一个临时的缓存中,交由后续的专门解码的线程/进程处理
以上两种分包方式,如果强制关闭程序,数据会存在丢失,第一种数据丢失在接收缓冲区;第二种丢失在程序自身缓存。
Netty自带的几种粘连包解决方案:
\1. DelimiterBasedFrameDecoder (带分隔符)
\2. FixedLengthFrameDecoder (定长)
\3. LengthFieldBasedFrameDecoder(将消息分为消息头和消息体,消息头中包含消息总长度的字段)
Netty解包组包
对于TCP编程最常遇到的就是根据具体的协议进行组包或者解包。
根据协议的不同大致可以分为如下几种类型:
\1. JAVA平台之间通过JAVA序列化进行解包组包(object->byte->object)
\2. 固定长度的包结构(定长每个包都是M个字节的长度)
\3. 带有明确分隔符协议的解包组包(例如HTTP协议\r\n\r\n)
\4. 可动态扩展的协议(每个包都添加一个消息头),此种协议通常遵循消息头+消息体的机制,其中消息头的长度是固定的,消息体的长度根据具体业务的不同长度可能不同。例如(SMPP协议、CMPP协议)
#序列化协议组包解包
可以使用的有:MessagePack、Google Protobuf、Hessian2
#固定长度解包组包
FixedLengthFrameDecoder 解包,MessageToByteEncoder 组包
#带有分隔符协议的解包组包
DelimiterBasedFrameDecoder 解包,MessageToByteEncoder 组包
#HTTP
io.netty.codec.http
#消息头固定长度,消息体不固定长度协议解包组包
LengthFieldBasedFrameDecoder
需要注意的是:对于解码的Handler必须做到在将ByteBuf解析成Object之后,需要将ByteBuf release()。
Netty Client断网重连机制
对于长连接的程序断网重连几乎是程序的标配。
断网重连具体可以分为两类:
CONNECT失败,需要重连
程序运行过程中断网、远程强制关闭连接、收到错误包必须重连
对于第一种解决方案是:实现ChannelFutureListener 用来启动时监测是否连接成功,不成功的话重试。
Future-Listener机制
在并发编程中,我们通常会用到一组非阻塞的模型:Promise,Future,Callback。
其中的Future表示一个可能还没有实际完成的异步任务的结果,针对这个结果添加Callback以便在执行任务成功或者失败后做出响应的操作。而经由Promise交给执行者,任务执行者通过Promise可以标记任务完成或者失败。以上这套模型是很多异步非阻塞框架的基础。具体的理解可参见JDK的FutureTask和Callable。JDK的实现版本,在获取最终结果的时候,不得不做一些阻塞的方法等待最终结果的到来。Netty的Future机制是JDK机制的一个子版本,它支持给Future添加Listener,以方便EventLoop在任务调度完成之后调用。
数据安全性之滑动窗口协议
我们假设一个场景,客户端每次请求服务端必须得到服务端的一个响应,由于TCP的数据发送和数据接收是异步的,就存在必须存在一个等待响应的过程。该过程根据实现方式不同可以分为一下几类(部分是错误案例):
\1. 每次发送一个数据包,然后进入休眠(sleep)或者阻塞(await)状态,直到响应回来或者超时,整个调用链结束。此场景是典型的一问一答的场景,效率极其低下
\2. 读写分离,写模块只负责写,读模块则负责接收响应,然后做后续的处理。此种场景能尽可能的利用带宽进行读写。但是此场景不做控速操作可能导致大量报文丢失或者重复发送。
\3. 实现类似于Windowed Protocol。此窗口是以上两种方案的折中版,即允许一定数量的批量发送,又能保证数据的完整性。
对于 Netty ByteBuf 的零拷贝(Zero Copy) 的理解
作者:@xys1228 本文为作者原创,转载请注明出处:https://www.cnblogs.com/xys1228/p/6088805.html Email:yongshun1228@gmail.com
目录
通过 CompositeByteBuf 实现零拷贝
通过 wrap 操作实现零拷贝
通过 slice 操作实现零拷贝
通过 FileRegion 实现零拷贝
此文章已同步发布在我的 segmentfault 专栏.
根据 Wiki 对 Zero-copy 的定义:
"Zero-copy" describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.
即所谓的 Zero-copy, 就是在操作数据时, 不需要将数据 buffer 从一个内存区域拷贝到另一个内存区域. 因为少了一次内存的拷贝, 因此 CPU 的效率就得到的提升.
在 OS 层面上的 Zero-copy 通常指避免在 用户态(User-space) 与 内核态(Kernel-space) 之间来回拷贝数据. 例如 Linux 提供的 mmap 系统调用, 它可以将一段用户空间内存映射到内核空间, 当映射成功后, 用户对这段内存区域的修改可以直接反映到内核空间; 同样地, 内核空间对这段区域的修改也直接反映用户空间. 正因为有这样的映射关系, 我们就不需要在 用户态(User-space) 与 内核态(Kernel-space) 之间拷贝数据, 提高了数据传输的效率.
而需要注意的是, Netty 中的 Zero-copy 与上面我们所提到到 OS 层面上的 Zero-copy 不太一样, Netty的 Zero-coyp 完全是在用户态(Java 层面)的, 它的 Zero-copy 的更多的是偏向于 优化数据操作 这样的概念.
Netty 的 Zero-copy 体现在如下几个个方面:
Netty 提供了
CompositeByteBuf类, 它可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf, 避免了各个 ByteBuf 之间的拷贝.通过 wrap 操作, 我们可以将 byte[] 数组、ByteBuf、ByteBuffer等包装成一个 Netty ByteBuf 对象, 进而避免了拷贝操作.
ByteBuf 支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf, 避免了内存的拷贝.
通过
FileRegion包装的FileChannel.tranferTo实现文件传输, 可以直接将文件缓冲区的数据发送到目标Channel, 避免了传统通过循环 write 方式导致的内存拷贝问题.
下面我们就来简单了解一下这几种常见的零拷贝操作.
通过 CompositeByteBuf 实现零拷贝
假设我们有一份协议数据, 它由头部和消息体组成, 而头部和消息体是分别存放在两个 ByteBuf 中的, 即:
`ByteBuf header = ...``ByteBuf body = ...`
我们在代码处理中, 通常希望将 header 和 body 合并为一个 ByteBuf, 方便处理, 那么通常的做法是:
ByteBuf allBuf = Unpooled.buffer(header.readableBytes() + body.readableBytes());
allBuf.writeBytes(header);
allBuf.writeBytes(body);
可以看到, 我们将 header 和 body 都拷贝到了新的 allBuf 中了, 这无形中增加了两次额外的数据拷贝操作了.
那么有没有更加高效优雅的方式实现相同的目的呢? 我们来看一下 CompositeByteBuf 是如何实现这样的需求的吧.
`ByteBuf header = ...`
`ByteBuf body = ...`
`CompositeByteBuf compositeByteBuf=Unpooled.compositeBuffer();`
`compositeByteBuf.addComponents(``true``, header, body);`
上面代码中, 我们定义了一个 CompositeByteBuf 对象, 然后调用
`public` `CompositeByteBuf addComponents(``boolean` `increaseWriterIndex, ByteBuf... buffers) {``...``}`
方法将 header 与 body 合并为一个逻辑上的 ByteBuf, 即:
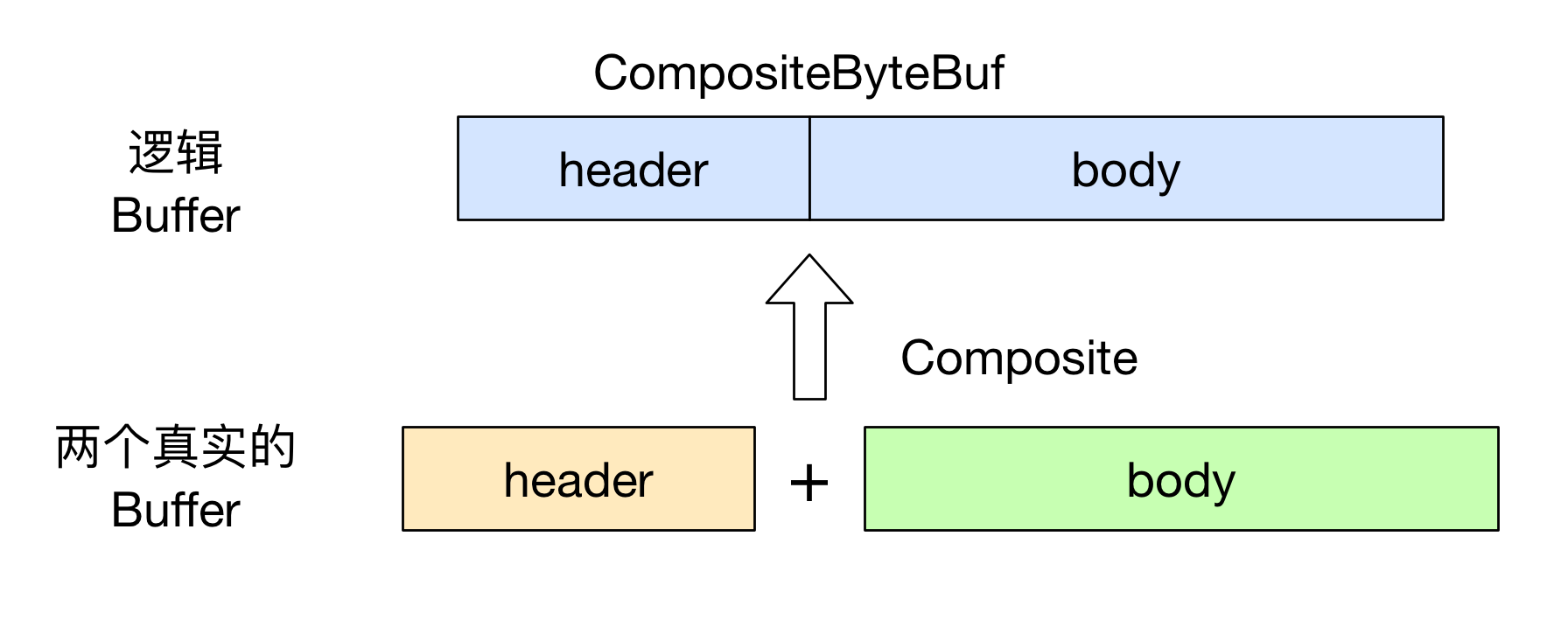
不过需要注意的是, 虽然看起来 CompositeByteBuf 是由两个 ByteBuf 组合而成的, 不过在 CompositeByteBuf 内部, 这两个 ByteBuf 都是单独存在的, CompositeByteBuf 只是逻辑上是一个整体.
上面 CompositeByteBuf 代码还以一个地方值得注意的是, 我们调用 addComponents(boolean increaseWriterIndex, ByteBuf... buffers) 来添加两个 ByteBuf, 其中第一个参数是 true, 表示当添加新的 ByteBuf 时, 自动递增 CompositeByteBuf 的 writeIndex. 如果我们调用的是
`compositeByteBuf.addComponents(header, body);`
那么其实 compositeByteBuf 的 writeIndex 仍然是0, 因此此时我们就不可能从 compositeByteBuf 中读取到数据, 这一点希望大家要特别注意.
除了上面直接使用 CompositeByteBuf 类外, 我们还可以使用 Unpooled.wrappedBuffer 方法, 它底层封装了 CompositeByteBuf 操作, 因此使用起来更加方便:
`ByteBuf header = ...``ByteBuf body = ...`
`ByteBuf allByteBuf = Unpooled.wrappedBuffer(header, body);`
通过 wrap 操作实现零拷贝
例如我们有一个 byte 数组, 我们希望将它转换为一个 ByteBuf 对象, 以便于后续的操作, 那么传统的做法是将此 byte 数组拷贝到 ByteBuf 中, 即:
`byte``[] bytes = ...
``ByteBuf byteBuf = Unpooled.buffer();`
`byteBuf.writeBytes(bytes);`
显然这样的方式也是有一个额外的拷贝操作的, 我们可以使用 Unpooled 的相关方法, 包装这个 byte 数组, 生成一个新的 ByteBuf 实例, 而不需要进行拷贝操作. 上面的代码可以改为:
`byte``[] bytes = ...`
`ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);`
可以看到, 我们通过 Unpooled.wrappedBuffer 方法来将 bytes 包装成为一个 UnpooledHeapByteBuf 对象, 而在包装的过程中, 是不会有拷贝操作的. 即最后我们生成的生成的 ByteBuf 对象是和 bytes 数组共用了同一个存储空间, 对 bytes 的修改也会反映到 ByteBuf 对象中.
Unpooled 工具类还提供了很多重载的 wrappedBuffer 方法:
`public` `static` `ByteBuf wrappedBuffer(``byte``[] array)`
`public` `static` `ByteBuf wrappedBuffer(``byte``[] array, ``int` `offset, ``int` `length)` `public` `static` `ByteBuf wrappedBuffer(ByteBuffer buffer)`
`public` `static` `ByteBuf wrappedBuffer(ByteBuf buffer)`
`public` `static` `ByteBuf wrappedBuffer(``byte``[]... arrays)`
`public` `static` `ByteBuf wrappedBuffer(ByteBuf... buffers)`
`public` `static` `ByteBuf wrappedBuffer(ByteBuffer... buffers)`
`public` `static` `ByteBuf wrappedBuffer(``int` `maxNumComponents, ``byte``[]... arrays)`
`public` `static` `ByteBuf wrappedBuffer(``int` `maxNumComponents, ByteBuf... buffers)`
`public` `static` `ByteBuf wrappedBuffer(``int` `maxNumComponents, ByteBuffer... buffers)`
这些方法可以将一个或多个 buffer 包装为一个 ByteBuf 对象, 从而避免了拷贝操作.
通过 slice 操作实现零拷贝
slice 操作和 wrap 操作刚好相反, Unpooled.wrappedBuffer 可以将多个 ByteBuf 合并为一个, 而 slice 操作可以将一个 ByteBuf 切片 为多个共享一个存储区域的 ByteBuf 对象. ByteBuf 提供了两个 slice 操作方法:
`public` `ByteBuf slice();`
`public` `ByteBuf slice(``int` `index, ``int` `length);`
不带参数的 slice 方法等同于 buf.slice(buf.readerIndex(), buf.readableBytes()) 调用, 即返回 buf 中可读部分的切片. 而 slice(int index, int length) 方法相对就比较灵活了, 我们可以设置不同的参数来获取到 buf 的不同区域的切片.
下面的例子展示了 ByteBuf.slice 方法的简单用法:
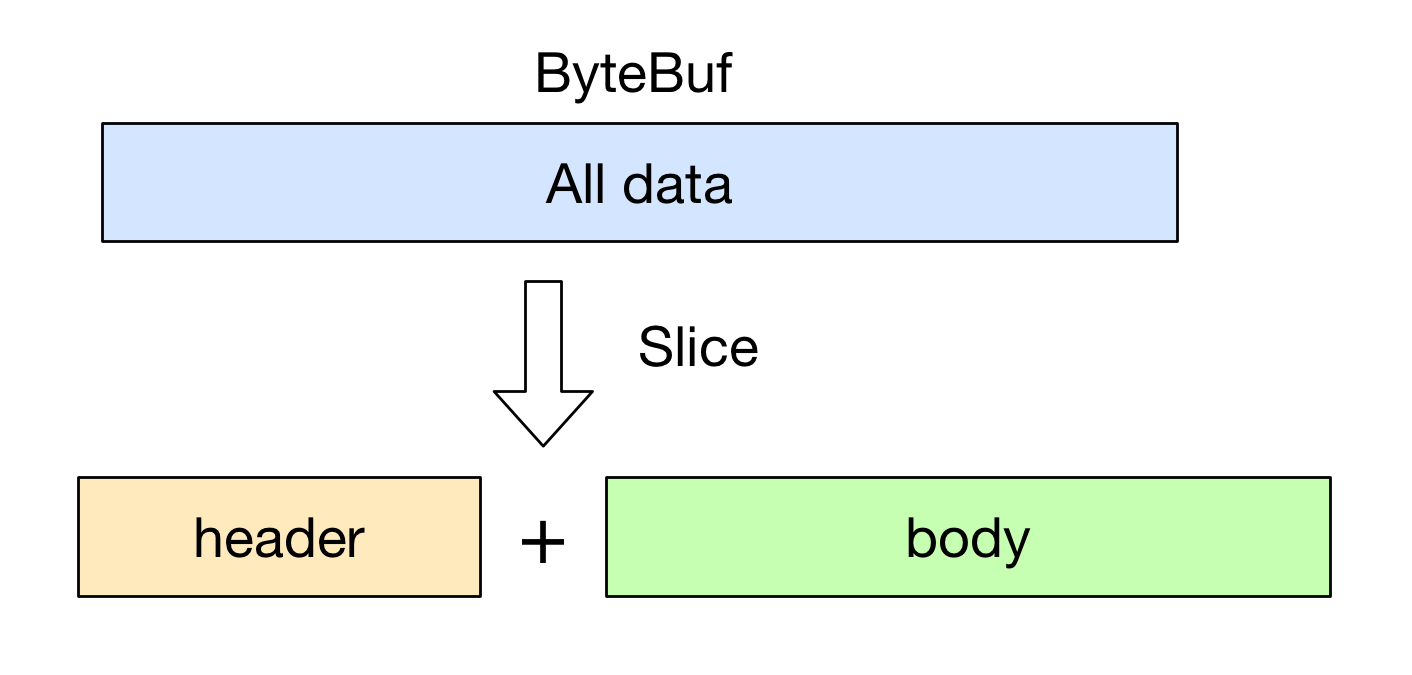
`ByteBuf byteBuf = ...`
`ByteBuf header = byteBuf.slice(``0``, ``5``);`
`ByteBuf body = byteBuf.slice(``5``, ``10``);`
用 slice 方法产生 header 和 body 的过程是没有拷贝操作的, header 和 body 对象在内部其实是共享了 byteBuf 存储空间的不同部分而已. 即:
通过 FileRegion 实现零拷贝
Netty 中使用 FileRegion 实现文件传输的零拷贝, 不过在底层 FileRegion 是依赖于 Java NIO FileChannel.transfer 的零拷贝功能.
首先我们从最基础的 Java IO 开始吧. 假设我们希望实现一个文件拷贝的功能, 那么使用传统的方式, 我们有如下实现:
`public` `static` `void` `copyFile(String srcFile, String destFile) ``throws` `Exception {`` ``byte``[] temp = ``new` `byte``[``1024``];``
``FileInputStream in = ``new` `FileInputStream(srcFile);``
``FileOutputStream out = ``new` `FileOutputStream(destFile);``
``int` `length;``
``while` `((length = in.read(temp)) != -``1``)
{``
``out.write(temp, ``0``, length);``
``}` `
``in.close();``
``out.close();`
`}`
上面是一个典型的读写二进制文件的代码实现了. 不用我说, 大家肯定都知道, 上面的代码中不断中源文件中读取定长数据到 temp 数组中, 然后再将 temp 中的内容写入目的文件, 这样的拷贝操作对于小文件倒是没有太大的影响, 但是如果我们需要拷贝大文件时, 频繁的内存拷贝操作就消耗大量的系统资源了. 下面我们来看一下使用 Java NIO 的 FileChannel 是如何实现零拷贝的:
`public` `static` `void` `copyFileWithFileChannel(String srcFileName, String destFileName) ``throws` `Exception {``
``RandomAccessFile srcFile = ``new` `RandomAccessFile(srcFileName, ``"r"``);``
``FileChannel srcFileChannel = srcFile.getChannel();` `
``RandomAccessFile destFile = ``new` `RandomAccessFile(destFileName, ``"rw"``);`` ``FileChannel destFileChannel = destFile.getChannel();` ` ``long` `position = ``0``;`` ``long` `count = srcFileChannel.size();` ` ``srcFileChannel.transferTo(position, count, destFileChannel);``}`
可以看到, 使用了 FileChannel 后, 我们就可以直接将源文件的内容直接拷贝(transferTo) 到目的文件中, 而不需要额外借助一个临时 buffer, 避免了不必要的内存操作.
有了上面的一些理论知识, 我们来看一下在 Netty 中是怎么使用 FileRegion 来实现零拷贝传输一个文件的:
`@Override`
`public` `void` `channelRead0(ChannelHandlerContext ctx, String msg)``throws` `Exception {`` ``RandomAccessFile raf = ``null``;``
``long` `length = -``1``;``
``try` `{``
``// 1. 通过 RandomAccessFile 打开一个文件.``
``raf = ``new` `RandomAccessFile(msg, ``"r"``);``
``length = raf.length();`` ``}
``catch` `(Exception e) {``
``ctx.writeAndFlush(``"ERR: "` `+ e.getClass().getSimpleName() + ``": "` `+ e.getMessage() + ``'\n'``);``
``return``;``
``} ``finally`
`{`` ``if` `(length < ``0` `&& raf != ``null``) {``
``raf.close();``
``}`` ``}` `
``ctx.write(``"OK: "` `+ raf.length() + ``'\n'``);``
``if` `(ctx.pipeline().get(SslHandler.``class``) == ``null``) {``
``// SSL not enabled - can use zero-copy file transfer.``
``// 2. 调用 raf.getChannel() 获取一个 FileChannel.``
``// 3. 将 FileChannel 封装成一个 DefaultFileRegion``
``ctx.write(``new` `DefaultFileRegion(raf.getChannel(), ``0``, length));``
``} ``else` `{``
``// SSL enabled - cannot use zero-copy file transfer.``
``ctx.write(``new` `ChunkedFile(raf));``
``}``
``ctx.writeAndFlush(``"\n"``);``}`
上面的代码是 Netty 的一个例子, 其源码在 netty/example/src/main/java/io/netty/example/file/FileServerHandler.java 可以看到, 第一步是通过 RandomAccessFile 打开一个文件, 然后 Netty 使用了 DefaultFileRegion 来封装一个 FileChannel 即:
`new` `DefaultFileRegion(raf.getChannel(), ``0``, length)`
当有了 FileRegion 后, 我们就可以直接通过它将文件的内容直接写入 Channel 中, 而不需要像传统的做法: 拷贝文件内容到临时 buffer, 然后再将 buffer 写入 Channel. 通过这样的零拷贝操作, 无疑对传输大文件很有帮助.
精彩问答
问:据我之前了解到,Java的NIO selector底层在Windows下的实现是起两个随机端口互联来监测连接或读写事件,在Linux上是利用管道实现的;我有遇到过这样的需求,需要占用很多个固定端口做服务端,如果在Windows下,利用NIO框架(Mina或Netty)就有可能会造成端口冲突,这种情况有什么好的解决方案吗?
你说的问题确实存在,Linux使用Pipe实现网络监听,Windows要启动端口。目前没有更好的办法,建议的方式是作为服务端的端口可以规划一个范围,然后根据节点和进程信息动态生成,如果发现端口冲突,可以在规划范围内基于算法重新生成一个新的端口。
问:请我,我现在将Spring与Netty做了整合,使用Spring的Service开启 Netty主线程,但是停止整个运行容器的时候,Netty的TCP Server端口不能释放?退出处理时,有什么好的办法释放Netty Server端口么?
实际上,由谁拉起Netty 主线程并不重要。我们需要做的就是当应用容器退出的时候(Spring Context销毁),在退出之前调用Netty 的优雅退出接口即可实现端口、NIO线程资源的释放。请参考这篇文章:http://www.infoq.com/cn/articles/netty-elegant-exit-mechanism-and-principles
问:适合用Netty写Web通信么?
Netty不是Web框架,无法解析JSP、HTML、JS等,但是它可以做Web 通信,例如可以使用Netty重写Tomcat的HTTP/HTTPS 通信协议栈。
问:能不能讲解一下Netty的串行无锁化设计,如何在串行和并行中达到最优?
为了尽可能提升性能,Netty采用了串行无锁化设计,在IO线程内部进行串行操作,避免多线程竞争导致的性能下降。表面上看,串行化设计似乎CPU利用率不高,并发程度不够。但是,通过调整NIO线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部无锁化的串行线程设计相比一个队列-多个工作线程模型性能更优。Netty的NioEventLoop读取到消息之后,直接调用ChannelPipeline的fireChannelRead(Object msg),只要用户不主动切换线程,一直会由NioEventLoop调用到用户的Handler,期间不进行线程切换,这种串行化处理方式避免了多线程操作导致的锁的竞争,从性能角度看是最优的。
一篇文章,读懂Netty的高性能架构之道的更多相关文章
- 一篇文章,读懂 Netty 的高性能架构之道
原文 Netty是一个高性能.异步事件驱动的NIO框架,它提供了对TCP.UDP和文件传输的支持,作为一个异步NIO框架,Netty的所有IO操作都是异步非阻塞的,通过Future-Listener机 ...
- 读懂Netty的高性能架构之道
Netty是一个高性能.异步事件驱动的NIO框架,它提供了对TCP.UDP和文件传输的支持,作为一个异步NIO框架,Netty的所有IO操作都是异步非阻塞的,通过Future-Listener机制,用 ...
- Netty学习总结(2)——Netty的高性能架构之道
Netty是一个高性能.异步事件驱动的NIO框架,它提供了对TCP.UDP和文件传输的支持,作为一个异步NIO框架,Netty的所有IO操作都是异步非阻塞的,通过Future-Listener机制,用 ...
- 揭秘Kafka高性能架构之道 - Kafka设计解析(六)
原创文章,同步首发自作者个人博客.转载请务必在文章开头处以超链接形式注明出处http://www.jasongj.com/kafka/high_throughput/ 摘要 上一篇文章<Kafk ...
- Kafka设计解析(六)Kafka高性能架构之道
转载自 技术世界,原文链接 Kafka设计解析(六)- Kafka高性能架构之道 本文从宏观架构层面和微观实现层面分析了Kafka如何实现高性能.包含Kafka如何利用Partition实现并行处理和 ...
- 【Kubernetes】两篇文章 搞懂 K8s 的 fannel 网络原理
近期公司的flannel网络很不稳定,花时间研究了下并且保证云端自动部署的网络能够正常work. 1.网络拓扑 拓扑如下:(点开看大图) 容器网卡通过docker0桥接到flannel0网卡,而每个 ...
- Linux零拷贝技术,看完这篇文章就懂了
本文首发于我的公众号 Linux云计算网络(id: cloud_dev),专注于干货分享,号内有 10T 书籍和视频资源,后台回复 「1024」 即可领取,欢迎大家关注,二维码文末可以扫. 本文讲解 ...
- 一文读懂 SuperEdge 边缘容器架构与原理
前言 superedge是腾讯推出的Kubernetes-native边缘计算管理框架.相比openyurt以及kubeedge,superedge除了具备Kubernetes零侵入以及边缘自治特性, ...
- Kafka设计解析(六)- Kafka高性能架构之道
本文从宏观架构层面和微观实现层面分析了Kafka如何实现高性能.包含Kafka如何利用Partition实现并行处理和提供水平扩展能力,如何通过ISR实现可用性和数据一致性的动态平衡,如何使用NIO和 ...
随机推荐
- nginx+tomcat把带WWW域名自动跳转到不带www域名方法
nginx+tomcat把带WWW域名自动跳转到不带www域名方法在nginx.conf里面 include /etc/nginx/conf.d/*.conf;在应该server里增加: if ($h ...
- Qt 学习之路 2(55):数据库操作
Qt 提供了 QtSql 模块来提供平台独立的基于 SQL 的数据库操作.这里我们所说的“平台独立”,既包括操作系统平台,又包括各个数据库平台.另外,我们强调了“基于 SQL”,因为 NoSQL 数据 ...
- web前端----JavaScript对象
简介: 在JavaScript中除了null和undefined以外其他的数据类型都被定义成了对象,也可以用创建对象的方法定义变量,String.Math.Array.Date.RegExp都是Jav ...
- P3868 [TJOI2009]猜数字
[TJOI2009]猜数字 中国剩余定理 求解i=1 to n : x≡a[i] (mod b[i])的同余方程组 设 t= ∏i=1 to n b[i] 我们先求出 i=1 to n : x≡1 ( ...
- 08:Python数据分析之pandas学习
1.1 数据结构介绍 参考博客:http://www.cnblogs.com/nxld/p/6058591.html 1.pandas介绍 1. 在pandas中有两类非常重要的数据结构,即序列Ser ...
- 03: MySQL基本操作
MySQL其他篇 目录: 参考网站 1.1 MySQL 三种数据类型(数值,字符串,日期) 1.2 MySQL常用增删改查命令 1.3 删除,添加或修改表字段 1.4 MySQL外键关联(一对多) 1 ...
- msf辅助模块的应用——20145301
msf辅助模块的应用 实验步骤 创建msf所需的数据库 service postgresql start msfdb start 开启msf,输入命令 use auxiliary/scanner/di ...
- Duilib 控件类html富文本绘制
转载:http://blog.csdn.net/wyansai/article/details/51088896 转载:http://blog.csdn.net/lixiang987654321/ar ...
- cogs 1962. [HAOI2015]树上染色
★★☆ 输入文件:haoi2015_t1.in 输出文件:haoi2015_t1.out 简单对比 时间限制:1 s 内存限制:256 MB [题目描述] 有一棵点数为N的树,树边有边 ...
- JavaScript 小知识
1.var 变量 <script type="text/javascript"> var a = "hong"; var fun = functio ...