【Python爬虫】如何确定自己浏览器的User-Agent信息
User-Agent:简称UA,它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本、浏览器及版本等信息。在做爬虫时加上此信息,可以伪装为浏览器;如果不加,很可能会被识别出为爬虫。
那么如何确定自己浏览器的User-Agent信息呢?
步骤如下:
1. 首先打开你的浏览器输入:about:version。

2. 输入后,浏览器会跳出图中的界面,红笔标出的“用户代理”一行就是浏览器的User-Agent。
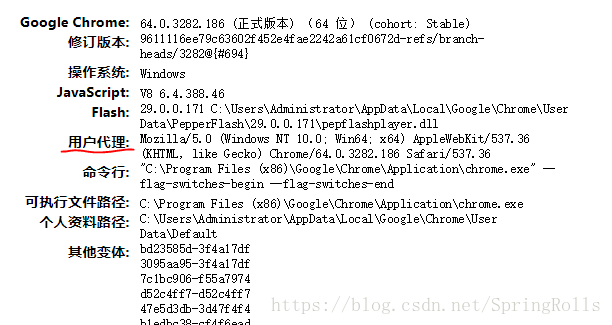
3. 当python要浏览网页时,按图中的方法,即可获得浏览器的权限。

【Python爬虫】如何确定自己浏览器的User-Agent信息的更多相关文章
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- python爬虫:使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少.原因他也大概分析了下,就是后面的图片是动态加载的.他的问题就是这部分动 ...
- python爬虫01在Chrome浏览器抓包
尽量不要用国产浏览器,很多是有后门的 chrome是首选 百度 按下F12 element标签下对应的HTML代码 点击Network,可以看到很多请求 HTTP请求的方式有好几种,GET,POST, ...
- Python爬虫:常用的浏览器请求头User-Agent(转)
原文地址:https://blog.csdn.net/mouday/article/details/80182397 user_agent = [ "Mozilla/5.0 (Macinto ...
- python爬虫之路——无头浏览器初识及简单例子
from selenium import webdriver url='https://www.jianshu.com/p/a64529b4ccf3' def get_info(url): inclu ...
- Python爬虫框架Scrapy获得定向打击批量招聘信息
爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这样的说法不够专业,更专业的描写叙述就是.抓取特定站点网页的HTML数据.只是因为一个站点的网页非常多,而我们又不可能事先知道全部网页的URL地址, ...
- [python爬虫] Selenium定向爬取PubMed生物医学摘要信息
本文主要是自己的在线代码笔记.在生物医学本体Ontology构建过程中,我使用Selenium定向爬取生物医学PubMed数据库的内容. PubMed是一个免费的搜寻引擎,提供生物医学方 ...
- Python爬虫(二十)_动态爬取影评信息
本案例介绍从JavaScript中采集加载的数据.更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import requests import re import t ...
- python爬虫实战之爬取智联职位信息和博客文章信息
1.python爬取招聘信息 简单爬取智联招聘职位信息 # !/usr/bin/env python # -*-coding:utf-8-*- """ @Author ...
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
随机推荐
- gradle 两种更新方法
第一种.Android studio更新 第一步:在你所在项目文件夹下:你项目根目录gradlewrappergradle-wrapper.properties 替换 distributionUrl= ...
- RN(八)——react-native-image-viewer & react-native-swiper
以项目(业务GO)为例: react-native-swiper 轮播(用在首页的图集轮播) https://github.com/leecade/react-native-swiper react- ...
- 在RDLC报表中对纸张的设置
RDLC报表是存放成XML文件格式的,这一点你可以直接打开RDLC报表文件看一下,而且在使用时,通过ReportViewer来读取报表并与数据源进行合成,也就是说RDLC是定义了一个格式,那就不能通过 ...
- 使用CreateProcess创建新的process 并返回process运行结束返回值
转自:http://blog.csdn.net/zgl7903/article/details/5975284 转载这篇主要是记住:获得create的新进程运行结束时的返回值的方法 如下: #in ...
- MongoDB安装问题以及启动
在安装MongoDB的文件中找到bin文件,其中有mongo.exe应用程序,双击打开会出现第二幅图的样子. 将MongoDB服务器作为Windows服务运行,运行后,不知道为什么无法启动,即使删除d ...
- 《转》Python学习(16)-python异常
转自 http://www.cnblogs.com/BeginMan/p/3171445.html 一.什么是错误,什么是异常,它们两者区别 这里解释如下:个人觉得很通俗易懂 错误是指在执行代码过程中 ...
- 【cs229-Lecture4】GLMS:选定指数分布族,如何用它来推导出GLM?
在Lecture4中有3部分内容: Newton’s method 牛顿方法 Exceponential Family 指数分布族 Generalized Linear M ...
- try except与try finally不同之处
try except与try finally不同之处 try//尝试执行 {SomeCode} except//出错的时候执行, Except有特定的错误类型 {SomeCode} end; t ...
- 修改JS文件不能及时在页面中体现,需重启浏览器?
对JS文件做个小小的改动,哪怕是加一句简单的ALERT语句,都要重启浏览器才能看到.你有这样的烦恼吗?怎样不用重启浏览器就能及时体现JS的变化呢? 对浏览器(IE)做如下设置即可:1.点击 工具栏 - ...
- Oracle —— 如何执行SQL文件
在Command模式下(笔者使用的是 PL/SQL Comand Window),输入 @文件路径\文件名 如: @D:\ORA_SQL\INSERT_SQL.sql