MapReduce – 基本思路之推荐引擎
理解MapReduce关键两个步骤;
首先是构想出结构的数据结构,这种数据结构可以支撑你的业务分析使用;是要理解这种模式的处理元素。
第二步,分析原始数据的结构是怎样的;
第三步,基于原始数据结构以及目标数据结构,在分析map的实现逻辑,返回值什么,sort-shuffle之后的值什么,这个值也是reduce的入口参数,然后是reduce的逻辑是什么,以符合目标结构;
map和reduce在处理数据上面的很大差别在于map之后会有一个汇总过程,按照key进行汇聚(发生在sort-shuffle阶段);reduce产生的数据不会再有这个过程,产生的是什么数据,加入到集合中之后,这个数据集合再无其他操作;如果再次把这个数据集合作为下一个阶段的Map-Reduce。
对于"购买过该商品的用户还购买了哪些商品",这个需求,分析过程如下:
0. 目标数据结构是:key:商品(主体);value:关联商品+权值(数量)列表;
1. 实现要明白map的入口参数是什么样子,用户对应一个商品;
2. 分析一下map之后数据,是一个商品对应多个商品;
3. shuffle没有什么特别处理;
3. reduce没有什么特别处理;
下面是第二轮mapreduce:
1. 入口参数是一个用户对多个商品;
2. map返回值某个用户的某个商品对应多个相关联的商品;
3. map之后shuffle合并是个集合,集合中的元素是:key是某个商品,value是相关联的商品List,此时这个list里面可能会有很多重复项;
4. reduce的入口参数是上步中介绍的内容;reduce处理之后,变成了key:某个商品;value:关联商品以及该商品的累加个数;
下面的是应用:基于reduce处理的数据,我们可以获得某个商品关联度最高的前N个商品(累加个数最高的N的)
处理的全流程如下图所示:
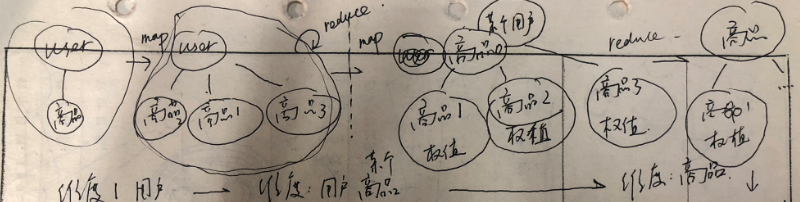
注意其实处理的维度的变化,阶段1map的处理维度还是在user;到了阶段儿的map处理维度是用户+商品,到了阶段2的reduce就抛弃了用户了,而是完全在商品的维度了;reduce的一个功能就是"降维",这个是我的一个说法,其实"降维"是指原本的key不管了,而是从value中在建立一套key-value数据结构;因为reduce功能是group,group意味着可以抛弃一个数据维度,或者说忽略某些个数据维度。
继续,对于"经常一起购买的商品":
0. 构想目标数据结构:key:商品;value:关联商品+权值列表;
1. 你要原始的数据集合中,一条记录的结构是交易-产品列表;
2. 在map阶段,直接"降维",抛弃key(交易ID),对于产品列表做两两配对;shuffle之后的数据集合的元素结构是[<p1,p2>, 1];
3. 到了reduce阶段,就是按照<p1, p2>进行汇聚,输出的是数据集合的元素结构是[<p1, p2>, n];
应用:
找到p1=XX,n最高的3个产品作为推荐。
第三波,难度比较大了,推荐好友,A和B是好友,B是C的好友,那么AC要双向推荐一下。
我最初的想法是做差集;A-B的人向B做推荐,B-A的人想A做推荐;但是这样算法无法获取共同好友,我们登录QQ看到推荐的时候,一般都会看到你和以下人是好友;
0. 构想目标数据结构,key:主体人,value:[推 荐者,List<共同好友>]
1. 原始数据结构:key:主体人,value:List<Friends>
2. map输出的是key:被推荐人;value:[推荐好友, 共同好友(入参的主体人)];shuffle之后是key是推荐人;value推荐好友列表;
3. reduce逻辑则是将被推荐人的推荐好友叠加到List中,同时叠加该推荐好友的共同朋友;
MapReduce – 基本思路之推荐引擎的更多相关文章
- PredictionIO+Universal Recommender快速开发部署推荐引擎的问题总结(3)
PredictionIO+Universal Recommender虽然可以帮助中小企业快速的搭建部署基于用户行为协同过滤的个性化推荐引擎,单纯从引擎层面来看,开发成本近乎于零,但仍然需要一些前提条件 ...
- 简易推荐引擎的python实现
代码地址如下:http://www.demodashi.com/demo/12913.html 主要思路 使用协同过滤的思路,从当前指定的用户过去的行为和其他用户的过去行为的相似度进行相似度评分,然后 ...
- 机器学习 101 Mahout 简介 建立一个推荐引擎 使用 Mahout 实现集群 使用 Mahout 实现内容分类 结束语 下载资源
机器学习 101 Mahout 简介 建立一个推荐引擎 使用 Mahout 实现集群 使用 Mahout 实现内容分类 结束语 下载资源 相关主题 在信息时代,公司和个人的成功越来越依赖于迅速 ...
- 数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)
七,共同好友. 在所有用户对中找出“共同好友”. eg: a b,c,d,g b a,c,d,e map()-> <a,b>,<b,c,d,g> ;< ...
- 从源代码剖析Mahout推荐引擎
转载自:http://blog.fens.me/mahout-recommend-engine/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pi ...
- 基于Azure构建PredictionIO和Spark的推荐引擎服务
基于Azure构建PredictionIO和Spark的推荐引擎服务 1. 在Azure构建Ubuntu 16.04虚拟机 假设前提条件您已有 Azure 帐号,登陆 Azure https://po ...
- [转] 基于 Apache Mahout 构建社会化推荐引擎
来源:http://www.ibm.com/developerworks/cn/java/j-lo-mahout/index.html 推荐引擎简介 推荐引擎利用特殊的信息过滤(IF,Informat ...
- 基于Spark ALS构建商品推荐引擎
基于Spark ALS构建商品推荐引擎 一般来讲,推荐引擎试图对用户与某类物品之间的联系建模,其想法是预测人们可能喜好的物品并通过探索物品之间的联系来辅助这个过程,让用户能更快速.更准确的获得所需 ...
- JVM调优(这里主要是针对优化基于分布式Mahout的推荐引擎)
优化推荐系统的JVM关键参数 -Xmx 设定Java允许使用的最大堆空间.例如-Xmx512m表示堆空间上限为512MB -server 现代JVM有两个重要标志:-client和-server,分别 ...
随机推荐
- ioS UI-导航控制器(NavigationController)
#import "AppDelegate.h" #import "ViewController.h" @interface AppDelegate () @en ...
- 利用CNN进行流量识别 本质上就是将流量视作一个图像
from:https://netsec2018.files.wordpress.com/2017/12/e6b7b1e5baa6e5ada6e4b9a0e59ca8e7bd91e7bb9ce5ae89 ...
- mysql主从搭建之诡异事件
今天在搭建主从后出现了主库system账号丢失INSERT权限的情况,记录如下 主库: system账号权限同root权限,并且mysql库已经删除 从库: mysql库存在,无system账号 主从 ...
- C++中的接口继承和实现继承
很多人认为,C++中是不存在接口继承的,只有Java.C#这类语言才提供了相应的语法支持. 但是,如同鲁迅说过的某句名言:世上本没有接口继承,用的人多了,才有了接口继承.C++中依然可以实现接口继承, ...
- 使用Mockito时遇到的一些问题
最近在使用Mockito时遇到了几个比较tricking的问题,在这里记录一下. 1.如果方法的参数或者返回类型是泛型通配符相关的(如<?>,<? extends XXX>), ...
- 2018-北航-面向对象567次OO作业分析与小结
设计策略及其变化 第五次作业-多线程电梯 在这次作业一开始的大部分时间,我一直想着怎样设计最为完美,完全使用BlockingQueue,导致交作业前发现设计并不能满足指导书的要求.最后仓皇之中加了一个 ...
- Apache 服务器认证 和重写
htaccess文件是Apache服务器中的一个配置文件,它负责相关目录下的网页配置.通过htaccess文件,可以帮我们实现:网页301重定向.自定义404错误页面.改变文件扩展名.允许/阻止特定的 ...
- TV-B-Gone Kit - Universal v1.2
- 12个有趣的 XSS Vector
XSS Vector #1 <script src=/〱20.rs></script> URL中第二个斜杠在Internet Explorer下(测试于IE11)可被U+303 ...
- makefile的一个错误:*** missing separator
原文转自:http://blog.sina.com.cn/s/blog_87c063060101c9yp.html 1.在写 多目录下makefile的时候,碰到一个错误提示,让我纠结许久,后面还是解 ...