Java LinkedList源码剖析
LinkedList
总体介绍
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(它是个接口名字)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
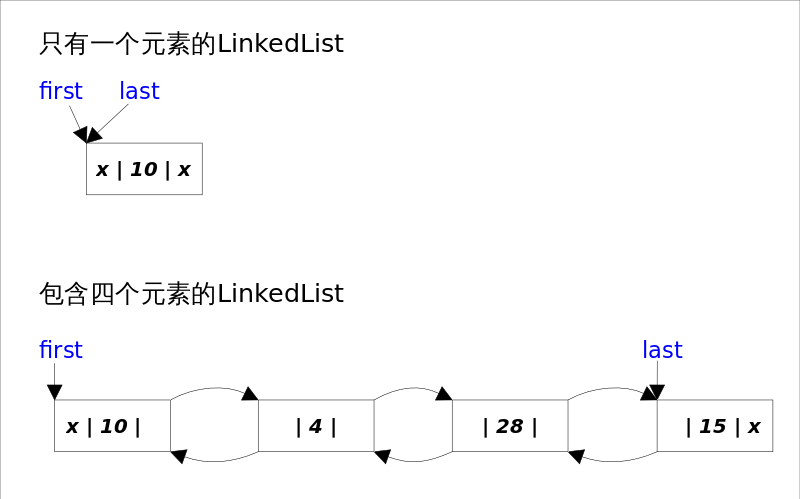
LinkedList底层通过双向链表实现,本节将着重讲解插入和删除元素时双向链表的维护过程,也即是之间解跟List接口相关的函数,而将Queue和Stack以及Deque相关的知识放在下一节讲。双向链表的每个节点用内部类Node表示。LinkedList通过first和last引用分别指向链表的第一个和最后一个元素。注意这里没有所谓的哑元,当链表为空的时候first和last都指向null。
//Node内部类
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList的实现方式决定了所有跟下标相关的操作都是线性时间,而在首段或者末尾删除元素只需要常数时间。为追求效率LinkedList没有实现同步(synchronized),如果需要多个线程并发访问,可以先采用Collections.synchronizedList()方法对其进行包装。
方法剖析
add()
add()方法有两个版本,一个是add(E e),该方法在LinkedList的末尾插入元素,因为有last指向链表末尾,在末尾插入元素的花费是常数时间。只需要简单修改几个相关引用即可;另一个是add(int index, E element),该方法是在指定下表处插入元素,需要先通过线性查找找到具体位置,然后修改相关引用完成插入操作。
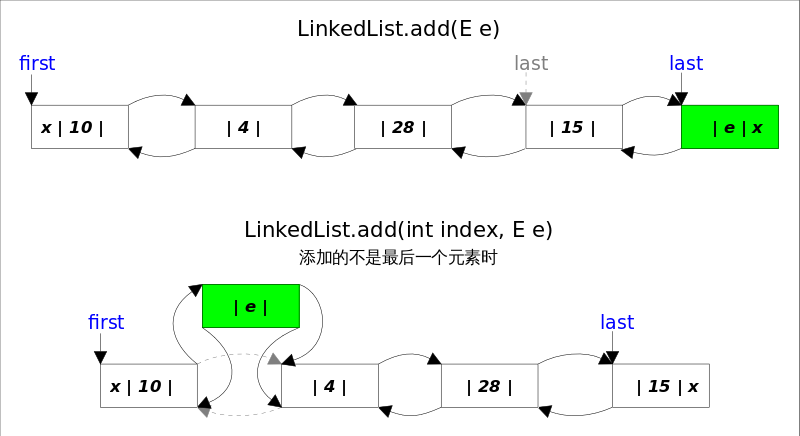
结合上图,可以看出add(E e)的逻辑非常简单。
//add(E e)
public boolean add(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;//原来链表为空,这是插入的第一个元素
else
l.next = newNode;
size++;
return true;
}
add(int index, E element)的逻辑稍显复杂,可以分成两部,1.先根据index找到要插入的位置;2.修改引用,完成插入操作。
//add(int index, E element)
public void add(int index, E element) {
checkPositionIndex(index);//index >= 0 && index <= size;
if (index == size)//插入位置是末尾,包括列表为空的情况
add(element);
else{
Node<E> succ = node(index);//1.先根据index找到要插入的位置
//2.修改引用,完成插入操作。
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)//插入位置为0
first = newNode;
else
pred.next = newNode;
size++;
}
}
上面代码中的node(int index)函数有一点小小的trick,因为链表双向的,可以从开始往后找,也可以从结尾往前找,具体朝那个方向找取决于条件index < (size >> 1),也即是index是靠近前端还是后端。
remove()
remove()方法也有两个版本,一个是删除跟指定元素相等的第一个元素remove(Object o),另一个是删除指定下标处的元素remove(int index)。
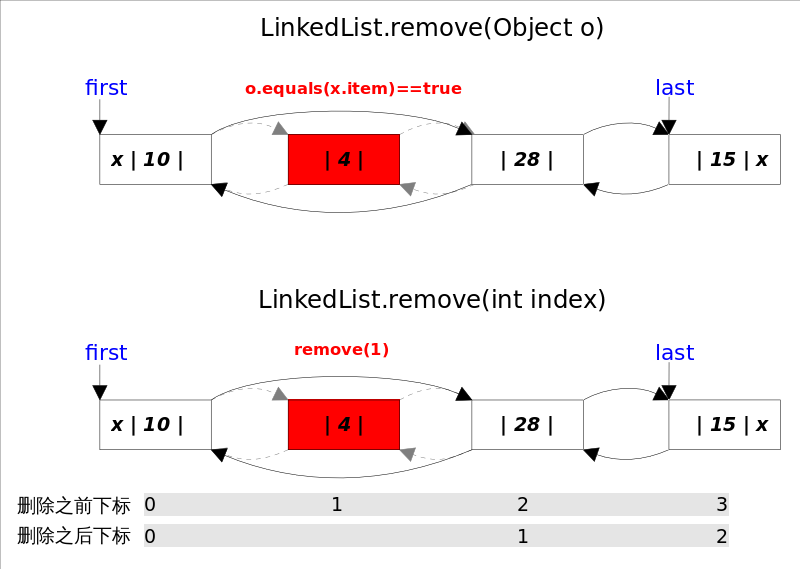
两个删除操作都要1.先找到要删除元素的引用,2.修改相关引用,完成删除操作。在寻找被删元素引用的时候remove(Object o)调用的是元素的equals方法,而remove(int index)使用的是下标计数,两种方式都是线性时间复杂度。在步骤2中,两个revome()方法都是通过unlink(Node<E> x)方法完成的。这里需要考虑删除元素是第一个或者最后一个时的边界情况。
//unlink(Node<E> x),删除一个Node
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {//删除的是第一个元素
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {//删除的是最后一个元素
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;//let GC work
size--;
return element;
}
get()
get(int index)得到指定下标处元素的引用,通过调用上文中提到的node(int index)方法实现。
public E get(int index) {
checkElementIndex(index);//index >= 0 && index < size;
return node(index).item;
}
set()
set(int index, E element)方法将指定下标处的元素修改成指定值,也是先通过node(int index)找到对应下表元素的引用,然后修改Node中item的值。
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;//替换新值
return oldVal;
}
Java LinkedList源码剖析的更多相关文章
- Java LinkedList 源码剖析
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack).这样看来,LinkedList简直就 ...
- Java ArrayList源码剖析
转自: Java ArrayList源码剖析 总体介绍 ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现.除该类未实现同步外 ...
- 转:【Java集合源码剖析】LinkedList源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/35787253 您好,我正在参加CSDN博文大赛,如果您喜欢我的文章,希望您能帮我投一票 ...
- LinkedList源码剖析
LinkedList简介 LinkedList是基于双向循环链表(从源码中可以很容易看出)实现的,除了可以当做链表来操作外,它还可以当做栈.队列和双端队列来使用. LinkedList同样是非线程安全 ...
- 转:【Java集合源码剖析】LinkedHashmap源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/37867985 前言:有网友建议分析下LinkedHashMap的源码,于是花了一晚上时 ...
- 转:【Java集合源码剖析】ArrayList源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/35568011 本篇博文参加了CSDN博文大赛,如果您觉得这篇博文不错,希望您能帮我投一 ...
- Java集合源码剖析——ArrayList源码剖析
ArrayList简介 ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长,类似于C语言中的动态申请内存,动态增长内存. ArrayList不是线程安全的,只能用在单线程环境下,多线 ...
- 转:【Java集合源码剖析】TreeMap源码剖析
前言 本文不打算延续前几篇的风格(对所有的源码加入注释),因为要理解透TreeMap的所有源码,对博主来说,确实需要耗费大量的时间和经历,目前看来不大可能有这么多时间的投入,故这里意在通过于阅读源码对 ...
- 转:【Java集合源码剖析】Hashtable源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36191279 Hashtable简介 Hashtable同样是基于哈希表实现的,同样每个元 ...
随机推荐
- mysql 权限管理 grant 命令
只有root账号可以授权,其他账号不能用grant 授权 mysql> select user(); +----------------+ | user() | +--------------- ...
- cookie与session的比较
首先来说一下什么是cookie:cookie是Web服务器保存在客户端的一系列文本信息: cookie的作用大致有三点:对特定对象的追踪,统计网页浏览次数,简化登陆. 它的安全性能是比较差的,容易泄露 ...
- phpmyadmin-配合nginx与php安装
1. 概况 phpMyAdmin是用来在网页端图形化操作MySQL数据库的工具,使用起来非常直观,目前最新版本是4.8.3.在搭建web集群架构时可能有这样的需求,数据库安装在专门的一台机器上,但是希 ...
- rsync+inotify安装配置 实时同步文件
安装 #安装inotify 工具 [root@localhost ~]# yum install inotify-tools -y 常用命令 [root@localhost ~]# inotifywa ...
- 支持向量机(SVM)、支持向量回归(SVR)
1.支持向量机( SVM )是一种比较好的实现了结构风险最小化思想的方法.它的机器学习策略是结构风险最小化原则 为了最小化期望风险,应同时最小化经验风险和置信范围) 支持向量机方法的基本思想: ( 1 ...
- selenium-python:登录网站并签到
测试网站的图像验证码统一设置成了:121 Elements中定位元素比较费眼睛~~ import time from selenium import webdriver # import os use ...
- [LeetCode] 680. Valid Palindrome II_Easy tag: Two Pointers
Given a non-empty string s, you may delete at most one character. Judge whether you can make it a pa ...
- 4.keras实现-->生成式深度学习之DeepDream
DeepDream是一种艺术性的图像修改技术,它用到了卷积神经网络学到的表示,DeepDream由Google于2015年发布.这个算法与卷积神经网络过滤器可视化技术几乎相同,都是反向运行一个卷积神经 ...
- python进程同步,condition例子
#coding=utf-8import multiprocessing as mpimport time def consumer(cond): with cond: print ...
- 安装vscode with springboot
1.安装jdk8 2.下载vscode,一切按照默认配置完成安装.下载地址:https://code.visualstudio.com 3.安装完成后,运行vscode.如果没有任何反应,在命令行上运 ...