Spark+IDEA单机版环境搭建+IDEA快捷键
1. IDEA中配置Spark运行环境
请参考博文:http://www.cnblogs.com/jackchen-Net/p/6867838.html
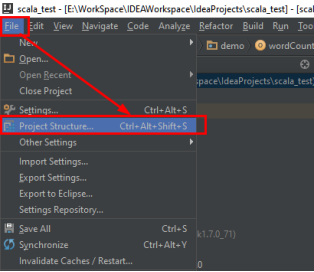
3.1.Project Struct查看项目的配置信息
3.2.IDEA中如果没有默认安装Scala,可在本地安装即可
如果需要安装多版本的scala请注意:
如果您在本地已经安装了msi结尾的scala,还需要安装第二个版本,建议下载zip包,优点是直接解压在IDEA中配置即可。如第3步所示。
注意:scala下载地址:http://www.scala-lang.org/download/2.10.4.html
3.3.查看scala环境配置,可以通过下图绿色的”+”添加本地已经下载的scala安装包


3.4.特别注意,如果在执行spark代码遇到如下问题,请更改scala版本
Exception in thread "main" java.lang.NoSuchMethodError:
scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;
at akka.actor.ActorCell$.<init>(ActorCell.scala:336)
at akka.actor.ActorCell$.<clinit>(ActorCell.scala)
at akka.actor.RootActorPath.$div(ActorPath.scala:159)
at akka.actor.LocalActorRefProvider.<init>(ActorRefProvider.scala:464)
at akka.actor.LocalActorRefProvider.<init>(ActorRefProvider.scala:452)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
at akka.actor.ReflectiveDynamicAccess$$anonfun$createInstanceFor$2.apply(DynamicAccess.scala:78)
at scala.util.Try$.apply(Try.scala:191)
at akka.actor.ReflectiveDynamicAccess.createInstanceFor(DynamicAccess.scala:73)
at akka.actor.ReflectiveDynamicAccess$$anonfun$createInstanceFor$3.apply(DynamicAccess.scala:84)
at akka.actor.ReflectiveDynamicAccess$$anonfun$createInstanceFor$3.apply(DynamicAccess.scala:84)
at scala.util.Success.flatMap(Try.scala:230)
at akka.actor.ReflectiveDynamicAccess.createInstanceFor(DynamicAccess.scala:84)
at akka.actor.ActorSystemImpl.liftedTree1$1(ActorSystem.scala:584)
at akka.actor.ActorSystemImpl.<init>(ActorSystem.scala:577)
at akka.actor.ActorSystem$.apply(ActorSystem.scala:141)
at akka.actor.ActorSystem$.apply(ActorSystem.scala:108)
at akka.Akka$.delayedEndpoint$akka$Akka$1(Akka.scala:11)
at akka.Akka$delayedInit$body.apply(Akka.scala:9)
at scala.Function0$class.apply$mcV$sp(Function0.scala:40)
at scala.runtime.AbstractFunction0.apply$mcV$sp(AbstractFunction0.scala:12)
at scala.App$$anonfun$main$1.apply(App.scala:76)
at scala.App$$anonfun$main$1.apply(App.scala:76)
at scala.collection.immutable.List.foreach(List.scala:383)
at scala.collection.generic.TraversableForwarder$class.foreach(TraversableForwarder.scala:35)
at scala.App$class.main(App.scala:76)
at akka.Akka$.main(Akka.scala:9)
at akka.Akka.main(Akka.scala)
解决方法是将scala2.11版本改为2.10版本即可。(注意:spark版本为1.6.0)
3.5.导入程序运行所需要的jar包
- 通过libary,点击”+”将spark-assembly-1.6.0-hadoop2.6.0.jar导入Classes位置
- 通过spark官网下载spark1.6.0的源码文件(spark1.6.0-src.tgz)解压在windows本地后,通过点击最右侧的”+”导入所有的源码包,从而可以查看源代码。

3.6.建立一个scala文件并写代码
package com.bigdata.demo
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by SimonsZhao on 3/25/2017.
*/
object wordCount {
def main(args: Array[String]) {
val conf =new SparkConf().setMaster("local").setAppName("wordCount")
val sc =new SparkContext(conf)
val data=sc.textFile("E://scala//spark//testdata//word.txt")
data.flatMap(_.split("\t")).map((_,)).reduceByKey(_+_).collect().foreach(println)
}
}
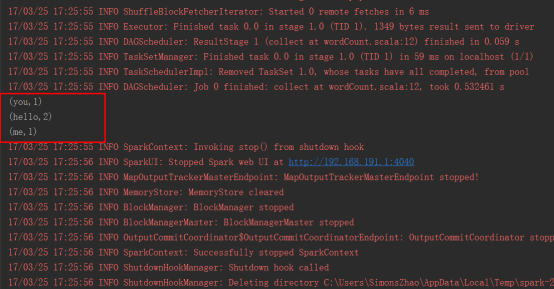
3.7.运行结果
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
// :: INFO SparkContext: Running Spark version 1.6.
// :: WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO SecurityManager: Changing view acls to: SimonsZhao
// :: INFO SecurityManager: Changing modify acls to: SimonsZhao
// :: INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(SimonsZhao); users with modify permissions: Set(SimonsZhao)
// :: INFO Utils: Successfully started service 'sparkDriver' on port .
// :: INFO Slf4jLogger: Slf4jLogger started
// :: INFO Remoting: Starting remoting
// :: INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.191.1:53292]
// :: INFO Utils: Successfully started service 'sparkDriverActorSystem' on port .
// :: INFO SparkEnv: Registering MapOutputTracker
// :: INFO SparkEnv: Registering BlockManagerMaster
// :: INFO DiskBlockManager: Created local directory at C:\Users\SimonsZhao\AppData\Local\Temp\blockmgr-7e548732-b1db-4e3c-acdb-37e686b10dff
// :: INFO MemoryStore: MemoryStore started with capacity 2.4 GB
// :: INFO SparkEnv: Registering OutputCommitCoordinator
// :: INFO Utils: Successfully started service 'SparkUI' on port .
// :: INFO SparkUI: Started SparkUI at http://192.168.191.1:4040
// :: INFO Executor: Starting executor ID driver on host localhost
// :: INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port .
// :: INFO NettyBlockTransferService: Server created on
// :: INFO BlockManagerMaster: Trying to register BlockManager
// :: INFO BlockManagerMasterEndpoint: Registering block manager localhost: with 2.4 GB RAM, BlockManagerId(driver, localhost, )
// :: INFO BlockManagerMaster: Registered BlockManager
// :: INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 153.6 KB, free 153.6 KB)
// :: INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 13.9 KB, free 167.5 KB)
// :: INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost: (size: 13.9 KB, free: 2.4 GB)
// :: INFO SparkContext: Created broadcast from textFile at wordCount.scala:
// :: WARN : Your hostname, SimonsCJ resolves to a loopback/non-reachable address: fe80:::::5efe:c0a8:bf01%, but we couldn't find any external IP address!
// :: INFO FileInputFormat: Total input paths to process :
// :: INFO SparkContext: Starting job: collect at wordCount.scala:
// :: INFO DAGScheduler: Registering RDD (map at wordCount.scala:)
// :: INFO DAGScheduler: Got job (collect at wordCount.scala:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (collect at wordCount.scala:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List(ShuffleMapStage )
// :: INFO DAGScheduler: Submitting ShuffleMapStage (MapPartitionsRDD[] at map at wordCount.scala:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.1 KB, free 171.6 KB)
// :: INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.3 KB, free 173.9 KB)
// :: INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost: (size: 2.3 KB, free: 2.4 GB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ShuffleMapStage (MapPartitionsRDD[] at map at wordCount.scala:)
// :: INFO TaskSchedulerImpl: Adding task set 0.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID , localhost, partition ,PROCESS_LOCAL, bytes)
// :: INFO Executor: Running task 0.0 in stage 0.0 (TID )
// :: INFO HadoopRDD: Input split: file:/E:/scala/spark/testdata/word.txt:+
// :: INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
// :: INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
// :: INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
// :: INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
// :: INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
// :: INFO Executor: Finished task 0.0 in stage 0.0 (TID ). bytes result sent to driver
// :: INFO DAGScheduler: ShuffleMapStage (map at wordCount.scala:) finished in 0.228 s
// :: INFO DAGScheduler: looking for newly runnable stages
// :: INFO DAGScheduler: running: Set()
// :: INFO DAGScheduler: waiting: Set(ResultStage )
// :: INFO DAGScheduler: failed: Set()
// :: INFO DAGScheduler: Submitting ResultStage (ShuffledRDD[] at reduceByKey at wordCount.scala:), which has no missing parents
// :: INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID ) in ms on localhost (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
// :: INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.6 KB, free 176.4 KB)
// :: INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1600.0 B, free 178.0 KB)
// :: INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost: (size: 1600.0 B, free: 2.4 GB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (ShuffledRDD[] at reduceByKey at wordCount.scala:)
// :: INFO TaskSchedulerImpl: Adding task set 1.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID , localhost, partition ,NODE_LOCAL, bytes)
// :: INFO Executor: Running task 0.0 in stage 1.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 0.0 in stage 1.0 (TID ). bytes result sent to driver
// :: INFO DAGScheduler: ResultStage (collect at wordCount.scala:) finished in 0.059 s
// :: INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID ) in ms on localhost (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: Job finished: collect at wordCount.scala:, took 0.532461 s
(you,1)
(hello,2)
(me,1)
// :: INFO SparkContext: Invoking stop() from shutdown hook
// :: INFO SparkUI: Stopped Spark web UI at http://192.168.191.1:4040
// :: INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
// :: INFO MemoryStore: MemoryStore cleared
// :: INFO BlockManager: BlockManager stopped
// :: INFO BlockManagerMaster: BlockManagerMaster stopped
// :: INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
// :: INFO SparkContext: Successfully stopped SparkContext
// :: INFO ShutdownHookManager: Shutdown hook called
// :: INFO ShutdownHookManager: Deleting directory C:\Users\SimonsZhao\AppData\Local\Temp\spark-220c67fe-f2c3-400b-bfe1-fe833e33e74f

2.Spark在windows环境搭建
2.1.进入spark官网下载对应hadoop版本的spark安装文件
http://spark.apache.org/docs/latest/
2.2.在windows下面配置环境变量(新建SPARK_HOME系统变量,输入spark安装文件路径,在PATH中加入%SPARK_HOME%\bin;变量即可。)
进入windows控制台中,直接输入spark-shell即可显示如下图。
否则,需要进入下载的spark1.6.0的下载安装目录中,执行spark-shell
执行结果如下:

3.测试是否正确:
3.1.准备数据
E:\scala\spark\testdata中的work.txt文件中写入以下文件
Hello you
Hello me
3.2.输入并查看结果输出



3.其他可能碰到的问题
java.lang.RuntimeException: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS should be writable. Curr
正常情况下是可以运行成功并进入到Spark的命令行环境下的,但是对于有些用户可能会遇到空指针的错误。这个时候,主要是因为Hadoop的bin目录下没有winutils.exe文件的原因造成的。这里的解决办法是:
- 前往 https://github.com/steveloughran/winutils 下载该项目的zip包在你的系统中,然后选择你安装的Hadoop版本号,然后进入到bin目录下,将找到的
winutils.exe这个文件放入到Hadoop的bin目录下,我这里是F:\hadoop\bin。
- 在打开的cmd中输入
F:\hadoop\bin\winutils.exe chmod 777 /tmp/Hive这个操作是用来修改权限的。注意前面的F:\hadoop\bin部分要对应的替换成实际你所安装的bin目录所在位置。 - 经过这几个步骤之后,然后再次开启一个新的cmd窗口,如果正常的话,应该就可以通过直接输入
spark-shell来运行Spark了。
END~
4.IDEA 快捷键常用集锦
/**
* IDEA快捷键
* Alt+enter 导入包,自动修正
* ctrl+alt+L 自动格式化代码
* alt+insert 自动生成构造器、getter/setter等等常用方法
* ctrl+d 复制当前行到下一行
* shift+enter 另起一行
* ctrl+N 查找类
* 双击shift 在项目的所有目录查找,就是你想看到你不想看到的和你没想过你能看到的都给你找出来
* Ctrl+Alt+O 优化导入的类和包
* Ctrl+J 自动代码
* 按Ctrl-J组合键来执行一些你记不起来的Live Template缩写。比如,键“it”然后按Ctrl-J看看有什么发生。
* Ctrl+O可以选择父类的方法进行重写
* Ctrl+Q可以看JavaDoc
* Ctrl+Alt+M 抽取方法
* Ctrl+Alt+V 抽取局部变量
* Ctrl+Alt+C 抽取常量
* Ctrl+Alt+F 抽取实例变量
* Ctrl+Alt+t 使用if-else trycatch方法
* shift+alt+下箭头
*/
Spark+IDEA单机版环境搭建+IDEA快捷键的更多相关文章
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- spark JAVA 开发环境搭建及远程调试
spark JAVA 开发环境搭建及远程调试 以后要在项目中使用Spark 用户昵称文本做一下聚类分析,找出一些违规的昵称信息.以前折腾过Hadoop,于是看了下Spark官网的文档以及 github ...
- Spark 集群环境搭建
思路: ①先在主机s0上安装Scala和Spark,然后复制到其它两台主机s1.s2 ②分别配置三台主机环境变量,并使用source命令使之立即生效 主机映射信息如下: 192.168.32.100 ...
- Spark—local模式环境搭建
Spark--local模式环境搭建 一.Spark运行模式介绍 1.本地模式(loca模式):spark单机运行,一般用户测试和开发使用 2.Standalone模式:构建一个主从结构(Master ...
- Spark集群环境搭建——部署Spark集群
在前面我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等.并且已经安装好了hadoop集群. 如果还没有配置好的,参考我前面两篇博客: Spark集群环境搭建--服务器环境初始化:htt ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- Spark 准备篇-环境搭建
本章内容: 待整理 参考文献: 学习Spark——环境搭建(Mac版) <深入理解SPARK:核心思想与源码分析>(前言及第1章) 搭建Spark源码研读和代码调试的开发环境 Readin ...
- Hadoop、Spark 集群环境搭建
1.基础环境搭建 1.1运行环境说明 1.1.1硬软件环境 主机操作系统:Windows 64位,四核8线程,主频3.2G,8G内存 虚拟软件:VMware Workstation Pro 虚拟机操作 ...
- Spark集群环境搭建——服务器环境初始化
Spark也是属于Hadoop生态圈的一部分,需要用到Hadoop框架里的HDFS存储和YARN调度,可以用Spark来替换MR做分布式计算引擎. 接下来,讲解一下spark集群环境的搭建部署. 一. ...
随机推荐
- [原]unity3D 移动平台崩溃信息收集
http://m.blog.csdn.net/blog/catandrat111/8534287http://m.blog.csdn.net/blog/catandrat111/8534287
- 上机题目(0基础)- 用数组实现记事本(Java)
用java实现一个记事本程序,记录记下的按键,代码例如以下: package com.java.test; import java.awt.Graphics; import java.awt.even ...
- 自定义tag标签-实现long类型转换成Date类型
数据库里存储的是bigint型的时间,entity实体中存放的是long类型的标签,现在想输出到jsp页面,由于使用的是jstl标签,而要显示的是可读的时间类型,找来找去有个 fmt:formatDa ...
- 利用Visio绘制数据流图与组织结构图
绘制数据流图: 利用Visio 2007来绘制网上书店系统的数据流图.利用Visio 2007创建Gane- Sarson数据流图,可以选择“软件和数据库”模板,然后再选择“数据流模型图”,创建之后可 ...
- Git 学习笔记--Git下的冲突解决
冲突的产生 很多命令都可能出现冲突,但从根本上来讲,都是merge 和 patch(应用补丁)时产生冲突. 而rebase就是重新设置基准,然后应用补丁的过程,所以也会冲突. git pull会自动m ...
- psutil的使用
psutil是Python中广泛使用的开源项目,其提供了非常多的便利函数来获取操作系统的信息. 此外,还提供了许多命令行工具提供的功能,如ps,top,kill.free,iostat,iotop,p ...
- Vim 的 Python 编辑器详细配置过程 (Based on Ubuntu 12.04 LTS)
为什么要用vim编辑py文件? 因为在Linux命令行中,缺少图形界面的IDE,vim是最佳的文本编辑器,而为了更好的编辑py文本,所以配置vim. 1. 安装完整版vim vi和vim的区别? 在L ...
- Charles抓包(iOS的http/https请求)
Charles抓包(iOS的http/https请求) Charles安装 HTTP抓包 HTTPS抓包 1. Charles安装 官网下载安装Charles:https://www.charlesp ...
- VS中快捷键修改以及快捷键的查看
eclipse用习惯了一直想把VS中的alt+/改为自动补全,同时自定义一下C#环境下自动加入命名控件的快捷键,前段时间摸索了一下,找到了比较好的方法 首先是vs中修改快捷键的方法:工具->选项 ...
- WebService连接sql serever并使用Android端访问数据
一.下载sql serever(真真难下) 建立数据库 二.创建WebService VS2015中新建项目,进行连接调试 1. 服务资源管理文件->数据连接->新建连接 2. 继续-&g ...