Centralized Cache Management in HDFS
Overview(概述)
Centralized cache management in HDFS is an explicit caching mechanism that allows users to specify paths to be cached by HDFS. The NameNode will communicate with DataNodes that have the desired blocks on disk, and instruct them to cache the blocks in off-heap caches.
HDFS中的集中式缓存管理是一个显式的管理缓存的机制,它允许用户指定被HDFS缓存的路径。NameNode将与磁盘上有所需的Block的DataNode通信,命令其在堆外缓存里缓存Block。
Centralized cache management in HDFS has many significant advantages.
1. Explicit pinning prevents frequently used data from being evicted from memory. This is particularly important when the size of the working set exceeds the size of main memory, which is common for many HDFS workloads.
2. Because DataNode caches are managed by the NameNode, applications can query the set of cached block locations when making task placement decisions. Co-locating a task with a cached block replica improves read performance.
3. When block has been cached by a DataNode, clients can use a new , more-efficient, zero-copy read API. Since checksum verification of cached data is done once by the DataNode, clients can incur essentially zero overhead when using this new API.
4. Centralized caching can improve overall cluster memory utilization. When relying on the OS buffer cache at each DataNode, repeated reads of a block will result in all n replicas of the block being pulled into buffer cache. With centralized cache management, a user can explicitly pin only m of the n replicas, saving n-m memory.
HDFS中的集中式缓存管理有许多重要的优势。
1. 明确地防止频繁使用的数据被赶出内存。当工作集的大小超过住内存的大小时,这是特别重要的,这对HDFS负载是很常见的。
2. 因为DataNode缓存被NameNode管理,应用程序在做任务位置决定时可以查询被缓存的Block的位置。将一个task与一个缓存块的一个副本协同工作。
3. 当Block被一个DataNode缓存时,客户端可以使用一个新的,更有效的,0-copy的读操作API。因为缓存的块的checksum检查只被DataNode做一次,客户端可以使用新的API带来0开销的读操作。
4. 集中式缓存可以全面提高了集群内存的利用率。当依赖每个DataNode上操作系统的Buffer Cache时,重复读一个Block将导致这个块的N个副本被放到Buffer Cache中。使用集中式缓存管理,一个用户可以明确的创建m个副本,节省n-m个副本的内存。
Use Cases(应用缓存)
Centralized cache management is useful for files that accessed repeatedly. For example, a small fact table in Hive which is often used for joins is a good candidate for caching. On the other hand, caching the input of a one year reporting query is probably less useful, since the historical data might only be read once.
集中式缓存管理对于重复访问的文件是有用的。例如,hive中的一个小的fact table,在join操作时经常被用到,这个小的fact table就是一个很好的缓存的候选数据。另一方面,缓存一年的查询报告可能用处不大,因为这些历史数据可能只被读一次。
Centralized cache management is also useful for mixed workloads with performance SLAs. Caching the working set of a high-priority workload insures that it does not contend for disk I/O with a low-priority workload.
集中式缓存管理对于有服务级别协议的混合负载也是非常有用的。缓存高优先级负载的工作集确保低优先级的负载不竞争磁盘I/O。
Architecture(架构)
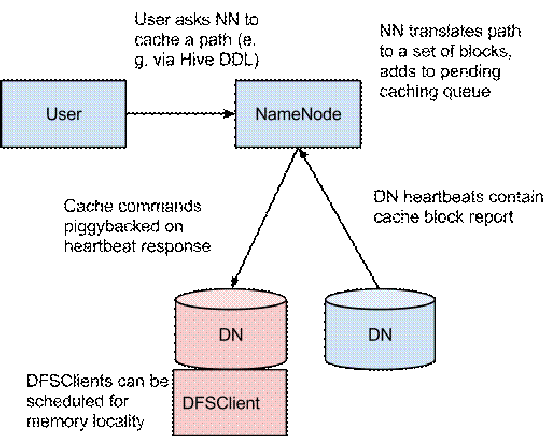
In this architecture, the NameNode is responsible for coordinating all the DataNode off-heap caches in the cluster. The NameNode periodically receives a cache report from each DataNode which describes all the blocks cached on a given DN. The NameNode manages DataNode caches by piggybacking cache and uncache commands on the DataNode heartbeat.
在这个架构中,NameNode负载协调集群中所有的DataNode栈外缓存。NameNode周期性地从每一个DataNode中收到一个缓存报告,这个报告描述了缓存在特定DataNode上的所有的Block。NameNode通过在心跳消息中背带缓存和不缓存的命令管理DataNode的缓存。
The NameNode queries its set of cache directives to determine which paths should be cached. Cache directives are persistently stored in the fsimage and edit log, and can be added, removed, and modified via Java and command-line APIs. The NameNode also stores a set of cache pools, which are administrative entities used to group cache directives together for resource management and enforcing permissions.
NameNode查询它的一系列缓冲指令来判定应该被缓存的路径。缓冲指令持久化存储在FsImage和editlog文件中,可以通过java或者命令行API被增加,删除和修改。NameNode以存储一系列的缓冲池,这是管理实体为了资源管理和强制许可用来分组缓存指令。
The NameNode periodically rescans the namespace and active cache directives to determine which blocks need to be cached or uncached and assign caching work to DataNodes. Rescans can also be triggered by user actions like adding or removing a cache directive or removing a cache pool.
NameNode周期性地扫描命名空间和Active的缓存指令来判定哪一个Block需要被缓存或者移除缓存,分配DataNode的缓存。重新扫描在用户执行像增加或者移除一条缓存指令或者移除一个缓冲池的时候被触发。
We do not currently cache blocks which are under construction, corrupt, or otherwise incomplete. If a cache directive covers a symlink, the symlink target is not cached.
目前,当Block正在构建、损坏或者有其他未完成的情况,Block不会被缓存。如果缓存指令是缓存一个符号链接,符号链接的目标不会被缓存。
Caching is currently done on the file or directory-level. Block and sub-block caching is an item of future work.
缓存目前只在文件或者目录级别。Block和子Block的缓存是将来工作中的一条。
Concepts(概念)
Cache directive
A cache directive defines a path that should be cached. Paths can be either directories or files. Directories are cached non-recursively, meaning only files in the first-level listing of the directory.
一个缓存指令定义了一个应该被缓存的路径。路径要么是目录要么是文件。目录非递归地被缓存,意味着值缓存目录列表中的文件级别的文件。
Directives also specify additional parameters, such as the cache replication factor and expiration time. The replication factor specifies the number of block replicas to cache. If multiple cache directives refer to the same file, the maximum cache replication factor is applied.
指令也指定额外的参数,像缓存副本因子和过期时间。副本因子指定被缓存的Block的副本的个数。如果多个缓存指令引用了同一个文件,最小的缓存副本因子将被应用。
The expiration time is specified on the command line as a time-to-live (TTL), a relative expiration time in the future. After a cache directive expires, it is no longer considered by the NameNode when making caching decisions.
过期时间在命令行作为TTL被指定,一个相对的过期时间。在一条缓存指令过期时,当NameNode做缓存决定时,它不在被NameNode考虑。
Cache pool
A cache pool is an administrative entity used to manage groups of cache directives. Cache pools have UNIX-like permissions, which restrict which users and groups have access to the pool. Write permissions allow users to add and remove cache directives to the pool. Read permissions allow users to list the cache directives in a pool, as well as additional metadata. Execute permissions are unused.
一个缓冲池是一个管理实体,用来管理缓存指令的分组。缓冲池有类Unix的权限,它限制用户和用户组访问缓冲池。写权限允许用户增加和删除缓冲池中的缓冲指令。读权限允许用户列出缓冲池中的缓冲指令和额外的元数据。没有可执行权限的概念。
Cache pools are also used for resource management. Pools can enforce a maximum limit, which restricts the number of bytes that can be cached in aggregate by directives in the pool. Normally, the sum of the pool limits will approximately equal the amount of aggregate memory reserved for HDFS caching on the cluster. Cache pools also track a number of statistics to help cluster users determine what is and should be cached.
缓冲池也被用来资源管理。缓冲池可以设置一个最大值,这个最大值限制缓冲池中指令总的可以被缓存的数据的大小。正常情况下,缓冲池限制的和大约等于集群中HDFS缓存的总的剩余。缓冲池也追踪很多的统计数据来帮助集群用户判断应该缓存什么。
Pools also can enforce a maximum time-to-live. This restricts the maximum expiration time of directives being added to the pool.
缓冲池也可以设置最大的过期时间。这将限制增加到缓冲池中的指令的最大的过期时间。
cacheadmin command-line interface
On the command-line, administrators and users can interact with cache pools and directives via the hdfs cacheadmin subcommand.
在命令行中,管理员和用户可以通过hdfs cacheadmin子命令与缓冲池和指令交互。
Cache directives are identified by a unique, non-repeating 64-bit integer ID. IDs will not be reused even if a cache directive is later removed.
缓冲指令通过一个全局唯一的,不重复的64为整数ID来标识。即使缓存之后再之后被删除,ID也不会被重用。
Cache pools are identified by a unique string name.
缓冲池通过一个全局唯一的字符串名字标识。
Cache directive commands
addDirective
Usage: hdfs cacheadmin -addDirective -path <path> -pool <pool-name> [-force] [-replication <replication>] [-ttl <time-to-live>]
Add a new cache directive.
增加一个新的缓存指令:
|
<path> |
A path to cache. The path can be a directory or a file. |
|
<pool-name> |
The pool to which the directive will be added. You must have write permission on the cache pool in order to add new directives. |
|
-force |
Skips checking of cache pool resource limits. |
|
<replication> |
The cache replication factor to use. Defaults to 1. |
|
<time-to-live> |
How long the directive is valid. Can be specified in minutes, hours, and days, e.g. 30m, 4h, 2d. Valid units are [smhd]. “never” indicates a directive that never expires. If unspecified, the directive never expires. |
removeDirective
Usage: hdfs cacheadmin -removeDirective <id>
Remove a cache directive.
移除一个缓存指令。
|
<id> |
The id of the cache directive to remove. You must have write permission on the pool of the directive in order to remove it. To see a list of cachedirective IDs, use the -listDirectives command. |
removeDirectives
Usage: hdfs cacheadmin -removeDirectives <path>
Remove every cache directive with the specified path.
移除所有路径列表中指定的缓存指令。
|
<path> |
The path of the cache directives to remove. You must have write permission on the pool of the directive in order to remove it. To see a list of cache directives, use the -listDirectives command. |
listDirectives
Usage: hdfs cacheadmin -listDirectives [-stats] [-path <path>] [-pool <pool>]
List cache directives.
列出所有的缓存指令。
|
<path> |
List only cache directives with this path. Note that if there is a cache directive for path in a cache pool that we don’t have read access for, it will not be listed. |
|
<pool> |
List only path cache directives in that pool. |
|
-stats |
List path-based cache directive statistics. |
Cache pool commands
addPool
Usage: hdfs cacheadmin -addPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-maxTtl <maxTtl>
Add a new cache pool.
增加一个新的缓冲池。
|
<name> |
Name of the new pool. |
|
<owner> |
Username of the owner of the pool. Defaults to the current user. |
|
<group> |
Group of the pool. Defaults to the primary group name of the current user. |
|
<mode> |
UNIX-style permissions for the pool. Permissions are specified in octal, e.g. 0755. By default, this is set to 0755. |
|
<limit> |
The maximum number of bytes that can be cached by directives in this pool, in aggregate. By default, no limit is set. |
|
<maxTtl> |
The maximum allowed time-to-live for directives being added to the pool. This can be specified in seconds, minutes, hours, and days, e.g. 120s, 30m, 4h, 2d. Valid units are [smhd]. By default, no maximum is set. A value of “never ” specifies that there is no limit. |
modifyPool
Usage: hdfs cacheadmin -modifyPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-maxTtl <maxTtl>]
Modifies the metadata of an existing cache pool.
修改一个已经存在的缓冲池的元数据。
|
<name> |
Name of the pool to modify. |
|
<owner> |
Username of the owner of the pool. |
|
<group> |
Groupname of the group of the pool. |
|
<mode> |
Unix-style permissions of the pool in octal. |
|
<limit> |
Maximum number of bytes that can be cached by this pool. |
|
<maxTtl> |
The maximum allowed time-to-live for directives being added to the pool. |
removePool
Usage: hdfs cacheadmin -removePool <name>
Remove a cache pool. This also uncaches paths associated with the pool.
移除一个缓冲池。这将同时移除相关的路径。
|
<name> |
Name of the cache pool to remove. |
listPools
Usage: hdfs cacheadmin -listPools [-stats] [<name>]
Display information about one or more cache pools, e.g. name, owner, group, permissions, etc.
显示一个或者多个缓冲池的信息,例如名字,所有者,用户组,权限等等。
|
-stats |
Display additional cache pool statistics. |
|
<name> |
If specified, list only the named cache pool. |
help
Usage: hdfs cacheadmin -help <command-name>
Get detailed help about a command.
关于一个命令的详细的帮助信息。
|
<command-name> |
The command for which to get detailed help. If no command is specified, print detailed help for all commands. |
Configuration
Native Libraries
In order to lock block files into memory, the DataNode relies on native JNI code found in libhadoop.so or hadoop.dll on Windows. Be sure to enable JNI if you are using HDFS centralized cache management.
为了将Block文件锁定在内存,DataNode依赖libhadoop.so中的本地JNI代码。如果你使用HDFS集中式缓存管理的话,确定开启了JNI。
Configuration Properties
Required
Be sure to configure the following:
- dfs.datanode.max.locked.memory
This determines the maximum amount of memory a DataNode will use for caching. On Unix-like systems, the “locked-in-memory size” ulimit (ulimit -l) of the DataNode user also needs to be increased to match this parameter (see below section on OS Limits). When setting this value, please remember that you will need space in memory for other things as well, such as the DataNode and application JVM heaps and the operating system page cache.
This setting is shared with the Lazy Persist Writes feature. The Data Node will ensure that the combined memory used by Lazy Persist Writes and Centralized Cache Management does not exceed the amount configured in dfs.datanode.max.locked.memory.
确定配置了下面的配置:
1. dfs.datanode.max.locked.memory
这决定了一个DataNode将要用来被做HDFS缓存的内存的最大值。用ulimit –l可以用来查看DataNode节点的程序锁定内存的限制,用户需要增加这个值以适应这个配置的参数。当设置了这个值之后,请记住,你将需要内存中的空间做其他事,像DataNode和应用的JVM的堆栈和操作系统的页面缓存。
Optional
The following properties are not required, but may be specified for tuning:
- dfs.namenode.path.based.cache.refresh.interval.ms
The NameNode will use this as the amount of milliseconds between subsequent path cache rescans. This calculates the blocks to cache and each DataNode containing a replica of the block that should cache it.
By default, this parameter is set to 300000, which is five minutes.
- dfs.datanode.fsdatasetcache.max.threads.per.volume
The DataNode will use this as the maximum number of threads per volume to use for caching new data.
By default, this parameter is set to 4.
- dfs.cachereport.intervalMsec
The DataNode will use this as the amount of milliseconds between sending a full report of its cache state to the NameNode.
By default, this parameter is set to 10000, which is 10 seconds.
- dfs.namenode.path.based.cache.block.map.allocation.percent
The percentage of the Java heap which we will allocate to the cached blocks map. The cached blocks map is a hash map which uses chained hashing. Smaller maps may be accessed more slowly if the number of cached blocks is large; larger maps will consume more memory. The default is 0.25 percent.
下面的属性是不必要的,担在调优的时候可以指定:
1. dfs.namenode.path.based.cache.refresh.interval.ms
NameNode将使用这个值作为两次连续的缓存扫描的时间间隔。这将计算缓存的块数和每个包含一个Block的副本的DataNode应该缓存这个Block。
2. dfs.datanode.fsdatasetcache.max.threads.per.volume
DataNode将使用这个值作为每个Volume用来缓存新块的最大的线程数。
默认,这个值被设置为 4.
3. dfs.cachereport.intervalMsec
DataNode将使用这个值作为两次发送完整的缓存状态的报告到NameNode的时间间隔。
默认,这个值被设置为10000,也就是10秒。
4. dfs.namenode.path.based.cache.block.map.allocation.percent
我们申请用来缓存Block的java堆的百分比。这个Map是一个HashMap。如果缓存块的数量太大,比较小的Map可能访问很慢,较大的map将会消耗更多的内存(hashmap的机制)。默认是0.25。
OS Limits
If you get the error “Cannot start datanode because the configured max locked memory size… is more than the datanode’s available RLIMIT_MEMLOCK ulimit,” that means that the operating system is imposing a lower limit on the amount of memory that you can lock than what you have configured. To fix this, you must adjust the ulimit -l value that the DataNode runs with. Usually, this value is configured in /etc/security/limits.conf. However, it will vary depending on what operating system and distribution you are using.
如果你得到一个错误,Cannot start datanode because the configured maxlocked memory size... is more than the datanode's available RLIMIT_MEMLOCKulimit,,这个意思是说,操作系统在你lock的内存总量设置了一个比你配置的值低的limit。为了修复这个错误,你必须调整运行DataNode的机器的ulimit -l的值。通常,这个值在 /etc/security/limits.conf 中被设置。但是,根据你使用的操作系统和发行版的不同会有变化。
You will know that you have correctly configured this value when you can run ulimit -l from the shell and get back either a higher value than what you have configured with dfs.datanode.max.locked.memory, or the string “unlimited,” indicating that there is no limit. Note that it’s typical for ulimit -l to output the memory lock limit in KB, but dfs.datanode.max.locked.memory must be specified in bytes.
当你在shell运行ulimit -l命令时,你将知道你是否正确的设置了新的值。这个命令应该返回一个高于你在dfs.datanode.max.locked.memory中设置的值,或者是字符串“ulimited”,代表没有限制。注意,ulimit-l的输出通常是KB,但是dfs.datanode.max.locked.memory必须以byte设置。
This information does not apply to deployments on Windows. Windows has no direct equivalent of ulimit -l.
这些信息并不适用于部署在Windows。窗户没有直接相当于ulimit - l。
Centralized Cache Management in HDFS的更多相关文章
- 十一:Centralized Cache Management in HDFS 集中缓存管理
集中的HDFS缓存管理,该机制可以让用户缓存特定的hdfs路径,这些块缓存在堆外内存中.namenode指导datanode完成这个工作. Centralized cache management i ...
- HDFS集中式缓存管理(Centralized Cache Management)
Hadoop从2.3.0版本号開始支持HDFS缓存机制,HDFS同意用户将一部分文件夹或文件缓存在HDFS其中.NameNode会通知拥有相应块的DataNodes将其缓存在DataNode的内存其中 ...
- System and method for cache management
Aspects of the invention relate to improvements to the Least Recently Used (LRU) cache replacement m ...
- NGINX Cache Management (.imh nginx)
In this article, we will explore the various NGINX cache configuration options, and tips on tweaking ...
- 论文阅读 Prefetch-aware fingerprint cache management for data deduplication systems
论文链接 https://link.springer.com/article/10.1007/s11704-017-7119-0 这篇论文试图解决的问题是在cache 环节之前,prefetch-ca ...
- Hadoop学习笔记—HDFS
目录 搭建安装 三个核心组件 安装 配置环境变量 配置各上述三组件守护进程的相关属性 启停 监控和性能 Hadoop Rack Awareness yarn的NodeManagers监控 命令 hdf ...
- 编译Hadoop 2.7.2支持压缩 转
hadoop Native Shared Libraries 使得Hadoop可以使用多种压缩编码算法,来提高数据的io处理性能.不同的压缩库需要依赖到很多Linux本地共享库文件,社区提供的二进制安 ...
- HADOOP docker(八):hadoop本地库
前言2. Native Hadoop Library3. 使用本地库4. 本地库组件5. 支持的平台6. 下载7. 编译8. 运行时观察9. 检查本地库10. 如果共享本地库 小伙伴还记得每次启动hd ...
- HDFS中的集中缓存管理详解
一.背景 Hadoop设计之初借鉴GFS/MapReduce的思想:移动计算的成本远小于移动数据的成本.所以调度通常会尽可能将计算移动到拥有数据的节点上,在作业执行过程中,从HDFS角度看,计算和数据 ...
随机推荐
- Dubbo -- 系统学习 笔记 -- 依赖
Dubbo -- 系统学习 笔记 -- 目录 依赖 必需依赖 缺省依赖 可选依赖 依赖 必需依赖 JDK1.5+ 理论上Dubbo可以只依赖JDK,不依赖于任何三方库运行,只需配置使用JDK相关实现策 ...
- mysql字段集合中如何去除其中一个元素
在一对多方案中,我们用逗号拼接进行存储,避免存储多条,或者分表,那么此时出现了存储上如果需要修改的话 就带来了难度,比如规则记录表如下 如果2号规则被删除,那么这张表的所有有2的记录也要被清除掉,此时 ...
- 关于C#事件的理解
一.一个不错的例子 class FileFFF { public delegate void FileWatchEventHandler(object sender,EventArgs args);/ ...
- 【Java知识点专项练习】之 数据类型两大类
Java的数据类型分为两大类:基本类型和引用类型: 基本类型只能保存一些常量数据,引用类型除了可以保存数据,还能提供操作这些数据的功能: 为了操作基本类型的数据,java也对它们进行了封装, 得到八个 ...
- VC利用调试寄存器实现硬件断点源码
[文章标题]:VC利用调试寄存器实现硬件断点源码 [文章作者]:yhswwr(SilenceRet) [作者QQ]:3412259 [编写语言]:C++ [使用工具]:VS2008.VC++9 [本文 ...
- springbatch---->springbatch的使用(三)
这里我们对上篇博客的例子做一个修改性的测试来学习一下springbatch的一些关于chunk的一些有用的特性.我渐渐能意会到,深刻并不等于接近事实. springbatch的学习 一.chunk的s ...
- css3整理--border-image
border-image语法: border-image : none | <image> [ <number> | <percentage>]{1,4} [ / ...
- python基础知识-GUI编程-TK-StringVar
1.如何引出StringVar 之前一直认为StringVar就是类似于Java的String类型的对象变量,今天在想要设置StringVar变量的值的时候,通过搜索发现StringVar并不是pyt ...
- Android Log缓冲区大小设置
当手机没有连接PC时,手机log缓冲区仍然会保存指定大小的最新log,连接pc,通过adb logcat 仍然可以拿出来 如何查看log缓缓区的大小? 通过adb logcat -g 可以查看 C:\ ...
- 重建索引:ALTER INDEX..REBUILD ONLINE vs ALTER INDEX..REBUILD
什么时候需要重建索引 1. 删除的空间没有重用,导致 索引出现碎片 2. 删除大量的表数据后,空间没有重用,导致 索引"虚高" 3.索引的 clustering_facto 和表不 ...