Hive的初识
Hive是构建于Hadoop上的数据仓库基础框架,它提供了以下功能:
- 可通过SQL轻松的访问数据,从而实现数据仓库的任务。如提取/转换/加载,报告和数据分析。
- 对各种数据格式施加结构。
- 访问存储在HDFS或是其他数据存储系统上文件。
- 可使用MapReduce或是Spark作为执行层。
- 通过Hive LLAP,YARN和Slider进行亚秒级查询检索。
Hive架构与基本组成
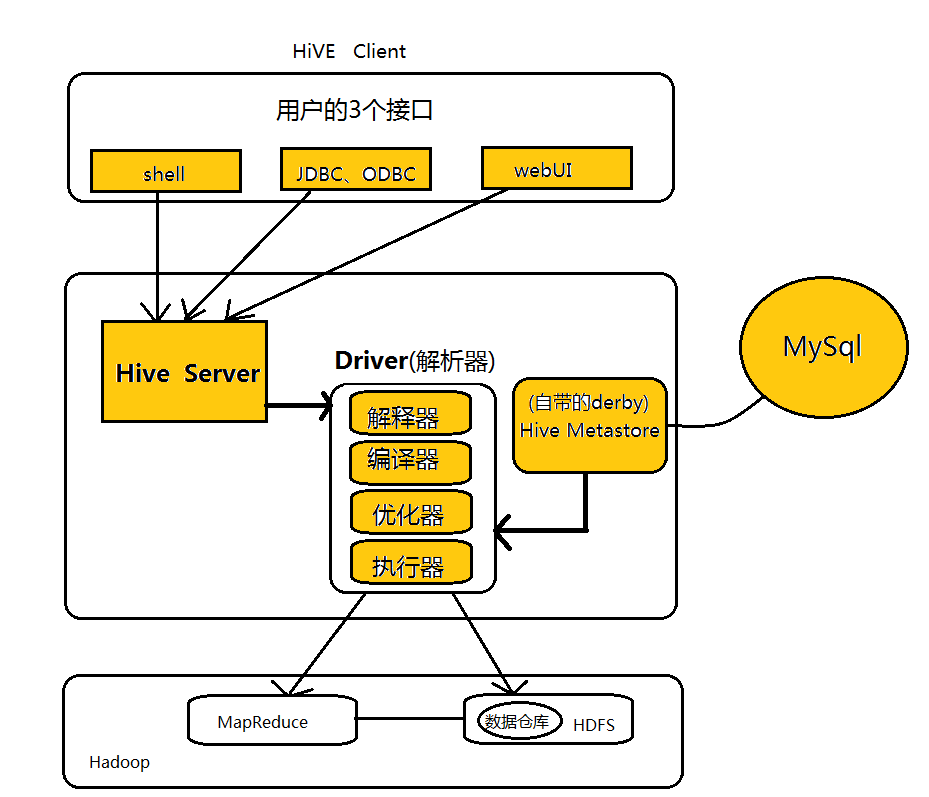
Hive的体系结构可以分为以下几部分:
- Hive对外提供的接口主要包括CLI,WebUI和基于JDBC/ODBC协议的数据库接口。其中最常用的是CLI。
- Hive将元数据存储在数据库中,如MySQL,Derby。Hive中的元数据包括表的名字、表的列和分区及其属性、表的数据所在目录等。
- 解析器、编辑器、优化器和执行器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询技术存储在HDFS中,并在随后由MapReduce调用执行。
- Hive的数据存储在HDFS中,大部分的查询计算都有MapReduce完成。
Hive的metastore的三种模式:
- 内嵌模式:元数据保持在内嵌的Derby模式,只允许一个会话连接。hive默认的启动模式,一般用于单元测试,这种模式有个缺点:hive server重启后所有的元数据都会丢失,而且在同一时间只能有一个进程连接使用数据库(单会话)
- 本地独立模式:在本地安装MySQL,并把元数据放到MySQL中
- 远程模式:将元数据放置在远程的MySQL数据库中。需在服务器端启动MetastoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
Hive中数据模型:
- 内外表比较
- Hive中的表跟数据库中的表概念类似,每个表在Hive中都有一个对应的存储目录。内部表默认存在HDFS的/user/hive/warehouse下(该路径由hive-site.xml文件中的${hive.metastore.warehouse.dir}指定,所有的表数据(外表除外)都保存在该目录中)。
- 内外表的相同之处:都需要指定元数据,都支持分区。
- 内外表不同之处:实际的数据存储地点不同。
- 内部表实际的数据存储在数据仓库目录中(默认是集群/user/hive/warehouse下),删除表时,表中的数据和元数据都将会被同时删除。
- 外部表的实际数据存储在创建语句location指定的HDFS路径中,不会移动到数据库目录中,如果删除一个外部表,仅会删除元数据而表中的数据不会被删除。一般在先有数据后要分析的时候选用外部表,因为可以创建一个外部表指向数据。
- 分区(Partition):每个表可以有一个或是多个分区键,用于确定数据的存储方式。Hive表中一个分区对应表下的一个目录,所有分区数据都存储在对应的子目录中。
- 桶:对指定列进行哈希计算时,根据哈希值切分数据,每一个桶对应一个文件。
Hive的初识的更多相关文章
- Hive[1] 初识 及 安装
本文前提是Hadoop & Java & mysql 数据库,已经安装配置好,并且 环境变量均已经配置到位 声明:本笔记参照 学习<Hive 编程指南>而来,如果有错误 ...
- [转帖]Hive学习之路 (一)Hive初识
Hive学习之路 (一)Hive初识 https://www.cnblogs.com/qingyunzong/p/8707885.html 讨论QQ:1586558083 目录 Hive 简介 什么是 ...
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- 初识hive
由facebook 开源用以帮用户解决海量数据etl,构建于hadoop的 数据仓库. 使用hql作为查询接口 使用hdfs作为底层存储 使用mr作为执行层 1.为什么使用hive? 1 ...
- [Hadoop大数据]——Hive初识
Hive出现的背景 Hadoop提供了大数据的通用解决方案,比如存储提供了Hdfs,计算提供了MapReduce思想.但是想要写出MapReduce算法还是比较繁琐的,对于开发者来说,需要了解底层的h ...
- Hive学习之路 (一)Hive初识
Hive 简介 什么是Hive 1.Hive 由 Facebook 实现并开源 2.是基于 Hadoop 的一个数据仓库工具 3.可以将结构化的数据映射为一张数据库表 4.并提供 HQL(Hive S ...
- Hive(一)Hive初识
一 Hive 简介 什么是Hive 1.Hive 由 Facebook 实现并开源 2.是基于 Hadoop 的一个数据仓库工具 3.可以将结构化的数据映射为一张数据库表 4.并提供 HQL(Hive ...
- Apache Hive (一)Hive初识
转自:https://www.cnblogs.com/qingyunzong/p/8707885.html Hive 简介 什么是Hive 1.Hive 由 Facebook 实现并开源 2.是基于 ...
- Hive初识(四)
Hive本质上是一个数据仓库,但不存储数据(只存储元数据(metadata),Hive中的元数据包括表的名字,表的列和分区及分区及其属性,表的属性(是否为外部表等),表的数据所在目录等),用户可以借助 ...
随机推荐
- div凹角实现
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- jieba库与词云的使用——以孙子兵法为例
1.打开cmd安装jieba库和 matplotlib. 2.打开python,输入代码.代码如下: from wordcloud import WordCloud import matplotlib ...
- 箭头函数里this理解
先来看代码: var obj1={ id:4, fn:function(){ var f=() => { console.log(this); //object,f()定义在obj1对象中,th ...
- 跟随我在oracle学习php(18)
修改表: 一般概述 通常,创建一个表,能搞定(做到)的事情,修改表也能做到.大体来说,就可以做到: 增删改字段: 增:alter table 表名 add [column] 字段名 字段类 ...
- python之路-模块初识
# sys模块 import sys #print (sys.path) #打印环境变量 print (sys.arge) print (sys.arge[2]) # os模块 import os # ...
- Google 最新推出数据集搜索
继Google在2004年11月推出Google的重量产品Google scholar后,Google在最近推出的另一个重量级产品 Google Dataset Search.众所周知,互联网上的信息 ...
- C++笔记之关键字explicit
在C++中,explicit关键字用来修饰类的构造函数,被修饰的构造函数的类,不能发生相应的隐式类型转换,只能以显示的方式进行类型转换. explicit使用注意事项: explicit 关键字只能用 ...
- js 判断变量是否为空或未定义
判断变量是否定义: if(typeof(hao) == "undefined"){ //未定义 }else{ //定义 } 判断变量是否为空或NULL,是则返回'', 反之返回原对 ...
- mysql安装(centos 7)
1.安装依赖 yum install -y cmake make gcc gcc-c++ libaio ncurses ncurses-devel cd /usr/local/src 链接:https ...
- 【转】Android-Input 触摸设备
https://source.android.com/devices/input/touch-devices 触摸设备 Android 支持各种触摸屏和触摸板,包括基于触控笔的数字化板. 触摸屏是与显 ...