目标检测(一) R-CNN
R-CNN全称为 Region-CNN,它是第一个成功地将深度学习应用到目标检测的算法,后续的改进算法 Fast R-CNN、Faster R-CNN都是基于该算法。
传统方法 VS R-CNN
传统的目标检测大多以图像识别为基础。一般是在图片上穷举出所有物体可能出现的区域框,然后对该区域框进行特征提取,运用图像识别方法进行分类,最后通过非极大值抑制输出结果。
传统方法最大的问题在特征提取部分,它基于经验驱动的人造特征范式,如haar、HOG、SIFT,并不能很好的表征样本。
R-CNN思路大致相同,但是采用了深度网络来提取特征。
计算机视觉概念科普
在计算机视觉领域,有很多不同方向的任务,如图像分类、图像定位、目标检测、实例分割
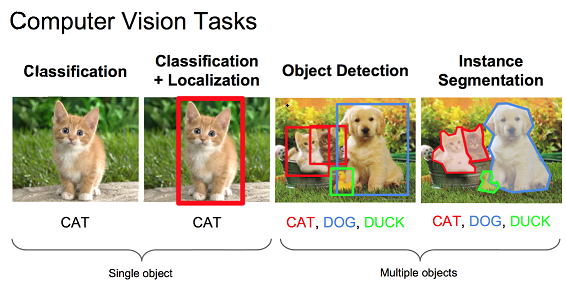
R-CNN可以用于后三种。
R-CNN详解
R-CNN模型比较复杂,训练和测试过程分开讲解
训练过程
训练过程的特点在于采用了有监督预训练,在特定样本上微调
1. 有监督预训练
| 样本 | 来源 |
|---|---|
| 正样本 | ILSVRC2012 |
| 负样本 | ILSVRC2012 |
ILSVRC数据集样本很多;
ILSVRC数据集只有图像类别标签,没有图像中物体位置标签;
采用AlexNet网络进行有监督预训练,学习率0.01;
AlexNet 输入为227x227,输出为4096-->1000
这一步的目的是得到预训练参数
================ 扩展 ================
什么叫有监督预训练
有监督预训练也叫迁移学习,举个例子,现在有大量人脸图片,其类别标签为年龄,可以根据该训练集得到CNN网络,用于预测年龄;现在又有一批人脸数据,其类别标签为性别,我们是否需要从头训练一个CNN网络呢?不需要。
我们可以把“年龄网络”的最后一层或几层去掉,换上我们需要的“性别网络”,把“年龄网络”前些层的参数直接赋给“性别网络”对应层,作为这些层的初始化参数,“性别网络”新增层采用常规初始化参数,然后利用训练集重新训练该网络。
说的简单一点,把一个训练好的模型的参数直接用于另一个模型,作为这个模型的初始化参数,再进行训练
有监督预训练的作用
1. 实践证明,提高了模型的精度
2. 加快模型的训练速度
3. 解决了小样本数据集无法训练深层CNN网络的问题,也解决了小样本数据集容易过拟合的问题
2. 特定样本下的微调
| 样本 | 来源 |
|---|---|
| 正样本 | Ground Truth+与Ground Truth相交IoU>0.5的建议框【由于Ground Truth太少了】 |
| 负样本 | 与Ground Truth相交IoU≤0.5的建议框 |
PASCAL VOC 2007数据集样本较少;
PASCAL VOC 2007数据集既有图像类别标签,也有图像中物体位置标签;
采用训练好的 AlexNet 网络进行PASCAL VOC 2007数据集下的微调,学习率0.001,;【参数已经预训练,所以学习率要小一点】
mini-batch 采用32正样本96负样本;【由于正样本比较少】
该网络的输入为通过 Selective Search 得到的建议框,需要变形为227x227,输出层由1000改为21,输出21类【20类+背景】
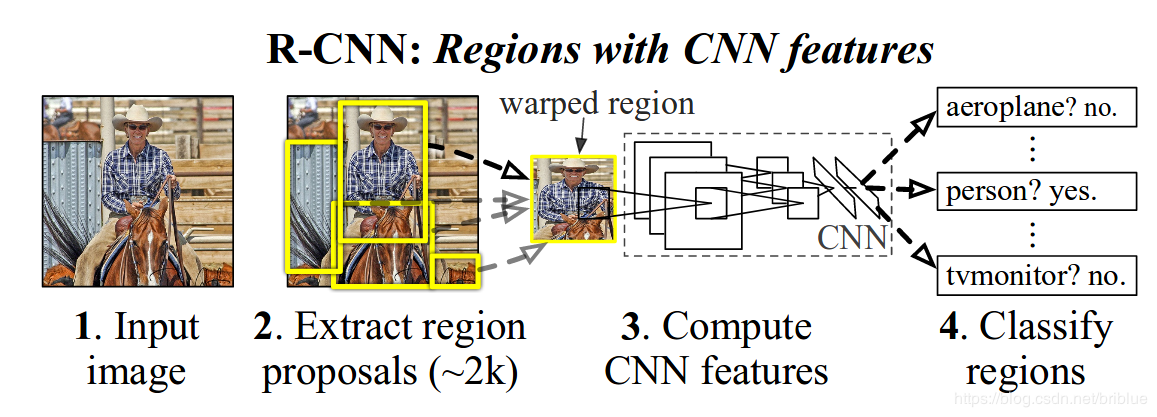
这一步的目的是得到用于特征提取的参数
================ 扩展 ================
为什么要在特定样本下微调?或者说可不可以直接用AlexNet的参数进行特征提取?
作者对微调与不微调都进行了实验
不微调,直接拿AlexNet的pool5、fc6、fc7层参数分别进行特征提取,输入SVM进行训练,【这相当于把AlexNet当做特征提取的标准模板,万金油模板,意思是不管什么任务,就是这一套,就像传统的harr特征一样】
结果发现 fc6层提取的特征比fc7更准,pool5层提取的特征与fc6、fc7层准确率差不多;
微调,用微调后的pool5、fc6、fc7层参数分别进行特征提取,发现fc6、fc7层提取的特征准确率明显高于pool5层;
卷积与全连接
通过上述实验,可以得出如下结论,
卷积提取的是共性特征,或者说基础特征,如人脸的鼻子、眼睛等;【注意鼻子眼睛只是举例,方便你理解,实际上不是的,可能只是一个点,比如你的色斑,只是形象描述而已】
全连接是针对类别标签得到的个性特征,如欧洲人鼻子比较尖,眼睛比较蓝;

3. SVM训练
| 样本 | 来源 |
|---|---|
| 正样本 | Ground Truth |
| 负样本 | 与Ground Truth相交IoU<0.3的建议框 |
SVM是二分类器,故需要多个SVM分类器 ;
SVM输入是微调后的AlexNet参数提取的特征,4096维,输出每类的得分;
负样本太多,采用hard negative mining的方法在负样本中选取有代表性的负样本
这一步的目的是得到SVM分类器
================ 扩展 ================
什么叫 IoU
图片的交集/图片的并集,A∩B/AUB
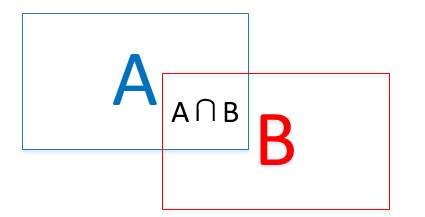
为什么要IoU
通过某种方式选择图片上物体所在区域时,可能会有同一个物体被多次选择的情况,此时需要通过IoU识别。

为什么第2步微调模型时正负样本IoU阈值与第3步SVM不一样?0.5 VS 0.3
1. 微调阶段由于CNN很容易对小样本过拟合,所以需要增加正样本的数目,而负样本不需增加,因为负样本是在图片上搜索到的,想要多少有多少,为了得到更多正样本,就要降低IoU的阈值,一般我们认为两张图片重合70% 80%才算一张,而降低到50%就能增加正样本。
而SVM不需要太多的数据集,无需增加样本,故IoU限制比较严格,重合70%才认为是一张图片。
2. 微调阶段是为了获取特征提取的参数,而样本中人脸有可能是半张脸,或者有遮挡等等,如果CNN模型只能提取整张脸的特征,那“部分脸”肯定会识别错误,减小阈值可以得到很多“部分脸”的样本,从而CNN可以提取“部分脸”的特征,原则上讲,如果计算资源运行,我们希望特征越多越好,即使无用也没关系。
而SVM是分类器,根据输入特征进行分类,正负样本需要有比较明显的界线,最好不要有模棱两可的样本,故 IoU要严格限制。
为什么不用AlexNet直接分类,而是又训练了SVM?
这个问题其实挺不好回答的,
网上有这么说的:因为 AlexNet 和 SVM 采用的正负样本不同,微调阶段正样本不一定是正样本,而SVM正样本就是正样本,而且微调阶段负样本随机采样,而SVM采用hard negative mining方法筛选负样本,
那不禁有人要问了,AlexNet 也采用 真正的正样本,负样本也hard negative mining方法筛选,不就行了?
我觉得这是一个需要系统回答的问题,个人理解如下:
传统的图像识别、目标检测等采用人造特征进行特征提取,深度学习盛行以后,作者想采用深度学习来提取特征,注意初衷只是提取特征,然后用传统机器学习如 SVM等来进行分类,以便比较人造特征和深度学习提取特征的差别有多大,所以作者刚开始就打算要SVM,而在实验过程中,作者发现了样本小,部分脸等问题,所以采用了微调阶段的数据增强等措施,而SVM就是正常的模型训练。
4. Bounding-Box Regression
| 样本 | 来源 |
|---|---|
| 正样本 | 与Ground Truth相交IoU最大的Region Proposal,并且IoU>0.6的Region Proposal |
回归器训练,这是在干嘛,哪来的回归问题?
首先要明确目标检测不仅是图像识别,还需要对物体进行定位,Bounding-Box定位准确与否也是模型精度的一部分。这里定位准确率可以用IoU衡量。

如上图,即使图像识别为飞机,但是标注框不准,IoU<0.5,也相当于没有检测出目标。
这一步的目的是生成标注框
================ 扩展 ================
回归模型如何设计
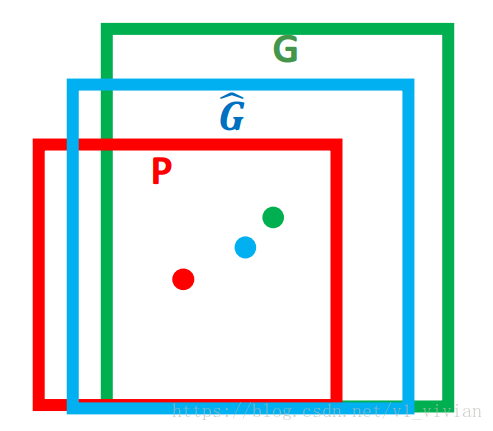
上图中,红色框P代表 Selective Search 选择的建议框Region Proposal,绿色框G代表实际框Ground Truth,蓝色框G'代表Region Proposal进行回归后的预测窗口
目标是找到P到G’的线性变换,使得G’无限接近于G。【笔者认为IoU>0.6的建议框才符合线性变换】
思考下线性变换,初始化参数wx+b,真实值y,然后 y-(wx+b),使其最小,思路同上。
设 P=(Px, Py, Pw, Ph),分别代表P的横坐标,纵坐标,红色框的宽度,高度,(Px, Py)是红色框的中心;
G=(Gx, Gy, Gw, Gh),绿色框,
G'=(G'x, G'y, G'w, G'h),蓝色框,
类比线性回归 wP+b-G=G'-G
从P到G',其实是一个平移和缩放的过程,
平移可以表示为
G'x=Px+Δx
G'y=Py+Δy
缩放可以表示为
G'w=Pw*Δw
G'h=Ph*Δh
作者用下面的式子表示线性变换
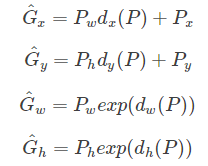
d(P)的输入其实并不是一个(x,y,w,h),而是 AlexNet 网络pool5层的特征 Ø(P)的线性变换,即 d(P)=wØ(P),w就是回归参数,
把真实数据带入上述线性变换的公式,即把G'换成G
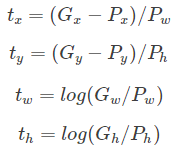
上面的d是预测,t是实际,t-d就是误差,于是得到损失函数
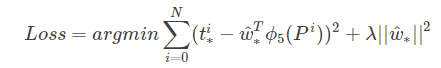
后面为正则项,不再赘述。
稍微总结一下
a. 构造样本对,也就是回归的数据集
// 首先明白一点,bbr是根据每类样本的特征得到回归方程的,所以每个类别有一个回归方程
// 每类样本中每次识别都选择与Ground Truth IoU最大的建议框,并且IoU>0.6,作为一个样本{P,G}
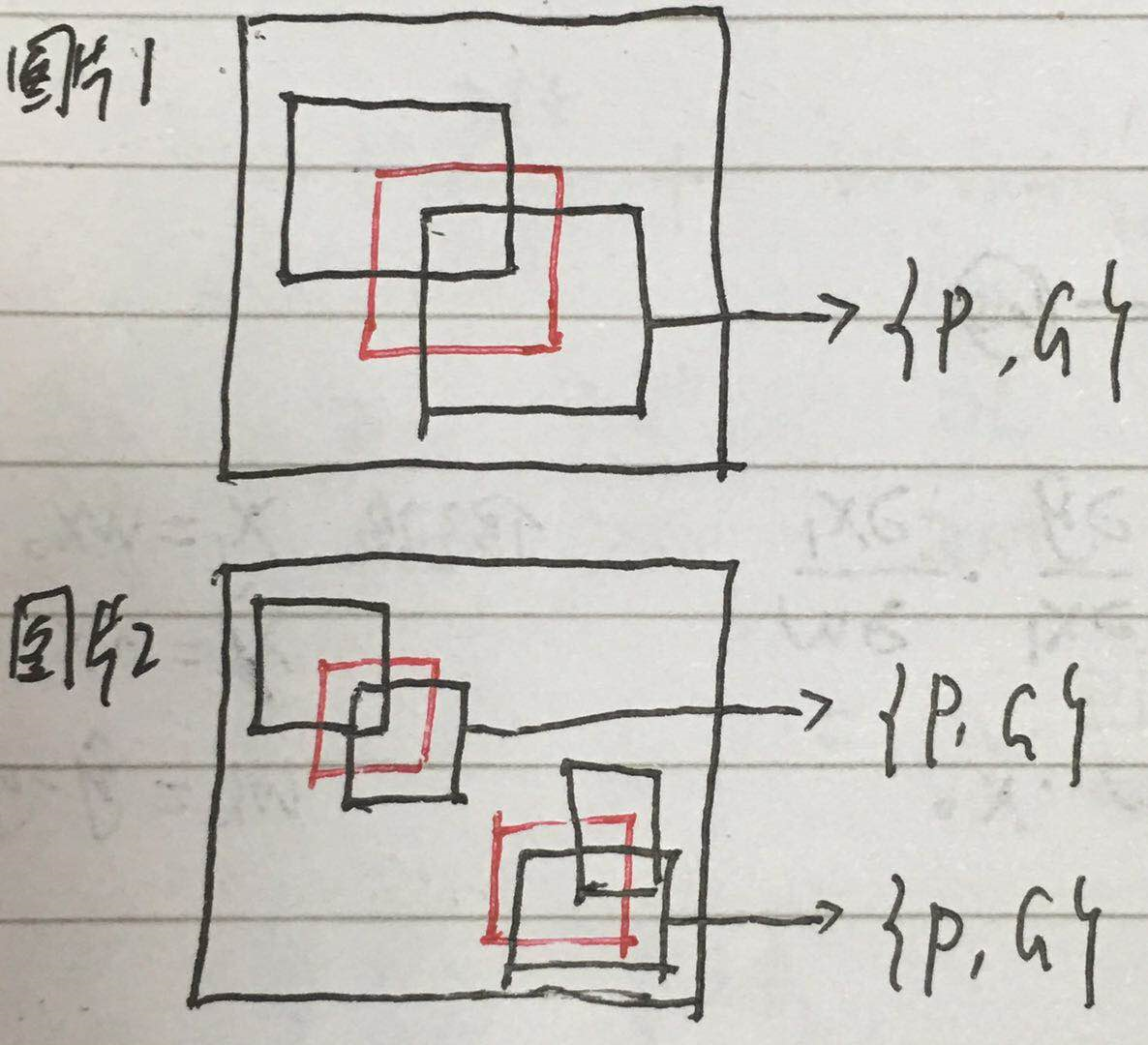
b. 针对每个类别训练回归器,输入该类别的样本,以及每个P对应的AlexNet的pool5层的特征
c. 得到参数w
至此,R-CNN 训练完成。
测试过程
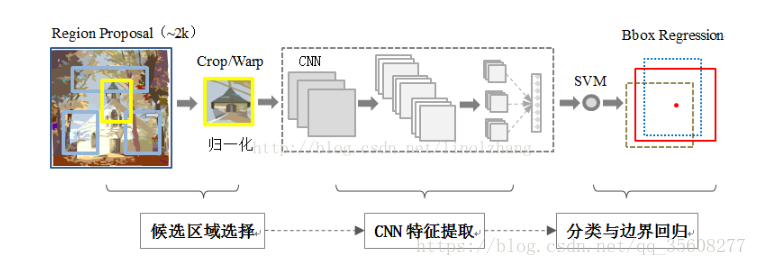
1. 给定一张多目标图片,采用 Selective Search 选出约2000个建议框
// 在每个建议框周围加上16个 <像素值为建议框像素平均值> 的边框,再形变为 227x227 的大小
// 将所有建议框像素减去 该建议框的像素平均值
2. 将2000个建议框送入AlexNet网络进行特征提取,生成2000x4096矩阵
3. 将特征矩阵送入SVM模型,生成2000x20矩阵,表示每个建议框输入每个类别的得分
4. 对上述2000x20矩阵每一列即每一类进行 非极大值抑制 操作,剔除重复建议框,得到每列中得分最高的不同建议框
5. 对每列中剩下的建议框进行回归操作,得到标注框
================ 扩展 ================
Selective Search
分割图片,具体我会在其他博客详解
如何形变为227x227
先解释两个名词
各向异性缩放:非等比例缩放,不管图片的长宽比例,不管缩放后是否扭曲,直接缩放就是了;缩放后一般会扭曲,扭曲会对CNN有一定影响
各向同性缩放:有两种做法
1. 直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;
2. 先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值);
作者进行了如下尝试
① 考虑context【图像中context指RoI周边像素】的各向同性变形,建议框像周围像素扩充到227×227,若遇到图像边界则用建议框像素均值填充,下图第二列;
② 不考虑context的各向同性变形,直接用建议框像素均值填充至227×227,下图第三列;
③ 各向异性变形,简单粗暴对图像就行缩放至227×227,下图第四列;
④ 变形前先进行边界像素填充【padding】处理,即向外扩展建议框边界,以上三种方法中分别采用padding=0下图第一行,padding=16下图第二行进行处理;
经过作者一系列实验表明采用padding=16的各向异性变形即下图第二行第三列效果最好,能使mAP提升3-5%。

非极大值抑制
解决问题:多个建议框指向了同一个物体,我们只需要该物体IoU最大的建议框
具体操作
1. 输入为2000x20矩阵,2000代表2000个建议框,20代表20个类别
2. 对每个类别进行排序,从大到小
3. 首先取得分最高的建议框,设为物体1,然后遍历后面所有的建议框,如果建议框和物体1的建议框IoU大于阈值,则认为是一个物体,把这些建议框删除,
如果小于阈值,则认为是另一个物体,暂时保留,保留下来的建议框仍然是有序的
4. 去掉该列被认定的建议框,如物体1,将剩下的建议框进行步骤3操作,直到认定完所有物体
5. 对每列进行上述操作
6. 也可以设定阈值对每列中剩余建议框与真实标注IoU较小的建议框【作者没有此步】
至此,R-CNN 测试完成。
R-CNN 的问题
1. 处理速度慢,一张图片采用 Selective Search 获取2000个建议框,然后变形,通过AlexNet提取特征,计算量很大,而且存在多个重复区域的重复计算
2. 整体过程太复杂,计算量大,一句话就够了
参考资料:
https://blog.csdn.net/wopawn/article/details/52133338
https://blog.csdn.net/qq_35608277/article/details/80178628
https://blog.csdn.net/v1_vivian/article/details/80292569 Bounding-Box 回归
https://blog.csdn.net/zijin0802034/article/details/77685438 Bounding-Box 回归
https://github.com/Stick-To/LH-RCNN-tensorflow/blob/master/LH_RCNN.py github 代码
目标检测(一) R-CNN的更多相关文章
- 数据挖掘、目标检测中的cnn和cn---卷积网络和卷积神经网络
content 概述 文字识别系统LeNet-5 简化的LeNet-5系统 卷积神经网络的实现问题 深度神经网路已经在语音识别,图像识别等领域取得前所未有的成功.本人在多年之前也曾接触过神经网络.本系 ...
- [转]CNN目标检测(一):Faster RCNN详解
https://blog.csdn.net/a8039974/article/details/77592389 Faster RCNN github : https://github.com/rbgi ...
- CNN之yolo目标检测算法笔记
本文并不是详细介绍yolo工作原理以及改进发展的文章,只用做作者本人回想与提纲. 1.yolo是什么 输入一张图片,输出图片中检测到的目标和位置(目标的边框) yolo名字含义:you only lo ...
- 【神经网络与深度学习】【计算机视觉】RCNN- 将CNN引入目标检测的开山之作
转自:https://zhuanlan.zhihu.com/p/23006190?refer=xiaoleimlnote 前面一直在写传统机器学习.从本篇开始写一写 深度学习的内容. 可能需要一定的神 ...
- CNN目标检测系列算法发展脉络——学习笔记(一):AlexNet
在咨询了老师的建议后,最近开始着手深入的学习一下目标检测算法,结合这两天所查到的资料和个人的理解,准备大致将CNN目标检测的发展脉络理一理(暂时只讲CNN系列部分,YOLO和SSD,后面会抽空整理). ...
- 皮卡丘检测器-CNN目标检测入门教程
目标检测通俗的来说是为了找到图像或者视频里的所有目标物体.在下面这张图中,两狗一猫的位置,包括它们所属的类(狗/猫),需要被正确的检测到. 所以和图像分类不同的地方在于,目标检测需要找到尽量多的目标物 ...
- 目标检测方法总结(R-CNN系列)
目标检测方法系列--R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD 目录 相关背景 从传统方法到R-CNN 从R-CNN到SPP Fast R-CNN ...
- 目标检测之R-CNN系列
Object Detection,在给定的图像中,找到目标图像的位置,并标注出来. 或者是,图像中有那些目标,目标的位置在那.这个目标,是限定在数据集中包含的目标种类,比如数据集中有两种目标:狗,猫. ...
- 利用更快的r-cnn深度学习进行目标检测
此示例演示如何使用名为“更快r-cnn(具有卷积神经网络的区域)”的深度学习技术来训练对象探测器. 概述 此示例演示如何训练用于检测车辆的更快r-cnn对象探测器.更快的r-nnn [1]是r-cnn ...
- 第三节,目标检测---R-CNN网络系列
1.目标检测 检测图片中所有物体的 类别标签 位置(最小外接矩形/Bounding box) 区域卷积神经网络R-CNN 模块进化史 2.区域卷积神经网络R-CNN Region proposals+ ...
随机推荐
- ORM的概念
- 添加“Git Bash Here”到右键菜单
1.按键盘上的组合键[Win+R]把运行调出来 2.在运行中输入[regedit]再点击确定. 3.定位到HKEY_CLASSES_ROOT\Directory\Background\shell(如果 ...
- js实现bind方法
//目标函数 function fun(...args) { console.log(this); console.log(args); } //目标函数原型对象上的一个方法cher func.pro ...
- Javaweb里“容器“为何出现,应用在哪,未来发展趋势
容器是一个Java 所编写的程序,可当做一个工具,没有容器时必须自行编写程序以管理对象关系,现在容器都会自动做好. 有一说法:如果有一个类专门用来存放其它类的对象,这个类就叫做容器.另一说法:容器里存 ...
- RecyclerView嵌套ScrollView导致RecyclerView内容显示不全
我们在使用RecyclerView嵌套至ScrollView内的时候 RecyclerView不在屏幕内的数据会不显示出来,这里是一个坑,我们需要重写RecyclerView /** * Create ...
- springcloud-feign组件实现声明式的调用
11.使用feign实现声明式的调用 使用RestTemplate+ribbon已经可以完成对服务端负载均衡的调用,为什么还要使用feign? @RequestMapping("/hi&qu ...
- 正则-关于一个结果不确定现象怪的研究(reg.test(‘-1’))
先看下边代码 var value = '-1'; var reg = /^-{0,1}\d+$/g; debugger; if (reg.test(value)||reg2.test(value)) ...
- 爬虫(三)http和https协议
一.HTTP协议 1.官方概念: HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文 ...
- ie8遇到的那些事
IE一直是我们津津乐道的浏览器,他的奇葩想必各位在开发之路上都不断的遇到了,其恶心程度就不必说了,我们公司主要是IE的浏览器,这次我就把我遇到的不兼容问题列举下来,欢迎大家补充.此举只发表IE8以上的 ...
- python - 初识面向对象
1.初识面向对象 面向过程:一切以事务的发展流程为中心 优点:负责的问题流程化,编写相对简单 缺点:可扩展性差,只能解决一个问题,改造也会很困难,牵一发 ...